We’re excited to share an update with people running Linux on ARM64 (also known as AArch64) architectures.
ARM64 Binaries Are Here
After launching the Firefox Nightly .deb package, feedback highlighted a demand for ARM64 builds. In response, we’re excited to now offer Firefox Nightly for ARM64 as both .tar archives and .deb packages. Keep the suggestions coming – feedback is always welcome!
.tar Archives: Prefer our traditional .tar.bz2 binaries? You can get them from our downloads page by selecting Firefox Nightly for Linux ARM64/AArch64.
.deb Packages: For updates and installation via our APT repository, you can follow these instructions and install the firefox-nightly package.
On ARM64 Build Stability
We want to be upfront about the current state of our ARM64 builds. Although we are confident in the quality of Firefox on this architecture, we are still incorporating comprehensive ARM64 testing into Firefox’s continuous integration and release pipeline. Our goal is to integrate ARM64 builds into Firefox’s extensive automated test suite, which will enable us to offer this architecture across the beta, release, and ESR channels.
Your Feedback Is Crucial
We encourage you to download the new ARM64 Firefox Nightly binaries, test them, and share your findings with us. By using these builds and reporting any issues, you’re empowering our developers to better support and test on this architecture, ultimately leading to a stable and reliable Firefox for ARM64. Please share your findings through Bugzilla and stay tuned for more updates. Thank you for your ongoing participation in the Firefox Nightly community!
We’re excited to share that Mozilla's IRL podcast is a Shorty Awards finalist in the Science and Technology Podcast category! If you enjoy IRL you can show your support by voting for us.
The Shorty Awards recognizes great content by brands, agencies and nonprofits. It’s really an honor to be able to feature the voices and stories of the folks who are putting people over profit in AI. A Shorty Award will help bring these stories to even more listeners.
Microsoft Exchange is a popular choice of email service for corporations and educational institutions, and so it’s no surprise that there’s demand among Thunderbird users to support Exchange. Until recently, this functionality was only available through an add-on. But, in the next ESR (Extended Support) release of Thunderbird in July 2024, we expect to provide this support natively within Thunderbird. Because of the size of this undertaking, the first roll-out of the Exchange support will initially cover only email, with calendar and address book support coming at a later date.
This article will go into technical detail on how we are implementing support for the Microsoft Exchange Web Services mail protocol, and some idea of where we’re going next with the knowledge gained from this adventure.
Before we dive in, just a quick note that Brendan Abolivier, Ikey Doherty, and Sean Burke are the developers behind this effort, and are the authors of this post.
Thunderbird is a long-lived project, which means there’s lots of old code. The current architecture for supporting mail protocols predates Thunderbird itself, having been developed more than 20 years ago as part of Netscape Communicator. There was also no paid maintainership from about 2012 — when Mozilla divested and transferred ownership of Thunderbird to its community — until 2017, when Thunderbird rejoined the Mozilla Foundation. That means years of ad hoc changes without a larger architectural vision and a lot of decaying C++ code that was not using modern standards.
Furthermore, in the entire 20 year lifetime of the Thunderbird project, no one has added support for a new mail protocol before. As such, no one has updated the architecture as mail protocols change and adapt to modern usage patterns, and a great deal of institutional knowledge has been lost. Implementing this much-needed feature is the first organization-led effort to actually understand and address limitations of Thunderbird’s architecture in an incremental fashion.
Why we chose Rust
Thunderbird is a large project maintained by a small team, so choosing a language for new work cannot be taken lightly. We need powerful tools to develop complex features relatively quickly, but we absolutely must balance this with long-term maintainability. Selecting Rust as the language for our new protocol support brings some important benefits:
Memory safety. Thunderbird takes input from anyone who sends an email, so we need to be diligent about keeping security bugs out.
Performance. Rust runs as native code with all of the associated performance benefits.
Modularity and Ecosystem. The built-in modularity of Rust gives us access to a large ecosystem where there are already a lot of people doing things related to email which we can benefit from.
The above are all on the standard list of benefits when discussing Rust. However, there are some additional considerations for Thunderbird:
Firefox. Thunderbird is built on top of Firefox code and we use a shared CI infrastructure with Firefox which already enables Rust. Additionally, Firefox provides a language interop layer called XPCOM (Cross-Platform Component Object Model), which has Rust support and allows us to call between Rust, C++, and JavaScript.
Powerful tools. Rust gives us a large toolbox for building APIs which are difficult to misuse by pushing logical errors into the domain of the compiler. We can easily avoid circular references or provide functions which simply cannot be called with values which don’t make sense, letting us have a high degree of confidence in features with a large scope. Rust also provides first-class tooling for documentation, which is critically important on a small team.
Addressing architectural technical debt. Introducing a new language gives us a chance to reconsider some aging architectures while benefiting from a growing language community.
Platform support and portability. Rust supports a broad set of host platforms. By building modular crates, we can reuse our work in other projects, such as Thunderbird for Android/K-9 Mail.
Some mishaps along the way
Of course, the endeavor to introduce our first Rust component in Thunderbird is not without its challenges, mostly related to the size of the Thunderbird codebase. For example, there is a lot of existing code with idiosyncratic asynchronous patterns that don’t integrate nicely with idiomatic Rust. There are also lots of features and capabilities in the Firefox and Thunderbird codebase that don’t have any existing Rust bindings.
The first roadblock: the build system
Our first hurdle came with getting any Rust code to run in Thunderbird at all. There are two things you need to know to understand why:
First, since the Firefox code is a dependency of Thunderbird, you might expect that we pull in their code as a subtree of our own, or some similar mechanism. However, for historical reasons, it’s the other way around: building Thunderbird requires fetching Firefox’s code, fetching Thunderbird’s code as a subtree of Firefox’s, and using a build configuration file to point into that subtree.
Second, because Firefox’s entrypoint is written in C++ and Rust calls happen via an interoperability layer, there is no single point of entry for Rust. In order to create a tree-wide dependency graph for Cargo and avoid duplicate builds or version/feature conflicts, Firefox introduced a hack to generate a single Cargo workspace which aggregates all the individual crates in the tree.
In isolation, neither of these is a problem in itself. However, in order to build Rust into Thunderbird, we needed to define our own Cargo workspace which lives in our tree, and Cargo does not allow nesting workspaces. To solve this issue, we had to define our own workspace and add configuration to the upstream build tool, mach, to build from this workspace instead of Firefox’s. We then use a newly-added mach subcommand to sync our dependencies and lockfile with upstream and to vendor the resulting superset.
XPCOM
While the availability of language interop through XPCOM is important for integrating our frontend and backend, the developer experience has presented some challenges. Because XPCOM was originally designed with C++ in mind, implementing or consuming an XPCOM interface requires a lot of boilerplate and prevents us from taking full advantage of tools like rust-analyzer. Over time, Firefox has significantly reduced its reliance on XPCOM, making a clunky Rust+XPCOM experience a relatively minor consideration. However, as part of the previously-discussed maintenance gap, Thunderbird never undertook a similar project, and supporting a new mail protocol requires implementing hundreds of functions defined in XPCOM.
Existing protocol implementations ease this burden by inheriting C++ classes which provide the basis for most of the shared behavior. Since we can’t do this directly, we are instead implementing our protocol-specific logic in Rust and communicating with a bridge class in C++ which combines our Rust implementations (an internal crate called ews_xpcom) with the existing code for shared behavior, with as small an interface between the two as we can manage.
Implementing Exchange support with Rust
Despite the technical hiccups experienced along the way, we were able to clear the hurdles, use, and build Rust within Thunderbird. Now we can talk about how we’re using it and the tools we’re building. Remember all the way back to the beginning of this blog post, where we stated that our goal is to support Microsoft’s Exchange Web Services (EWS) API. EWS communicates over HTTP with request and response bodies in XML.
Sending HTTP requests
Firefox already includes a full-featured HTTP stack via its necko networking component. However, necko is written in C++ and exposed over XPCOM, which as previously stated does not make for nice, idiomatic Rust. Simply sending a GET request requires a great deal of boilerplate, including nasty-looking unsafe blocks where we call into XPCOM. (XPCOM manages the lifetime of pointers and their referents, ensuring memory safety, but the Rust compiler doesn’t know this.) Additionally, the interfaces we need are callback-based. For making HTTP requests to be simple for developers, we need to do two things:
Support native Rust async/await syntax. For this, we added a new Thunderbird-internal crate, xpcom_async. This is a low-level crate which translates asynchronous operations in XPCOM into Rust’s native async syntax by defining callbacks to buffer incoming data and expose it by implementing Rust’s Future trait so that it can be awaited by consumers. (If you’re not familiar with the Future concept in Rust, it is similar to a JS Promise or a Python coroutine.)
Provide an idiomatic HTTP API. Now that we had native async/await support, we created another internal crate (moz_http) which provides an HTTP client inspired by reqwest. This crate handles creating all of the necessary XPCOM objects and providing Rustic error handling (much nicer than the standard XPCOM error handling).
Handling XML requests and responses
The hardest task in working with EWS is translating between our code’s own data structures and the XML expected/provided by EWS. Existing crates for serializing/deserializing XML didn’t meet our needs. serde’s data model doesn’t align well with XML, making distinguishing XML attributes and elements difficult. EWS is also sensitive to XML namespaces, which are completely foreign to serde. Various serde-inspired crates designed for XML exist, but these require explicit annotation of how to serialize every field. EWS defines hundreds of types which can have dozens of fields, making that amount of boilerplate untenable.
Ultimately, we found that existing serde-based implementations worked fine for deserializing XML into Rust, but we were unable to find a satisfactory tool for serialization. To that end, we introduced another new crate, xml_struct. This crate defines traits governing serialization behavior and uses Rust’s procedural derive macros to automatically generate implementations of these traits for Rust data structures. It is built on top of the existing quick_xml crate and designed to create a low-boilerplate, intuitive mapping between XML and Rust. While it is in the early stages of development, it does not make use of any Thunderbird/Firefox internals and is available on GitHub.
We have also introduced one more new crate, ews, which defines types for working with EWS and an API for XML serialization/deserialization, based on xml_struct and serde. Like xml_struct, it is in the early stages of development, but is available on GitHub.
Overall flow chart
Below, you can find a handy flow chart to help understand the logical flow for making an Exchange request and handling the response.
Fig 1. A bird’s eye view of the flow
What’s next?
Testing all the things
Before landing our next major features, we are taking some time to build out our automated tests. In addition to unit tests, we just landed a mock EWS server for integration testing. The current focus on testing is already paying dividends, having exposed a couple of crashes and some double-sync issues which have since been rectified. Going forward, new features can now be easily tested and verified.
Improving error handling
While we are working on testing, we are also busy improving the story around error handling. EWS’s error behavior is often poorly documented, and errors can occur at multiple levels (e.g., a request may fail as a whole due to throttling or incorrect structure, or parts of a request may succeed while other parts fail due to incorrect IDs). Some errors we can handle at the protocol level, while others may require user intervention or may be intractable. In taking the time now to improve error handling, we can provide a more polished implementation and set ourselves up for easier long-term maintenance.
Expanding support
We are working on expanding protocol support for EWS (via ews and the internal ews_xpcom crate) and hooking it into the Thunderbird UI. Earlier this month, we landed a series of patches which allow adding an EWS account to Thunderbird, syncing the account’s folder hierarchy from the remote server, and displaying those folders in the UI. (At present, this alpha-state functionality is gated behind a build flag and a preference.) Next up, we’ll work on fetching message lists from the remote server as well as generalizing outgoing mail support in Thunderbird.
Documentation
Of course, all of our work on maintainability is for naught if no one understands what the code does. To that end, we’re producing documentation on how all of the bits we have talked about here come together, as well as describing the existing architecture of mail protocols in Thunderbird and thoughts on future improvements, so that once the work of supporting EWS is done, we can continue building and improving on the Thunderbird you know and love.
Like many people who work at Mozilla, I’m inspired by the organization’s mission: to ensure the Internet is a global public resource, open and accessible to all. In thinking about the team I belong to, though, what’s our piece of this bigger puzzle?
The Firefox User Research team tackled this question early last year. We gathered in person for a week of team-focused activities; defining a team mission statement was on the agenda. As someone who enjoys workshop creation and strategic planning, I was on point to develop the workshop. The end goal? A team-backed statement that communicated our unique purpose and value.
Mission statement development was new territory for me. I read up on approaches for creating them and landed on a workshop design (adapted from MITRE’s Innovation Toolkit) that would enable the team to participate in a process of collectively reflecting on our work and defining our shared purpose.
To my delight, the workshop was fruitful and engaging. Not only did it lead us to a statement that resonates, but it also sparked meaningful discussion along the way.
Here, I outline the five workshop activities that guided us there.
1) Discuss the value of a good mission statement
We kicked off the workshop by discussing the value of a well-crafted statement. Why were we aiming to define one in the first place? Benefits include: fostering alignment between the team’s activities and objectives, communicating the team’s purpose, and helping the team to cohere around a shared direction. In contrast to a vision statement, which describes future conditions in aspirational language, a mission statement describes present conditions in concrete terms.
In our case, the team had recently grown in size to thirteen people. We had a fairly new leadership team, along with a few new members of the team. With a mix of longer tenure and newer members, and quantitative and mixed methods researchers (which at one point in the past had been on separate teams), we wanted to inspire team alignment around our shared goals and build bridges between team members.
2) Individually answer a set of questions about our team’s work
Large sheets of paper were set up around the room with the following questions:
A. What do we, as a user research team, do?
B. How do we do what we do?
C. What value do we bring?
D. Who benefits from our work?
E. Why does our team exist?
Markers in hand, team members dispersed around the room, spending a few minutes writing answers to each question until we had cycled through them all.
Team members during the workshop
3) Highlight keywords and work in groups to create draft statements
Small groups were formed and were tasked with highlighting keywords from the answers provided in the previous step. These keywords served as the foundation for drafting statements, with the following format provided as a helpful guide:
Our mission is to (A — what we do) by (B — how we do it).
We (C — the value we bring) so that (D — who benefits from our work ) can (E — why we exist).
One group’s draft statement from Step 3
4) Review and discuss resulting statements
Draft statements emerged remarkably fluidly from the activities in Steps 2 and 3. Common elements were easy to identify (we develop insights and shape product decisions), while the differences sparked worthwhile discussions. For example: How well does the term ‘human-centered’ capture the work of our quantitative researchers? Is creating empathy for our users a core part of our purpose? How does our value extend beyond impacting product decisions?
As a group, we reviewed and discussed the statements, crossing out any jargony terms and underlining favoured actions and words. After this step, we knew we were close to a final statement. We concluded the workshop, with a plan to revisit the statements when we were back to work the following week.
5) Refine and share for feedback
The following week, we refined our work and shared the outcome with the lead of our Content Design practice for review. Her sharp feedback included encouraging us to change the phrase ‘informing strategic decisions’ to ‘influencing strategic decisions’ to articulate our role as less passive — a change we were glad to make. After another round of editing, we arrived at our final mission statement:
Our mission is to influence strategic decisions through systematic, qualitative, and quantitative research. We develop insights that uncover opportunities for Mozilla to build an open and healthy internet for all.
Closing thoughts
If you’re considering involving your team in defining a team mission statement, it makes for a rewarding workshop activity. The five steps presented in this article give team members the opportunity to reflect on important foundational questions (what value do we bring?), while deepening mutual understanding.
Crafting a team mission statement was much less of an exercise in wordsmithing than I might have assumed. Instead, it was an exercise in aligning on the bigger questions of why we exist and who benefits from our work. I walked away with a better understanding of the value our team brings to Mozilla, a clearer way to articulate how our work ladders up to the organization’s mission, and a deeper appreciation for the individual perspectives of our team members.
Technology and Artificial Intelligence (AI) are just about everywhere, all the time — and that’s even more the case for the younger generation. We rely on apps, algorithms and chatbots to stay informed and connected. We work, study and entertain ourselves online. We check the news, learn about elections and stay informed during crises through screens. We monitor our health using smart devices and make choices based on the results and recommendations displayed back to us. Very few aspects of our lives evades digitization, and even those that remain analog require intention and mindfulness to keep it that way.
In this context and with the rise of AI and a growing generation of teens relying on the internet for learning, entertainment and socializing, now more than ever, it’s important to find ways to involve them in conversations about how technology influences their lives, their communities and the future of the planet.
Tech isn’t all or nothing — it’s something in between
The message adults used early on when it came to discussing technology with teens was “don’t.” Don’t spend too much time on your phone. Don’t play video games. Don’t use social media. This old-school method proved ineffective and, in some cases, counterproductive.
More recently, things have changed, and in some cases, adults have welcomed technology into their homes with open arms, sometimes without critique or caution. At the same time, schools have put great emphasis on training teens in web development and robotics in order to prepare them for the ever-changing job market. But before slow-motion running on a beach into a full embrace with technology, pause for a moment to reflect on the power of what we hold in our hands, and consider the profound ways in which it has reshaped our world.
It’s as if adults jumped between two extreme poles: from utter dystopia, to bright and shiny techno-solutionism, skipping the nuances in between. So, how can adults prepare to foster discussions with teens about technological ethics and the impacts of technology? How can teens be involved and engaged in conversations about their relationship to the technologies they use? We share the future with younger generations, so we need to involve them in these conversations in meaningful ways.
Teens don’t just want to have fun, they want to talk about what matters to them
At Tactical Tech, we’re always coming up with creative, sometimes unconventional ways to talk about technology and its impacts. We make public exhibitions in unexpected places. We create toolkits and guides in surprising formats. But to make interventions specifically for teens, we knew we needed to get them involved. We asked almost 300 international teens what matters to them, what they worry about and what they expect the future to be like. The results gave us goosebumps. Here are just a few quotes:
“I have a sad feeling that everything in the future will be online, including school.”
“Everyone is inside all the time, they’re not outside enjoying the world.”
“Loneliness is a problem. Online relationships aren’t real.”
But not all of their responses were so despairing. They also had dreams about technology being used to help us, such as through education and medical advancements.
“Internet can close the distance gap that currently exists. Since society is more connected, cultures are more accepted.”
“Nobody dies. Artificial intelligence has trained on their personalities, and we can digitally bring them back to life thanks to this data.”
We also asked 100 international educators what they needed in order to confidently talk to teens about technology. Educators felt positive about our creative, and non-judgmental approach. They encouraged us to make resources that are even more playful, to add more relatable examples and to make sure the points are as concrete and transferable as possible.
Breaching serious topics in fun and creative ways
With all that in mind, we co-created Everywhere, All The Time, a fun-yet-impactful learning experience for teens. Educators can use it to encourage young people to talk about technology, AI and how it affects them. Everywhere, All The Time, can be used to create a space where they can think about their relationship with technology and become inspired to make choices about the digital world they want to live in. This self-learning intervention includes a package with captivating posters and activities about:
Gaming and the attention economy
Our relationship to technology
How Large Language Models (LLMs) work
Algorithms in everyday life
The materiality of the internet
The invisible labor behind technology
The package, created by Tactical Tech’s youth initiative, What the Future Wants, includes provocative posters, engaging activity cards and a detailed guidebook that trains educators to facilitate these nuanced and sometimes delicate conversations.
Whether you work in a school, library, community center or want to hang it up at home, you can use the Everywhere, All The Time posters, activity cards and guidebook to start conversations with teens about the topics they care about. Now is the moment to come together and involve teens in these conversations.
At Mozilla, we know we can’t create a better future alone, that is why each year we will be highlighting the work of 25 digital leaders using technology to amplify voices, effect change, and build new technologies globally through our Rise 25 Awards. These storytellers, innovators, activists, advocates, builders and artists are helping make the internet more diverse, ethical, responsible and inclusive.
This week, we chatted with Finn Lützow-Holm Myrstad, a true leader of development of better and more ethical digital policies and standards for the Norwegian Consumer Council. We talked with Finn about his work focusing on tech policy, the biggest concerns in 2024 and ways people can take action against those in power.
You started your journey to the work you do now when you were a little kid going to camps. What did that experience teach you that you appreciate now as an adult?
Since CISV International gathered children from around the world and emphasized team building and friendship, it gave me a more global perspective and made me realize how we need to work together to solve problems that concern us all. Now that the internet is spreading to all corners of the world and occupying a larger part of our lives, we also need to work together to solve the challenges this creates.
There’s a magnitude of subjects of concern in the tech policy space, especially considering how rapid tech is evolving in our world. Which area has you most concerned?
Our freedom to think and act freely is under pressure as increased power and information asymmetries put people at an unprecedented disadvantage, which is reinforced by deceptive design, addictive design and artificial intelligence. This makes all of us vulnerable in certain contexts. Vulnerabilities can be identified and reinforced by increased data collection, in combination with harmful design and surveillance-based advertising. Harm will probably be reinforced against groups who are already vulnerable.
What do you think are easy ways people can speak up and hold companies, politicians, etc. accountable that they might not even be thinking about?
This is not easy for the reason outlined above. Having said that, we all need to speak up. Talk to your local politicians and media about your concerns, and try to use alternative tech services when possible (for example: for messaging, browsing and web searches.) However, it is important to stress that many of the challenges need to be dealt with at the political and regulatory level.
What do you think is the biggest challenge we face in the world this year on and offline? How do we combat it?
I see the biggest challenges as interlocked with each other. For example, this year in 2024, at least 49 percent of people in the world are meant to hold national elections. The decrease in trust in democracy and public institutions is a threat to freedom and to solving existential problems such as the climate emergency. Technology can be a part of solving these problems. However, that lack of transparency and accountability, in combination with power concentrated in a few tech companies, algorithms that favor enraging content, and a large climate and resource footprint, are currently part of the problem and not the solution.
We need to hold companies to account and ensure that fundamental human rights are respected.
<figcaption class="wp-element-caption">Finn Lützow-Holm Myrstad at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
What is one action that you think everyone should take to make the world and our lives online a little better?
Pause to think before you post is generally a good rule. If we all took a bit more care when posting and resharing content online, we could probably contribute to a less polarized discussion and maybe also get less addicted to our phones.
We started Rise25 to celebrate Mozilla’s 25th anniversary, what do you hope people are celebrating in the next 25 years?
That we managed to use the internet for positive change in the world, and that open internet is still alive.
What gives you hope about the future of our world?
That there is increased focus from all generations on the need for collective action. Together, I hope we can solve big challenges like the climate crisis and securing a free and open internet.
This spring we’re happy to announce that we’re refreshing the Mozilla Firefox Desktop and Mobile knowledge bases. This is a project that we’ve been working on for the past several months and now, we’re ready to finally share it with you all! We’ve put together a video to walk you through what these changes mean for SUMO and how they’ll impact you.
Introduction of Article Categories
When exploring our knowledge base, we realized there’s so many articles and it’s important to set expectations for users. We’ll be introducing three article types:
About – Article that aims to be educational and informs the reader about a certain feature.
How To – Article that aims to teach a user how to interact with a feature or complete a task.
Troubleshooting – Article that aims to provide solutions to an issue a user might encounter.
FAQ – Article that focuses on answering frequently asked questions that a user might have.
We will standardize titles and how articles are formatted per category, so users know what to expect when interacting with an article.
Downsizing and concentration of articles
There’s hundreds upon hundreds of articles in our knowledge base. However, many of them are repetitive and contain similar information. We want to reduce the number of articles and improve the quality of our content. We will be archiving articles and revising active articles throughout this refresh.
Style guideline update focus on reducing cognitive load
As mentioned in a previous post, we will be updating the style guideline and aiming to reduce the cognitive load on users by introducing new style guidelines like in-line images. There’s not huge changes, but we’ll go over them more when we release the updated style guidelines.
With all this coming up, we hope you join us for the community call today and learn more about the knowledge base refresh today. We hope to collaborate with our community to make this update successful.
Have questions or feedback? Drop us a message in this SUMO forum thread.
We admit it. Thunderbird is getting a bit Rusty, but in a good way! In our monthly Development Digests, we’ve been updating the community about enabling Rust in Thunderbirdto implementnative support for Exchange. Now, we’d like to invite you for a chat with Team Thunderbird and the developers making this change possible. As always, send your questions in advance to officehours@thunderbird.net! This is a great way to get answers even if you can’t join live.
Be sure to note the change in day of the week and the UTC time. (At least the time changes are done for now!) We had to shift our calendar a bit to fit everyone’s schedules and time zones!
April Office Hours: Rust and Exchange
This month’s topic is a new and exciting change to the core functionality: using Rust to natively support Microsoft Exchange. Join us and talk with the three key Thunderbird developers responsible for this shiny (rusty) new addition: Sean Burke, Ikey Doherty, and Brendan Abolivier! You’ll find out why we chose Rust, challenges we encountered, how we used Rust to interface with XPCOM and Necko to provide Exchange support. We’ll also give you a peek into some future plans around Rust.
Catch Up On Last Month’s Thunderbird Community Office Hours
While you’re thinking of questions to ask, watch last month’s office hours where we answered some of your frequently asked recent questions. You can watch clips of specific questions and answers on our TILvids channel. If you’d prefer a written summary, this blog post has you covered.
Join The Video Chat
We’ve also got a shiny new Big Blue Button room, thanks to KDE! We encourage everyone to check out their Get Involved page. We’re grateful for their support and to have an open source web conferencing solution for our community office hours.
WebDriver is a remote control interface that enables introspection and control of user agents. As such it canhelp developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we’ve done as part of the Firefox 125 release cycle.
Contributions
With Firefox being an open source project, we are grateful to get contributions from people outside of Mozilla.
We added support for the User Agent capability which is returned with all the other capabilities by the new session commands. It is listed under the userAgent key and contains the default user-agent string of the browser. For instance when connecting to Firefox 125 (here on macos), the capabilities will contain a userAgent property such as:
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:125.0) Gecko/20100101 Firefox/125.0"
WebDriver BiDi
New: Support for the “input.setFiles” command
The “input.setFiles” command is a new feature which allows clients to interact with <input> elements with type="file". As the name suggests, it can be used to set the list of files of such an input. The command expects three mandatory parameters. First the context parameter identifies the BrowsingContext (tab or window) where we expect to find an <input type="file">. Then element should be a sharedReference to this specific <input> element. Finally the files parameter should be a list (potentially empty) of strings which are the paths of the files to set for the <input>. This command has a null return value.
Note that providing more than one path in the files parameter is only supported for <input> elements with the multiple attribute set. Trying to send several paths to a regular <input> element will result in an error.
It’s also worth highlighting that the command will override the files which were previously set on the input. For instance providing an empty list as the files parameter will reset the input to have no file selected.
New: Support for the “storage.deleteCookies” command
In Firefox 124, we added two methods to interact with cookies: “storage.getCookies” and “storage.setCookie”. In Firefox 125 we are adding “storage.deleteCookies” so that you can remove previously created cookies. The parameters for the “deleteCookies” command are identical to the ones for the “getCookies” command: the filter argument allows to match cookies based on specific criteria and the partition argument allows to match cookies owned by a certain storage partition. All the cookies matching the provided parameters will be deleted. Similarly to “getCookies” and “setCookie”, “deleteCookies” will return the partitionKey which was built to retrieve the cookies.
New: Support for the “userContext” property in the “partition” argument
All storage commands accept a partition parameter to specify which storage partition it should use, whether it is to retrieve, create or delete cookie(s). Clients can now provide a userContext property in the partition parameter to build a partition key tied to a specific user context. As a reminder, user contexts are collections of browsing contexts sharing the same storage partition, and are implemented as Containers in Firefox.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization. The following
RFCs would benefit from user testing before moving forward:
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing
label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature
need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
There is absolutely no way I can imagine that Option is causing that error. That'd be like turning on the "Hide Taskbar" setting causing your GPU to catch fire.
[...]
If it's not any of those, consider an exorcist because your machine might be haunted.
We know the Thunderbird community has LOTS of questions! We get them on Mozilla Support, Mastodon, and X.com (formerly Twitter). They pop up everywhere, from the Thunderbird subreddit to the teeming halls of conferences like FOSDEM and SCaLE. During our March Community Office Hours, we took your most frequently asked questions to Team Thunderbird and got some answers. If you couldn’t watch the full session, or would rather have the answers in abbreviated text clips, this post is for you!
Thunderbird for Android / K-9 Mail
The upcoming release on Android is definitely on everyone’s mind! We received lots of questions about this at our conference booths, so let’s answer them!
Will there be Exchange support for Thunderbird for Android?
Yes! Implementing Exchange in Rust in the Thunderbird Desktop client will enable us to reuse those Rust crates as shared libraries with the Mobile client. Stay up to date on Exchange support progress via our monthly Developer Digests.
Will Thunderbird Add-ons be available on Android?
Right now, no, they will not be available. K-9 Mail uses a different code base than Thunderbird Desktop. Thunderbird add-ons are designed for a desktop experience, not a mobile one. We want to have add-ons in the future, but this will likely not happen within the next two years.
