Hello once more from the Thunderbird development team! For many of our team members, the summer has started with our annual sprint to release ESR and enjoy a little time afk, as our colleagues in the southern hemisphere hunker down for winter and power through a pile of work down under.
Extended Support Release is alive!
For enterprise users (and those who have been using Thunderbird for a long time and found themselves on the Extended Support Release channel), the annual release “ESR 140 Eclipse” has made it to our update servers and will be pushed out over the next few weeks.
We had initially planned to release within hours or days of the Firefox ESR release, but much of the ESR build process has changed in the last 12 months (largely due to the Firefox mozilla-central Git migration) – so we ended up learning a lot and took pause to release at a time that produced the best experience for the majority of our users.
In the hours following the initial release, we have another build hot on its heels which includes some important patches and will ship today or tomorrow. Things move fast around here!
If waiting a year doesn’t sound appealing to you, our Monthly release may be better suited. It offers access to the latest features, improvements, and fixes as soon as they’re ready. Watch out for an in-app invitation to upgrade or install over ESR to retain your profile settings.
Exchange support in Daily
The EWS 0.2 milestone has been completed and the feature was turned on by default in Daily release to facilitate more manual QA testing. In order to provide test coverage on a variety of EWS server versions and configurations, we’re tackling in a few ways:
Adding a small number of Hosted Exchange 2016 mailboxes to facilitate testing of all existing functionality at endpoints other than O365.
Contacting enterprise partners who can help us test on their infrastructure – please get in touch if this might be you!
Hosting our own EWS instance that allows us to configure a variety of security and authentication settings to ensure our code works for all
Focusing on automated test coverage throughout the month of July
Since my last update, the team has grown even more and made great progress on items in our “Phase 2 operations” and “Phase 2 polish” milestones, with these features delivered recently:
EWS-to-EWS move & copy for items and folders
Authentication Error handling
Server Version handling
Threading support
Folder updates & deletions during sync operations
Folder cache cleanup
Folder copy/move
Bug fixes!
We plan to temporarily expand the team during July to include two more of our most experienced senior engineers to push this project over the finish line and tackle some remaining complexities:
The new email account feature was enabled as the default experience for users adding their second email account. It is now available in all release channels. We’re currently finalizing the UX and associated functionality that detects whether account autodiscovery requires a password, and reacts accordingly – which will hopefully be uplifted once stable.
We’re wrapping up the redesigned Account Hub UI for Address Book account additions this week, which we’ll enable for users on Daily and beta in the coming weeks. Look out for it in our Monthly release 142.
Global Message Database
Since the last update, we’ve landed a landslide of patches. Critical refactoring continues to clean and optimize the code, in many cases clearing the way for new beneficial protocol implementations.
To follow their progress, take a look at the meta bug dependency tree. The team also maintains documentation in Sourcedocs which are visible here.
Recent Features and Fixes
A number of other features and fixes have reached our Daily users this month. We want to give special thanks to the contributors who made the following possible…
If you would like to see new features as they land, and help us squash some early bugs, you can try running daily and check the pushlog to see what has recently landed. This assistance is immensely helpful for catching problems early.
The wait is over! Thunderbird 140 “Eclipse” has reached totality. From all of us at the Thunderbird project, from MZLA staff and the Thunderbird Council to our global community of contributors, we’re excited to announce the latest Extended Support Release has arrived.
Eclipse not only builds on Thunderbird 128 “Nebula,” but also the recent features and improvements from the Monthly Release channel. This latest release transforms your email experience with adaptive dark messaging and improved visual controls. Enhanced features keep everyday email tasks light and effortless, while the streamlined new Account Hub ensures adding new accounts is a snap.
Dark Message Mode
Thunderbird’s Dark Mode now automatically adapts your messages when enabled, to ensure your Dark Mode experience stays totally dark. Need to bring your messages back into the light in case of visual problems? Adjust your message view as needed with a quick optional toggle.
Appearance Settings
Make Thunderbird yours across all your folders and accounts with a single click in the Settings (panel). Change your message list layout between Cards and Table view, adjust your Cards View, and set your default sorting order and threading options with ease.
Native OS Notifications
Leverage the speed and ease of your Operating System’s built-in notifications, whether you’re on Windows, Linux, or Mac. Quickly delete, archive, or use customizable actions directly from your notifications and get more done with your day.
Account Hub
Adding a new account to Thunderbird is now easier than ever. Connect all of your emails, address books and calendars in a few easy steps.
Manual Folder Sorting
Don’t like the order for your custom folders? Just click and drag to arrange them exactly how you want.