When Thunderbird for Android launches, will it be available on F-Droid?
It absolutely will.
When Thunderbird for Android is ready to be released, what will the upgrade path look like?
We know some in the K-9 Mail community love their adorable robot dog and don’t want to give him up yet. So we will support K-9 Mail (same code, different brand) in parallel for a year or two, until the product is more mature, and we see that more K-9 Mail users are organically switching.
Because of Android security, users will need to manually migrate from K-9 Mail to Thunderbird for Android, versus an automatic migration. We want to make that effortless and unobtrusive, and the Sync feature using Mozilla accounts will be a large part of that. We are exploring one-tap migration tools that will prompt you to switch easily and keep all your data and settings – and your peace of mind.
Will CalDAV and CardDAV be available on Thunderbird for Android?
Probably! We’re still determining this, but we know our users like having their contacts and calendars inside one app for convenience, as well as out of privacy concerns. While it would be a lot of engineering effort, we understand the reasoning behind these requests. As we consider how to go forward, we’ll release all these explorations and ideas in our monthly updates, where people can give us feedback.
Will the K-9 Mail API provide the ability to download the save preferences that Sync stores locally to plug into automation like Ansible?
Yes! Sync is open source, so users can self-host their own instead of using Mozilla services. This question touches on the differences between data structure for desktop and mobile, and how they handle settings. So this will take a while, but once we have something stable in a beta release, we’ll have articles on how to hook up your own sync server and do your own automation.
Thunderbird for Desktop
When will we have native Exchange support for desktop Thunderbird?
We hope to land this in the next ESR (Extended Support Release), version 128, in limited capacity. Users will still need to use the OWL Add-on for all situations where the standard exchange web service is not available. We don’t yet know if native calendar and address book support will be included in the ESR. We want to support every aspect of Exchange, but there is a lot of code complexity and a history of changes from Microsoft. So our primary goal is good, stable support for email by default, and calendar and address book if possible, for the next ESR.
When will conversations and a true threaded view be added to Thunderbird?
Viewing your own sent emails is an important component of a true conversation view. This is a top priority and we’re actively working towards it. Unfortunately, this requires overhauling the backend database that underlies Thunderbird, which is 20 years old. Our legacy database is not built to handle conversation views with received and sent messages listed in the same thread. Restructuring a two decades old database is not easy. Our goal is to have a new global message database in place by May 31. If nothing has exploded, it should be much easier to enable conversation view in the front end.
When will we get a full sender name columnwith the raw email address of the sender?This will help further avoid phishing and spam.
We plan to make this available in the next ESR — Thunderbird 128 — which is due July 2024.
Will there ever be a browser-based view of Thunderbird?
Despite our foundations in Firefox, this is a huge effort that would have to be built from scratch. This isn’t on our roadmap and not in our plans for now. If there was a high demand, we might examine how feasible this could be. Alex explains this in more detail during the short video below:
Welcome to the latest edition of the Performance Testing Newsletter! The PerfTools team empowers engineers with tools to continuously improve the performance of Mozilla products. See below for highlights from the changes made in the last quarter.
If you have any questions, or are looking to add performance testing for your code component, you can find us in #perftest on Element, or #perf-help on Slack.
P.S. If you’re interested in including updates from your teams in a quarterly newsletter like this, and you are not currently covered by another newsletter, please reach out to me (:sparky). I’m interested in making a more general newsletter for these.
In 2024, we'll be working with SRE to take over other monitoring services they
are currently supporting like New Relic, InfluxDB/Grafana, and others.
This newsletter covers an overview of 2024q1. Please forward it to interested
readers.
Highlights
🤹 Observability Services: Change in user support
🏆 Sentry: Change in ownership
‼️ Sentry: Please don't start new trials
⏲️ Sentry: Cron monitoring trial ending April 30th
⏱️ Sentry: Performance monitoring pilot
🤖 Socorro: Improvements to Fenix support
🐛 Socorro: Support guard page access information
See details below.
Blog posts
None this quarter.
Detailed project updates
Observability Services: Change in user support
We overhauled our pages in Confluence, started an #obs-help Slack channel,
created a new Jira OBSHELP project, built out a support rotation, and leveled
up our ability to do support for Observability-owned services.
documentation for common tasks (get protected data access, create a Sentry
team, etc)
self-serve instructions
Hop in #obs-help in Slack to ask for service
support, help with monitoring problems, and advice.
Sentry: Change in ownership
The Observability team now owns Sentry service at Mozilla!
We successfully completed Phase 1 of the transition in Q1. If you're a member
of the Mozilla Sentry organization, you should have received a separate email
about this to the sentry-users Google group.
We've overhauled Sentry user support documentation to improve it in a few ways:
easier to find "how to" articles for common tasks
best practices to help you set up and configure Sentry for your project needs
There's still a lot that we're figuring out, so we appreciate your patience and
cooperation.
Sentry: Please don't start new trials
Sentry sends marketing and promotional emails to Sentry users which often
include links to start a new trial. Please contact us before starting any new
feature trials in Sentry.
Starting new trials may prevent us from trialing those features in the future
when we’re in a better position to evaluate the feature. There's no way for
admins to prevent users from starting a trial.
Sentry: Cron monitoring trial ending April 30th
The Cron Monitoring trial that was
started a couple of months ago will end April 30th.
Based on feedback so far and other factors, we will not be enabling this
feature once the trial ends.
This is a good reminder to build in redundancy in your monitoring systems.
Don't rely solely on trial or pilot features for mission critical information!
Once the trial is over, we'll put together an evaluation summary.
Sentry: Performance monitoring pilot
Performance Monitoring is
being piloted by a couple of teams; it is not currently available for general
use.
In the meantime, if you are not one of these pilot teams, please do not use
Performance Monitoring. There is a shared transaction event quota for the
entire Mozilla Sentry organization. Once we hit that quota, events are dumped.
If you have questions about any of this, please reach out.
Once the trial is over, we'll put together an evaluation summary.
Socorro: Improvements to Fenix support
We worked on improvements to crash ingestion and the Crash Stats site for the
Fenix project:
Previously, the platform would be "Unknown". Now the platform for Fenix crash
reports is "Android". Further, the platform_pretty_version includes the
Android ABI version.
<figcaption>
Figure 1: Screenshot of Crash Stats Super Search results showing Android
versions for crash reports.
Forks of Fenix outside of our control periodically send large swaths of crash
reports to Socorro. When these sudden spikes happened, Mozillians would spend
time looking into them only to discover they're not related to our code or our
users. This is a waste of our time and resources.
We implemented support for the Android_PackageName crash annotation and
added a throttle rule to the collector to drop crash reports from any
non-Mozilla releases of Fenix.
From 2024-01-18 to 2024-03-31, Socorro accepted 2,072,785 Fenix crash reports
for processing and rejected 37,483 unhelpful crash reports with this new rule.
That's roughly 1.7%. That's not a huge amount, but because they sometimes come
in bursts with the same signature, they show up in Top Crashers wasting
investigation time.
A long time ago, in an age partially forgotten, Fenix crash reports from a
crash in Java code would send a crash report with a JavaStackTrace crash
annotation. This crash annotation was a string representation of the Java
exception. As such, it was difficult-to-impossible to parse reliably.
In 2020, Roger Yang and Will Kahn-Greene spec'd out a new JavaException crash
annotation. The value is a JSON-encoded structure mirroring what Sentry uses
for exception information. This structure provides more information than the
JavaStackTrace crash annotation did and is much easier to work with because we
don't have to parse it first.
Between 2020 and now, we have been transitioning from crash reports that only
contained a JavaStackTrace to crash reports that contained both a
JavaStackTrace and a JavaException. Once all Fenix crash reports from
crashes in Java code contained a JavaException, we could transition Socorro
code to use the JavaException value for Crash Stats views, signature
generation, generate-create-bug-url, and other things.
Recently, Fenix dropped the JavaStackTrace crash annotation. However, we
hadn't yet gotten to updating Socorro code to use--and prefer--the
JavaException values. This broke the ability to generate a bug for a Fenix
crash with the needed data added to the bug description. Work on bug 1884041
fixed that.
Crash report: https://crash-stats.mozilla.org/report/index/eb6f852b-4656-4cf5-8350-fd91a0240408
Top 10 frames:
0 android.database.sqlite.SQLiteConnection nativePrepareStatement SQLiteConnection.java:-2
1 android.database.sqlite.SQLiteConnection acquirePreparedStatement SQLiteConnection.java:939
2 android.database.sqlite.SQLiteConnection executeForString SQLiteConnection.java:684
3 android.database.sqlite.SQLiteConnection setJournalMode SQLiteConnection.java:369
4 android.database.sqlite.SQLiteConnection setWalModeFromConfiguration SQLiteConnection.java:299
5 android.database.sqlite.SQLiteConnection open SQLiteConnection.java:218
6 android.database.sqlite.SQLiteConnection open SQLiteConnection.java:196
7 android.database.sqlite.SQLiteConnectionPool openConnectionLocked SQLiteConnectionPool.java:503
8 android.database.sqlite.SQLiteConnectionPool open SQLiteConnectionPool.java:204
9 android.database.sqlite.SQLiteConnectionPool open SQLiteConnectionPool.java:196
This both fixes the bug and also vastly improves the bug comments from what we
were previously doing with JavaStackTrace.
Between 2024-03-31 and 2024-04-06, there were 158,729 Fenix crash reports
processed. Of those, 15,556 have the circumstances affected by this bug: a
JavaException but don't have a JavaStackTrace. That's roughly 10% of
incoming Fenix crash reports.
While working on this, we refactored the code that generates these crash report
bugs, so it's in a separate module that's easier to copy and use in external
systems in case others want to generate bug comments from processed crash data.
Further, we changed the code so that instead of dropping arguments in function
signatures, it now truncates them at 80 characters.
We're hoping to improve signature generation for Java crashes using
JavaException values in 2024q2. That work is tracked in
bug #1541120.
We updated the stackwalker to pick up the changes for determining
is_likely_guard_page. Then we exposed that in crash reports in the
has_guard_page_access field. We added this field to the Details tab in
crash reports and made it searchable. We also added this to the signature
report.
This helps us know if a crash is possibly due to a bug with memory access that
could be a possible security vulnerability vector--something we want to
prioritize fixing.
Since this field is security sensitive, it requires protected data access to
view and search with.
(To read the complete Mozilla.ai publication featuring all our OSS contributions, please visit the Mozilla.ai blog)
Like our parent company, Mozilla.ai’s founding story is rooted in open-source principles and community collaboration. Since our start last year, our key focus has been exploring state-of-the-art methods for evaluating and fine-tuning large-language models (LLMs).
Throughout this process, we’ve been diving into the open-source ecosystem around LLMs. What we’ve found is an electric environment where everyone is building. As Nathan Lambert writes in his post, “It’s 2024, and they just want to learn.”
“While everything is on track across multiple communities, that also unlocks the ability for people to tap into excitement and energy that they’ve never experienced in their career (and maybe lives).”
The energy in the space, with new model releases every day, is made even more exciting by the promise of open source where, as I’ve observed before, anyone can make a contribution and have it be meaningful regardless of credentials, and there are plenty of contributions to be made. If the fundamental question of the web is, “Why wasn’t I consulted,” open-source in machine learning today offers the answer, “You are as long as you can productively contribute PRs, come have a seat at the table.”
Even though some of us have been active in open-source work for some time, building and contributing to it at a team and company level is a qualitatively different and rewarding feeling. And it’s been especially fun watching upstream make its way into both the communities and our own projects.
At a high level, here’s what we’ve learned about the process of successful open-source contributions:
1. Start small when you’re starting with a new project. If you’re contributing to a new project for the first time, it takes time to understand the project’s norms: how fast they review, who the key people are, their preferences for communication, code review style, build systems, and more. It’s like starting a new job entirely from scratch.
Be gentle with both yourself and the reviewers and pick something like a documentation task, or a “good first issue” label just to get a feel for how things work.
2. Be easy to work with. There are specific norms around working with open source, and they closely follow this fantastic post of understanding how to be an effective developer – “As a developer you have two jobs: to write code, and be easy to work with.”
In open source, being easy to work with means different things to different people, but I generally see it as:
a. Submitting clean PRs with working code that passes tests or gets as close as possible. No one wants to fix your build.
b. Making small code changes by yourself, and proposing larger architecture changes in a group before getting them down in code for approval. Asking “What do you think about this?” Always try to also propose a solution instead of posing more problems to maintainers: they are busy!
c. Write unit tests if you’re adding a significant feature, where significant is anything more than a single line of code.
d. Remembering Chesterton’s fence: that code is there for a reason, study it before you suggest removing it.
3. Assume good intent, but make intent explicit. When you’re working with people in writing, asynchronously, potentially in other countries or timezones, it’s extremely easy for context, tone, and intent to get lost in translation. Implicit knowledge becomes rife. Assume people are doing the best they can with what they have, and if you don’t understand something, ask about it first.
4. The AI ecosystem moves quickly. Extremely quickly. New models come out every day and are implemented in downstream modules by tomorrow. Make sure you’re ok with this speed and match the pace. Something you can do before you do PRs is to follow issues on the repo, and follow the repo itself so you get a sense for how quickly things move/are approved. If you’re into fast-moving projects, jump in. Otherwise, pick one that moves at a slower cadence.
5. The LLM ecosystem is currently bifurcated between HuggingFace and OpenAI compatibility: An interesting pattern has developed in my development work on open-source in LLMs. It’s become clear to me that, in this new space of developer tooling around transformer-style language models at an industrial scale, you are generally conforming to be downstream of one of two interfaces:
a. models that are trained and hosted using HuggingFace libraries and particularly the HuggingFace hub as infrastructure.
b. Models that are available via API endpoints, particularly as hosted by OpenAI.
If you want to be successful in this space today, you as a library or service provider have to be able to interface with both of these.
6. Sunshine is the best disinfectant. As the recent xz issue proved, open code is better code and issues get fixed more quickly. This means, don’t be afraid to work out in the open. All code has bugs, even yours and mine, and discovering those bugs is a natural process of learning and developing better code rather than a personal failing.
We’re looking forward to both continuing our contributions, upstreaming them and learning from them as we continue our product development work.
Read the whole publication and subscribe to future ones on the Mozilla.ai blog.
We have long been excited to improve the existing Firefox sidebar and strengthen productivity use cases in the browser. We are laying the groundwork for these improvements, and you may have seen early work-in-progress in our test builds and in Nightly behind preferences (Firefox Nightly with vertical tabs and Firefox is experimenting with a sidebar in Nightly).
What to expect next?
In the near future, we will be landing foundational sidebar features in Nightly to ensure parity with the existing sidebar and make the new experience more useful and easy to use. Many of the ideas we are exploring are based on your suggestions in Mozilla Connect. You’ve shared how you imagine productivity, switching between contexts, and juggling multiple tasks could improve in Firefox, and we’ve listened.
We are encouraged by your positive feedback on our early concepts, and we look forward to engaging with the community and hearing more about what you think once sidebar features are ready for testing. We will announce feature readiness for feedback in the follow-up blog posts and on Connect.
In the meantime, if you have questions or general feedback, please engage with us on Mozilla Connect.
Niklas added RTL support for the new screenshots UI component (currently enabled by default in Nightly)
Shout-out to Paul Bone who landed some changes to mozjemalloc, reducing the number of calls to VirtualAlloc. This change caused various improvements (3.5% – 5%) to both Speedometer 2 and Speedometer 3 subtests, with no measurable regression in memory usage!
The Search team enabled Search Config V2 in Nightly, and this has shown multiple improvements in startup time, by at least 3%!
Work continues integrating the new Rust backend and improving exposure metrics.
Daisuke has exposed icons mime-types along with blobs, from the offline Suggest backend. Bug 1882967
Drew has fixed a problem with the recording of exposure metrics in experiments. Bug 1886175
Clipboard result
Karandeep has fixed a problem with empty searches returning no results in Tab, History and Bookmarks Search Mode, and a problem with the clipboard result persisting when switching through multiple empty tabs. Bug 1884094, Bug 1865336
SERP categorization metrics
Stephanie and James have fixed multiple issues in this area.
Categorization metric has been enabled in Nightly.
Search Config v2
Standard8 and Mandy have fixed multiple issues in this area.
Work continues as Config v2 has been enabled in Nightly.
Frecency ranking
Marco has changed frecency recalculation to accelerate when many changes have been made from the last recalculation. This should help with large imports. Bug 1873629
Marco has corrected a schema migration mistake, preventing recalculation of frecency for not recently accessed domains. That caused autofill of domains to not work as expected in the Address Bar for Firefox 125 Nightly (and first week of Beta). Bug 1886975
Other fixes
Drew has corrected visual alignment of weather results. Bug 1886694
Dale has corrected visual alignment of rich search suggestions. Bug 1871022
To update the tokens files (tokens-shared, tokens-platform, tokens-brand), you’ll need to modify the design-tokens.json file and then run ./mach npm run build –prefix=toolkit/themes/shared/design-system
At Mozilla, we know we can’t create a better future alone, that is why each year we will be highlighting the work of 25 digital leaders using technology to amplify voices, effect change, and build new technologies globally through our Rise 25 Awards. These storytellers, innovators, activists, advocates, builders and artists are helping make the internet more diverse, ethical, responsible and inclusive.
This week, we chatted with Marek Tuszynski, an artist and curator that is the Executive Director and co-founder of Tactical Tech, a program dedicated to supporting initiatives focused on promoting better privacy and digital rights. We talked with Marek about his travels abroad shaping his career, what sparks his inspiration and future challenges we face online.
So the first question that I had that I wanted to ask you about this is very straightforward, but what initially inspired you to co-found Tactical Tech? What was the first thing that made you really want to start the work that you do?
Marek Tuszynski: Things were not looked at the ways that I thought it’s important to look at them, especially technical things that have been around for over 20 years now. But the truth is, it was actually more excitement. Excitement that there’s such a massive opportunity, such a massive chance for many different people — actors, places, nations — to do things different and outside of the constraints that they are in, where they are at the time, and so on. I worked internationally at the time in sub-Saharan Africa and Southeast Asia and was just thinking that a lot of tech is being damned there in these places — I’m also from Eastern Europe, so we’ve never seen the leading edge of the technology, we’ve seen the tail if we’re lucky if the censorship allowed. So I just wanted to use technology as not only an opportunity that I have been kind of given by chance — it just happened I was in the right place in the right time — but also to bring it, and to co-develop it and do things together with people. My focus early on was with open source with software, and that was the driving force behind how we think about which technology is better for society, which is a more right one, which gives you more freedoms, not restrict them, and so on, etc. The story now, as we know, it turned kind of dark, but the inspiration was fascination with the possibilities of technology in terms of the tool for how we can access knowledge and information, the tool for how we can refine the way we see the world. It’s still there, and I think was there at the very beginning, and I think that’s a major force.
You mentioned some of the traveling that you did. I’m very much of the belief that traveling is one of the best ways for us to learn. How much did the traveling and the places that you’ve been to and that you’ve seen influence or impact the work that you did and give you a bigger perspective on some of the things that you wanted to do?
That’s interesting because I come from the art background and one of my fascinations was a period in history of ours where some of the makers spent some of their time when they were learning on traveling. To go and visit other artists or studios, vendors and makers, etc., to see how they do things because there was no other way of information to travel, and for me that was very important. But I think you are right. It is not cool to talk about traveling these days, because travel also means burning fossil fuels and all this kind of stuff — which is unfortunately true, but you can do other travel, I’m doing a lot of sailing these days. But the initial traveling for me, coming from an entirely restricted part of the world and where I was growing up, I actually thought, “I’m never going to travel” in my mind. This is like something I’m going to read in the books, see on films, but never experience because I can’t get a passport. I couldn’t get the basic rights to leave the border that I was constrained with. So the moment I could do that I did it, and I practically never come back. I’ve left the place I’m from 35 years ago.
The question that you’re asking is very important because travel teaches you a lot of things, and you become much more humble. Your eyes and brain and heart opens up much more. And you see that the world is unique, that people around you are unique — you’re not that unique yourself and there’s a lot to learn from that. Initially, when you travel, you have this arrogance — I had this arrogance at least — that I’m going to go to places, learn them, understand them, and turn into something, etc. And then you go, and you learn, and you never stop. Learning is endless, and that’s the most fascinating part. But I think that the biggest privilege was to meet people and meet them on their own ground with their own ideas about everything. And then you confront yourself and rip the way you frame things because you just come from a place with ideas that somebody else put into your education system. So for me, yeah, it (traveling) worked in a way. And it’s not necessarily the travel in the physical space that we need. Now you can do it virtually like we have the conversation, and you get to know people and, you travel in some way. You may not see the actual architecture of the space you are in, but you are seeing “Okay, this is a person coming from somewhere with a certain set of ideas, questions, and so on, etc.” You look at them and think how we can have the conversation knowing that we come from very different places. Travel gives you that.
When it gets to like some of the ideation process, what sparks the inspiration for the experiences you try to create? Is there any research or data that you look at? Are there just trends that you look at to get inspired by? What kind of like starts that?
There’s a mixture. I think we’re probably the least analyzing organization. Even if it’s a trend or some kind of mainstream stuff with the social media or all media, etc., it’s too late. I think for me personally, it’s always observing what’s being talked about. With AI, it’s what aspects of AI actually are being totally omitted. There’s a lot of focus now, for example, on elections and the visible impact of the AI, so how we can amplify this information, confusion and basically deteriorate trust into what we see, what we hear, what we read. And it’s super important. People are going to learn that very quickly.
I think what is happening is the invisible part, where businesses that are interested in influencing political or non-political opinions around issues that are critical for people will be using AI for analyzing the data. For hyper fast profiling of people in much more clever ways of addressing them with more clever advertisements, in that it won’t necessarily be paid — it doesn’t have to be. Or even how you design certain strategies, etc. that can be augmented by how you use AI. And I think this is where I will be focusing on rather than talking about that the deepfakes which we’ve done already. But to the core of the question you asked about how we have topics that we focus on, from the first day of Tactical Tech, we’ve always based our work on partners, collaborators and people that we work with — and often that we are invited to work with like a group of people or institutional organizations, etc. And good listening is for me part of the critical research. So instead of coming in a view and ideas of research questions, we listen to what questions are already there. Where the curiosity is, where the fears are, where the hopes are, and so on, and sometimes start to build backwards toward and think about what you can bring from the position you occupy.
Is there one collaboration or organization that you’ve worked with before that you felt was really impactful that you’re the most proud of?
There are hundreds of those (laughs). We had this group of people from Tajikistan — many people don’t know what Tajikistan is. And they were amazing. They were basically like a sponge, just sucking everything in and trying to engage with the culture cross between us and them and everybody else and people from probably other countries and so on — it was massive. But everybody was positive and trying to figure out some kind of common language that is bizarre English being mixed with some other languages, and so on. And that first encounter turned into a friendship and collaboration that led them to be the key people that brought the whole open source tool to the school system in Tajikistan, and so on, etc. I think that was one of these examples where it was very positive, encouraging.
We do a lot of collaboration. So we have hundreds of partners now, especially on our educational work. And I think the most successful series was with a number of groups in Brazil that we collaborated with because they really took the content and the collaboration to the next level and took ownership of that. And for me, the ideal scenario over the work we do is that we may be developing something on the stage together, but there should be a moment when we disappear from the stage and somebody else take that stage. And that’s what happened. And that’s just beautiful to see. And when somebody tells you about this product that is amazing, and they don’t even know that you were part of that, that is the best compliment you can get.
<figcaption class="wp-element-caption">Marek Tuszynski at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
What do you think is the biggest challenge we face in the world this year on and offline? How do we combat it?
I think people have different challenges in different places. The first thing that we are going to launch is a series of election influence situation rooms, which is just kind of a creative space that has the front of the house and back of the house that you would like to mount around some of the elections that are happening — like U.S. or European Parliament, or many other elections. What we would like to showcase and kind of demystify is not only the way we elect people, but how much the entire system works or doesn’t work.
And what we’re trying to illustrate with this project “the situation rooms” is to unpack it and show how important, for a lot of entities, confusion is. How important polarization is, how important the lack of trust towards specific formats of communication are, or how institutions fail, because in this environment it is much easier to put forward everything from conspiracy theories to fake information, but it also makes people frustrated. It makes people to be much more black and white and aligning themselves with things that they would not align with earlier. I think this is the major thing that we are focusing on this year. So the set of elections and how we can get people engaged without any paranoia and any kind of dystopian way of thinking about it. It helps ourselves in a way to build apparatus for recognizing this situation we are in. And then let’s build some methods for what we need to know, to understand what is happening and then how that can be useful for democratic person elections, but how also it can be extremely harmful.
What do you think is one action that everyone should take to make the world and our lives online a little bit better?
Technology is the bridge. Technologies open the channel of communications, so on, etc. Use technology for that. Don’t focus on yourself as much as you can focus on the world and other people. And if technology can help you to understand where they’re coming from, what the needs are and what kind of role you can play from whatever level of privilege you may have, use it. And the fact that you may use better technologies and some people have access to it already, that’s a certain kind of privilege that I think we should be able to share widely.
You use technology to engage other people who don’t want to engage. Who lost trust. Don’t give up on them. Don’t give up on people on the other side, those voting for people you don’t have any respect. They are lost. And part of the reason they are lost is the technology they’re using.
How it is challenging the information and making them believe in things that they shouldn’t be believing in and that they probably wouldn’t if that technology didn’t happen. I think we passed this kind of libertarian way of using technology for individual good that’s going to turn everything into a better world. We have proven itself wrong many times by now.
We started Rise25 to celebrate Mozilla’s 25th anniversary, what do you hope people are celebrating in the next 25 years?
I think Rise 25 was fantastic because it was nice to see all the kinds of people. The 25 people who are so different in such different ways thinking about tech and ideas, and so on, etc., and so diverse in many ways that you don’t see very often. And it gave people the space to actually vocalize what they think and so on. And that was definitely unique. So I think Mozilla plays a specific role in this kind of in-between sector thing where it’s a corporation in a city in San Francisco that builds tools, but it’s also a foundation.
Mozilla has unique access to people around the world that do a lot of creative work around technology. And I think that should be celebrated. I don’t think there’s enough of that. Usually people are celebrated for what they achieve with technology, usually making a lot of money, and so on, etc., there’s very little to talk about the technology that has positive impact on society in the world. And I think Mozilla should be touching and showcasing that, and I think there are plenty of things that can be celebrated.
What gives you hope about the future of our world?
You know, it’s going to be okay. Don’t worry. But we are going to see people that’ll be happy and there will be people that separate. I think the more we can do now for the next generations of people that are coming up now, the better. And if you’re lucky to live long, you may feel proud for what you’ve been doing — focus on that, rather than imagining or picturing some future machine.
As a web engine, Servo embeds another engine for its script execution capabilities, including both JavaScript and Wasm: SpiderMonkey.
One of the goals of Servo is modularity, and the question of how modular it really was with regards to those capabilities came up.
For example, how easy would it be for Servo to use Chrome’s V8 engine, or the next big script engine?
To answer that question, we’ve written a short report analysing the relationship between Servo and SpiderMonkey.
The problem
Running a webpage happens inside the script component of Servo; the loading process starts there, and the page continues to run its HTML event loop there.
By its very nature, executing a script from within a webpage requires an integration between the script engine and the web engine that surrounds it.
Anything shared between the two, including the DOM itself and any other construct calling from one into the other, needs to be integrated somehow, and much but not all of that is done via WebIDL.
For example, an integration area that is left for web and script engines to implement as they see fit is that with a garbage collector (see example in Rust for SpiderMonkey).
The need to integrate can result in tight coupling, but the classic ways of increasing modularity — abstractions and interfaces — can be applied here as well, and that is where we found Servo lacking in some ways, but also on the right path.
Servo already comes with abstractions and interfaces for a large surface area of its integration with SpiderMonkey, providing ease of use and clarity while preserving boundaries between the two.
Other parts of that integration rely on direct, and unsafe, calls into the low-level SpiderMonkey APIs.
The solution
The low-hanging fruit consists of removing these direct calls into low-level SpiderMonkey APIs, replacing them with safe and higher-level constructs.
Work on this has started, through a combination of efforts from maintainers and the enthusiasm of community members: eri, tannal, and Taym Haddadi.
These efforts have already resulted in the closing of several issues:
Note that the safer higher-level constructs that replace low-level SpiderMonkey API calls are still internally tightly coupled to SpiderMonkey.
By centralizing these calls, and hiding them from the rest of the codebase, it becomes possible to enumerate what exactly Servo is doing with SpiderMonkey, and to start thinking about a second layer of abstraction: one that would hide the underlying script engine.
An existing, and encouraging, example of such a layer comes from React Native in the form of its JavaScript Interface (JSI).