Don’t like the order for your custom folders? Just click and drag to arrange them exactly how you want.
More Refinements & Updates
Experimental Exchange Support Natively set up a Microsoft Exchange account in Thunderbird by enabling a preference.
Export for Mobile Generate a QR code to quickly transfer your account settings and credentials to your Thunderbird for Android app.
Horizontal Scroll for Table View Lots of tabular data? Let the message list scroll horizontally, like a spreadsheet or file manager.
Bug Fixes and Improvements
Thousands of bug fixes and performance improvements to bring you the smooth, reliable Thunderbird experience you expect.
Looking Forward
Whether you’re waiting for the next Thunderbird ESR or total solar eclipse, we understand that sometimes you want new features, or that cosmic awe, sooner. While we can’t change the universe, you can now get the latest Thunderbird features as they land, instead of once a year. Switch to Thunderbird Release and enjoy monthly updates with the same dependable stability.
Thunderbird 140 Availability For Windows, Linux, and MacOS
Even with QA and beta testing, any major software release may have issues exposed after significant public testing. That’s why we are slowly enabling automatic updates until we’re confident no such issues exist. We do have a known issue where users sending mail through 32bit MAPI will be prompted for a password, unless they use the compose window.
We have enabled manual upgrade to 140 via Help > About, and you can upgrade now or wait to receive automatic updates. Thunderbird version 140.0 is also offered as direct download from thunderbird.net. Be sure to select ‘Thunderbird Extended Support Release’ in the ‘Release Channel’ drop-down menu.
For Linux users running Thunderbird from the snap or flatpak, 140 will be available within the next few weeks. Likewise, Thunderbird 140 will also arrive on the Windows store by mid-July.
We’re growing a few more stars! We’re so happy to hear there is great interest in Thunderbird for iOS, and hope to reach a stage soon where you all can be more involved. Thank you, also, to those of you who’ve submitted an increasing number of ideas via Mozilla Connect.
Todd has been preparing the JMAP implementation for iOS, which will allow us to test the app with real data. We’re exploring the possibility of releasing the first community TestFlight a bit earlier by working directly with in-memory live data instead of syncing everything to a database upfront. The app may crash if your inbox has 30GB of email, but this approach should help us iterate more quickly. We still believe offline-first is the right path, and designing a database that supports this will follow soon after.
Further we’ve set up the initial localization infrastructure. This was surprisingly easy using Weblate’s translation propagation feature. We simply needed to add a new component to our Android localization project that pulls from the iOS repository. While Weblate doesn’t (yet?) auto-propagate when the component is set up, if there are changes across iOS and Android in the future, the strings will automatically apply to both products.
Thunderbird for Android
We spent a lot of time thinking about the beta and making adjustments. Fast forward to June, we’re still experiencing a number of crashes. If you are running the beta, please report crashes and try to find out how to trigger them. If you are not using Beta, please give it a try and report back on the beta list or issue tracker. We’d greatly appreciate it! Here are a few updates worth noting for the month of May:
Some folks on beta may have noticed the “recipient field contains incomplete input” error which kept you from sending emails. We’ve noticed as well, and halted the rollout of 11.0b1 on app stores where supported. Shamim fixed this issue for 11.0b2.
Another important issue was when attaching multiple issues, only one image would be attached. This happens all the way back to 10.0, and we’ll release a 10.1 that includes this fix. Again thank you to Shamim!
Final round of fixes from Shamim: new mail notifications can be disabled again, we have a bunch of new tests and refactoring, we have a few new UI types for the new preference system that Wolf created.
Timur Erofeev solved a crash on Android 7 due to some library changes in dependency updates we didn’t anticipate
Wolf is getting closer to finishing the drawer updates that we’re excited to share in a beta soon. He has also been working diligently to remove some of the crashes we’ve been experiencing on beta due to the new drawer and some of the legacy code it needs to fall back to. Finally, as we’re venturing into Thunderbird for iOS, Wolf has been thinking about the KMP (Kotlin Multiplatform) approach and added support to the Thunderbird for Android repository. He will soon separate a simple component and set things up so we can re-use it from Thunderbird for iOS.
Rafael and Marcos have fixed some issues with the system bar appearing transparent. The issue has been very persistent, we’re still getting reports of cases where this isn’t yet resolved.
Philipp has fixed an issue for our release automation to make sure the changelog doesn’t break on HTML entities.
I also wanted to highlight the new Git Commit Guide that Wolf created to give us a little more stability in our commits and set expectations for pull requests. We have a few more docs coming up in June, stay tuned.
You could be on this list next month, please get in touch if you’d like to help out!
— Philipp Kewisch (he/him) Thunderbird Mobile Engineering | Mozilla Thunderbird
It’s been just over two months (!) since we first announced our upcoming Thunderbird Pro suite and Thundermail email service. We thought it would be a great idea to bring in Chris Aquino, a Software Engineer on our Services team, to chat about these upcoming products. We want our community to get to know the newest members of the Thunderbird family even before they hatch!
We’ll be back later this summer after our upcoming Extended Support Release, Thunderbird 140.0, is out! Members of our desktop team will be here to talk about the newest features. Of course, if you’d like to try the newest features a little sooner, we encourage you to try the monthly Release channel. Just be sure to check if your Add-ons are compatible first!
May Office Hours: Thunderbird Pro and Thundermail
Chris has been a part of the Thunderbird Pro products since we first started developing them. So not only is he a great colleague, he’s an ideal guest to help tell the story about this upcoming chapter in the Thunderbird story. Chris starts with an overview for each product that covers the features we have planned for each of our Thunderbird Pro products and Thundermail. We know how curious our community is about these products, and so our hosts have lots of questions for each product, and Chris is more than up to the challenge in answering them. We also make sure to point out how to get involved with trying, testing, and helping us improve these products by linking you to our repositories.
Watch, Read, and Get Involved
The entire interview with Chris is below, on YouTube and Peertube. There’s a lot of references in the interview, which we’ve handily provided below. We hope you’re enjoying these looks into what we’re doing at Thunderbird as much as we’re enjoying making them, and we’ll see you soon!
We also know some of you might only be interested in a single product, and so we’ve also made separate videos for each product!
In this month’s Community Office Hours, we’re chatting with our director Ryan Sipes. This talk opens with a brief history of Thunderbird and ends on our plans for its future. In between, we explain more about MZLA and its structure, and how this compares to the Mozilla Foundation and Corporation. We’ll also cover the new Thunderbird Pro and Thundermail announcement And we talk about how Thunderbird put the fun in fundraising!
And if you’d like to know even more about Pro, next month we’ll be chatting with Services Software Engineer Chris Aquino about our upcoming products. Chris, who most recently has been working on Assist, is both incredibly knowledgeable and a great person to chat with. We think you’ll enjoythe upcoming Community Office Hours as much as we do.
April Office Hours: Thunderbird and MZLA
The beginning is always a very good place to start. We always love hearing Ryan recount Thunderbird’s history, and we hope you do as well. As one of the key figures in bringing Thunderbird back from the ashes, Ryan is ideal to discuss how Thunderbird landed at MZLA, its new home since 2020. We also appreciate his perspective on our relationship to (and how we differ from) the Mozilla Foundation and Corporation. And as Thunderbird’s community governance model is both one of its biggest strengths and a significant part of its comeback, Ryan has some valuable insights on our working relationship.
Thunderbird’s future, however, is just as exciting a story as how we got here. Ryan gives us a unique look into some of our recent moves, from the decision to develop mobile apps to the recent move into our own email service, Thundermail, and the Thunderbird Pro suite of productivity apps. From barely surviving, we’re glad to see all the ways in which Thunderbird and its community are thriving.
Watch, Read, and Get Involved
The entire interview with Ryan is below, on YouTube and Peertube. There’s a lot of references in the interview, which we’ve handily provided below. We hope you’re enjoying these looks into what we’re doing at Thunderbird as much as we’re enjoying making them, and we’ll see you next month!
Here is an update of what Thunderbird’s mobile community has been up to in April 2025. With a new team member, we’re getting Thunderbird for iOS out in the open and continuing to work on release feedback from Thunderbird for Android.
The Team is Growing
Last month we introduced Todd and Ashley to the MZLA mobile team, and now we have another new face in the team! Rafael Tonholo joins us as a Senior Android Engineer to focus on Thunderbird for Android. He also has much experience with Kotlin Multiplatform, which will be beneficial for Thunderbird for iOS as well.
Thunderbird for iOS
We’ve published the initial repository of Thunderbird for iOS! The application doesn’t really do a lot right this moment, since we intend to work very incrementally and start in the open. You’ll see a familiar welcome screen, slightly nicer than Thunderbird for Android and have the opportunity to make a financial contribution.
Testflight Distribution
We’re planning to distribute Thunderbird for iOS through TestFlight. To support that, we’ve set up an Apple Developer account and completed the required verification steps.
Unlike Android, where we maintain separate release and beta versions, the iOS App Store will have a single “Thunderbird” app. Apple prefers not to list beta versions as separate apps, and their review process tends to be stricter. Once the main app is published, we’ll be able to use TestFlight to offer a beta channel.