Call to action
If you are interested in contributing to these efforts, the issues below are good places to start:
I missed Southern California Linux Expo this year. Normally I can think of a talk to do, but between work and [virus redacted] I didn’t have a lot of conference abstract writing time last fall. I need some new material anyway. The talks that tend to do well for me there are kind of a mix of tips for doing weird stuff.
I didn’t really have anything good to submit last fall, but this year I am building up a bunch of miscellaneous Linux stuff similar to what has worked for me at SCALE before. Because of the big Fediverse trend, the search quality crisis, the ends of third-party cookies and Twitter, and enshittification in general, it seems like there’s a lot more interest in redoing your blog—I know I have been doing it, so that’s what I’m going to see if I can come up with something on for next SCALE. But I’m not going to use a blog software package. I’m more comfortable with a mix of different stuff. This blog is now mainly done in Pandoc, auto-rebuilt by Make, and has a bunch of scripts in various languages, including shell, Perl, Python, and even a little bit of Lua now.
<figcaption>protip: use cowsay(1) to alert the user to errors in Makefile before restarting</figcaption>
I don’t really expect anybody to copy this blog, more outdo it by getting the audience to realize how much you can now do with the available tools. I’m not going to win any design prizes but with modern CSS I can make a reasonable responsive layout and dark/light modes. And yes you can make a valid RSS feed in GNU Make.
The feature I just did today is the similar posts in the left column. Remember that paper about how you can measure the similarity between two pieces of text by seeing how well they compress together? “Low-Resource” Text Classification: A Parameter-Free Classification Method with Compressors - ACL Anthology This is Python code for rating similarity of chunks of text. Check it out in the left column, you can now follow the links to similar blog posts.
Next I will probably try stuff like Fediverse-powered comments, some kind of search feature, LLM training set poisoning, some privacy and p2p features, and maybe something else. A lot of what I’m doing here will be possible to translate into other environments, and should be portable to people’s favorite blog software.
Are they answering accurately? People might be under- or over-reporting their use of ad blockers. Under-reporting because they don’t want to admit to free-riding on ad-supported sites, or over-reporting because install an ad blocker is now one of the typical Internet tips you’re supposed to do, like not re-using passwords and installing software updates when they come out. People might be trying to look more responsible. When the FBI says you should be running an ad blocker to deal with fake search ads, that puts a certain amount of pressure on people.icymi: Ad Blockers and the Four Currencies by Lars Doucet.
Are they using an honest blocker with real protection? The ad blocking category has a lot of scams, including adware and paid allow-listing, so most of the people saying yes are not getting the blocking they think they are. (The company that owns the number one ad blocker makes a business out of selling exceptions from blocking. Senator Ron Wyden wrote a letter to the FTC asking them to investigate the ad-blocking industry back in 2020, but no action as far as I know. In the meantime you can check your ad blocker using a tool from the EFF.)
How much of their browsing is on a protected browser or device? It’s a lot easier to install an ad blocker on desktop than on mobile, and people have different habits.
The second most newsworthy part of the new Censuswide survey is why people say they’re using an ad blocker. Protect online privacy is now the number one reason, with block ads and speed up page loads coming in after that. I’ll leave the most newsworthy part to the end. I know, I know, the surveillance advertising people are going to reply with something like, yeah, right, these ad blocker users are just rationalizing free-riding on ad-supported sites, like Napster users making bogus fair use arguments instead of paying for CDs back when that was a thing. In order to understand this survey we have to put it in context with other research. Compare to Turow et al. on attitudes to cross-context tracking, and to an IAB Europe study that found only 20% of users would be happy for their data to be shared with third parties for advertising purposes.
It looks like the privacy concerns are real for a significant subset of people, and part of the same trend as popular US State Privacy Legislation. Different people have different norms around ad personalization, and if people can’t get companies to comply with those norms they will get the government to do something about it. For companies, adjusting to privacy norms doesn’t just mean throwing privacy-enhancing technologies (PETs) at the problem. Jerath et al. found similar levels of perceived privacy violations for on-device ad personalization as for old-fashioned cookie-based tracking. PETs have different mathematical properties from cookies, but either don’t address other problems or make them worse.
Companies deploying PETs are asking users to trust that they will do complicated math honestly—but they’re not starting from a position of trust. When users have the opportunity to evaluate the companies’ honesty in a way they do understand, the companies don’t measure up. Most people can look at an online map of their neighborhood and spot places where a locksmith isn’t. And it’s easy to look up a person on a social site and see where there are enough profiles that not all of them can be real.
<figcaption>screenshot of several fake Facebook profiles, all using the same two photos of retired US Army General Mark Hertling</figcaption>
The biggest problem with PETs will be that the Big Tech companies do both easy-to-understand activities—like scams, fake profiles, and union busting—and hard-to-understand activities, like PET math. I see you served me scam ads and a map with fake companies in my neighborhood, but I totally trust your math to protect my privacy — no one ever If you don’t know if the PET math is honest, but you can see the same company acting dishonestly in other ways, then it’s hard to trust the PET math. (Personally I think the actual PETs are probably legit, but they’re being rolled out as part of a larger program to squeeze out legit publishers and other smaller companies.)
<figcaption>In AIC polls, confidence in Amazon, Meta, and Google has fallen since 2018.</figcaption>
Doc Searls called ad blocking the biggest boycott in world history back in 2015. Ad blocking looks like a response to creepy practices (or perceived privacy violations if that works better for you) and those practices are part of a more general scam culture crisis. Tressie McMillan Cottom writes,read the whole thing
Scams weaken our trust in social institutions, but their going mainstream—divorced from empathy for the victims or stigma for the perpetrators—means that we have accepted scams as institutions themselves.
I can’t see any one big policy solution for surveillance advertising, tech oligopolies, or the broader scam culture problem. All of that stuff would have to change in order to move the ad blocking numbers. It’s going to take a variety of approaches, maybe including a surveillance advertising ban, maybe a Pigovian tax on databases containing PII, maybe breaking up Big Tech firms. So far the most promising approach seems to be state laws with private right of action, which is one of the reasons I’m so optimistic about Washington State’s My Health My Data Act. My experience on a jury (not an ad-related case) was the most productive meeting I have been in since I came to California. If surveillance advertising issues can grind their way through a few jury trials, where lawyers have an incentive to explain what’s going on in an accurate, comprehensible way, then both surveillance marketers and privacy nerds will be able to reset how we approach this stuff based on more common sense.
At Mozilla, we know we can’t create a better future alone, that is why each year we will be highlighting the work of 25 digital leaders using technology to amplify voices, effect change, and build new technologies globally through our Rise 25 Awards. These storytellers, innovators, activists, advocates, builders and artists are helping make the internet more diverse, ethical, responsible and inclusive.
This week, we chatted with creator Rachel Hislop, a true storyteller at heart that is currently the VP of content and editor-in-chief at OkayAfrica. We talked with Rachel about the ways the internet allows us to tell our own stories, working for Beyoncé and what’s to come in the next chapter of her career.
So the first question I have is what was your favorite Beyoncé project to work on? I want to know. Also, what’s your favorite Beyoncé album?
I’ll say that my favorite project to work on was definitely Lemonade. It was just so different from anything that had ever existed. It was so culturally relevant. It was well-timed. It was honest and just really beautiful. You can sometimes be jaded by the work when you’re too close to it, and I think that’s across the board in any industry, but there was never a moment of working on that project that I didn’t understand and appreciate just how beautiful everything was. It was really just like, all of you people that I see at work every day, this came out of your minds? And then, it was just a lot of love, and it was a really important time in culture, I think. And I really enjoyed being part of that.
My favorite Beyoncé album … I don’t know that I can answer that because every part has had a very important impact on my life. I had The Writings on the Wall on a cassette tape that I used to play in my little boombox. And Dangerously in Love, I was in high school and experiencing little crushes for the first time. The albums grew. I met Sasha Fierce when I’m in college and learning the dualities of self when I’m away from home, and so on and so forth. So, it’s hard to pick a favorite when each of those moments were so tied to different portions of my life.
I’m curious to know what types of stories pull you in and influence the work that you do as a writer?
It’s living, honestly. I’m a really curious person, and I think all the best writers are. It’s even weird calling myself a writer sometimes because so much of what I write right now is just for me, and projects that I really believe in. It’s really just the curiosity. I want to know how everything went. How did you get here? What inspired you? I’m good for going out alone and sitting next to a stranger and then learning their whole life story because I am just truly interested in people and there is no parallel in lived life. I also love reading fiction. I am not the girl that’s like, “yeah, self-help books and self-improvement” and things like that. I want to fully escape into a story. I want to be able to turn my brain on and imagine things and fully detach and escape from this world. And then I love reading old magazine articles from when people were allowed to have long, luxurious deadlines and follow subjects for a really long time. I remember this article that they would make us read in journalism school, which was Frank Sinatra has a cold, and I love that voyeurism journalism where if you can’t get to the subject, you’re talking about the things around them. Everything is so interesting to me. I also love TikTok. I learn so much. I think that it’s a really valuable form of storytelling. In short-form, I think it’s really hard — it’s harder than people give a lot of these creators credit for. My grand hope is that those small insights through those short videos are peaking curiosity and sending people on rabbit holes to go discover and read and just be deeper into the internet. I remember back in college there was this internet plugin called stumbled upon and it would roulette the internet and land on these random pages and learn things. That is how my brain is always processing. I’ll see something that’ll interest me and then be like, “I want to know more about that.”
<figcaption class="wp-element-caption">Rachel Hislop at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
You’ve been in the content media space for a while. What do you think is the biggest misconception people have about working in this space?
You know that saying that if you do what you love every day, you’ll never work a day in your life? I think it’s that. There is a pressure that you feel when you are following your actual passion. This is not just my job, this is what I like to do in my free time, this is what I think is important. This is what I feel like I was born to do, right? To storytell. And every day, it feels like work. And it feels even harder than work because it feels like a calling. From the outside, I’m sure people are like, “Oh, you get to do this cool stuff. You get to talk to all these interesting people. You get to talk about the things that you care about.” But there is truly a pressure to document this stuff in a way that pays homage to everyone and everything that came before it that solidifies its place in history to come, and to handle things with delicacy and care and importance. There’s just so many layers to it. So, it’s never just about the one thing that you love. It’s about the responsibility that you now have to this thing because you love it. And when you’re working in culture spaces specifically, there is always someone that you have to give their flowers to for you to be able to do the work that you’re doing, but you also have to be forward. You have to look forward and innovate, while you are also honoring what has come before. And there can be a misconception about it like it being easy. Or “I can do that” — we see a lot of that with interviewers I love, where people say, “Shannon Sharpe didn’t ask the right questions. Insert podcaster here who got a really great hit and didn’t ask the right questions.” It’s because we’ve lost the art because people see the end product, they believe that it is easy. And they forget that everything that journalists are doing is in service to the audience and not in service to themselves. And we’re seeing this really weird landscape now where everyone is in service to themselves and to their own popularity and to growing their own audiences, but then they don’t serve those audiences with ethics. That for me is the misconception — that it’s just so easy, anyone could do it. Now everyone is doing it, and they’re wondering where the value is and the premium stories and all of these things like that.
Who are the Black women you’re inspired by and the people you go to when you’re faced with so many of the challenges Black people have in the content/media industry?
I am very intentional about friendships, and I treat my friends like extensions of myself. They’re the board of directors for my life, and these are often friends from college. I think people really discount the friends that you make in your first big girl job and how you’re learning everything together. Those have become the people that I call on throughout my career, who I call on to collaborate with projects, who I call on when things are falling apart. I’ve been just so blessed to have those people in my life as my board of directors for all things. And I serve as the same for them. I am going to tell you the truth: I don’t know that I’ve met a Black woman that I’m not inspired by. I truly am just so in awe of so many women.
I made a practice after the pandemic of being like, “I don’t want these people who I like online to just be my online friends.” I wanted to meet these people in real life. I started just DM’ing people and being like, “Hey, we’ve been on here a while. Can we grab lunch?” And then just continuing that connection in person has been so, so fantastic.
I do also want to shout out Poynter Institute. I did a training with them in 2019 right before the pandemic for women in leadership positions in newsrooms. When I tell you it was a week-long, intensive, seven days we were in a classroom … it was like therapy for work in a way that I didn’t know I needed, and I didn’t know was available to any of us. We built such strong bonds, even though some people worked at competing publications. But when we put all of that aside, it was just women of all ages and all backgrounds who were working in an industry and really, really cared about the work they were doing and wanted to be their best. And through that group of people, I have just made true, lifelong friends. When things were falling apart in 2020, I was calling on my cohort members and building deep, deep connections from there.
What do you think is the biggest challenge we face in the world this year on and offline? How do we combat it?
There’s so much happening in the world that I think the one thing that I can say that continues to be dangerous is misinformation online. I’m going to speak specifically about Palestine. We see the power of storytelling from the front lines in a way that we have never witnessed before with any conflict, right? And we’ve seen that unfold into just horrors that we would never know were happening if we did not see it coming from the front lines. I just give kudos to the journalists that are on the ground and the people who have become journalists by force who have documented us through situations that we couldn’t even fathom. Even if we tried, we couldn’t fathom what it’s like to work through that. And while that is really helpful and illuminating the evils of the world, the other side of that there’s so much misinformation because everyone is trying to be fast to discredit what we’re seeing with our own eyes and framing that used to be able to take place is not available anymore. And I’m not going to speak to that being a political tool or otherwise, but the framing is not as readily available. I think we saw this with our election in America. Specifically, we’re in an election year — we saw this with our elections, four, eight years ago — and now as technology starts to grow and change faster than we are learning how to master it, I really do believe that misinformation is going to be one of the hardest things to combat.
I really don’t know how to combat it. Things are just changing so quickly and there’s just so much access to so much. I think the answer as it is with most things is community and people coming together to dream together. There’s not going to be a single person that solves for all of this. It’s going to take collective efforts to help make sure that we’re doing our best.
What is one action that you think everyone should take to make the world and our lives online a little better?
I think everyone can be a little bit more curious. We don’t need to trust things at face value the first time. We need to be more curious about the sources of the information that we are taking in. And it doesn’t mean that we have to be constantly engaging in combat with it. You can take things at face value and then do more research to inform yourself about all sides of a story, and I think that that’s one action that we can take in our day-to-day lives to just be better.
We started Rise25 to celebrate Mozilla’s 25th anniversary. What do you hope people are celebrating in the next 25 years?
I hope we get those flying cars that we were promised (laughs). But truly, I hope that in 25 years, we are celebrating the earth more. I really do hope that we’re celebrating the earth still housing us and that we’re all just being a little kinder and more thoughtful in the ways that we’re engaging with nature and ourselves, and that people are spending a little bit more time reconnecting with who they are offline.
What gives you hope about the future of our world?
I mentor with the Lower East Side Girls Club, which is a nonprofit here in New York, and we do a mentee outing once a month. The girls are aged middle school through high school, and they are so bright and so well-rounded and smart, but they’re also funny, and they have great social cues and they think so deeply about the world and they’re really compassionate. They don’t allow the things that used to trip me up and trip me and my peers up as like middle schoolers, like they’re so evolved past that. Every time that I think that mentoring means me teaching, I realize that it really means me learning, and when I leave those girls, I’m like, “alright, we’re going to be okay.” They give me some hope.
As an industry, generative AI is moving quickly, and so requires teams exploring new ideas and technologies to move quickly as well. To do so, we have been using Gradio, a low-code prototyping toolkit from Hugging Face, to spin up experiments and experiences. Gradio has allowed us to validate concepts through prototyping without large investments of time, effort, or infrastructure.
Although Gradio has made the development phase of prototyping easier, the design phase has been largely the same. Even with Gradio, designers have had to create components in Figma, outline expected user flows and behaviors, and hand off designs for developers in the same way they have always done. While working on a recent exploration, we realized something was needed: a set of Figma components based on Gradio that enabled designers to create wireframes quickly.
Today, we are releasing our library of design components for Gradio for others to use. The components are based on version 4.23.0 of Gradio and will be available through our Figma profile: Mozilla Innovation Projects, https://www.figma.com/@futureatmozilla. We hope these components help teams accelerate their discovery and experimentation with ML and generative AI.
Thanks to Amy Chiu and Anais Ron who created the components and to the Gradio team for their work. Happy designing!
What’s Inside Gradio UI for Figma?
Because Gradio is an ever-changing prototyping kit, current components are based on version 4.23.0 of Gradio. We selected components based on their wide array of potential uses. Here is a list of the components inside the kit:
To start using the library, follow these simple steps:
Access the Library: Access the component library directly by visiting our public Figma profile (https://www.figma.com/@futureatmozilla) or by searching for “Gradio UI for Figma” within the Figma Community section of your web or desktop Figma application.
Explore the Documentation: Familiarize yourself with the components and guidelines to make the most out of your design process.
Connect with Us: Connect with us by following our Figma profile or emailing us at innovations@mozilla.com
If you’ve been wondering how the work to turn K-9 Mail into Thunderbird for Android is coming along, you’ve found the right place. This blog post contains a report of our development activities in March 2024.
We’ve published monthly progress reports for a while now. If you’re interested in what happened previously, check out February’s progress report. The report for the preceding month is usually linked in the first section of a post. But you can also browse the Android section of our blog to find progress reports and release announcements.
Fixing bugs
For K-9 Mail, new stable releases typically include a lot of changes. K-9 Mail 6.800 was no exception. That means a lot of opportunities to accidentally introduce new bugs. And while we test the app in several ways – manual tests, automated tests, and via beta releases – there’s always some bugs that aren’t caught and make it into a stable version. So we typically spend a couple of weeks after a new major release fixing the bugs reported by our users.
K-9 Mail 6.801
Stop capitalizing email addresses
One of the known bugs was that some software keyboards automatically capitalized words when entering the email address in the first account setup screen. A user opened a bug and provided enough information () for us to reproduce the issue and come up with a fix.
Line breaks in single line text inputs
At the end of the beta phase a user noticed that K-9 Mail wasn’t able to connect to their email account even though they copy-pasted the correct password to the app. It turned out that the text in the clipboard ended with a line break. The single line text input we use for the password field didn’t automatically strip that line break and didn’t give any visual indication that there was one.
While we knew about this issue, we decided it wasn’t important enough to delay the release of K-9 Mail 6.800. After the release we took some time to fix the problem.
DNSSEC? Is anyone using that?
When setting up an account, the app attempts to automatically find the server settings for the given email address. One part of this mechanism is looking up the email domain’s MX record. We intended for this lookup to support DNSSEC and specifically looked for a library supporting this.
A user in our support forum reported a strange error message (“Cannot serialize abstract class com.fsck.k9.mail.oauth.XOAuth2Response”) when using OAuth 2.0 while adding their email account. Our intention was to display the error message returned by the OAuth server. Instead an internal error occurred.
We tracked this down to the tool optimizing the app by stripping unused code and resources when building the final APK. The optimizer was removing a bit too much. But once the issue was identified, the fix was simple enough.
Crash when downloading an attachment
Shortly after K-9 Mail 6.800 was made available on Google Play, I checked the list of reported app crashes in the developer console. Not a lot of users had gotten the update yet. So there were only very few reports. One was about a crash that occurred when the progress dialog was displayed while downloading an attachment.
The crash had been reported before. But the number of crashes never crossed the threshold where we consider a crash important enough to actually look at.
It turned out that the code contained the bug since it was first added in 2017. It was a race condition that was very timing sensitive. And so it worked fine much more often than it did not.
The fix was simple enough. So now this bug is history.
Don’t write novels in the subject line
The app was crashing when trying to send a message with a very long subject line (around 1000 characters). This, too, wasn’t a new bug. But the crash occurred rarely enough that we didn’t notice it before.
The bug is fixed now. But it’s still best practice to keep the subject short!
Work on K-9 Mail 6.802
Even though we fixed quite a few bugs in K-9 Mail 6.801, there’s still more work to do. Besides fixing a couple of minor issues, K-9 Mail 6.802 will include the following changes.
F-Droid metadata
In preparation of building two apps (Thunderbird for Android and K-9 Mail), we moved the app description and screenshots that are used for F-Droid’s app listing to a new location inside our source code repository. We later found out that this new location is not supported by F-Droid, leading to an empty app description on the F-Droid website and inside their app.
We switched to a different approach and hope this will fix the app description once K-9 Mail 6.802 is released.
Push not working due to missing permission
Fresh installs of the app on Android 14 no longer automatically get the permission to schedule exact alarms. But this permission is necessary for Push to work. This was a known issue. But since it only affects new installs and users can manually grant this permission via Android settings, we decided not to delay the stable release until we added a user interface to guide the user through the permission flow.
K-9 Mail 6.802 will include a first step to improve the user experience. If Push is enabled but the permission to schedule exact alarms hasn’t been granted, the app will change the ongoing Push notification to ask the user to grant this permission.
In a future update we’ll expand on that and ask the user to grant the permission before allowing them to enable Push.
What about new features?
Of course we haven’t forgotten about our roadmap. As mentioned in February’s progress report we’ve started work on switching the user interface to use Material 3 and adding/improving Android 14 compatibility.
There’s not much to show yet. Some Material 3 changes have been merged already. But the user interface in our development version is currently very much in a transitional phase.
The Android 14 compatibility changes will be tested in beta versions first, and then back-ported to K-9 Mail 6.8xx.
Releases
In March 2024 we published the following stable release:
So you’ve found yourself a plot that looks like this:
You suspect this has something to do with a code change because, wouldn’t you know it, the sharp decline starts around Feb 22 and we released Firefox 123 on Feb 20. But where do you go from here? Here’s a step-by-step of how I went from this plot arriving in Slack#data-help to finding the bugfix that most likely caused the change:
1. Ensure this is actually a version-specific change
It’s interesting that the cliff in the plot happened near a release day, and it’s an excellent intuition to consider code releases for these sorts of sea-changes in data volume or character. But we should verify that this is the case by grouping by mozfun.norm.truncate_version(app_version, 'major') AS major_version which in our case gives us:
Sure enough, in this case the volume cliff happens entirely within the Firefox 123+ colours. If this isn’t what you get, then it’s somewhat less likely that this is caused by a client code change and this guide might not help you. But for us this is near-certain confirmation that the change in the data is caused by a code change that landed in Firefox 123… but which one?
( This is where I spent a little time checking some frequent “gotcha” changes that could’ve happened. I checked: was it because data went from all-channel to pre-release-only? (No, the probe definitions didn’t change and the fall isn’t severe enough for that (would look more like an order of magnitude)) Was it because specific instrumentation within the group happened to expire in Fx123? (No, the first plot is grouped by specific probe, and all of the groups shared the same shape as their sum) Was it an incredibly-successful engagement-boosting experiment that ended? (No, there haven’t been any relevant experiments since last July) )
2. Figure out which Nightly builds are affected
Firefox Desktop releases new software versions twice a day on the Nightly channel. We can look at the numbers reported by these builds to narrow down what specific 12h period the code landed that caused this drastic shift. Or, well, you’d think we could, but when you group by build_id you get:
Because our Nightly population isn’t randomly distributed across timezones, there are usage patterns that affect the population who use which build on which day. And sometimes there are “respins” where specific days will have more than 2 nightlies. And since our Nightly population is so small (You Can Help! Download Nightly Today!), and this data is a little sparse to begin with, little changes have big effects.
No, far more commonly the correct thing to do is to look at what I call a “build day”. This is how GLAM makes things useful, and this is how I make patterns visible. So group by SUBSTR(build_id, 1, 8) AS build_day, and you get:
Much better. We can see that the change likely landed in Jan 18’s nightlies. That Jan 18-20 are all of a level suggests to me that it probably ended up in all of Jan 18’s nightly builds (if it only landed in one of the (normally) two nightly builds we’d expect to see a short fall-off where Jan 18 would be more like an average between Jan 17 and 19.).
Regardless of when during the day, we’re pretty sure we have this nailed down to only one day’s worth of patches! That’s good… but it could be better.
3. Going from build days to pushlog
Ever since I was the human glue keeping the (now-decommissioned) automated regression detection system “alerts.tmo” working, I’ve had a document on my disk reminding me how to transform build days or build_ids into a “pushlog” of changes that landed in the suspect builds. This is how it works:
Get the hg revisions of the suspect builds by looking through this list of all firefox releases for the suspect builds’ ids. You want the final build of the day before the first suspect build day and the final build of the final suspect build day, which in this case are Jan 17 and Jan 18, so we get f593f07c9772 and 9c0c2aab123:
This gives you a list of all changes that are in the suspect builds, plus links to the specific code changes and the relevant bugs, with the topic sentence from each commit right there for you. Handy!
4. Going from a pushlog to a culprit
This is where human pattern matching, domain expertise, organizational memory, culture and practices, and institutional conventions all combine… or, to put it another way, I don’t know how to help you get from the list of all code that could have caused your data change to the one (or more) likely suspects. My brain has handily built me a heuristic and not handed me the source code, alas. But I’ve noticed some patterns:
Any change that is backed out can be disregarded. Often for reasons of test failures changes will be backed out and relanded later. Sometimes that’s later the same day. Sometimes that’s outside our pushlog. Skip any changes that have been backed out by disregarding any commits from a bug that is mentioned before a commit that says “Backed out N changesets (bug ###)…”.
You can often luck out by just text searching for keywords. It is custom at Mozilla to try to be descriptive about the “what” of a change in the commit’s topic, so you could try looking for “telemetry” or “ping” or “glean” to see if there’s anything from the data collection system itself in there. Or, since this particular example had to do with Firefox Relay’s integration with Firefox Desktop, I looked for “relay” (no hits) and then “form” (which hit a few times, like on the word “information”, … but also on the culprit which was in the form detector code.)
This is a web view on the source code, so you’re not limited to what it gives you. If you have a mozilla-central checkout yourself, you can pull up the commits (if you’re using git-cinnabar you can use its hg2git functionality to change the revs from hg to git) and dump their sum-total changes to a viewer, or pipe it through grep, or turn it into a spreadsheet you can go through row-by-row, or anything you want. I’m lazy so I always try keywording on the pushlog first, but these are always there for when I strike out.
5. Getting it wrong
Just because you found the one and only commit that landed in a suspect build that is at all related, even if that commit’s bug specifically mentions that it fixed a double-counting issue, even if there’s commentary in the code review that explains that they expect to see this exact change you just saw… you might be wrong.
Do not be brusque in your reporting. Do not cast blame. And for goodness’ sake be kind. Even if you are correct, being the person who caused a change that resulted in this investigation can be a not-fun experience. Ask Me How I Know.
Firefox Desktop is a complex system, and complex systems fail. It’s in their nature.
And that’s it! If you have any comments, question, or (better yet) improvements, please find me on the #glean:mozilla.org channel on Matrix and I’d love to chat.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization. The following
RFCs would benefit from user testing before moving forward:
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing
label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature
need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
A quiet week; all the outright regressions were already triaged (the one biggish one was #122077, which is justified as an important bug fix). There was a very nice set of improvements from PR #122070, which cleverly avoids a lot of unnecessary allocator calls when building an incremental dep graph by reusing the old edges from the previous graph.
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
As a former JavaScript plebeian who has only been semi-recently illuminated by the suspiciously pastel pink, white and blue radiance of Rust developers, NOT having to sit in my web console debugger for hours pushing some lovingly crafted [object Object] or undefined is a blessing.
Since the release of Thunderbird 115, a big focus has been on improving the state of our automated testing. Automated testing increases the software quality by minimizing the number of bugs accidentally introduced by changes to the code. For each change made to Thunderbird, our testing machines run a set of tests across Windows, macOS, and Linux to detect mistakes and unintended consequences. For a single change (or a group of changes that land at the same time), 60 to 80 hours of machine time is used running tests.
Our code is going to be under more pressure than ever before – with a bigger team making more changes, and monthly releases reducing the time code spends on testing channels before being released.
We want to find the bugs before our users do.
Why We’re Testing
We’re not writing tests merely to make ourselves feel better. Tests improve Thunderbird by:
Preventing mistakes If we test that some code behaves in an expected way, we’ll find out immediately if it no longer behaves that way. This means a shorter feedback loop, and we can fix the problem before it annoys the users.
Finding out when somebody upstream breaks us Thunderbird is built from the Firefox code. The Firefox code, which we are not responsible for, is 30 to 40 times the size of the code we are responsible for. When something inevitably changes in Firefox that affects us, we want to know about it immediately so that we can respond.
Freeing up human testers If we use computers to prove that the program does what it’s supposed to do, particularly if we avoid tedious repetition and difficult-to-set-up tasks, then the limited human resources we have can do more things that humans are better at. For example, I’ve recently added tests that check 22 ways to trigger fetching mail, and 10 circumstances fetching mail might not work. There’s no way our human testers (great though they are) are testing all of them, but our automated tests can and do, several times a day.
Thinking through what the code should be doing Testing forces an engineer to look at the code from a different point-of-view, and this is helpful to think about what the code is supposed to do in more circumstances. It also makes it easier to prove that the code does work in obscure circumstances.