Before the App Store listing goes live, we’ll use TestFlight to distribute our builds. Apple provides an internal TestFlight option that doesn’t require a review, but it only works if testers have access to the developer account. That makes it unsuitable for community testing.
Initial Features for the Public Testflight Alpha
To share a public TestFlight link, we need to pass an initial App Store review. Apple expects apps to meet a minimum bar for functionality, so we can’t publish something like a simple welcome screen. Our goal for the first public TestFlight build is to support manual account setup and display emails in the inbox. Here are the specifics:
Initial account setup will be manual with hostname/username/password.
There will be a simple message list that will only show the INBOX folder messages, with a sender, subject, and maybe 2–3 preview lines.
You’ll have the opportunity to pull to refresh your inbox.
That is certainly not what you’d call a fully functional email client, but it could qualify for bare minimum functionality required for the Apple review. We have more details and a feature comparison in this document.
In other exciting news, we’re going to build Thunderbird for iOS with JMAP support first and foremost. While support on the email provider side is limited, we start with a modern email stack. This will allow us to build towards some of the features that email from the late 80’s was missing. We’ll be designing the code architecture in a way that adding IMAP support is very simple, so it will ideally follow soon after.
iOS Release Engineering and Localization
We’ve also gone through a few initial conversations on what the release workflow might look like. We’re currently deciding between:
GitHub Actions with Upload Actions (Pro: very open, re-use of some work on the Thunderbird for Android side. Con: Custom work, not many well-supported upload actions)
GitHub Actions with Fastlane (Pro: very open, well-supported, uses the same listing metadata structure we already have on Android. Con: Ruby as yet another language, no prior releng work)
Xcode Cloud (Pro: built in to Xcode, easy to configure, we’ll probably get by with the free tier for quite some time. Con: Not very open, increasing build cost)
Bitrise (Pro: Easy to configure, used by Firefox for iOS, we’ll get some support from Mozilla on this. Con: Can be pricy, not very open)
For now, our release process is pressing a button every once in a while. Xcode makes this very easy, which gives the release operations more time to plan a solution.
For localization, we’re aiming to use Weblate, just as Thunderbird for Android. The strings will mostly be the same, so we don’t need to ask our localizers to do double work.
Thunderbird for Android
We’re still focusing on release feedback by working on the drawer and looking to improve stability. April has very much been focused on onboarding the new team. I’ll keep the updates in this section a bit more brief, as we have less to explore and more to fix
We’ve accepted a new ADR to change the shared modules package from app.k9mail and com.fsck to net.thunderbird. We’ll be doing this gradually when migrating over legacy code.
Ashley has fixed a few keyboard accessibility issues to get started. She has also resolved a crash related to duplicate folder ids in the drawer. Her next projects are improving our sync debug tooling and other projects to resolve stability issues in retrieving emails.
Clément Rivière added initial support for showing hierarchical folders. The work is behind a feature flag for now, as we need to do some additional refactoring and crash fixes before we can release it. You can however try it out on the beta channel.
Fishkin removed a deprecated progress indicator, which provides slightly better support for Android watches.
Rafael fixed an issue related to Outlook/Microsoft accounts. If you have received the “Authentication Unsuccessful” message in the past, please try again on our beta channel.
Shamim continues on his path to refactor and move over some of our legacy code into the new modular structure. He also added support to attach files from the camera, and has resolved an issue in the drawer where the wrong folder was selected.
Timur Erofeev added support for algorithmic darkening where supported. This makes dark mode work better for a wider range of emails, following the same method that is used on web pages.
Wolf has been working diligently to improve our settings and drawer infrastructure. He took a number of much needed detours to refactor legacy code, which will make future work easier. Most notably, we have a new settings system based on Jetpack Compose, where we will eventually migrate all the settings screens to.
That’s a wrap for April! Let us know if you have comments, or see opportunities to help out. See you soon!
Hello from the Thunderbird development team! With some of our time spent onboarding new team members and interviewing for open positions, April was a fun and productive month. Our team grew and we were amazed at how smooth the onboarding process has been, with many contributions already boosting the team’s output.
Gearing up for our annual Extended Support Release
We have now officially entered the release cycle which will become our annual “ESR” at the end of June. The code we’re writing, the features we’re adding, the bugs we’re fixing at the moment should all make their way into the next major update, to be enjoyed by millions of users. This most stable release is used by enterprises, governments and institutions who have specific requirements around consistency, long-term support, and minimized change over time.