Finding existing bugs In software terms we’re working with some very old code, and much of it is untested. Testing it puts a fresh set of eyes on the code and reveals some of the mistakes of the past, and where the ravages of time have broken things. It also helps the person writing the tests to understand what the code does, a lot better than just reading the code does.
We’re not trying to completely cover a feature or every edge case in tests. We are trying to create a testing framework around the feature so that when we find a bug, as well as fixing it, we can easily write a test preventing the bug from happening again without being noticed. For too much of the code, this has been impossible without a weeks-long detour into tests.
Breaking New Ground
In the past few months we’ve figured out how to make automated tests for things that were previously impossible:
Communication with mail servers using encrypted channels.
OAuth2 authentication with mail servers.
Communication with web servers where a specific address must be used and an unencrypted channel must not be used.
Servers at any given host name or port. Previously, if we wanted to start a server for automated testing, it had to be on the local machine at a non-standard location. Now we can pretend that the server is anywhere, and using standard ports, which is needed for proper testing of account configuration features. (Actually, this was possible before, but now it’s much easier.)
These new abilities are being used to wrap better testing around account set-up features, ahead of the new Account Hub development, so that we can be sure nothing breaks without being noticed. They’re also helping test that collecting mail works when it should, or gives the error prompts we expect when it doesn’t.
Code coverage
We record every line of code that runs during our tests. Collecting all that data tells what code doesn’t run during our tests. If a block of code doesn’t run during any of our tests, nothing will tell us when it breaks until somebody uses the code and complains.
Looking at the data, you might notice that our overall number is now lower than it was when we started measuring. This doesn’t mean that our testing got worse, it actually shows where we added a lot of code (that isn’t maintained by us) in the third_party directory. For a better reflection of the progress we’ve made, check out the individual directories, especially mail/base which contains the most important user interface code.
Just setting up the code coverage tools and looking at the results uncovered several memory leaks. (A memory leak is where memory is allocated for a task and not released when it is no longer needed.) We fixed these leaks and some more that existed in our test code. We now have very low levels of memory leaking in our test runs, so if we make a mistake it is easy to spot.
Code coverage data can also point to code that is no longer used. We’ve removed some big chunks of this dead code, which means we’re not wasting time maintaining it.
Mozmill no more
Towards the end of last year we finally retired an old test suite known as Mozmill. Those tests were partially migrated to a different test suite (Mochitest) about four years ago, and things were mostly working fine so it wasn’t a priority to finish. These tests now do things in a more conventional way instead of relying on a bunch of clever but weird tricks.
How much of the code is test code?
About 27%. This is a very rough estimate based on the files in our code repository (minus some third-party directories) and whether they are inside a directory with “test” in the name or not. That’s risen from about 19% in the last five years.
There is no particular goal in mind, but I can imagine a future where there is as much test code as non-test code. If we achieve that, Thunderbird will be in a very healthy place.
Looking ahead, we’ll be asking contributors to add tests to their patches more often. This obviously depends on the circumstance. But if you’re adding or fixing something, that is the best time to ensure it continues to work in the future. As always, feel free to reach out if you need help writing or running tests, either via Matrix or Topicbox mailing lists:
We’re setting the stage for something big: a revamp of our style guide designed to make our support content not just user-friendly, but user-delightful. To get a clearer picture of the SUMO user experience, we enlisted the help of an external agency, embarking on a research project designed to peel back the layers of how users interact with our platform. The results were quite revealing. Many users, it turns out, find themselves overwhelmed by the vast amount of information available, often feeling confused and struggling to pinpoint the exact answers they’re searching for. To address this, we’re rolling out targeted improvements focused enhancements to our style guides and contributor resources, aiming to refine how we organize, categorize, and present our support content in SUMO for a smoother, more intuitive user journey.
Have questions or feedback? Drop us a message in this SUMO forum thread.
Refreshing the content taxonomy
A key takeaway from the research was the users’ difficulty in navigating our content categories. This prompted us to rethink our approach to organizing support content, aiming for a better alignment with user needs and industry best practices. This project is in full swing, and we’ll be ready to share more details with you shortly.
Auditing the Firefox content
In our effort to align our content with user needs, we’ve initiated a comprehensive audit of all Firefox support articles. This exhaustive review aims to identify areas where we can reclassify content, eliminate outdated information, and consolidate similar topics. Our goal is to ensure that every piece of information in the KB is relevant, easy to understand, and directly beneficial to our users.
We’re gearing up to share how you can contribute to this exciting initiative. Mark your calendars for the SUMO Community Meeting on Wednesday, April 10, 2024, where we’ll unveil more about this project.
Updating the article types
Using consistent content types for our knowledge base articles has many benefits including ease of navigation and improved clarity and organization, in addition to helping us create content more effectively. We are transitioning to categorizing external knowledge base articles into four types, each serving a specific purpose:
About: These articles address “What is…” questions, providing essential information to help readers understand a topic.
How-to: These articles focus on answering “How to…?” questions, guiding readers through the steps required to achieve a specific goal or procedure.
Troubleshooting: These articles assist users in identifying, diagnosing, and resolving common issues they may encounter with a product, service, or feature by addressing “How to…?” questions related to problem-solving.
FAQ: These articles contain concise answers to frequently asked questions on a single topic, which may not fit within other individual KB articles, providing a quick reference for common inquiries.
Stay tuned for additional training and documentation on these article types!
Reducing cognitive load We believe finding information should not be akin to a mental obstacle course. Focused on minimizing cognitive load, we’ve outlined a series of strategies aimed at guiding users directly to the information they need, no fuss involved. Below are the key strategies we’re implementing:
Straight to the point with inline images and icons: We’re transitioning from textual guidance to visual demonstrations. By embedding inline targeted UI captures and icons directly into the article flow, we aim to provide a more visual path for users, minimizing the need for mental translation of text into actions. But, hang on – we haven’t forgotten about making these changes work for everyone. For those using screen readers, we’re counting on you to help us ensure every image and icon comes with comprehensive alt text, making every visual accessible through sound. And on the localization front, your skills are more important than ever. We’re calling on you to assist in capturing and adding alt text to localized images, ensuring it’s accessible and resonant for every member of our global community. For details see Effective use of inline images.
Cleaner, more focused images with SUI (simplified user interfaces): To make things even clearer, we’re simplifying our product’s UI in screenshots to just the essentials. This not only makes the images easier to follow but also means they’ll stay accurate longer, even if small UI changes happen. For more info, see Simplifications.
Streamlined steps with annotated screenshots: For tasks that necessitate two or more clicks or actions on a single screen, we’re shifting to a more intuitive approach: using screenshots marked with numbered annotations. This strategy will clear away the need for multiple, similar screenshots, making instructions easier to follow while minimizing scrolling.
Keep an eye out for the updated style guides – they’re coming soon!
What this means for you
Our updates will be rolling out from Q2 to Q4 2024, and we’re thrilled to have you on board as we bring these changes to life. The kickoff is just around the corner, so stay tuned for updates! Have thoughts to share or looking to contribute? We’re all ears. Engage with us directly on this SUMO forum thread. Your feedback and involvement are crucial as we progress together.
The Rust team has published a new point release of Rust, 1.77.2. Rust is a
programming language that is empowering everyone to build reliable and
efficient software.
If you have a previous version of Rust installed via rustup, getting Rust
1.77.2 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the
appropriate page on our website.
Before this release, the Rust standard library did not properly escape
arguments when invoking batch files (with the bat and cmd extensions) on
Windows using the Command API. An attacker able to control the arguments
passed to the spawned process could execute arbitrary shell commands by
bypassing the escaping.
This vulnerability is CRITICAL if you are invoking batch files on Windows
with untrusted arguments. No other platform or use is affected.
WASI 0.2 was recently
stabilized, and Rust has begun
implementing first-class support for it in the form of a dedicated new target.
Rust 1.78 will introduce new wasm32-wasip1 (tier 2) and wasm32-wasip2 (tier
3) targets. wasm32-wasip1 is an effective rename of the existing wasm32-wasi
target, freeing the target name up for an eventual WASI 1.0 release. Starting
Rust 1.78 (May 2nd, 2024), users of WASI 0.1 are encouraged to begin migrating
to the new wasm32-wasip1 target before the existing wasm32-wasi target is
removed in Rust 1.84 (January 5th, 2025).
In this post we'll discuss the introduction of the new targets, the motivation
behind it, what that means for the existing WASI targets, and a detailed
schedule for these changes. This post is about the WASI targets only; the
existing wasm32-unknown-unknown and wasm32-unknown-emscripten targets are
unaffected by any changes in this post.
Introducing wasm32-wasip2
After nearly five years of work the WASI 0.2 specification
was recently stabilized. This work builds on WebAssembly
Components (think: strongly-typed
ABI for Wasm), providing standard interfaces for things like asynchronous IO,
networking, and HTTP. This will finally make it possible to write asynchronous
networked services on top of WASI, something which wasn't possible using WASI
0.1.
People interested in compiling Rust code to WASI 0.2 today are able to do so
using the cargo-component
tool. This tool is able to take WASI 0.1 binaries, and transform them to WASI 0.2
Components using a shim. It also provides native support for common cargo
commands such as cargo build, cargo test, and cargo run. While it
introduces some inefficiencies because of the additional translation layer, in
practice this already works really well and people should be able to get
started with WASI 0.2 development.
We're however keen to begin making that translation layer obsolete. And for
that reason we're happy to share that Rust has made its first steps towards
that with the introduction of the tier
3wasm32-wasip2
target landing in Rust 1.78. This will initially miss a lot of expectedfeatures such as stdlib support, and we don't recommend people use this targetquite yet. But as we fill in those missing features over the coming months, we
aim to eventually meet the criteria to become a tier 2 target, at which
point the wasm32-wasip2 target would be considered ready for general use. This
work will happen through 2024, and we expect for this to land before the end of
the calendar year.
Renaming wasm32-wasi to wasm32-wasip1
The original name for what we now call WASI 0.1 was "WebAssembly System
Interface, snapshot 1". Rust shipped support for this in 2019, and we did so
knowing the target would likely undergo significant changes in the future. With
the knowledge we have today though, we would not have chosen to introduce the
"WASI, snapshot 1" target as wasm32-wasi. We should have instead chosen to add
some suffix to the initial target triple so that the eventual stable WASI 1.0
target can just be called wasm32-wasi.
In anticipation of both an eventual WASI 1.0 target, and to preserve consistency
between target names, we'll begin rolling out a name change to the existing WASI
0.1 target. Starting in Rust 1.78 (May 2nd, 2024) a new wasm32-wasip1 target
will become available. Starting Rust 1.81 (September 5th, 2024) we will begin
warning existing users of wasm32-wasi to migrate to wasm32-wasip1. And
finally in Rust 1.84 (January 9th, 2025) the wasm32-wasi target will no longer
be shipped on the stable release channel. This will provide an 8 month
transition period for projects to switch to the new target name when they update
their Rust toolchains.
The name wasip1 can be read as either "WASI (zero) point one" or "WASI preview
one". The official specification uses the "preview" moniker, however in most
communication the form "WASI 0.1" is now preferred. This target triple was
chosen because it not only maps to both terms, but also more closely resembles
the target terminology used in other programming
languages. This is something the WASI Preview 2
specification also makes note
of.
Timeline
This table provides the dates and cut-offs for the target rename from
wasm32-wasi to wasm32-wasip1. The dates in this table do not apply to the
newly-introduced wasm32-wasi-preview1-threads target; this will be renamed to
wasm32-wasip1-threads in Rust 1.78 without going through a transition period.
The tier 3 wasm32-wasip2 target will also be made available in Rust 1.78.
date
Rust Stable
Rust Beta
Rust Nightly
Notes
2024-02-08
1.76
1.77
1.78
wasm32-wasip1 available on nightly
2024-03-21
1.77
1.78
1.79
wasm32-wasip1 available on beta
2024-05-02
1.78
1.79
1.80
wasm32-wasip1 available on stable
2024-06-13
1.79
1.80
1.81
warn if wasm32-wasi is used on nightly
2024-07-25
1.80
1.81
1.82
warn if wasm32-wasi is used on beta
2024-09-05
1.81
1.82
1.83
warn if wasm32-wasi is used on stable
2024-10-17
1.82
1.83
1.84
wasm32-wasi unavailable on nightly
2024-11-28
1.83
1.84
1.85
wasm32-wasi unavailable on beta
2025-01-09
1.84
1.85
1.86
wasm32-wasi unavailable on stable
Conclusion
In this post we've discussed the upcoming updates to Rust's WASI targets. Come
Rust 1.78 the wasm32-wasip1 (tier 2) and wasm32-wasip2 (tier 3) targets will
be added. In Rust 1.81 we will begin warning if wasm32-wasi is being used. And
in Rust 1.84, the existing wasm32-wasi target will be removed. This will free
up wasm32-wasi to eventually be used for a WASI 1.0 target. Users will have 8
months to switch to the new target name when they update their Rust toolchains.
The wasm32-wasip2 target marks the start of native support for WASI 0.2. In
order to target it today from Rust, people are encouraged to use
cargo-component tool
instead. The plan is to eventually graduate wasm32-wasip2 to a tier-2 target,
at which point cargo-component will be upgraded to support it natively instead.
With WASI 0.2 finally stable, it's an exciting time for WebAssembly development.
We're happy for Rust to begin implementing native support for WASI 0.2, and
we're excited about what this will enable people to build.
The Rust Security Response WG was notified that the Rust standard library did
not properly escape arguments when invoking batch files (with the bat and
cmd extensions) on Windows using the Command API. An attacker able to
control the arguments passed to the spawned process could execute arbitrary
shell commands by bypassing the escaping.
The severity of this vulnerability is critical if you are invoking batch
files on Windows with untrusted arguments. No other platform or use is
affected.
This vulnerability is identified by CVE-2024-24576.
Overview
The Command::arg and Command::args APIs state in their
documentation that the arguments will be passed to the spawned process as-is,
regardless of the content of the arguments, and will not be evaluated by a
shell. This means it should be safe to pass untrusted input as an argument.
On Windows, the implementation of this is more complex than other platforms,
because the Windows API only provides a single string containing all the
arguments to the spawned process, and it's up to the spawned process to split
them. Most programs use the standard C run-time argv, which in practice results
in a mostly consistent way arguments are splitted.
One exception though is cmd.exe (used among other things to execute batch
files), which has its own argument splitting logic. That forces the standard
library to implement custom escaping for arguments passed to batch files.
Unfortunately it was reported that our escaping logic was not thorough enough,
and it was possible to pass malicious arguments that would result in arbitrary
shell execution.
Mitigations
Due to the complexity of cmd.exe, we didn't identify a solution that would
correctly escape arguments in all cases. To maintain our API guarantees, we
improved the robustness of the escaping code, and changed the Command API to
return an InvalidInput error when it cannot safely escape an argument.
This error will be emitted when spawning the process.
The fix will be included in Rust 1.77.2, to be released later today.
If you implement the escaping yourself or only handle trusted inputs, on
Windows you can also use the CommandExt::raw_arg method to bypass the
standard library's escaping logic.
Affected Versions
All Rust versions before 1.77.2 on Windows are affected, if your code or one of
your dependencies executes batch files with untrusted arguments. Other
platforms or other uses on Windows are not affected.
Acknowledgments
We want to thank RyotaK for responsibly disclosing this to us according to the
Rust security policy, and Simon Sawicki (Grub4K) for identifying some of
the escaping rules we adopted in our fix.
We also want to thank the members of the Rust project who helped us disclose
the vulnerability: Chris Denton for developing the fix; Mara Bos for reviewing
the fix; Pietro Albini for writing this advisory; Pietro Albini, Manish
Goregaokar and Josh Stone for coordinating this disclosure; Amanieu d'Antras
for advising during the disclosure.
The EU’s Digital Services Act (DSA) has taken effect, ushering in a new era of accountability, transparency, and responsibility for digital platforms. Mozilla has actively supported the DSA – and its aim to build a safer digital ecosystem – since the legislation was first proposed, and continues to contribute to conversations about how to implement it effectively.
Technology companies that offer services in the EU must “designate a sufficiently mandated legal representative in the Union and provide information relating to their legal representatives to the relevant authorities,” and each EU country must appoint a Digital Services Coordinator to interpret and enforce the DSA.
In January of this year the Authority for Consumers and Markets in the Netherlands (ACM) published draft guidelines for its interpretation and enforcement of the DSA. Mozilla recently provided feedback, focused largely on areas where further detail or clarification would be helpful, as well as discussing challenges small and mid sized platforms may face during implementation.
Specifically, Mozilla recommended the following:
Clarification of “ancillary services.”
The ACM’s draft guidelines note that Recital 13 of the DSA exempts “ancillary services” where, as with the comment section of a newspaper’s website, “the possibility of posting comments… is only an incidental characteristic of the main service.” Mozilla recommends that this “ancillary services” exception also expressly include services for tech support and product feedback, and similar platforms that exist only to support a primary product that is not subject to DSA. Such forums are clearly ancillary to the main products, as their purpose is to help address bugs and other product-specific issues within those products.
Refining the definition of “traders.”
The DSA imposes additional requirements on platforms that host B2C online marketplaces, by requiring that the platforms track and store data about “traders” that operate on their platform. DSA Recital 23, which presumes that traders in an online marketplace are offering goods or services for a price, highlights that this provision is intended to cover those platforms that facilitate online commerce. Mozilla recommends that the guidelines make this intent clear, by expressly stating that: (i) “traders” do not include those providing free online services, and (ii) platforms which do not incur profits or facilitate the exchange of money are not B2C online marketplaces.
Allowing platforms the flexibility to address spam.
The DSA’s obligations do not apply when platforms act to address “deceptive, high-volume commercial content.” For effective implementation of the guidelines, we believe there needs to be more clarification of how such content is defined. The ACM guidance indicates that the exception applies where someone intentionally manipulates a service through the use of bots, fake accounts, or deceptive practices. Mozilla recommends that the guidance be supplemented to ensure that platforms have the ability to address evolving threats: including clarifying that the references to bots and fake accounts are non-exhaustive examples and not intended to further constrain the spam exception, and establishing a plan to periodically update the guidance to address changing circumstances and developing technologies.
Clarifying the Statement of Reasons requirement.
Both the DSA itself and the ACM guidance require platforms to provide a statement of reasons whenever they moderate content or restrict a user account, explaining the legal or contractual provision on which their action was based. Mozilla asked that ACM provide additional details on what such statements should contain; this would provide greater clarity and standardization for platforms and ensure that moderation (particularly of illegal content) remains workable at scale.
Allowing platforms flexibility on suspensions.
The ACM guidance allows a platform to permanently suspend users for “manifestly illegal content related to serious crimes.” However, it requires that a platform always issue a warning, before suspending a user. Mozilla recommends that the ACM expressly confirm platforms have the right to suspend users for violating their Terms of Service, even if their activity is not illegal. Mozilla also recommends that the warning requirement be clarified, and reduced in cases where having to warn a user might prevent platforms from responding to serious offenses in a timely manner.
As a longtime advocate for the DSA and for platform accountability, Mozilla is enthusiastic about the legislation’s potential to create a safer Internet ecosystem for all. Our comments to ACM, and our ongoing work on this subject, aims to further that goal, without overly burdening small and mid-size platforms. We look forward to working with the ACM and other European regulators in the coming months, as this legislation continues to take shape.
Let’s step back into the Thunderbird Time Machine and teleport ourselves back to December 2009. If you were on the bleeding edge, maybe you were upgrading your computer to the newly released Windows 7 (or checking out Ubuntu 9.10 “Karmic Koala”.) Perhaps you were pouring all your free time into Valve’s ridiculously fun team-based survival shooter Left 4 Dead 2. And maybe, just maybe, you were eagerly anticipating installing Thunderbird 3.0 — especially since it had been a lengthy two years since Thunderbird 2.0 had launched.
What happened during those two years? The Thunderbird developer community — and Mozilla Messaging — clearly stayed busy and productive. Thunderbird 3.0 introduced several new feature milestones!
1) The Email Account Wizard
We take it for granted now, but in the 2000s, adding an account to an email client wasn’t remotely simple. Traditionally you needed to know your IMAP/POP3 and SMTP server URLs, port numbers, and authentication settings. When Thunderbird 3.0 launched, all that was required was your username and password for most mainstream email service providers like Yahoo, Hotmail, or Gmail. Thunderbird went out and detected the rest of the settings for you. Neat!
2) A New Tabbed Interface
With Firefox at its core, Thunderbird followed in the footsteps of most web browsers by offering a tabbed interface. Imagine! Being able to quickly tab between various searches and emails without navigating a chaotic mess of separate windows!
3) A New Add-on Manager
<figcaption class="wp-element-caption">Screenshot from HowToGeek’s Thunderbird 3.0 review.</figcaption>
Speaking of Firefox, Thunderbird quickly adopted the same kind of Add-on Manager that Firefox had recently integrated. No need to fire up a browser to search for useful extensions to Thunderbird — now you could search and install new functionality from right inside Thunderbird itself.
4) Advanced Search Options
Searching your emails got a massive boost in Thunderbird 3.0. Advanced filtering tools means you could filter your results by sender, attachments, people, folders, and more. A shiny new timeline view was also introduced, letting you jump directly to a certain date’s results.
5) The Migration Assistant
Tying this all together was a simple but wonderful migration assistant. It served as a way to introduce users to certain new features (like per-account IMAP synchronization), and visually toggle them on or off (useful for displaying the revised Message Toolbar and giving users a choice of where to enjoy it). To me, this particular addition felt ahead of its time. We’ve been discussing the idea of re-introducing it in a future Thunderbird release, but one of the steep hurdles to doing so now is localization. If it’s something you’d like to see, let us know in the comments.
Try It Out For Yourself
If you want to personally step into the Thunderbird Time Machine, every version ever released for Windows, Linux, and macOS is available in this archive. I ran mine inside of a Windows 7 virtual machine, since my native Linux install complained about missing libraries when trying to get Thunderbird 3.0 running.
Regardless if you’re a new Thunderbird user or a veteran who’s been with us since 2003, thanks for being on the journey with us!
I wrote xpidump to give a human-readable summary of some information about a
Firefox add-on. It is designed to answer these two questions: is the add-on
likely1 signed? And if so, how?
This tool takes an XPI file as input. XPI files are Firefox add-ons packaged
as ZIP archives with the .xpi file extension. xpidump currently extracts
information from up to 4 files in an XPI (depending on what is available in the
archive):
manifest.json: this JSON file defines the add-on. It is required in any
add-on (packaged or not, signed or not).
META-INF/mozilla.rsa: this binary file is a PKCS#7 signature. Any signed
add-on should have this file (in addition to META-INF/mozilla.sf and
META-INF/manifest.mf but xpidump doesn’t read them).
META-INF/cose.sig: this binary file is a COSE signature2. It might
not be present when the add-on isn’t signed or relatively old3. There
should also be a META-INF/cose.manifest file when this file exists.
mozilla-recommendation.json: this JSON file is generated by Mozilla’s
signing service Autograph when an add-on is signed with recommendation
states. This is how Firefox knows that an add-on is recommended for
instance. It might or might not be present.
xpidump is both a command-line tool and a web app since the latter is usually
more convenient (no need to install anything). It’s written in Rust, and
compiled to WebAssembly for the web app. You can try it at:
williamdurand.fr/xpidump/.
xpidump is available in the browser thanks to WebAssembly!
The code is published on GitHub under the MIT license, see:
willdurand/xpidump. I don’t have any
more plans for this weekend-ish project, it’s doing what I wanted it to be
doing… Let me know if you have ideas, though.
One more thing while we’re here… If you want a tool to read the entire content
of any XPI file and get tons of information, you want to use CRX Viewer
created by my brilliant colleague Rob!
This tool doesn’t verify the signature, so it cannot guarantee that the
add-on is correctly signed. ↩
Well, a COSE sign message with a signature and serialized with CBOR,
though we should probably refer to the protocol as COSEish because of
this issue. ↩
Ownership is an important concept in Rust — but I’m not talking about the type system. I’m talking about in our open source project. One of the big failure modes I’ve seen in the Rust community, especially lately, is the feeling that it’s unclear who is entitled to make decisions. Over the last six months or so, I’ve been developing a project goals proposal, which is an attempt to reinvigorate Rust’s roadmap process — and a key part of this is the idea of giving each goal an owner. I wanted to write a post just exploring this idea of being an owner: what it means and what it doesn’t.
Every goal needs an owner
Under my proposal, the project will identify its top priority goals, and every goal will have a designated owner. This is ideally a single, concrete person, though it can be a small group. Owners are the ones who, well, own the design being proposed. Just like in Rust, when they own something, they have the power to change it.1
Just because owners own the design does not mean they work alone. Like any good Rustacean, they should treasure dissent, making sure that when a concern is raised, the owner fully understands it and does what they can to mitigate or address it. But there always comes a point where the tradeoffs have been laid on the table, the space has been mapped, and somebody just has to make a call about what to do. This is where the owner comes in. Under project goals, the owner is the one we’ve chosen to do that job, and they should feel free to make decisions in order to keep things moving.
Teams make the final decision
Owners own the proposal, but they don’t decide whether the proposal gets accepted. That is the job of the team. So, if e.g. the goal in question requires making a change to the language, the language design team is the one that ultimately decides whether to accept the proposal.
Teams can ultimately overrule an owner: they can ask the owner to come back with a modified proposal that weighs the tradeoffs differently. This is right and appropriate, because teams are the ones we recognize as having the best broad understanding of the domain they maintain.2 But teams should use their power judiciously, because the owner is typically the one who understands the tradeoffs for this particular goal most deeply.
Ownership is empowerment
Rust’s primary goal is empowerment — and that is as true for the open-source org as it is for the language itself. Our goal should be to empower people to improve Rust. That does not mean giving them unfettered ability to make changes — that would result in chaos, not an improved version of Rust — but when their vision is aligned with Rust’s values, we should ensure they have the capability and support they need to realize it.
Ownership requires trust
There is an interesting tension around ownership. Giving someone ownership of a goal is an act of faith — it means that we consider them to be an individual of high judgment who understands Rust and its values and will act accordingly. This implies to me that we are unlikely to take a goal if the owner is not known to the project. They don’t necessarily have to have worked on Rust, but they have to have enough of a reputation that we can evaluate whether they’re going to do a good job.’
The design of project goal proposals includes steps designed to increase trust. Each goal includes a set of design axioms identifying the key tradeoffs that are expected and how they will be weighed against one another. The goal also identifies milestones, which shows that the author has thought about how to breakup and approach the work incrementally.
It’s also worth highlighting that while the project has to trust the owner, the reverse is also true: the project hasn’t always done a good job of making good on its commitments. Sometimes we’ve asked for a proposal on a given feature and then not responded when it arrives.3 Or we set up unbounded queues that wind up getting overfull, resulting in long delays.
The project goal system has steps to build that kind of trust too: the owner identifies exactly the kind of support they expect to require from the team, and the team commits to provide it. Moreover, the general expectation is that any project goal represents an important priority, and so teams should prioritize nominated issues and the like that are related.
Trust requires accountability
Trust is something that has to be maintained over time. The primary mechanism for that in the project goal system is regular reporting. The idea is that, once we’ve identified a goal, we will create a tracking issue. Bots will prompt owners to give regrular status updates on the issue. Then, periodically, we will post a blog post that aggregates these status updates. This gives us a chance to identify goals that haven’t been moving — or at least where no status update has been provided — and take a look as to see why.
In my view, it’s expected and normal that we will not make all our goals. Things happen. Sometimes owners get busy with other things. Other times, priorities change and what was once a goal no longer seems relevant. That’s fine, but we do want to be explicit abouty noticing it has happened. The problem is when we let things live in the dark, so that if you want to really know what’s going on, you have to conduct an exhaustive archaeological expedition through github comments, zulip threads, emails, and sometimes random chats and minutes.
Conclusion
Rust has strong values of being an open, participatory language. This is a good thing and a key part of how Rust has gotten as good as it is. Rust’s design does not belong to any one person. A key part of how we enforce that is by making decisions by consensus.
But people sometimes get confused and think consensus means that everyone has to agree. This is wrong on two levels:
The team must be in consensus, not the RFC thread: in Rust’s system, it’s the teams that ultimately make the decision. There have been plenty of RFCs that the team decided to accept despite strong opposition from the RFC thread (e.g., the ? operator comes to mind). This is right and good. The team has the most context, but the team also gets input from many other sources beyond the people that come to participate in the RFC thread.
Consensus doesn’t mean unanimity: Being in consensus means that a majority agrees with the proposal and nobody thinks that it is definitely wrong. Plenty of proposals are decided where team members have significant, even grave, doubts. But ultimately tradeoffs must be made, and the team members trust one another’s judgment, so sometimes proposals go forward that aren’t made the way you would do it.
The reality is that every good thing that ever got done in Rust had an owner – somebody driving the work to completion. But we’ve never named those owners explicitly or given them a formal place in our structure. I think it’s time we fixed that!
Hat tip to Jack Huey for this turn of phrase. Clever guy. ↩︎
There is a common misunderstanding that being on a Rust team for a project X means you are the one authoring code for X. That’s not the role of a team member. Team members hold the overall design of X in their heads. They review changes and mentor contributors who are looking to make a change. Of course, team members do sometimes write code, too, but in that case they are playing the role of a (particularly knowledgable) contributor. ↩︎
At Mozilla, we believe in an open web that is safe to use. To that end, we improve and maintain the security of people using Firefox around the world. This includes a solid track record of responding to security bugs in the wild, especially with bug bounty programs such as Pwn2Own. As soon as we discover a critical security issue in Firefox, we plan and ship a rapid fix. This post describes how we recently fixed an exploit discovered at Pwn2Own in less than 21 hours, a success only made possible through the collaborative and well-coordinated efforts of a global cross-functional team of release and QA engineers, security experts, and other stakeholders.
To give you a sense of scale, Firefox is a massive piece of software: 30 million+ lines of code, six platforms (Windows 32 & 64bit, GNU/Linux 32 & 64bit, Mac OS X and Android), 90 languages, plus installers, updaters, etc. Releasing such a beast involves coordination across many cross-functional teams spanning the entire globe.
The timing of the Pwn2Own event is known weeks beforehand, so Mozilla is always ready when it rolls around! The Firefox train release calendar takes into consideration the timing of Pwn2Own. We try not to ship a new version of Firefox to end users on the release channel on the same day as Pwn2Own to hopefully avoid multiple updates close together. This also means that we are prepared to ship a patched version of Firefox as soon as we know what vulnerabilities were discovered if any at all.
So What Happened?
The specific exploit disclosed at Pwn2Own consisted of two bugs, a necessity when typical web content is rendered inside of a proverbial browser sandbox: These two sophisticated exploits took an admirable amount of effort to reveal and leverage. Nevertheless, as soon as it was discovered, Mozilla engineers got to work, shipping a new release within 21 hours! We certainly weren’t the only browser “pwned”, but we were the first of all, to patch our vulnerability. That’s right: before you knew about this exploit, we had already protected you from it.
As scary as this might sound, Sandbox Escapes, like many web browser exploits, are an issue common to all browsers, thanks to the evolving nature of the internet. Firefox developers are always eager to find and resolve these security issues as quickly as possible to ensure our users stay safe. We do this continuously by shipping new mitigations like win32k lockdown, site isolation, investing in security fuzzing, and promoting bug bounties for similar escapes. In the interest of openness and transparency, we also continuously invite and reward security researchers who share their newest attacks, which helps us keep our product safe even when there isn’t a Pwn2Own to participate in.
Related Resources
If you’re interested in learning more about Mozilla’s security initiatives or Firefox security, here are some resources to help you get started:
Last year we took ownership of the Thunderbird Flatpak, and it has been our officially recommended package for Linux users. However, we are expanding our horizons to make sure the Thunderbird Snap experience is officially supported too. We at Thunderbird are team “free software”, independent of the packaging technology. This will mostly affect our Ubuntu users but there are plenty of other Snap users out there as well.
Why support both the Snap and Flatpak?
In the spirit of free software, we want to support as many of our users as possible without discriminating on their package preferences. We are not a large company with infinite resources, so we can’t support everything under the sun. But we can make informed decisions that reach the majority of our Linux users.
The Thunderbird Snap has been well maintained by the Ubuntu desktop team for years, and we felt it was time to step up and help out.
What does this mean for me?
If you are an Ubuntu user, then you may already be using the Thunderbird Snap. The next release of Ubuntu is 24.04 (available April 25) and will be the first Ubuntu release that seeds the Thunderbird Snap on the ISO. So if you do a fresh full install of Ubuntu, you will be using the Thunderbird Snap that you know is directly supported by the Thunderbird team.
If you are not an Ubuntu user but Snaps are still a part of your life, then you will still benefit from the same rolling updates provided by the Snap experience.
What changes are expected?
From a user perspective, you should see no changes. Just keep using whichever Thunderbird Snap channel you are comfortable with.
From a developer perspective, we have added the Snap build to our build infrastructure on treeherder. This means whenever a full build is triggered automatically from commits, the Snap is built as well for testing. Whenever the build is one we want to release to the public, this will trigger a general flow:
The existing launchpad mirror will pick up this change and automatically build the Snap for x86 and arm64.
If the launchpad Snap build succeeds, the Snap will be uploaded to the designated Snap store channel.
So all we are changing is adding the snap build into the Thunderbird build infrastructure and plugging it into the existing automation that feeds the snap store.
You can’t predict how or when success will come. In the case of Control Panel for Twitter — a Firefox extension that gives users authority over the amount of algorithmic content they’re fed — it went viral in Japan a few years ago and word spread fast. One devoted fan even jumped into the open-source code and quickly localized the extension in Japanese, further catapulting its appeal. Today, Control Panel for Twitter has more than 250,000 users from all over the world enjoying it across various browsers.
A comprehensive Options page gives you easy, intuitive control over your Twitter/X experience.
“Most of my extensions are for sites I’m a long-time user of, fixing issues which bug me, and adding missing features,” explains developer Jonny Buchannon. One of the first issues he addressed was designing a feature that moved retweets into a separate tab.
“If you don’t like the algorithmic ‘For you’ timeline, it’s usually because it’s full of random tweets about topics you’re not interested in, or worse, deliberate engagement bait. If you look at all the retweets in your timeline, they tend to have a similar problem,” explains Buchannon. “By default, following someone on Twitter lets them put any tweet in your timeline with no effort — a single click or tap — without having to add their own comment, and sometimes they do that because the tweet in question made them feel strong negative emotions; sometimes people will also retweet a string of tweets about similar topics, filling up your timeline.”
To fix this problem the extension swaps the “For you” timeline for the “Following” (chronological) version. Control Panel for Twitter can also hide other types of Twitter/X content like the “See new Tweets” button, “Who to follow,” “Follow some topics,” all the X Premium upsell prompts, and more.
Even with gobs of current customization features, Buchannon says there’s a “huge backlog” of potential enhancements in their GitHub Issues. New features coming soon include the ability to control what you see in Notifications (like hiding Likes and retweets) and improvements viewing a conversation under a focused tweet.
App-solutely atrocious experience — try Twitter/X on the mobile web!
Control Panel for Twitter is also available on Firefox for Android (addons.mozilla.org [AMO] recently launched an open ecosystem of extensions on Firefox for Android). While it may seem strange to use a mobile browser to access Twitter/X instead of the app, Buchannon says he primarily added mobile support for his own personal use. “I’m the #1 user on that front,” he says before issuing a “warning” to prospective users of his extension on Firefox for Android: “Once you get used to the changes Control Panel for Twitter makes to the experience, default Twitter is unusable — be it the app or the website.”
There are also mobile-specific features, such as changes it brings to Twitter/X search functionality. In standard Twitter/X, when you tap the Search nav you’re brought to the Explore page, which is loaded with algorithmic content. Control Panel for Twitter can hide that so you’re simply presented with a streamlined search field.
Apparently Buchannon isn’t alone in his preference to experience the mobile web version of Twitter/X while using his extension. He claims Control Panel for Twitter has only been available on the App Store for Safari for a little over a year, but already 78% of its Safari users are using it on the iPhone.
Based on the same philosophical functionality as Control Panel for Twitter, Buchannon just released Control Panel for YouTube.
“One of the main focuses of the initial version was improving the Subscription pages by automatically hiding any content you don’t want to see in there like Shorts, live streams, ‘upcoming’ videos you can’t watch now, and hiding videos you’ve already watched, so it acts more like an inbox, where videos disappear as you watch them.”
Sounds great, can’t wait to try it out. Less is often more with social media.
Do you have an intriguing extension development story? Do tell! Maybe your story should appear on this blog. Contact us at amo-featured [at] mozilla [dot] org and let us know a bit about your extension development journey.
Your tech choices matter more than ever. That’s why at Firefox, we believe in empowering users to make informed decisions that align with their values. In that spirit, we’re excited to announce our partnership with Qwant, a search engine that prioritizes user privacy and tracker blocking.
Did you know you could choose the search engine of your choice right from your Firefox URL bar? Whether you prioritize privacy, climate protection, or simply want a search experience tailored to your preferences, we’ve got you covered.
Qwant is a privacy-focused search engine that puts your needs first while protecting your personal data. By blocking trackers and advertisements, Qwant helps your search results remain unbiased and comprehensive. Just like Firefox, they are committed to protecting your privacy and preserving the decentralized nature of the web, where people have control over their online experiences.
Together, Firefox and Qwant are contributing to a more open, inclusive web, and above all — one where you can make an informed choice about what tech you use, and why. Your tech choices make a difference.
As Firefox continues to champion user empowerment and innovation, we invite you to join us in shaping a web that works for everyone. Together, let’s make a positive impact—one search at a time.
Over the last couple weeks I have looked at the WebKit code with the intent of fixing a few things in areas of the web platform I’m familiar with as a personal curiosity. The code had always appeared hackable to me, but I had never given it a go in practice. In fact, this is the first time I have written C++ in my life! Marcos had given me a quick guide to set up my environment and I was off to the races.
It has been a lot of fun trying to get things to compile and making tests pass. And also have the chance to study how things are implemented in more detail. I wish web standards had some of the checks available in C++. Now I am well aware that C++ does not have the best reputation, but English is even more error-prone. Granted, the level of abstraction English sits at can also make things easier.
I can heartily recommend this to anyone who has been interested in doing this, but didn’t because it seemed too intimidating. Mind that the first contribution is a bit of a hurdle and can be humbling. Definitely was for me! I recommend tackling something that seems doable. And remember that as with a lot of things it will get easier over time.
(To read the complete Mozilla.ai publication on LLM evaluation, please visit the Mozilla.ai blog)
In a year marked by extraordinary advancements in artificial intelligence, largely driven by the evolution of large language models (LLMs), one factor stands out as a universal accelerator: the exponential growth in computational power.
Over the last few years, researchers have continuously pushed the boundaries of what a ‘large’ language model means, increasing both the size of these models and the volume of data they were trained on. This exploration has revealed a consistent trend: as the models have grown, so have their capabilities.
Fast forward to today, and the landscape has radically transformed. Training state-of-the-art LLMs like ChatGPT has become an immensely costly endeavor. The bulk of this expense stems from the staggering amount of computational resources required. To train an LLM, researchers process enormous datasets using the latest, most advanced GPUs (graphics processing units). The cost of acquiring just one of these GPUs, such as the H100, can reach upwards of $30,000. Moreover, these units are power-hungry, contributing to significant electricity usage.
While there have been substantial efforts by researchers and organizations towards openness in the development of large language models, in addition to the compute challenges, three major hurdles have also hampered efforts to level the playing field:
Limited Transparency: The specifics of model architecture, data sources, and tuning parameters are often closely guarded.
Challenging Reproducibility: Due to the swift pace of innovation, independently replicating these models on your own infrastructure can be very difficult.
Disjointed Evaluation: The absence of a universally accepted benchmark for LLM evaluation complicates direct comparisons. The multitude of available tasks and frameworks, each assessing different capabilities, means comparisons are often inconclusive.
The high compute requirements, coupled with the opaqueness and the complexities of developing and evaluating LLMs, are hampering progress for researchers and smaller organizations striving for openness in the field. This not only threatens to reduce the diversity of innovation but also risks centralizing control of powerful models in the hands of a few large entities. The critical question arises: are these entities prepared to shoulder the ethical and moral responsibilities this control entails? Moreover, what steps can we take to bridge the divide between open innovators and those who hold the keys to the leading LLM technology?
Why LLMs make model evaluation harder than ever
Evaluation of LLMs involves assessing their performance and capabilities across various tasks and benchmarks and provides a measure of progress and highlights areas where models excel or need improvement.
‘Traditional’ machine learning evaluation is quite straightforward: if we develop a model to predict lung cancer from X-ray images, we can test its accuracy by using a collection of X-rays that doctors have already diagnosed as either having cancer (YES) or not (NO). By comparing the model’s predictions with the doctor-diagnosed cases, we can assess how well it matches the expert classifications.
In contrast, LLMs can complete an almost endless number of tasks: summarization, autocompletion, reasoning, generating recommendations for movies and recipes, writing essays, telling stories, generating good code, and so on. Evaluation of performance therefore becomes much, much harder.
At Mozilla.ai, we believe that making open-source model fine-tuning and evaluation as accessible as possible is an important step to helping people own and trust the technology they use. Currently, this still requires expertise and the ability to navigate a rapidly evolving ecosystem of techniques, frameworks, and infrastructure requirements. We want to make this less overwhelming for organizations and developers, which is why we’re building tools that:
Help them find the right open-source LLM for their needs
Make it simple to fine-tune an open-source LLM on their own data
Make language model evaluation and validation more accessible
We think there will be a significant opportunity for many organizations to use these tools to develop their own small and specialized language models that address a range of meaningful use cases in a cost-effective way. We strive to empower developers and organizations to engage with and trust the open-source ecosystem and minimize their dependence on using closed-source models over which they have no ownership or control.
Read the whole publication and subscribe to future ones in the Mozilla.ai blog.
The announcement that Google would remove the ability to track people using cookies in its Chrome browser was met with some consternation from advertisers. After all, when your business relies so heavily on tracking, as is common in the advertising industry, removing the key means of performing that tracking is a bit of a big deal.
Google relies on tracking too, but this change has the potential to skew the advertising market in Google’s favor. For online advertisers looking to perform individualized ad targeting, tracking is a significant important source of visitor information. Smaller ad networks and websites depend on being able to source information about what people do on other sites in order to be competitive in the ruthless online advertising marketplace. Without that, these smaller players might be less able to connect visitors with the — often shady — trade in personal data.
On the other hand, entities like Google who operate large sites, might rely less on information from other sites. Losing the information that comes from tracking people might affect them far less when they can use information they gather from their many services.
So, while the privacy gains are clear — reducing tracking means a reduction in the collection and trade of information about what people do online — the competition situation is awkward. Here we have a company that dominates both the advertising and browser markets, proposing a change that comes with clear privacy benefits, but it will also further entrench its own dominance in the massively profitable online advertising market.
Protected Audience is a cornerstone of Google’s response to pressure from competition regulators, in particular the UK Competition and Markets Authority, with whom Google entered into a voluntary agreement in 2022. Protected Audience seeks to provide some counterbalance to the effects of better privacy in the advertising market.
We find Google’s claims about the effect of Protected Audience on advertising competition credible. The proposal could make targeted advertising better for sites that heavily relied on tracking in the past. That comes with a small caveat: complexity might cause a larger share of advertising profits to go to ad tech intermediaries.
However, the proposal fails to meet its own privacy goals. The technical privacy measures in Protected Audience fail to prevent sites from abusing the API to learn about what you did on other sites.
To say that the details are a bit complicated would be something of an understatement. Protected Audience is big and involved, with lots of moving parts, but it can be explained with a simple analogy.
The idea behind Protected Audience is that it creates something like an alternative information dimension inside of your (Chrome) browser. In this alternative dimension, tracking what you saw and did online is possible. Any website can push information into that dimension. While we normally avoid mixing data from multiple sites, those rules are changed to allow that. Sites can then process that data in order to select advertisements. However, no one can see into this dimension, except you. Sites can only open a window for you to peek into that dimension, but only to see the ads they chose.
Leaving the details aside for the moment, the idea that personal data might be made available for specific uses like this, is quite appealing. A few years ago, something like Protected Audience might have been the stuff of science fiction. Protected Audience might be flawed, but it demonstrates real potential. If this is possible, that might give people more of a say in how their data is used. Rather than just have someone spy on your every action then use that information as they like, you might be able to specify what they can and cannot do. The technology could guarantee that your choice is respected.
Maybe advertising is not the first thing you would do with this newfound power, but maybe if the advertising industry is willing to fund investments in new technology that others could eventually use, that could be a good thing.
Sadly, Protected Audience fails in two ways. To be successful, it must process data without leaks. In a complex design like this, it is almost expected that there will be a few holes in the design. However, the biggest problem is that the browser needs to stop websites from seeing the information that they process.
Preventing advertising companies from looking at the information they process makes it extremely difficult to use Protected Audience. In response to concerns from these companies, Google loosened privacy protections in a number of places to make it easier to use. Of course, by weakening protections, the current proposal provides no privacy. In other words, to help make Protected Audience easier to use, they made the design even leakier.
A lot of these leaks are temporary. Google has a plan and even a timeline for closing most of the holes that were added to make Protected Audience easier to use for advertisers. The problem is that there is no credible fix for some of the information leaks embedded in Protected Audience’s architecture.
A stronger Protected Audience might lead us to ask some fairly challenging questions. We might ask whether objections to targeted advertising arise solely from the privacy problems with current technology? Or, is it the case that targeted manipulation itself is the problem? Targeted advertising is more effective because it uses greater information about its audience — you — to better influence your decisions. So would a system that prevented information collection, but still allowed advertisers to exercise that influence, be acceptable?
We would also need to decide to what extent a browser — a user agent — can justifiably act in ways that are not directly in the interests of its user. Protected Audience exists for the benefit of the advertising industry. A system that makes it easier to make websites supported by advertising has benefits. After all, advertising does have the potential to make content more widely accessible to people of different means, with richer people effectively subsidizing content for those of lesser means. A stronger Protected Audience might then provide people with a real, if indirect, benefit. Does that benefit outweigh the costs of giving advertisers greater influence over our decision-making?
With Protected Audience as it is today, we can simply set those questions aside. In failing to achieve its own privacy goals, Protected Audience is not now — and maybe not ever — a good addition to the Web.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization. The following
RFCs would benefit from user testing before moving forward:
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing
label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature
need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
A pretty quiet week, with most changes (dropped from the report below) being
due to continuing bimodality in the performance data. No particularly notable
changes landed.
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
(this post is subject to change as I come up with more places. Get in touch if you want to suggest one.)
Now that we have Global Privacy Control for the web, can we do better? Where else do we need it? Not everything is on the web.
The big risk of having GPC for web but not for other systems is that surveillance companies will start forcing or nudging you to interact with them in other ways—if the surveillance options are too easy to use elsewhere, then more companies will use deceptive practices to drive us to all use communications technologies where browser privacy features can’t protect us. From my point of view, as someone who would rather use the web, that would be bad. (Install our app for full product info or to sechedule a demo! Press the button on your printer or Internet refrigerator to order! Yikes.)
Smart TVs: As far as I know, these support HTTP, so the existing Sec-GPC header should work fine. Finding the right option in the TV menus is left as an exercise for the reader.
mobile apps: Same, apps also use HTTP so the same header should work. Set one preference per device or account and have it work across all apps.
other devices with an order button: I don’t know about these, will have to look it up.
email part 1: Email also has headers, so standardizing a GPC header would also work, but needs to grind through the RFC process.
email part 2: add +sec-gpc to your address when you mail a company. CRM systems and related software can already handle RFC 5233-style plus addresses, so could treat incoming email from bob+sec-gpc@dobbs.example as an opt out for bob@dobbs.example. (GPC in email could be DKIM-signed, too.)
Instant messaging: So many options, should be doable but a pain because all the big companies want to have their own special protocol. The mobile device GPC should cover it from the sender side, but a recipient company still needs to get the GPC passed through on a message from a customer, somehow.
NFC:The standard behind tap-to-pay and similar features could be extended to support GPC. This one would take more coding and have a longer deployment cycle, though.
vehicle license plates: It’s time for a crossover event between the California Privacy Protection Agency (CPPA) and Special Interest License Plates at the DMV. Add a special symbol to license plates to require companies using ALPR systems to treat the plate, and related database records, as opted out. But wait a minute, custom and special-interest plates cost extra! Wouldn’t that be asking people to pay for privacy? (I’d get one, but really just to fly my privacy nerd flag so I don’t count.) Not necessarily—most of these could end up being free to the vehicle owner. In practice, GPC plates would be a way to help resolve privacy class action lawsuits. Instead of getting yet another free credit monitoring service when a company settles a case (and you probably had free credit monitoring from the last class you were in) a company could settle for buying everyone in the class their choice of credit monitoring or a GPC plate. An interesting piece of graphic design work for somebody would be coming up with an easily recognizable symbol that an ALPR system would not get mixed up with any of the other symbols that are allowed on a license plate.
face recognition: Once we have a GPC symbol for license plates, require companies that process images for the purposes of identifying people to also check for the symbol. Then you could wear it on a T-shirt, on a piece of flair, or on the front of a hat.
tire pressure monitors: These devices have a unique ID and can be used for surveillance. This probably also apples to a bunch of other little radios that follow you around, but maybe the easier method here is to ban commercial surveillance using little radios that follow people around, since there’s not really a legit use case.
postal addresses: There should be a way to pack a GPC into an apartment number. Maybe treat an address from apartment “GPC” as an opt-out for the same address without “GPC” if you have it, and an address from apartment “3AGPC” as an opt-out for apartment 3A?
more GPC for web
Sec-GPC as a response header: The big use case for this would be a server that hosts a directory, blog, services booking tool, or other resource containing personal information. The Sec-GPC response header would look just like the existing header except on the HTTP response, not the request. The meaning would be to apply a do-not-sell-or-share preference to any personal information collected by web crawlers.
GPC meta tag: This could be something like <meta http-equiv="Sec-GPC" content="1" />. Would be useful for people making personal sites on hosting plans where they can edit HTML but not configure HTTP headers.
GPC in robots.txt: Another possible place to put GPC as a server-to-crawler OOPS. FIXME: how to handle this to convey permssions—you might want a crawler to check for something like an RSS update, but not harvest your contact info for sale/sharing.
GPC in links: Sort of like a nofollow link, you could tag a link containing personal info as opted out: <a class="secGPC" href="mailto:user@example.com">mail me (but don't sell/share my info)</a>. That would send an OOPS for the email address but not any other info collected from the page.
Scraping can already be actionable as a violation of site ToS, but being able to tag a page by or about a person as opted out is another level of protection that imho will help encourge more people to make more useful sites. As a site operator, you want to be able to put up something like a blog, company directory, or event speaker profiles without feeding your site’s people to who knows what.
The first version of the Speedometer 3 benchmark was released last week. Read bgrins’ blog post about the benchmark, and how we’re collaborating with other browser vendors to develop a meaningful benchmark that has actually resulted in felt improvements to web performance.
Henrik Skupin vendored the new Puppeteer v22.4.0 release into mozilla-central (#1878632)
Henrik Skupin fixed mach puppeteer-test command to enable running the tests with Chrome, including the ability to specify a custom binary (#1877629)
Henrik Skupin fixed the behavior when running with only WebDriver BiDi enabled (without CDP), no recommended automation preferences were being set for Firefox (#1882748)
Henrik Skupin resolved a race condition in WebDriver BiDi when creating or switching between tabs within the same OS window. This fix ensures that the document.visibilityState value is correctly set to hidden when the corresponding commands are executed (#1877469)
Alexandra Borovova implemented the input.setFiles command, which allows clients to set the files property of a given input element with type file to a list of file paths (#1855040)
Julian Descottes added a new capability userAgent for WebDriver Classic and BiDi, which returns the default user agent (#1885495)
Working with PM and UX, we think we’ve settled on a format for the single-file backup archive that ticks all of the boxes. We’ll hopefully have more details on that soon after we finish writing documentation for it.
This was mentioned in the meeting but I wanted to shout out again that the screenshots component is now enabled in Nightly (bug 1789727)! This allows screenshots on about: pages, has better performance, keyboard accessibility, and much more!
The search configuration defines the search engines which are displayed to the user by default, according to their region, locale and other settings.
Standard8 and mcheang have enabled the new search configuration on nightly, due to ship in FF 126
This replaces the previous WebExtension + remote settings collection with a single remote settings collection for the configuration, and a separate one for icons.
It also addresses complexities and other issues that were in the old configuration.
The same collection will also be picked up later this year by our mobile platforms, allowing easier updates to our search engine configuration across products.
Hello Thunderbird Community! March is over, which means it’s time for another Development Digest to share the current progress and product direction of Thunderbird development.
Is this your first time reading the Development Digest? Find them all using the Dev Digest tag!
Rust and Exchange
It seems that this section is part of every Development Digest! But that’s the reality of these large efforts, spanning across multiple months with slow but steady progress.
This month we completed initial Exchange Autodiscovery and compatibility with OAuth in our account setup flow, as well as fetching and rendering of all folders. Some areas still need polish and clean up. But work continues towards having things behind a pref in the next beta release. You can follow the progress in this bug.
Meanwhile, here are some goodies to try if you need to parse the Microsoft Exchange Web Services data set and the current crates for serializing and deserializing XML don’t serve you well. https://github.com/thunderbird/xml_struct
List management
Shout out to Magnus for implementing the first step towards a more manageable mailing list subscription flow. An initial implementation of the List Management feature just landed on daily and beta, and it was recently announced in the tb-beta mailing list with a screenshot to show it in action.
It’s currently accessible via a context menu on the List ID. But we’re planning to do some UX and UI explorations to find the best way to expose it without making it annoying.
Another big shout out to Magnus for finishing the ESMification effort! As users, you won’t see or notice any difference, but for developers this substantial architectural change saw the removal of all .jsm files in favor of standard JavaScript modules.
A huge win for a more standardized code base! This allows us to leverage all the nice features of modern JavaScript in Thunderbird development.
Tiny changes and improvements in Thunderbird development
A lot of nice quality of life improvements tend to happen in small chunks that are not easy to see or spot right away.
Here’s a list of the projects we’re actively working on and will be focusing on for the next month:
Cards view UI completion.
Fixed missing FindBar in multimessage and browser view.
Implementation of a new visual selection paradigm.
Improvements to usability and accessibility of the Quick Filter bar.
Completion of the email setup in the new Account Hub.
Many add-ons API improvements and additions (big shout out to John).
Support for viewing nested signed messages and other OpenPGP improvements.
Stay tuned and make sure to sign up to our mailing lists to get detailed updates on all the items in this list, and a lot more.
As usual, if you want to see things as they land you can always check the pushlog and try running daily, which would be immensely helpful for catching bugs early.
See ya next time in our April Development Digest.
Alessandro Castellani(he, him) Director of Product Engineering
If you’re interested in joining the technical discussion around Thunderbird development, consider joining one or several of our mailing list groups here.
The EU isn’t just concerned with today. It’s really taking Steve Jobs’ advice and listening to the Wayne Gretzky quote: it’s skating to where the puck is going, not where it’s been. Its aim is to ensure that two very large companies don’t own the market for smartphones to such a degree they can determine everything that happens in those markets, to their advantage. The EU is a capitalist body: its obsession is keeping markets open, and it will do anything it needs to do to make sure that happens.
From here in the USA, it looks to me like we need to put our understanding of European privacy and competition policy into context. We seem to spend a lot of time in the weeds trying to figure out what will be allowed by specific laws and regulations, and maybe we’re missing the big picture. From here, it looks like the EU has two really big problems.
The EU’s most important problem is climate change, including the problem of climate refugees. Worst case is that Europe has to rebuild their infrastructure and agriculture while somehow dealing with 1.2 billion people who need to move there because their old home is unlivable now. None of the ways that the EU can address this problem are going to make everybody happy, and the EU somehow has to do them in a decentralized democratic system.
The EU’s most urgent problem is that Europe is being invaded by Russia—regular Russian forces in several eastern European countries, and economic, information, and network warfare clearing the way for them further west. Also a hard problem, partly because of the Putin regime’s ability to work the political system.
Big Tech isn’t in trouble in Europe because companies are failing to comply with whatever the EU laws are today. They’re in trouble because they’re more of a part of the problem than a part of the solution on the big issues. The EU says that they want social media companies to hire factcheckers to fight election fake news, they opened up a bunch of competition cases on platform companies, and, of course, they’re going to shut down Meta’s bogus pay or consent policy. if the pay or consent model actually worked it would turn the whole GDPR into a no-op. Every vending machine would have pay €2 and consent and pay €1002, no consent buttons. Pay or consent is not going to hold up in court but the Meta team that deployed it have already collected their bonuses and moved on.
But it’s not about the individual cases. If the EU throws the book at a Big Tech company, and the company successfully dodges it, what happens is that the EU makes a heavier book and throws harder. As long as a company is working for the Russians, for the fossil-fuel industry, and for divisive right-wing groups (yes, they overlap) then they’re going to have a problem in the EU. Someone in the EU is probably also reading the history of the US Republican party and direct mail—a party that had been a coalition of defense, free-market, and social conservative factions rapidly pivoted in the post-Goldwater years based on what works as direct mail (and now email and social media) copy. In the USA, it looks like direct mail, personalized, and surveillance advertising give advantages to fear-based and racially divisive messsages that would work less well in other media. If that applies in Europe too, a crackdown on the surveillance industry makes sense even outside the context of the coming post-surveillance economic boom.
And yes, there’s an Al Capone effect going on here. The same Big Tech management teams that reward sexual harassment with big checks are also willing to monetize scams hosted in adversary countries and copyright-infringing sites run from adversary countries. I still don’t understand the appeal of Vladimir Putin fandom among tech thought leaders, but it’s there—and as long it persists, climate change and European security are the underlying problems for Big Tech in Europe, not any specific policies.
<figcaption>Servo now supports tables, box and text shadows, setting fonts on 2D canvases, synthetic small caps, conic and repeating conic gradients, and WOFF2 web fonts.</figcaption>
This month, after surpassing our legacy layout engine in the CSS test suites, we’re proud to share that Servo has surpassed legacy in the whole suite of Web Platform Tests as well!
In other layout news, tables are now enabled by default (@Loirooriol, #31470), you can now transform <iframe> and <img> (and other inline replaced elements) without wrapping them in a container (@mrobinson, #31833), we now have full support for <div align> and <center> (@Loirooriol, #31423), and ‘text-align: justify’ now takes ‘text-indent’ into account (@mrobinson, #31777).
You can now set the font on 2D canvases (@syvb, #31436), and use several other APIs:
as of 2024-03-02, <meta http-equiv="Refresh"> (@syvb, #31468)
Servo now stops loading videos and other media after encountering decode errors (@frereit, #31748), and our docs and dev tooling have been updated to ensure support for WebM and AV1 (@delan, #31687).
Servo no longer crashes when <video poster> fails to load (@sebsebmc, #31447), when interacting with CSS layers in the CSSOM (@Loirooriol, #31481).
As a result of the work done on Servo this month, we’ve made some big strides in our pass rates for CSS tables (+30.4pp to 62.9%), CSS2 margin-padding-clear (+13.2pp to 93.6%), and CSS2 box-display (+10.0pp to 84.4%).
servoshell and debug logging
servoshell has had a good amount of love this month, with a new loading spinner (@frereit, #31713) and a rendering glitch under the location bar now fixed (@delan, #31774).
Logging in servoshell is no longer mixed with libservo (@delan, #31439), with the RUST_LOG prefix now being servoshell:: instead of servo::.
Speaking of RUST_LOG, you can now filter event logging in servoshell and the constellation at runtime (@delan, #31657, #31659), with the new RUST_LOG prefixes servoshell<winit@, servoshell<servo@, servoshell>servo@, constellation<compositor@, constellation<script@, and constellation<layout@.
For example:
to trace all events in the constellation from layout, plus all events from the compositor other than ReadyToPresent: RUST_LOG=‘constellation<layout@,constellation<compositor@,constellation<compositor@ReadyToPresent=off’
to trace only winit window moved events in servoshell, plus all ordinary servoshell logs at trace level: RUST_LOG=‘servoshell,servoshell<=off,servoshell>=off,servoshell<winit@WindowEvent(Moved)’
<figcaption>Comparison of event tracing without (left) and with (right) runtime filtering.</figcaption>
Embedding and dev changes
We’ve now defined a simple policy for reporting security vulnerabilities (@mrego, #31622), though this is subject to change once Servo is no longer purely experimental.
Servo had a pervasive but confusing concept of webviews or pipelines being “visible”, which actually controls whether script runs timers at a heavily limited rate and the compositor pauses animations.
We’ve replaced this with the more concrete (but inverted) concept of a webview being “throttled” (@delan, #31816), including in our embedding API, where WebViewVisibilityChanged has been replaced with SetWebViewThrottled (@delan, #31815).
mach fmt now uses stable Rust (@mrobinson, #31441) and should now be much faster on macOS (@mrobinson, #31440).
mach doc is now working again, and the spurious “crown” warnings have been fixed (@mrobinson, #31804).
As for try jobs on CI, builds now immediately fail when Cargo.lock is out of date (@Loirooriol, #31720), the test result comments no longer ping random users (@sagudev, #31691), and build artifacts now include the more compact “wptreport” logs (@sagudev, #31616).
We’ve also landed changes to reduce test flakiness in requestAnimationFrame() (@mrobinson, #31561), as well as when the compositor waits for frames (@mrobinson, #31523), when the compositor is shutting down (@mrobinson, #31733), and when loading fonts on macOS (@mrobinson, #31658).
Last but not least, NixOS users can rejoice, as nix-shell will no longer break when Cargo.lock changes (@mukilan, #31825).
Outreachy
Servo is also participating in Outreachy this year!
Outreachy is a three-month paid (7000 USD) remote internship program that runs twice a year, with a special focus on open source software.
To select interns for Outreachy, there was a contribution period that is now coming to a close, during which contributors have landed a wide range of improvements.
One contributor went further, cleaning up the codegen for our DOM bindings (@eerii, #31721, #31711, #31844), improving our dev tooling (@eerii, #31694), and improving our image decoding by replacing per-image threads with a thread pool (@eerii, #31517, #31585)!
One of the big problems with widespread use of large language models (LLMs) is going to be that reputation management firms will be able to put up a lot of content to try to clean up mentions of their own clients. Other players will also, in a totally deniable way, be able to put up their own text to train LLMs to say bad stuff about people who are opposed to their clients in some way. What is seen as important material about a person from the point of view of, say, a reporter or Wikipedia editor, is not necessarily going to be what gets pulled out a big pile of crawled text by an LLM.
You can kind of see what’s possible by looking at 20th century history. Many Axis officers from World War II have a lot of content about them on the Internet somewhere.
For example, let’s take a look at the 14 defendants in the High Command Trial at Nuremberg. To a human editor, the Nuremberg trials were a significant historic event, so the fact that an officer was a defendant is going to be a key fact about him that makes it into any reasonable length bio.
For ChatGPT, not so much. Asking ChatGPT: “what is officer_name known for” gives different results. I tried it.
All 14 are correctly identified by country and historical period
In 5 cases, the ChatGPT answer has no mention of the trial, of any of the conduct for which the officer was tried, or any mention of war crimes at all.
Answers often end with something like, After the war, officer_name was captured by Allied forces and held as a prisoner of war. He was later released and returned to civilian life.
The Nuremberg trials were extremely well covered at the time, a lot has been written about them, and they’re still studied today. Old-school propaganda operations, keyboard warriors, and random wehraboos were able to scrub this major event, and the crimes for which the defendants were tried, without really trying. So the same kind of thing is going to be practical for lots of people, companies, and organizations. Reputation management firms typically don’t have to obscure something as big as the Nuremberg trials, and they can use LLMs to produce far more text, faster, than even an online army of gamers can. Expect the defendants in run-of-the-mill corporate trials to effectively disappear their crimes, too.
It’s possible that the big “AI” companies could deal with the reputation management problem by licensing a set of known neutral point of view (NPOV) content and either avoiding material that looks conflicting, or filtering out responses that look inconsistent with it. But that’s a big task, and will get bigger the more that “reputation management” is seen to work.
Rust has long had an inconsistency with C regarding the alignment of 128-bit integers
on the x86-32 and x86-64 architectures. This problem has recently been resolved, but
the fix comes with some effects that are worth being aware of.
As a user, you most likely do not need to worry about these changes unless you are:
Assuming the alignment of i128/u128 rather than using align_of
Ignoring the improper_ctypes* lints and using these types in FFI
There are also no changes to architectures other than x86-32 and x86-64. If your
code makes heavy use of 128-bit integers, you may notice runtime performance increases
at a possible cost of additional memory use.
This post documents what the problem was, what changed to fix it, and what to expect
with the changes. If you are already familiar with the problem and only looking for a
compatibility matrix, jump to the Compatibility section.
Background
Data types have two intrinsic values that relate to how they can be arranged in memory;
size and alignment. A type's size is the amount of space it takes up in memory, and its
alignment specifies which addresses it is allowed to be placed at.
The size of simple types like primitives is usually unambiguous, being the exact size of
the data they represent with no padding (unused space). For example, an i64 always has
a size of 64 bits or 8 bytes.
Alignment, however, can vary. An 8-byte integer could be stored at any memory address
(1-byte aligned), but most 64-bit computers will get the best performance if it is
instead stored at a multiple of 8 (8-byte aligned). So, like in other languages,
primitives in Rust have this most efficient alignment by default. The effects of this
can be seen when creating composite types (playground link):
use core::mem::{align_of, offset_of};
#[repr(C)]
struct Foo {
a: u8, // 1-byte aligned
b: u16, // 2-byte aligned
}
#[repr(C)]
struct Bar {
a: u8, // 1-byte aligned
b: u64, // 8-byte aligned
}
println!("Offset of b (u16) in Foo: {}", offset_of!(Foo, b));
println!("Alignment of Foo: {}", align_of::<Foo>());
println!("Offset of b (u64) in Bar: {}", offset_of!(Bar, b));
println!("Alignment of Bar: {}", align_of::<Bar>());
Output:
Offset of b (u16) in Foo: 2
Alignment of Foo: 2
Offset of b (u64) in Bar: 8
Alignment of Bar: 8
We see that within a struct, a type will always be placed such that its offset is a
multiple of its alignment - even if this means unused space (Rust minimizes this by
default when repr(C) is not used).
These numbers are not arbitrary; the application binary interface (ABI) says what they
should be. In the x86-64 psABI (processor-specific ABI) for System V (Unix & Linux),
Figure 3.1: Scalar Types tells us exactly how primitives should be represented:
C type
Rust equivalent
sizeof
Alignment (bytes)
char
i8
1
1
unsigned char
u8
1
1
short
i16
2
2
unsigned short
u16
2
2
long
i64
8
8
unsigned long
u64
8
8
The ABI only specifies C types, but Rust follows the same definitions both for
compatibility and for the performance benefits.
The Incorrect Alignment Problem
If two implementations disagree on the alignment of a data type, they cannot reliably
share data containing that type. Rust had inconsistent alignment for 128-bit types:
println!("alignment of i128: {}", align_of::<i128>());
// rustc 1.76.0
alignment of i128: 8
printf("alignment of __int128: %zu\n", _Alignof(__int128));
// gcc 13.2
alignment of __int128: 16
// clang 17.0.1
alignment of __int128: 16
(Godbolt link) Looking back at the psABI, we can see that Rust has
the wrong alignment here:
C type
Rust equivalent
sizeof
Alignment (bytes)
__int128
i128
16
16
unsigned __int128
u128
16
16
It turns out this isn't because of something that Rust is actively doing incorrectly:
layout of primitives comes from the LLVM codegen backend used by both Rust and Clang,
among other languages, and it has the alignment for i128 hardcoded to 8 bytes.
Clang uses the correct alignment only because of a workaround, where the alignment is
manually set to 16 bytes before handing the type to LLVM. This fixes the layout issue
but has been the source of some other minor problems.12
Rust does no such manual adjustement, hence the issue reported at
https://github.com/rust-lang/rust/issues/54341.
When calling a function, the arguments get passed in registers (special storage
locations within the CPU) until there are no more slots, then they get "spilled" to
the stack (the program's memory). The ABI tells us what to do here as well, in the
section 3.2.3 Parameter Passing:
Arguments of type __int128 offer the same operations as INTEGERs, yet they do not
fit into one general purpose register but require two registers. For classification
purposes __int128 is treated as if it were implemented as:
typedef struct {
long low, high;
} __int128;
with the exception that arguments of type __int128 that are stored in memory must be
aligned on a 16-byte boundary.
We can try this out by implementing the calling convention manually. In the below C
example, inline assembly is used to call foo(0xaf, val, val, val) with val as
0x11223344556677889900aabbccddeeff.
x86-64 uses the registers rdi, rsi, rdx, rcx, r8, and r9 to pass function
arguments, in that order (you guessed it, this is also in the ABI). Each register
fits a word (64 bits), and anything that doesn't fit gets pushed to the stack.
/* full example at <https://godbolt.org/z/5c8cb5cxs> */
/* to see the issue, we need a padding value to "mess up" argument alignment */
void foo(char pad, __int128 a, __int128 b, __int128 c) {
printf("%#x\n", pad & 0xff);
print_i128(a);
print_i128(b);
print_i128(c);
}
int main() {
asm(
/* load arguments that fit in registers */
"movl $0xaf, %edi \n\t" /* 1st slot (edi): padding char (`edi` is the
* same as `rdi`, just a smaller access size) */
"movq $0x9900aabbccddeeff, %rsi \n\t" /* 2rd slot (rsi): lower half of `a` */
"movq $0x1122334455667788, %rdx \n\t" /* 3nd slot (rdx): upper half of `a` */
"movq $0x9900aabbccddeeff, %rcx \n\t" /* 4th slot (rcx): lower half of `b` */
"movq $0x1122334455667788, %r8 \n\t" /* 5th slot (r8): upper half of `b` */
"movq $0xdeadbeef4c0ffee0, %r9 \n\t" /* 6th slot (r9): should be unused, but
* let's trick clang! */
/* reuse our stored registers to load the stack */
"pushq %rdx \n\t" /* upper half of `c` gets passed on the stack */
"pushq %rsi \n\t" /* lower half of `c` gets passed on the stack */
"call foo \n\t" /* call the function */
"addq $16, %rsp \n\t" /* reset the stack */
);
}
Running the above with GCC prints the following expected output:
0xaf
0x11223344556677889900aabbccddeeff
0x11223344556677889900aabbccddeeff
0x9900aabbccddeeffdeadbeef4c0ffee0
//^^^^^^^^^^^^^^^^ this should be the lower half
// ^^^^^^^^^^^^^^^^ look familiar?
Surprise!
This illustrates the second problem: LLVM expects an i128 to be passed half in a
register and half on the stack when possible, but this is not allowed by the ABI.
Since the behavior comes from LLVM and has no reasonable workaround, this is a
problem in both Clang and Rust.
Solutions
Getting these problems resolved was a lengthy effort by many people, starting with a
patch by compiler team member Simonas Kazlauskas in 2017: D28990. Unfortunately,
this wound up reverted. It was later attempted again in D86310 by LLVM contributor
Harald van Dijk, which is the version that finally landed in October 2023.
Around the same time, Nikita Popov fixed the calling convention issue with D158169.
Both of these changes made it into LLVM 18, meaning all relevant ABI issues will be
resolved in both Clang and Rust that use this version (Clang 18 and Rust 1.78 when using
the bundled LLVM).
However, rustc can also use the version of LLVM installed on the system rather than a
bundled version, which may be older. To mitigate the chance of problems from differing
alignment with the same rustc version, a proposal was introduced to manually
correct the alignment like Clang has been doing. This was implemented by Matthew Maurer
in #116672.
Since these changes, Rust now produces the correct alignment:
println!("alignment of i128: {}", align_of::<i128>());
// rustc 1.77.0
alignment of i128: 16
As mentioned above, part of the reason for an ABI to specify the alignment of a datatype
is because it is more efficient on that architecture. We actually got to see that
firsthand: the initial performance run with the manual alignment change showed
nontrivial improvements to compiler performance (which relies heavily on 128-bit
integers to work with integer literals). The downside of increasing alignment is that
composite types do not always fit together as nicely in memory, leading to an increase
in usage. Unfortunately this meant some of the performance wins needed to be sacrificed
to avoid an increased memory footprint.
Compatibility
The most imporant question is how compatibility changed as a result of these fixes. In
short, i128 and u128 with Rust using LLVM 18 (the default version starting with
1.78) will be completely compatible with any version of GCC, as well as Clang 18 and
above (released March 2024). All other combinations have some incompatible cases, which
are summarized in the table below:
As mentioned in the introduction, most users will notice no effects of this change
unless you are already doing something questionable with these types.
Starting with Rust 1.77, it will be reasonably safe to start experimenting with
128-bit integers in FFI, with some more certainty coming with the LLVM update
in 1.78. There is ongoing discussion about lifting the lint in an upcoming
version, but we want to be cautious and avoid introducing silent breakage for users
whose Rust compiler may be built with an older LLVM.
Haven’t filled out the nomination form yet? You’re in luck. We are extending the deadline for nominations for 2024’s Rise25 cohort until 5PM PT Friday, April 12th. You can nominate someone you know who is making an impact with AI (or yourself) below:
On the heels of Mozilla’s Rise25 Awards in Berlin last year, we’re excited to announce that we’ll be returning once again with a special celebration that will take place in Dublin, Ireland later this year.
The 2nd Annual Rise25 Awards will feature familiar categories, but with an emphasis on trustworthy AI. We will be honoring 25 people who are leading that next wave of AI — who are using philanthropy, collective power, and the principles of open source to make sure the future of AI is responsible, trustworthy, inclusive and centered around human dignity.
2023 was indeed the year of AI, and as more people adopt it, we know it is a technology that will continue to impact our culture and society, act as a catalyst for innovation and creation, and be a medium to engage people from all walks of life in conversations thanks to its growing ubiquity in our everyday lives.
We know we cannot do this alone: At Mozilla, we believe the most groundbreaking innovations emerge when people from diverse backgrounds unite to collaborate and openly trade ideas.
Five winners from each of the five categories below will be selected to make up our 2024 Rise25 cohort:
Advocates –Guiding AI towards a responsible future
These are the policymakers, activists, and thinkers ensuring AI is developed ethically, inclusively, and transparently. This category also includes those who are adept at translating complex AI concepts for the broader public — including journalists, content creators, and cultural commentators. They champion digital rights and accessible AI, striving to make AI a force for societal good.
Builders – Developing AI through ethical innovation
They are the architects of trustworthy AI, including engineers and data scientists dedicated to developing AI’s open-source language infrastructure. They focus on technical proficiency and responsible and ethical construction. Their work ensures AI is secure, accessible, and reliable, aiming to create tools that empower and advance society.
Artists – Reimagining AI’s creative potential
They transcend traditional AI applications, like synthesizing visuals or using large language models. Their projects, whether interactive websites, films, or digital media, challenge our perceptions and demonstrate how AI can amplify and empower human creativity. Their work provokes thought and offers fresh perspectives on the intersection of AI and art.
Entrepreneurs – Fueling AI’s evolution with visionary ventures
These daring individuals are transforming imaginative ideas into reality. They’re crafting businesses and solutions with AI to meet societal needs, improve everyday life and forge new technological paths. They embody innovation, steering startups and projects with a commitment to ethical standards, inclusiveness and enhancing human welfare through technology.
Change Agents – Cultivating inclusive AI
They are challengers that lead the way in diversifying AI, bringing varied community voices into tech. They focus on inclusivity in AI development, ensuring technology serves and represents everyone, especially those historically excluded from the tech narrative. They are community leaders, corporate leaders, activists and outside-the-box thinkers finding ways to amplify the impacts of AI for marginalized communities. Their work fosters an AI environment of equality and empowerment.
This year’s awards build upon the success of last year’s programming and community event in Berlin, which brought to life what a future trustworthy Internet could look like. Last year’s event crowned trailblazers and visionaries across five distinct categories: Builders, Activists, Artists, Creators, and Advocates. (Psst! Stay tuned as we unveil their inspiring stories in a video series airing across Mozilla channels throughout the year, leading up to the 2nd Annual Rise25 Awards.)
So join us as we honor the innovators, advocates, entrepreneurs, and communities who are working to build a happier, healthier web. Click here to submit your nomination today.
For years, the U.S. government has seen the challenges and opportunities of leveraging AI to advance its mission. Federal agencies have tried to use facial recognition to identify suspects and taxpayers, raising serious concerns about bias and privacy. Some agencies have tried to use AI to identify veterans at higher risk of suicide, where incorrect predictions in either direction can harm veterans’ health and well-being. On the flip side, federal agencies are already harnessing AI in promising ways — from making it easier to forecast the weather, to predicting failures of air navigation equipment, to simply automating paperwork. If harnessed well, AI promises to improve the many federal services that Americans rely upon every day.
That’s why we’re thrilled that, today, the White House established a strong policy to empower federal agencies to responsibly harness the power of AI for public benefit. The policy carefully identifies riskier uses of AI and sets up strong guardrails to ensure those applications are responsible. And, the policy simultaneously creates leadership and incentives for agencies to fully leverage the potential of AI.
The policy is rooted in a simple observation: not all applications of AI are equally risky or equally beneficial. For example, it’s far less risky to use AI for digitizing paper documents than to use AI for determining who receives asylum. The former doesn’t need more scrutiny beyond existing rules, but the latter introduces risks to human rights and should be held to a much higher bar.
Diagram explaining how this policy mitigates AI risks.
Hence, the policy takes a risk-based approach to prioritize resources for AI accountability. This approach largely ignores AI applications that are low risk or appropriately managed by other policies, and focuses on AI applications that could meaningfully impact people’s safety or rights. For example, to use AI in electrical grids or autonomous vehicles, it needs to have an impact assessment, real-world testing, independent evaluation, ongoing monitoring, and appropriate public notice and human override. And, to use AI to filter resumes and approve loans, it needs to include the aforementioned protections for safety, mitigate against bias, incorporate public input, conduct ongoing monitoring, and provide reasonable opt-outs. These protections are based on common sense: AI that’s integral to domains like critical infrastructure, public safety, and government benefits should be tested, monitored, and include human overrides. The specifics of these protections are aligned with years of rigorous research and incorporate public comment so that the interventions are more likely to be both effective and feasible.
The policy applies a similar approach to AI innovation. It calls for agencies to create AI strategies with a focus on prioritizing top AI use cases, reducing barriers to AI adoption, setting goals around AI maturity, and building the capacity needed to harness AI in the long run. This, paired with actions in the AI Executive Order that surge AI talent to high-priority locations across the federal government, sets agencies up to better deploy AI where it can be most impactful.
These rules are also coupled with oversight and transparency. Agencies are required to appoint senior Chief AI Officers who oversee both the accountability and innovation mandates in the policy, and agencies also have to publish their plans to comply with these rules and stop using AI that doesn’t. In general, federal agencies also have to report their AI applications in annual AI use case inventories, and provide additional information about how they are managing risks from safety- and rights-impacting AI. The Office of Management and Budget (OMB) will oversee compliance, and that office is required to have sufficient visibility into any exemptions sought by agencies to the AI risk mitigation practices outlined in the policy.
These practices are slated to be highly impactful. Federal law enforcement agencies — including immigration and border enforcement — should now have many of their uses of facial recognition and predictive analytics subject to strong risk mitigation practices. Millions of people work for the U.S. Government, and now these federal workers will have the protections outlined in this policy if their employers try to surveil and manage their movements and behaviors via AI. And, when federal agencies try to use AI to identify fraud in programs such as food stamps and financial aid, those agencies will now have to make sure that the AI actually works and doesn’t discriminate.
These rules also apply regardless of whether a federal agency builds the AI themselves or purchases it from a vendor. That will have a large market-shaping impact, as the U.S. government is the largest purchaser of goods and services in the world, and agencies will now be incentivized to only purchase AI services that comply with the policy. The policy further directs agencies to share their AI code, models, and data — promoting open-source approaches that are vital for the AI ecosystem broadly. Additionally, when procuring AI services, the policy recommends that agencies promote market competition and interoperability among AI vendors, and avoid self-preferential treatment and vendor lock-in. This all helps advance good government, making sure taxpayer dollars are spent on safe and effective AI solutions, not on risky and over-hyped snake oil from contractors.
Now, federal agencies will work to comply with this policy in the coming months. They will also develop follow-up guidance to support the implementation of this policy, advance better procurement of AI, and govern the use of AI in national security applications. The hard work is not over; there are still outstanding questions to tackle as part of this future work, such as figuring out how to embed open source requirements more explicitly as part of the AI procurement process, helping to reduce agencies’ dependencies on specific AI vendors.
Amidst a flurry of government activity on AI, it’s worth stepping back and reflecting: today is a big day for AI policy. The U.S. government is leading by example with its own rules for AI, and Mozilla stands ready to help make the implementation of this policy a success.
The Rust team has published a new point release of Rust, 1.77.1. Rust is a
programming language that is empowering everyone to build reliable and
efficient software.
If you have a previous version of Rust installed via rustup, getting Rust
1.77.1 is as easy as:
rustup update stable
If you don't have it already, you can get rustup from the
appropriate page on our website.
Rust 1.77.1 therefore disables the new Cargo behavior on Windows for
targets that use MSVC. There are no changes for other targets. We plan to eventually re-enable debuginfo stripping in
release mode in a later Rust release.
Contributors to 1.77.1
Many people came together to create Rust 1.77.1. We couldn't have done it
without all of you. Thanks!
On February 29, Mozilla and the Columbia Institute of Global Politics brought together over 40 leading scholars and practitioners working on openness and AI. These individuals — spanning prominent open source AI startups and companies, non-profit AI labs, and civil society organizations — focused on exploring what “open” should mean in the AI era. We previously wrote about the convening, why it was important, and who we brought together.
Today, we are publishing two readouts from the convening.
The first is a technical memorandum that outlines three different approaches to openness in AI, and highlights different components and spectrums of openness. It includes an extensive appendix that outlines key components in the AI stack, and describes how more openness in each component can help advance system and societal goals. Finally, it outlines open questions that would be worthy of future exploration, digging deeper into the specifics of openness and AI. This memorandum will be helpful for technical leaders and practitioners who are shaping the future of AI, so that they can better incorporate principles of openness to make their own AI systems more effective for their goals and more beneficial for society.
The second is a policy memorandum that outlines how and why policymakers should support openness in AI. It outlines the societal benefits from openness in AI, provides a higher-level overview of how different parts of the AI stack contribute to different opportunities and risks, and lays out a series of recommendations about how policymakers can advance openness in AI. This memorandum will be helpful for policymakers, especially those who are grappling with the details of policy interventions related to openness in AI.
In the coming weeks, we will also be publishing a longer document that goes into greater detail about the dimensions of openness in AI. This will help advance our broader work with partners and allies to tackle complex and important topics around openness, competition, and accountability in AI. We will continue to keep mozilla.org/research/cc updated with materials stemming from the Columbia Convening on Openness and AI.
In the evolving digital landscape, where every click, swipe, and interaction shapes people’s daily lives, the need for robust consumer protection has never been more paramount. The propagation of deceptive design practices, aggressive personalization, and proliferation of fake reviews have the potential to limit or distort choices online and harm people, particularly the most vulnerable, by tricking them into taking actions that are not in their best interest, causing financial loss, loss of privacy, security, and well-being.
At Mozilla, we are committed to building a healthy Internet – an Internet that respects fundamental rights and constitutes a space where individuals can genuinely exercise their choices. Principles 4 and 5 of our Manifesto state that individuals must have the ability to shape the internet and their own experiences on it, while their security and privacy are fundamental and must not be treated as optional. In today’s interconnected world, these are put at stake.
Voluntary commitments by industry are not sufficient, and legislation can play a crucial role in regulating such practices. Recent years have seen the EU act as a pioneer when it comes to online platform regulation. Updating existing EU consumer protection rules and ensuring strong and coherent enforcement of existing legislation will build on this framework to further protect EU citizens in the digital age.
Below, we summarise our recommendations to EU policymakers ahead of the next European Commission mandate 2024-2029 to build a fairer digital world for users and consumers:
Addressing harmful design practices – Harmful design practices in digital experiences – such as those that coerce, manipulate, or deceive consumers – are increasingly compromising user autonomy and reducing choice. They not only thrive at the interface level but also lie deeper in the system’s architecture. We advocate for a clear shift towards ethical digital design through stronger regulation, particularly as technology evolves. This would include stronger enforcement of existing regulations addressing harmful design practices (e.g., GDPR, DSA, DMA). At the same time, the EU should update its consumer protection rules to prohibit milder ‘dark patterns’ and introduce an anti-circumvention clause to ensure that no bypassing of legal requirements by design techniques will be possible.
Balancing personalization & privacy online – Personalization in digital services enhances user interaction but poses significant privacy risks and potential biases, leading to the exposure of sensitive information and societal inequalities. To address these issues, our key recommendations include the adoption of rules that will ensure the enforcement of consumer choices given through consent processes. Such rules should also incentivise the use and uptake of privacy-enhancing technologies through legislation (e.g. Consumer Rights Directive) to strike the right balance between personalization practices and respect of privacy online.
Tackling fake reviews – The growing problem of fake reviews on online platforms has the potential to mislead consumers and distort product value. We recommend stronger enforcement of existing rules, meaningful transparency measures, including explicit disclosure requirements for incentivized reviews, increased accountability for consumer-facing online platforms, and consistency across the EU and internationally in review handling to ensure the integrity and trustworthiness of online reviews.
Rethinking the ‘average consumer’ – The traditional definition of the ‘average consumer’ in EU consumer law is characterised as “reasonably well informed, observant, and circumspect”. The digital age directly challenges this definition as consumers are increasingly more vulnerable online. Due to the ever-growing information asymmetry between traders and consumers, the yardstick of an ‘average consumer’ does not necessarily reflect existing consumer behaviour. For that reason, we ask for the reevaluation of this concept to reflect today’s reality. Such an update will actively lower the existing threshold and thus increase the overall level of protection and prevent the exploitation of vulnerable groups, especially in personalised commercial practices.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization. The following
RFCs would benefit from user testing before moving forward:
No calls for testing were issued this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing
label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature
need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
An overall fairly quiet week with the unfortunate one exception of large instruction count and binary size regressions caused by changes in const evaluation. This was largely balanced out (at least in instruction count) by a group of small improvements, but the compiler did end up 0.2% slower on average across 97 benchmarks.
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
"Top contributor" is not a place of glory, it should go to a bot because people should work at a sustainable pace and prioritize touching grass every once in a while. If a person ever works harder than bors, that's a problem!
I’m super excited to share that Konstantina is joining the Customer Experience team to help with the community in SUMO. Some of you may already know Konstantina because she’s been around in Mozilla for quite a while. She’s transitioning internally from the Community Programs team under Marketing to the Customer Experience team under the Strategy and Operation.
Here’s a bit more about Konstantina in her own words:
Hi everyone, my name is Konstantina and I am very happy I am joining your team! I have been involved with Mozilla since 2011, initially as a volunteer and then as a contractor (since late 2012). During my time here, I have had a lot of roles, from events organizer, community manager to program manager, from working with MDN, Support, Foxfooding, Firefox and many more. I am passionate about communities and how we bring their voices to create great products and I am joining your team to work with Kiki on creating a great community experience. I live in Berlin, Germany with my partner and our cat but I am originally from Athens, Greece. Fun fact about me, I studied geology and I used to do a lot of caving, so I know a lot about ropes and rappelling (though I am a bit rusty now). I also love building legos as you will soon see from my office background. Can’t wait to get to know you all more
Please join me to welcome Konstantina (back) to SUMO!
This month’s topics for our Thunderbird Community Office Hours will be decided by you! We’d like to invite the community to bring their questions, comments, and general conversation to Team Thunderbird for an informal and informational chat. As always, send your questions in advance to officehours@thunderbird.net!
Be sure to note the change in day of the week and time, especially if you’re in Europe and not on summer time yet!
March Office Hours: Open Forum and FAQ
While we love having community office hours with specific topics, from our design process to Add-ons, we want to make time for an open forum, where you bring the topics of discussion. Do you have a great idea for a feature request, or need help filing a bug? Or do you want to know how to use SUMO better, or get some Thunderbird tips? Maybe you want to know more about Team Thunderbird, whether it’s how we got started in open source to how we like our coffee. This is the time to ask these questions and more!
We also just got back from SCaLE21x, and we had so many great questions from people who stopped by the booth. So in addition to answering your questions, whether emailed or live, we’d like to tackle some the things people asked most during our first SCaLE appearance.
Catch Up On Last Month’s Thunderbird Community Office Hours
While you’re thinking of questions to ask, watch last month’s office hours with John Bieling all about Add-on development. We had a fantastic chat about the history, present state, and future of Add-ons, with advice on getting involved in development and support. Watch the video below and read more about our guest at last month’s blog post.
Update | 27 March 2024: Mozilla has submitted its comments to the NTIA’s consultation on openness in AI models referenced in this blog post originally. Drawing on Mozilla’s own history as part of the open source movement, the submission seeks to help guide difficult conversations about openness in AI. First, we shine a light on the different dimensions of openness in AI, including on different components across the AI stack and development lifecycle. Second, we argue that openness in AI can spur competition and help the diffusion of innovation and its benefits more broadly across the economy and society as a whole; that it can advance open science and progress in the entire field of AI; and that it advances accountability and safety by enabling more research and supporting independent scrutiny as well as regulatory oversight. In the past and with a view to recent progress in AI, openness has been a key tenet of U.S. leadership in technology — but ill-conceived policy interventions could jeopardize U.S. leadership in AI. We also recently published the technical and policy readouts from the Columbia Convening on Openness and AI to serve as a resource to the community, both for this consultation and beyond.
Civil society and academics are joining together to defend AI openness and transparency. Mozilla and the Center for Democracy & Technology (CDT), along with members of civil society and academia, have united to underscore the importance of openness and transparency in AI. Nearly 50 signatories sent a letter to Secretary Gina Raimondo in response to the U.S. Commerce Department’s request for comment on openness in AI models.
“We are excited to collaborate with expert individuals and organizations who are committed to seeing more transparent AI innovation,” said Jenn Taylor Hodges, Director of US Public Policy & Government Relations at Mozilla. “Open models in AI will promote trustworthiness and accountability that will better serve society. Mozilla has a long history of promoting open source and fighting corporate consolidation on the Internet. We are bringing those values and experiences to the AI era, making sure that everyone has a say in shaping the future of AI.”
There has been a noticeable shift in the AI landscape toward closed systems, a trend that Mozilla has diligently worked to counter. As detailed in the recently released Accelerating Progress Toward Trustworthy AI report, prominent AI entities are adopting closed systems, prioritizing proprietary control over collaborative openness. These companies have advocated for increased opacity, citing fears of misuse. However, beneath these arguments lies a clear agenda to stifle competition and limit oversight in the AI market.
The joint letter was sent in advance of the Department of Commerce’s comment deadline on AI models which closes March 27. Endorsed by science policy think tanks, advocates against housing discrimination, and computer science luminaries, it argued:
Open models have significant benefits to society: They help advance innovation, competition, research, civil and human rights protections, and safety and security.
Policy should look at marginal risks of open models compared to closed models: Commerce should look to recent Stanford and Princeton research, which emphasizes limited evidence that open models create new risks not present in closed models.
Policy should focus more on AI applications, not models: Where openness makes AI risks worse, policy interventions are more likely to succeed in going after how the AI system is deployed, not by restricting the sharing of information about AI models.
Policy should proactively advance openness: Policy on this topic must be developed and vetted by more than just national security agencies, and should promote more R&D into open approaches for AI and better standards for testing and releasing open models.
“The range of participants in this effort – from civil liberties to civil rights organizations, from progressive groups to more market-oriented groups, with advocates for openness in both government and industry, and a broad range of academic experts from law, policy, and computer science – demonstrates how the future of open innovation around powerful AI models is critically important to a wide variety of communities,” said Kevin Bankston, Senior Advisor on AI Governance for CDT. “As our letter highlights, the benefits of open models over closed models for competition, innovation, security and transparency are rather clear, while the risks compared to closed models aren’t. Therefore the White House and Congress should exercise great caution when considering whether and how to regulate the publication of open models.”
Mozilla’s upcoming longer submission to the Commerce Department’s request for comment will include greater details including expanding on Mozilla’s long history of increasing privacy, security, and functionality across the internet through its products, investments, and advocacy. It highlights key findings from the recent Columbia Convening on Openness and AI, and explains how openness is vital to innovation, competition, and accountability – including safety and security, as well as protecting rights and freedoms. It also takes on some of the most prominent arguments driving the push to limit access to AI models, such as claims of “unknown unknown” security risks.
The joint letter and Mozilla’s upcomingresponse to the call for comments demonstrates how openness can be an enabler of a better future – one where everyone can help build, shape, and test AI so that it works for everyone. That is the future we need, and it’s the one we must keep working toward through policy, technology, and advocacy alike.
Developer Tools help developers write and debug websites on Firefox. This newsletter gives an overview of the work we’ve done as part of the Firefox 124 Nightly release cycle.
Firefox being an open source project, we are grateful to get contributions from people outside of Mozilla:
Oliver Schramm fixed the Geometry Editor which could be misplaced when the page was zoomed in (#1877890)
Redfirerf corrected an erroneous comment in our Console API implementation (#1879991)
As we were wrapping up projects at the end of 2023 and discussing plans for 2024, we decided that the whole team would spend a couple months focusing on known performance issues. We stuck to the plan and are proud to start reporting the fruits of our labor
We already did a similar project last year with great results, especially on the Console and the Debugger, but this time we felt like the Inspector needed some love too, fixing reports of extreme cases that make DevTools crumble. For example, we had a bug filed a few years ago where displaying 10000 rules was hanging the Rules view (#1247751). A specific function, used to compute information about the CSS Rules, was taking 7000ms (yes 7s) on my machine. After giving it a very hard look (and providing a patch), it now only takes around 50ms, a very nice 99% improvement!
Last month, we already reported some improvements on the Console when it contains a lot of messages. We kept digging (#1875045) and the Console is now almost 5 times faster when adding new messages when there’s already more than 10000 messages displayed. Our performance test also reports a 25% improvement when reloading the Console.
<figcaption class="wp-element-caption">Performance test duration going from ~5s to ~1s</figcaption>
Coincidentally, we got a report (#1879575) from a Mozilla employee that the Debugger was freezing on one of their project, which had a lot of JavaScript files. We analyzed the performance profile they recorded with the Firefox Profiler and were able to reduce the time spent adding sources by 25%.
Finally, we started some preliminary work to remove the main source of slowness in the Debugger: Babel, which we use to build Abstract Syntax Trees. For example, we use this to build the expression we need to evaluate to display properties in the Variable Tooltip. Babel is great, but we want to explore and see if we can get faster performance in other ways. And you know the saying, when you have a hammer, everything looks like a nail, and so we implemented a few things over the years, relying on Babel, where something faster could have been used. So first, we’re going to remove all the unnecessary usage of Babel (#1878061 is a first step). And then, since we’re using CodeMirror to display the file content, and given that the newest version of CodeMirror uses a very capable and efficient parser (Lezer), we’re going migrate to this new version (we’re still using version 5), in the hope of reusing part of what CodeMirror is already doing to display the source. We’re using CodeMirror in quite a few places, and some consumers are making extensive usage of its different APIs, so the migration will take a bit of time. For now, we started small and migrated our first consumer, the EventTooltip in the markup view (#1878605).
Various fixes and improvements
Although we’re focusing a lot of our time on performance, we’re still actually maintaining the toolbox and fixing annoying bugs that our wonderful users report in Bugzilla. In no particular order we:
fixed an issue in the Debugger variable tooltip when hovering variables named values (#1876297)
ensured that text selection works fine in the Debugger (#1878698, #1880428)
prevented CSS values to be translated in the Inactive CSS tooltip (#1878651)
fixed the autocomplete for color CSS variables in the Inspector (#1582400)
Speaking of the Inspector, the property name will now autocomplete with existing CSS variables (#1867595), making very easy to redefine them on a given CSS rule:
<figcaption class="wp-element-caption">Easy access to existing CSS variables</figcaption>
Finally, a setting was added in the preference panel to control if the Enter key should move the focus to the next input in the Rules view (#1876694), for those of you who liked the behavior we briefly added (and reverted) in 122 (see https://fxdx.dev/rules-view-enter-key/)
Thank you for reading this and using our tools, see you next month for a new round of updates
The Rust team is happy to announce a new version of Rust, 1.77.0. Rust is a programming language empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, you can get 1.77.0 with:
If you'd like to help us out by testing future releases, you might consider updating locally to use the beta channel (rustup default beta) or the nightly channel (rustup default nightly). Please report any bugs you might come across!
What's in 1.77.0 stable
This release is relatively minor, but as always, even incremental improvements lead to a greater whole. A few of those changes are highlighted in this post, and others may yet fill more niche needs.
C-string literals
Rust now supports C-string literals (c"abc") which expand to a nul-byte
terminated string in memory of type &'static CStr. This makes it easier to write code
interoperating with foreign language interfaces which require nul-terminated
strings, with all of the relevant error checking (e.g., lack of interior nul
byte) performed at compile time.
Support for recursion in async fn
Async functions previously could not call themselves due to a compiler
limitation. In 1.77, that limitation has been lifted, so recursive calls are
permitted so long as they use some form of indirection to avoid an infinite
size for the state of the function.
1.77.0 stabilizes offset_of! for struct fields, which provides access to the
byte offset of the relevant public field of a struct. This macro is most useful
when the offset of a field is required without an existing instance of a type.
Implementing such a macro is already possible on stable, but without an
instance of the type the implementation would require tricky unsafe code which
makes it easy to accidentally introduce undefined behavior.
Users can now access the offset of a public field with offset_of!(StructName, field). This expands to a usize expression with the offset in bytes from the
start of the struct.
Enable strip in release profiles by default
Cargo profiles
which do not enable debuginfo in
outputs (e.g., debug = 0) will enable strip = "debuginfo" by default.
This is primarily needed because the (precompiled) standard library ships with
debuginfo, which means that statically linked results would include the
debuginfo from the standard library even if the local compilations didn't
explicitly request debuginfo.
Users which do want debuginfo can explicitly enable it with the
debug
flag in the relevant Cargo profile.
Hello and Welcome to the SpiderMonkey Newsletter for Firefox 124-125. It’s Matthew Gaudet back again. This newsletter is a way in which we can share what we have been working on as a team, and highlight some interesting changes when they happen.
“20-30% reduction in GC time across desktop platforms”
“10% reduction in GC max pause time”
“10% fewer GC slices”
“Telemetry indicates this is working well. Mark rate increased by 50-60%, median total GC time decreased by 35% (and by more for longer collections) and median max pause time decreased by 20%.”
Sometimes a contributor comes along who decides that one of the ways they can help is by taking ownership of an area, and making steady improvement forwards. This was the case with Vinny Diehl who has come in and become an expert on Date.parse. This is a challenging method, because it is simultaneously commonly used while extremely underspecified, leading to lots of implementation defined behaviour. This kind of implementation defined behaviour can be bad for Firefox, as dates that are parsed correctly by Chrome or Safari might not be parsed correctly by Firefox, leading to web interoperability problems.
Vinny has been working on improving this, and has made enormous strides in helping to push this challenging area forward. In his own words:
Vinny Diehl is a helicopter pilot who dabbles in software development and reverse engineering in his spare time. He has worked on flight simulators, game engines, and Nintendo decompilation projects, among other things. With a growing interest in browser work, he has made it his mission to perfect SpiderMonkey’s date parsing compatibility. You can view some of his work in the meta bug.
Huge amounts of gratitude to Vinny for tackling this and making Firefox more compatible for everyone.
Jan has made it possible to use the Firefox Pref system inside of SpiderMonkey. This is going to make it dramatically easier to make code activate conditionally with far less boilerplate than currently exists, and naturally cooperates directly with the current Firefox Preferences system!
WebDriver is a remote control interface that enables introspection and control of user agents. As such it canhelp developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we’ve done as part of the Firefox 124 release cycle.
Contributions
With Firefox being an open source project, we are grateful to get contributions from people outside of Mozilla.
New: Support for the “storage.getCookies” and “storage.setCookie” commands
First off, we are introducing 2 new commands from the “storage” module to interact with HTTP cookies.
The storage.getCookies command allows to retrieve cookies currently stored in the browser. You can provide a filter argument to only return cookies matching specific criteria (for instance size, domain, path, …). You can also use the partition argument to retrieve cookies owned by a certain partition. You can read more about state partitioning in this MDN article.
The second command storage.setCookie allows to create a new cookie. This command expects a cookie argument with properties describing the cookie to create: name, value, domain, … Similarly to getCookies, you can provide a partition argument which will be used to build the partition key of the partition which should own the cookie.
Below is a quick example using those commands to set and get a cookie, without using partition keys.
New: Basic support for network request interception
With Firefox 124, we are enabling several commands from the network module to allow you to intercept network requests.
Before diving into the details of the various commands, a high level summary of the way this feature works. Requests can be intercepted in three different phases: beforeRequestSent, responseStarted and authRequired. In order to intercept requests, you first need to register network “intercepts”. A network intercept tells the browser which URLs should be intercepted (using simple URL patterns), and in which phase.You might notice that the name of the three phases correspond to some of the network events. This is intentional: when raising a network event, the request will be intercepted if any intercept registered for the corresponding phase matches the URL of the request. Those events will contain additional information in their payload to let you know if the request was blocked or not. When a request is intercepted, it will be paused until you use one of the network interception commands to resume it, modify it or cancel it.
The first two commands will allow you to manage the list of intercepts currently in use. The network.addIntercept command expects a phases argument, which is the list of phases where the intercept will be active, and an optional urlPatterns argument which is a list of URL patterns that will be used to match individual requests. If urlPatterns is omitted, the intercept will match all requests regardless of their URL. This command returns the unique id for the created intercept. You can then use the network.removeIntercept command to remove an intercept, by providing its unique id in the intercept argument.
For instance, adding an intercept to block all requests to https://fxdx.dev/ in the beforeRequestSent phase can be done as shown below:
Now, assuming you are subscribed to network.beforeRequestSent events for a context where you try to navigate to https://fxdx.dev/, you will get an event payload similar to this:
Note the isBlocked flag set to true, and the intercepts list containing the id for the intercept added earlier. At this point, the request is blocked, and it’s a good time to take a look at which methods you can use to unblock it. Two small notes before moving forward. First remember to subscribe to network events, adding an intercept for “beforeRequestSent” will not transparently subscribe you to network.beforeRequestSent events. Second, removing an intercept with network.removeIntercept will not automatically unblock intercepted requests, they still need to be unblocked individually.
In order to handle intercepted requests, you can use several network commands:
network.continueRequest allows to continue a request blocked in the beforeRequestSent phase. It expects a unique id for the request in the request argument. As you can see in the specification, the command also supports several optional arguments to modify the request headers, cookies, method, URL, … However at the moment we do not support those optional arguments, only request is supported.
network.continueResponse allows to continue a request blocked either in the responseStarted or the AuthRequired phase. Similar to network.continueRequest, the command expects a mandatory request argument, and other optional arguments are not supported yet.
network.continueWithAuth is dedicated to handle requests in the AuthRequired phase, which is especially useful when testing websites using HTTP Authentication. This command expects an action argument which can either be "cancel", "default" or "provideCredentials". The cancel action will fail the authentication attempt. The default action will let the browser handle the authentication via a username / password prompt. Finally, the provideCredentials action expects a credentials argument containing a username and a password. If the credentials are wrong, you will receive another network.authRequired event when the authentication attempt fails, and you can use network.continueWithAuth again to unblock the request.
network.failRequest can be used in any of the intercept phases, and will cancel the ongoing request, leading to a network.fetchError event. This command only expects a request argument to identify the request to cancel.
network.provideResponse can be used in any of the intercept phases. Similar to network.continueRequest, we only support the request argument at the moment. But in the future this command will allow to set the response body, headers, cookies, …
Back to the example of our request to https://fxdx.dev, we can use network.failRequest to cancel the request, and receive a network.fetchError event in case we are subscribed to those events:
With Firefox 124 we are also adding support for user contexts. User contexts are collections of top-level browsing contexts (tabs) which share the same storage partition. Different user contexts cannot share the same storage partition, so this provides a way to avoid side effects between tests. In Firefox, user contexts are implemented via Containers.
The browser.getUserContexts command will return the list of current user contexts as a list of UserContextInfo objects containing the unique id for each context. This will always include the default user context, which is assigned the id "default".
The browser.removeUserContext command allows to remove any existing user context, except for the default one. This command expects a userContext argument to provide the unique id of the user context that should be removed.
Support for userContext with “browsingContext.create” and “browsingContext.Info”
The browsingContext.create command has been updated to support the optional userContext argument, which should be the unique id of an existing user context. If provided, the new tab or window will be owned by the corresponding user context. If not, it will be assigned to the “default” user context.
<figcaption class="wp-element-caption">Firefox windows and tabs created in different containers using browsingContext.create</figcaption>
Support for contexts argument in “script.addPreloadScript”
The script.addPreloadScript command now supports an optional contexts argument so that you can restrict in which browsing contexts a given preload script will be executed. This argument should be a list of unique context ids. If not provided, the preload script will still be applied to all browsing contexts.
We fixed an issue with Get Element Text, which ignored the slot value of a web component when no custom text is specified. To give an example, with the following markup, the command will now successfully return “foobar” as the text for the custom element, instead of “bar” previously:
Developer Tools help developers write and debug websites on Firefox. This newsletter gives an overview of the work we’ve done as part of the Firefox 123 Nightly release cycle.
Firefox being an open source project, we are grateful to get contributions from people outside of Mozilla. Many thanks to Aaron who added a “Save as File” context menu entry in the Network panel so (mostly) all responses can be saved to disk (#1221964)
A source map is a file that maps from a generated source, i.e. the actual Javascript source the browser runs, to the original source, which could be typescript, jsx, or even regular JS file that was compressed. This enables DevTools to display code to the developers in the way they wrote it.
It can happen that a referenced source map file can’t be retrieved by the Debugger, or that it’s invalid, and in such case, we’ll now show a warning message in the editor to indicate why we can only show the generated source (#1834725).
Still related to source map, a link to the original source is now displayed in the footer when selecting a location in a generated source (#1834729).
We some time fixing common issues that were affecting the Preview Popup, which is displayed when hovering variables (#1873147, #1872715, #1873149). It should now be more solid and reliable, but less us know if you’re still having problem with it!
Finally, we fixed a nasty bug that could crash the Debugger (#1874382).
Misc
We vastly improved console performance when there is a lot of messages being displayed (#1873066, #1874696) and fixed logging of cross-origin iframe’s contentWindow (#1867726) and arrays in workers (#1874695).
The Network panel timing markers for Service Worker interception are now displayed correctly (#1353798).
We fixed a couple regressions in the Inspector. The first one was preventing using double click edit attribute with URLs in the markup view (#1870214), and the second was adding extra line when copy/pasting rule from the Rules view (#1876220).
Thank you for reading this and using our tools, see you next month week for a new round of updates
Calling all extension developers! With Manifest V3 picking up steam again, we wanted to provide some visibility into our current plans as a lot has happened since we published our last update.
Back in 2022 we released our initial implementation of MV3, the latest version of the extensions platform, in Firefox. Since then, we have been hard at work collaborating with other browser vendors and community members in the W3C WebExtensions Community Group (WECG). Our shared goals were to improve extension APIs while addressing cross browser compatibility. That collaboration has yielded some great results to date and we’re proud to say our participation has been instrumental in shaping and designing those APIs to ensure broader applicability across browsers.
We continue to support DOM-based background scripts in the form of Event pages, and the blocking webRequest feature, as explained in our previous blog post. Chrome’s version of MV3 requires service worker-based background scripts, which we do not support yet. However, an extension can specify both and have it work in Chrome 121+ and Firefox 121+. Support for Event pages, along with support for blocking webRequest, is a divergence from Chrome that enables use cases that are not covered by Chrome’s MV3 implementation.
Well what’s happening with MV2 you ask? Great question – in case you missed it, Google announced late last year their plans to resume their MV2 deprecation schedule. Firefox, however, has no plans to deprecate MV2 and will continue to support MV2 extensions for the foreseeable future. And even if we re-evaluate this decision at some point down the road, we anticipate providing a notice of at least 12 months for developers to adjust accordingly and not feel rushed.
As our plans solidify, future updates around our MV3 efforts will be shared via this blog. We are loosely targeting our next update after the conclusion of the upcoming WECG meeting at the Apple offices in San Diego. For more information on adopting MV3, please refer to our migration guide. Another great resource worth checking out is the recent FOSDEM presentation a couple team members delivered, Firefox, Android, and Cross-browser WebExtensions in 2024.
If you have questions, concerns or feedback on Manifest V3 we would love to hear from you in the comments section below or if you prefer, drop us an email.
User research about advertising, personalization, and privacy is surprisingly consistent. In a replication prediction market, I would invest in futures on any research that shows:
About 30 percent of people want personalized ads.
About 30 percent of people don’t want personalized ads.
For the other 40 percent it depends how you ask.
A lot of good work has been done in this area, but the results are inconvenient for anybody who wants to be able to build one set of online advertising software and settings for everybody. People are different. Research links, in order of percentage of pro-personalization people found.
18%
McDonald et al. did in-person interviews with questions on people’s knowledge and preferences about Internet ads.
30% agree with No one should use data from Internet history to personalize ads.
18% agree with Glad to have relevant advertisements about things I am interested in instead of random advertisements
36% are Personalized Pioneers who say they want personalized ads
55% say that personalized ads creep them out.
42%
IAB Europe did a survey of 11,020 European Internet users.
42% don’t mind personalized ads based on browsing data
20% don’t mind having data shared with third parties for ads
47% (or 30%)
U.S. Internet Users Ready to Limit Online Tracking for Ads In a Gallup poll of 1,019 adults, 30% agree that advertisers should be allowed to match ads to interests based on websites visited but 47% want to be able to allow advertisers they choose to personalize ads to them in some way. (It depends how you ask.)
59.2%
A report from Didomi, a consent management platform company, reports 59.2% of users opting in to a Transparency and Consent Framework (TCF) consent dialog.
People are different
Some people are privacy people and I’m one. Personally I don’t understand why anybody would want a personalized ad at all. I’m most likely to get any use from advertising when I need to buy unfamiliar stuff, and that happens when I’m learning about a new activity that I’m not good at. I want to see the same ads that show up for people who already know the skills and the scene, and would raise a stink about a deceptive ad in their information space. As far as I can tell, personalization makes advertising work in the wrong direction.
Some people are personalization people and don’t understand why you wouldn’t want a personalized ad. If you’re going to look at an ad anyway it might as well be for something that you’re more likely to buy. (But I want to see the same ad that a company is willing to show to the regulators, editors, and experts in their community of practice, not what they think they can get some random person to click on. I don’t understand Kevin and he doesn’t understand me.)
Other people, the biggest group at 40 percent, are probably better off not overthinking online ads and, instead, learning about other stuff.
Whatever a person prefers,Can database marketing sell itself to the people in the database? it seems to be about the personalization using any information from outside the context in which the ad appears—cross-context behavioral advertising—not about individualized tracking. Jerath et al. found similar perceived privacy violations (PPV) for new ad personalization technologies that prevent individual identifiers from being used: New technologies or proposals that ensure that data are kept on the consumer’s machine lower PPV relative to behavioral targeting but, importantly, this decrease is small. Furthermore, group-level targeting does not differ significantly from individual-level targeting in reducing PPV. The IAB and Gallup studies imply that there is a cohort of users who want personalization but not cross-context tracking, but safer personalization looks like a small add-on to the 30%, not a widely held preference that splits off a chunk of users from the core anti-personalization group.
People might want the law as protection from “people search” and other business models, not just advertising
People might vote for an option they don’t plan to exercise (or would use only against non-ad holders of their info)
In the 2020 election, pro-surveillance-advertising organizations didn’t come out to defend their side. Instead, the argument against on the state mailer was from organizations that claimed Prop. 24 didn’t go far enough, and left too many loopholes for big companies. Some of the “no” vote might have been extra pro-privacy people. A poll before the election showed 81% support for the proposition.
Pagefair’s Research result: what percentage will consent to tracking for advertising? is the source for low-personalization/high-privacy claims like Only a very small proportion (3%) believe that the average user will consent to web-wide tracking for the purposes of advertising (tracking by any party, anywhere on the web). This one isn’t based on talking to users. It’s a pre-GDPR survey of publishers, adtech, brands, and various others asking people’s opinions on what users would do with various GDPR consent dialogs that ended up not being representative of what sites actually ended up deploying.
using the 30-40-30 rule
A lot of this research looks useful as a way to spot deceptive patterns in personalization preferences. If fewer than 30% or more than 70% of users end up with ad personalization turned on, something is probably wrong with the personalization UX or the underlying trustworthiness of the medium.
And when building anything that depends on advertising, it’s going to be hard to build something that only works if everybody who uses it has personalization, or that only works if nobody does. As far as I can tell, adding extra personalization for those who don’t want it just builds support for privacy habits, settings, tools, and laws, in that order. And banning personalization entirely, or building a medium that can’t be tweaked to support it, hasn’t really been tried yet but would probably cause problems of its own.
In my humble opinion, the biggest benefit of the 30-40-30 rule is that it helps justify the decision to support Global Privacy Control everywhere. People are just different, so let everybody pick once whether they want cross-context behavioral advertising everywhere. Yes, I know, I know, under a different set of laws we could have had Global Personalization Control, that would work the other way around so that the work of turning it on would be done by the personalization people and not the privacy people. But GPC is there, it works, and if sites, browsers, and platforms can implement it in a common-sense way you should just be able to turn it on once and be happy for as long as you own the software or device, kind of like Filmmaker Mode on a TV. In the long run, I can safely predict that the fraction of users who turn GPC on will be somewhere between 30 and 70 percent. Which end of the range we end up with will depend in how trustworthy the ads, the Internet, and the economy are in other ways, but that’s another story. More:GPC all the things!
Mozilla recently signed onto an amicus brief – alongside the Electronic Frontier Foundation , the Internet Society, Signal, and a broad coalition of other allies – on the Nevada Attorney General’s recent attempt to limit encryption. The amicus brief signals a collective commitment from these organizations on the importance of encryption in safeguarding digital privacy and security as fundamental rights.
The core of this dispute is the Nevada Attorney General’s proposition to limit the application of end-to-end encryption (E2EE) for children’s online communications. It is a move that ostensibly aims to aid law enforcement but, in practice, could significantly weaken the privacy and security of all internet users, including children. Nevada argues that end-to-end encryption might impede some criminal investigations. However, as the amicus brief explains, encryption does not prevent either the sender or recipient from reporting concerning content to police, nor does it prevent police from accessing other metadata about communications via lawful requests. Blocking the rollout of end-to-end encryption would undermine privacy and security for everyone for a marginal benefit that would be far outweighed by the harms such a draconian limitation could create.
The case, set for a hearing in Clark County, Nevada, encapsulates a broader debate on the balance between enabling law enforcement to combat online crimes and preserving robust online protections for all users – especially vulnerable populations like children. Mozilla’s involvement in this amicus brief is founded on its long standing belief that encryption is an essential component of its core Manifesto tenet – privacy and security are fundamental online and should not be treated as optional.
Looking back at the past year it sure was different than the years before, again.
Obviously we left most of the pandemic isolation behind us and I got to meet more of my coworkers in person:
At the Mozilla All-Hands in Montreal, Canada, though that was cut short for me due to ... of course: Covid.
At PyCon DE and PyData here in Berlin.
And at another workweek with my extended team also here in Berlin.
My work also changed.
As predicted a year ago I branched out beyond the Glean SDK, took a look at our data pipeline,
worked on features across the stack and wrote a ton of stuff that is not code.
Most of that work spanned months and months and some is still not 100% finished.
For this year I'm focusing a bit more on the SDK and client-side world again.
With Glean used just about everywhere it's time we look into some optimizations.
In the past we made it correct first and paid less attention to optimize resource usage (CPU & memory for example).
Now that we have more and more usage in Firefox Desktop (Use Counters!) we need to look into making data collection more efficient.
The first step is to get better insights where and how much memory we use.
Then we can optimize.
Firefox comes with some of its own tooling for that with which we need to integrate, see about:memory for example.
I'm also noticing some parts in our codebase where in hindsight I wish we had made different implementation decisions.
At the time though we did make the right choices, now we need to deal with that (memory usage might be one of these, storage sure is another one).
And Mozilla more broadly?
It's changing. All the time.
We just had layoffs and reprioritization of projects.
That certainly dampens the mood.
Focus shifts and work changes.
But underneath there's still the need to use data to drive our decisions and so I'm rather confident that there's work for me to do.
Thank you
None of my work would happen if it weren't for my manager Alessio and team mates Chris, Travis, Perry, Bruno and Abhishek.
They make it fun to work here, always have some interesting things to share and they still endure my bad jokes all the time.
Thank you!
Thanks also goes out to the bigger data engineering team within Mozilla, and all the other people at Mozilla I work or chat with.
This post was planned to be published more than a week ago. It's still perfectly in time. I wasn't able to focus on it earlier.
In modern technology, interoperability between programs is crucial to the usability of applications, user choice, and healthy competition. Today Mozilla has joined an amicus brief at the Ninth Circuit, to ensure that copyright law does not undermine the ability of developers to build interoperable software.
This amicus brief comes in the latest appeal in a multi-year courtroom saga between Oracle and Rimini Street. The sprawling litigation has lasted more than a decade and has already been up to the Supreme Court on a procedural question about court costs. Our amicus brief addresses a single issue: should the fact that a software program is built to be interoperable with another program be treated, on its own, as establishing copyright infringement?
We believe that most software developers would answer this question with: “Of course not!” But the district court found otherwise. The lower court concluded that even if Rimini’s software does not include any Oracle code, Rimini’s programs could be infringing derivative works simply “because they do not work with any other programs.” This is a mistake.
The classic example of a derivative work is something like a sequel to a book or movie. For example, The Empire Strikes Back is a derivative work of the original Star Wars movie. Our amicus brief explains that it makes no sense to apply this concept to software that is built to interoperate with another program. Not only that, interoperability of software promotes competition and user choice. It should be celebrated, not punished.
This case raises similar themes to another high profile software copyright case, Google v. Oracle, which considered whether it was copyright infringement to re-implement an API. Mozilla submitted an amicus brief there also, where we argued that copyright law should support interoperability. Fortunately, the Supreme Court reached the right conclusion and ruled that re-implementing an API was fair use. That ruling and other important fair use decisions would be undermined if a copyright plaintiff could use interoperability as evidence that software is an infringing derivative work.
Over the past year, Servo has gone a long way towards reigniting the dream of a web rendering engine in Rust. This comes with a lot of potential, and not just towards becoming a viable alternative to WebKit and Chromium for embedded webviews. If we can make the web platform more modular and easily reusable in both familiar and novel ways, and help build web-platform-grade libraries in underlying areas like networking, graphics, and typography, we could really change the Rust ecosystem.
In theory, anything is possible in a free and open source project like ours, and we think projects like Servo and Ladybird have shown that building a web browser with limited resources is more achievable than many have assumed. But doing those things well does take time and money, and we can only achieve Servo’s full potential with your help.
We will stop accepting donations on LFX soon. Any funds left over will also be transferred to the Servo project, but recurring donations will be cancelled, so if you would like to continue your recurring donation, please do so on GitHub or Open Collective.
Both one-time and monthly donations are appreciated, and over 94% of the amount will go directly towards improving Servo, with the remaining 6% going to processing fees. The way the funds are used is decided in public via the Technical Steering Committee, but to give you a sense of scale…
at 100 USD/month, we can cover the costs of our website and other core infrastructure
at 1,000 USD/month, we can set up dedicated servers for faster Windows and macOS builds, better test coverage and reliability, and new techniques like fuzzing and performance testing
at 10,000 USD/month, we can sponsor a developer to make Servo their top priority
If you or your company are interested in making a bigger donation or funding specific work that would make Servo more useful to your needs, you can also reach out to us at join@servo.org.
The new Screenshots component (which replaces the Screenshots built-in extension) is now enabled by default on Nightly (bug 1789727)! This improves upon the extension version of the feature in a number of ways:
You can capture screenshots of about: pages and other pages that extensions cannot normally manipulate
Improved performance!
Greatly improved keyboard and visual accessibility
You can ensure it’s on by default by checking if screenshots.browser.component.enabled is set to true in about:config
You can access the Screenshot feature via the keyboard shortcut (ctrl + shift + s or cmd + shift + s for macos), the context menu, or by adding the Screenshot button to your toolbar via toolbar customization
The Firefox Profiler has a new “Network Bandwidth” feature to record the network bandwidth used between every profiler sample. Example profile
We’ve started early investigations on a profile backup feature. This feature will, in theory, allow users to create backups of their user profile in an archive on the local file system. We’re still very early days here, but we have a meta bug here that people can follow along with.
Collected here are the most recent blog posts from all over the Mozilla community.
The content here is unfiltered and uncensored, and represents the views of individual community members.
Individual posts are owned by their authors -- see original source for licensing information.





 <figcaption class="wp-element-caption">Finn Lützow-Holm Myrstad at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Finn Lützow-Holm Myrstad at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>

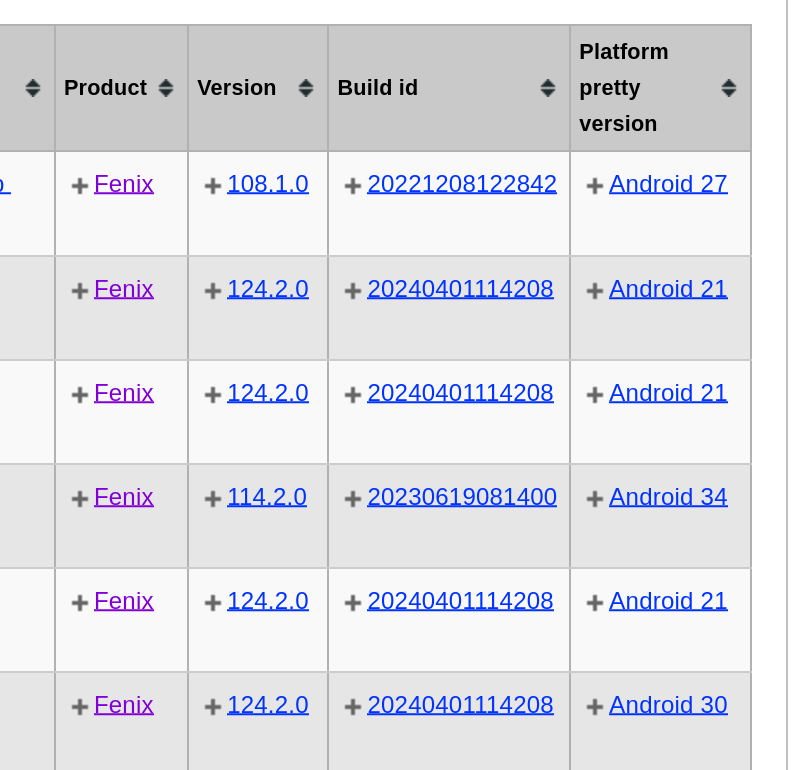
 <figcaption class="wp-element-caption">Marek Tuszynski at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Marek Tuszynski at Mozilla’s Rise25 award ceremony in October 2023.</figcaption> <figcaption>protip: use cowsay(1) to alert the user to errors in Makefile before restarting</figcaption>
<figcaption>protip: use cowsay(1) to alert the user to errors in Makefile before restarting</figcaption>  <figcaption>screenshot of several fake Facebook profiles, all using the same two photos of retired US Army General Mark Hertling</figcaption>
<figcaption>screenshot of several fake Facebook profiles, all using the same two photos of retired US Army General Mark Hertling</figcaption>  <figcaption>In AIC polls, confidence in Amazon, Meta, and Google has fallen since 2018.</figcaption>
<figcaption>In AIC polls, confidence in Amazon, Meta, and Google has fallen since 2018.</figcaption>  <figcaption class="wp-element-caption">Rachel Hislop at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Rachel Hislop at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>

 ) for us to reproduce the issue and come up with a
) for us to reproduce the issue and come up with a 
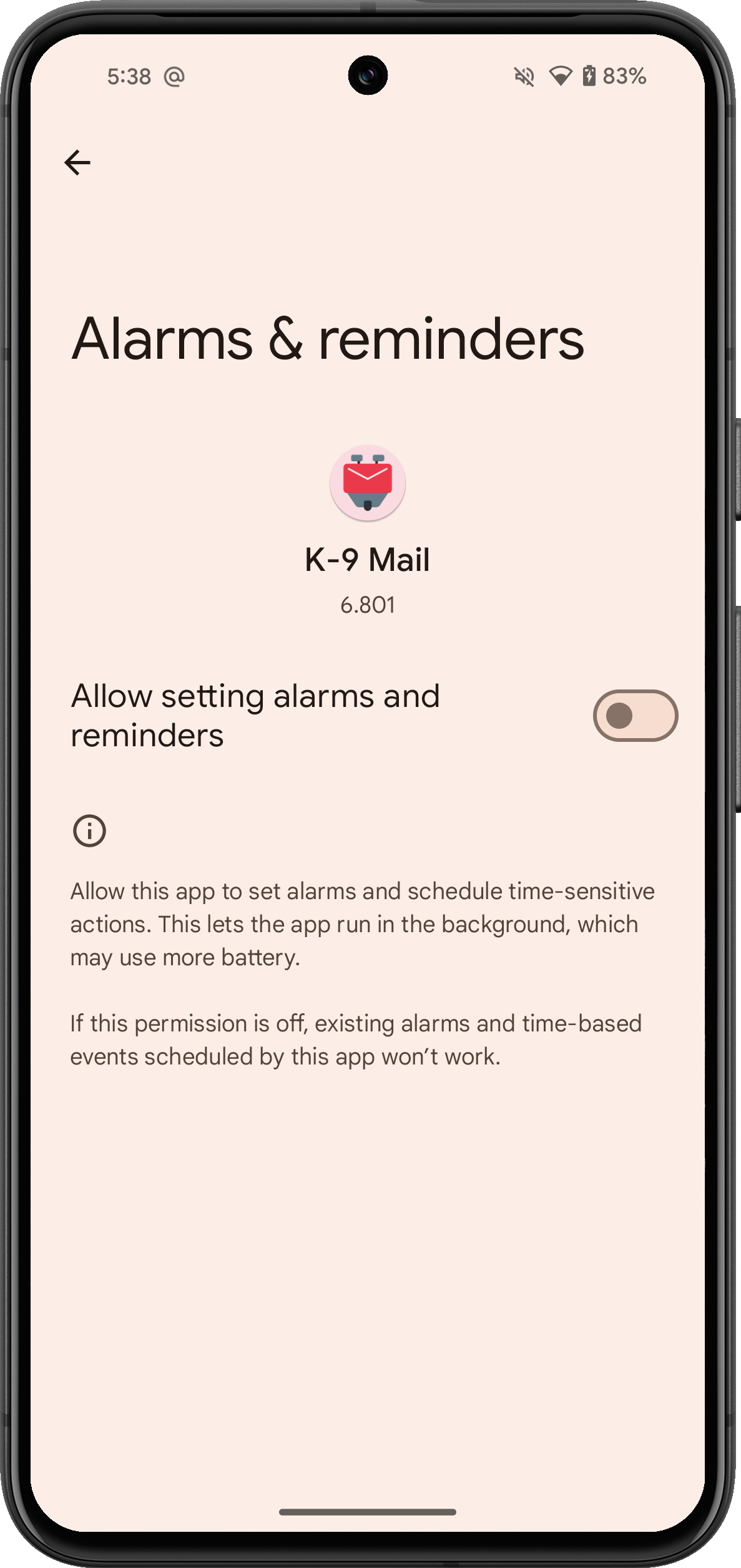








 xpidump is available in the browser thanks to WebAssembly!
xpidump is available in the browser thanks to WebAssembly!
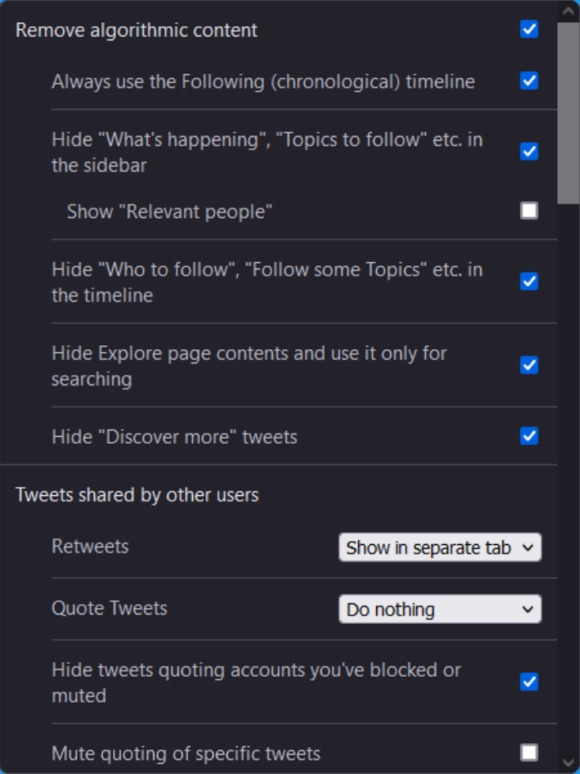
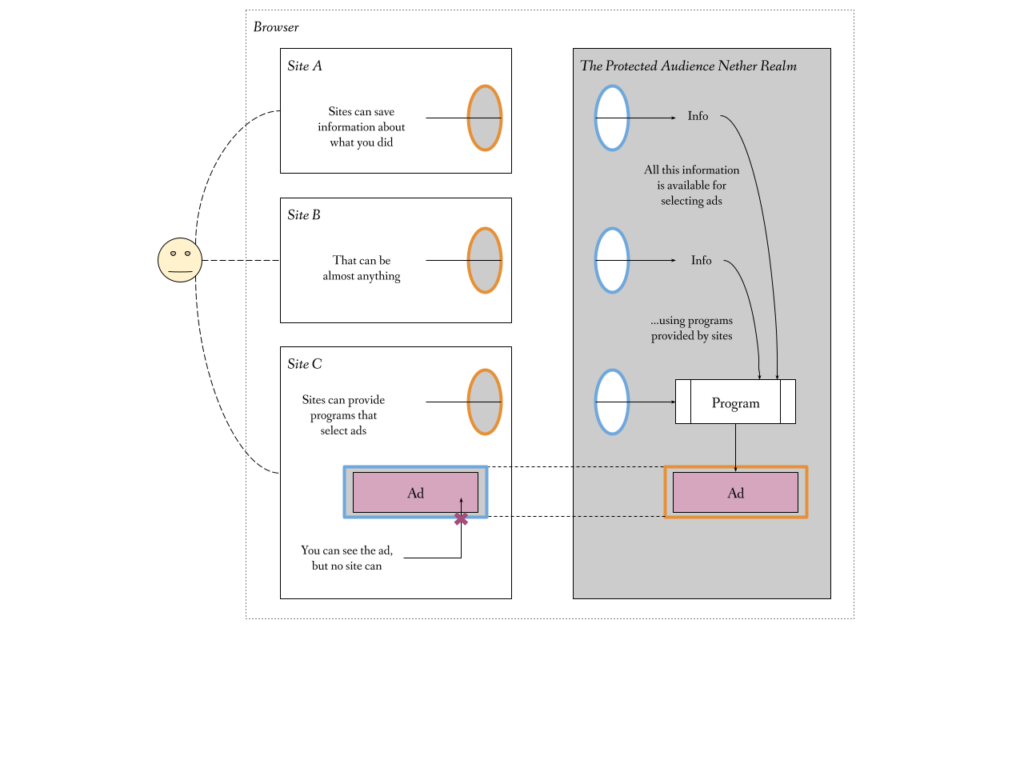
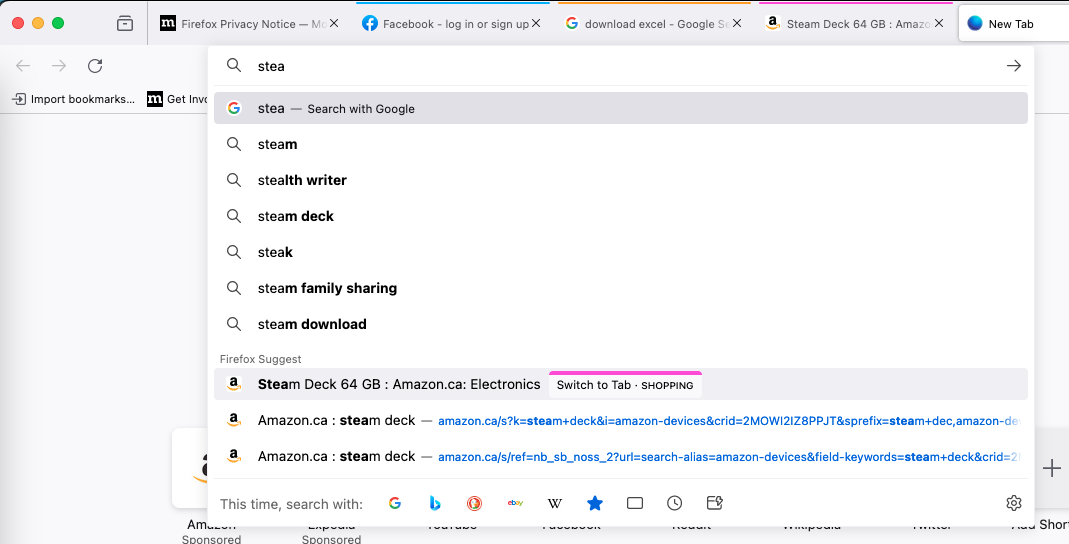

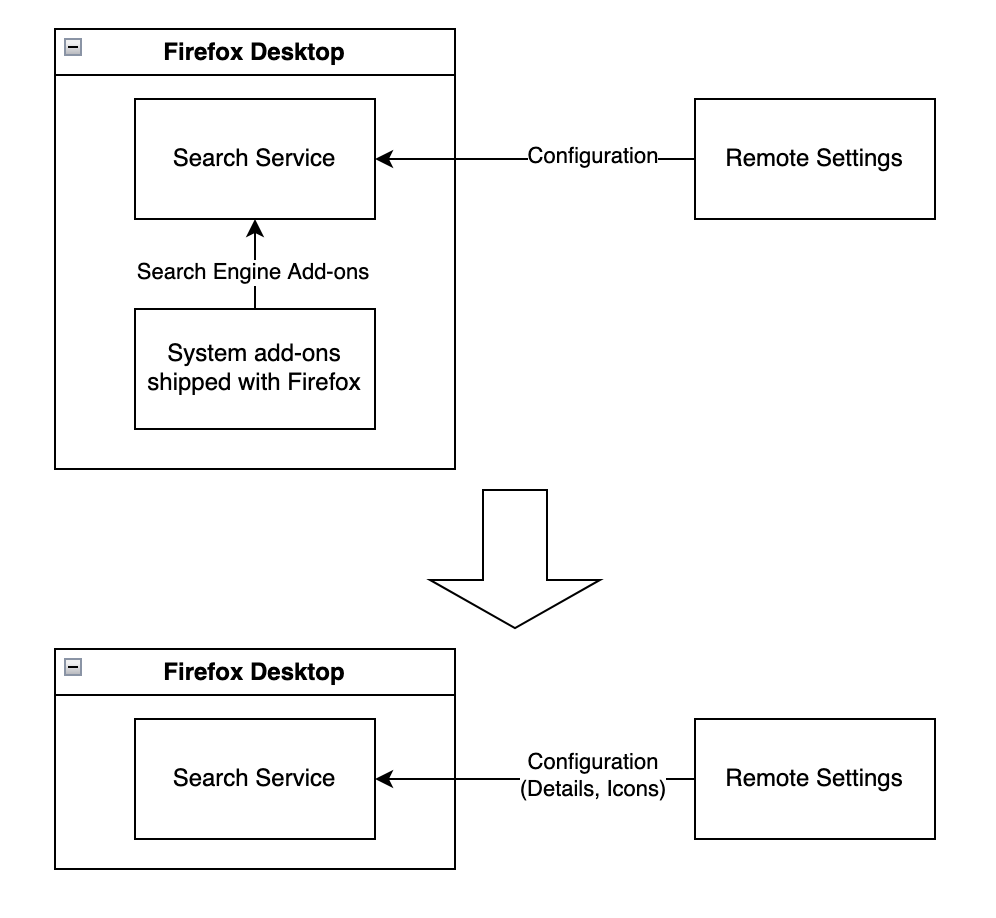

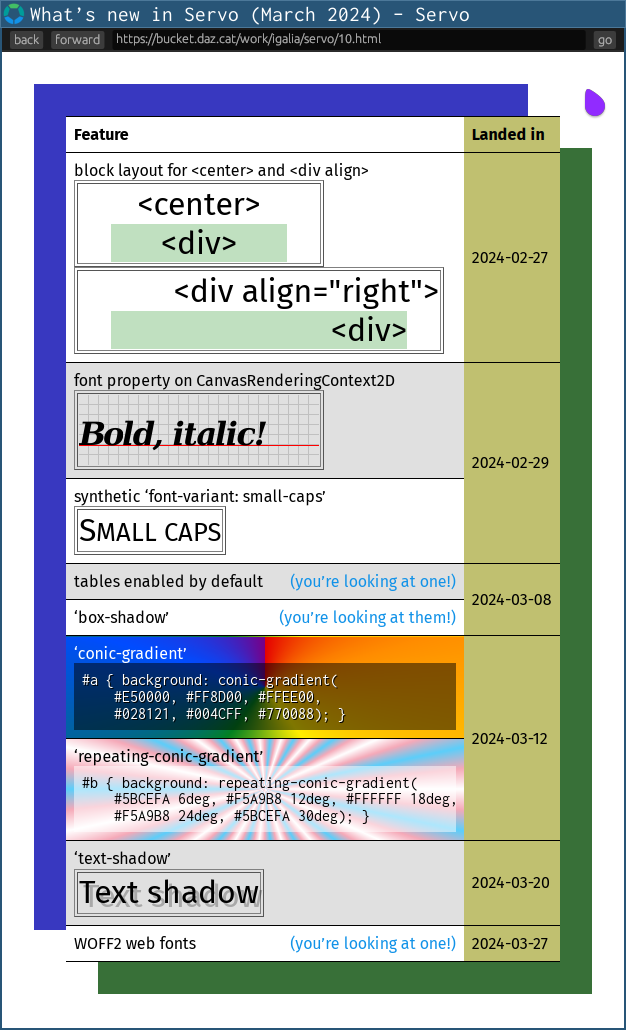
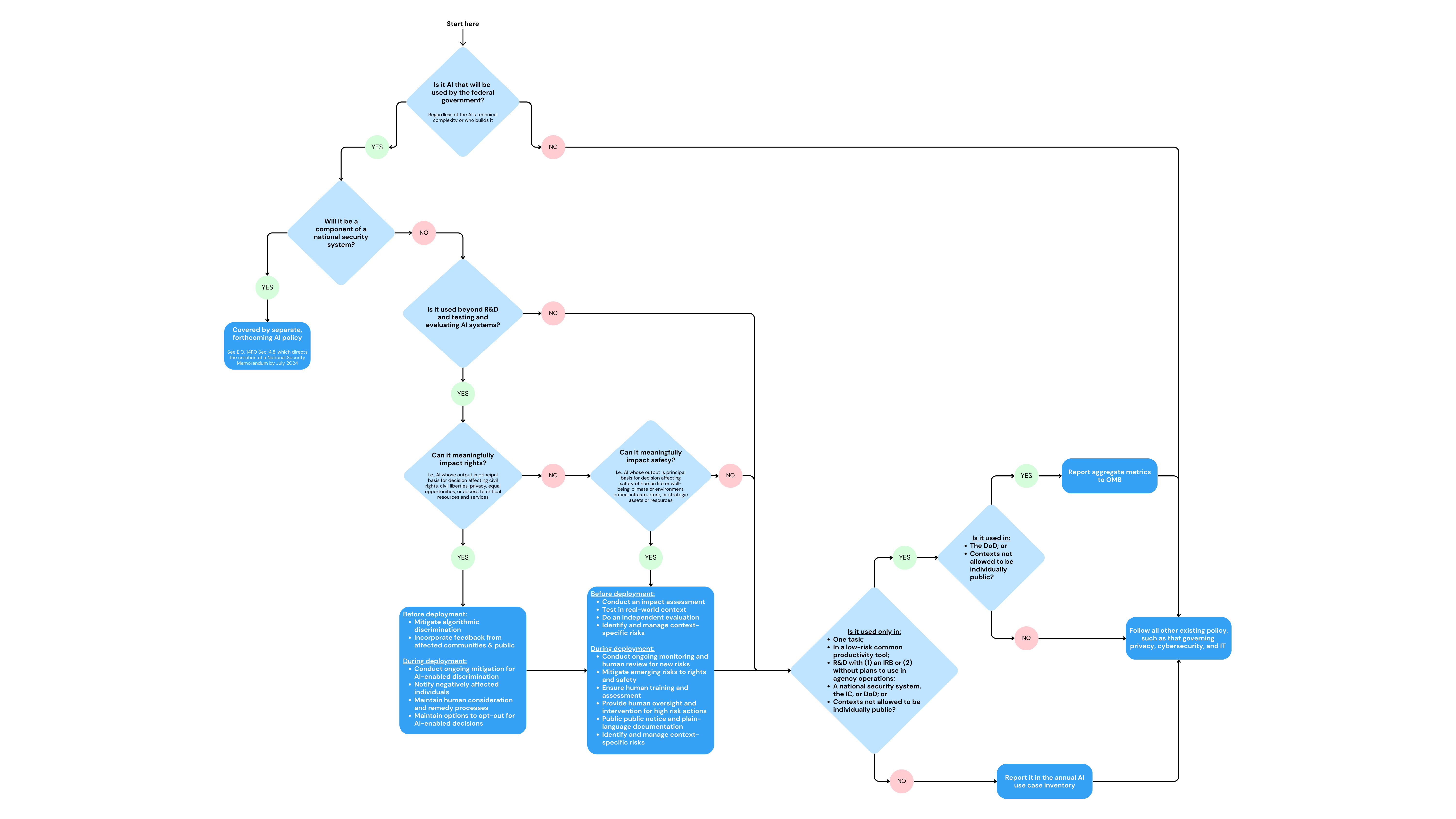


 <figcaption class="wp-element-caption">Performance test duration going from ~5s to ~1s</figcaption>
<figcaption class="wp-element-caption">Performance test duration going from ~5s to ~1s</figcaption> <figcaption class="wp-element-caption">Easy access to existing CSS variables</figcaption>
<figcaption class="wp-element-caption">Easy access to existing CSS variables</figcaption>
 <figcaption class="wp-element-caption">Firefox windows and tabs created in different containers using
<figcaption class="wp-element-caption">Firefox windows and tabs created in different containers using