If waiting a whole year doesn’t sound appealing to you, our Monthly release may be better suited. It offers access to the latest features, improvements, and fixes as soon as they’re ready. Watch out for an in-app invitation to upgrade or install over ESR to retain your profile settings.
Calendar UI Rebuild
The implementation of the new event dialog hit some challenges in April with the dialog positioning and associated tests causing more than a few headaches when our CI started reporting test failures that were not easy to debug. Not surprising given the 60,000 tests which run for this one patch alone!!
The focus on loading data into the various containers continues, so that we can enable this feature and begin the QA process.
Our 0.2 release will make it into the hands of Daily and QA testers this month, with only a handful of smaller items left in our current milestone, before the “polish” milestone begins. The following items were completed in April:
Connectivity check for EWS accounts
Threading support
Folder updates & deletions in sync
Folder cache cleanup
Folder copy/move
Bug fixes!
Our hope is to include this feature set to users on beta and monthly release in 140 or 141.
The new email account feature was “preffed on” as the default experience for the Daily build but recent changes to our Oauth process have required some rework to this user experience. We’re currently working on designing a UX and associated functionality that can detect whether account autodiscovery requires a password, and react accordingly.
The redesigned UI for Address Book account additions is also underway and planned for release to users on 25th May.
Global Message Database
We welcomed a new team member in April so technical onboarding has been a priority. In addition, a long list of patches landed, with the team focused on refactoring core code responsible for the management of common folders such as Drafts or Sent Mail, and significant changes to nsIMsgPluggableStore.
Time was spent to research and plan a path to tackle dangling folders in May.
To follow their progress, the team maintains documentation in Sourcedocs which are visible here.
New Features Landing Soon
A number of requested features and important fixes have reached our Daily users this month. We want to give special thanks to the contributors who made the following possible…
If you would like to see new features as they land, and help us squash some early bugs, you can try running daily and check the pushlog to see what has recently landed. This assistance is immensely helpful for catching problems early.
In this month’s Community Office Hours, we’re chatting with Vineet Deo, a Software Engineer on the Desktop team, who walks us through the new Account Hub on the Desktop app. If you want a sneak peak at this new streamlined experience, you can find it in the Daily channel now and the Beta channel towards the end of April.
Next month, we’ll be chatting with our director Ryan Sipes. We’ll be covering the new Thunderbird Pro and Thundermail announcement and the structure of MZLA compared to the Mozilla Foundation and Corporation. And we’ll talk about how Thunderbird put the fun in fundraising!
March Office Hours: The New Account Hub
Setting up a new email account in Thunderbird is already a solid experience, so why the update? Firstly, this is the first thing new users will see in the app. Thus, it’s important it has the same clean, cohesive look that is becoming the new Thunderbird design standard. It’s also helpful for users coming from other email clients to have a familiar, wizard-like experience. While the current account setup works well, it’s browser based. This makes it possible a user could exit out before finishing and get lost before they even started. This is the opposite of what we want for potential users!
Vineet and his team are also working to make the new Account Hub ready for Exchange. Likewise, they also have plans for a similar hub to set up new address books and calendars. We’re proud of the collaboration between back and frontend teams, and designers and engineers, to make the Account Hub.
Watch, Read, and Get Involved
But don’t take our word for it! Watch Vineet’s Account Hub talk and demo, along with a Q&A session. If you’re comfortable testing Daily, you can test this new feature now. (Go to File > New > Email Account to start the experience.) Otherwise, keep an eye on our Beta release channel at the end of April. And if you’re watching this after Account Hub is part of the regular release, now you know the feature’s story!
Hello, everyone, and welcome to the Thunderbird for Android March 2025 Progress Report. We’re keeping our community updated on everything that’s been happening in the Android team, which is quickly becoming a more general mobile team with some recent hires. In addition to team news, we’re talking about our roadmap board on GitHub.
Team Changes
In March we said goodbye to cketti, the K-9 Mail maintainer who joined the team when Thunderbird first announced plans for an Android app. We’re very grateful for everything he’s created, and for his trust that K-9 Mail and Thunderbird for Android are in good hands. But we also said hello to Todd Heasley, our new iOS engineer, who started March 26. We also have just added Ashley Soucar, an Android/iOS engineer, who joined us on April 7. If all continues to go well, we’ll also be adding another Android engineer in the next couple of weeks.
Our Roadmap Board
Our roadmap board is now available! We’re grateful to the Council for their trust and support in approving it. As the board will reflect any changes in our planning, this is the most up-to-date source for our upcoming development. Each epic will show its objective and what’s in scope – and as importantly, what’s out of scope. The project information on the side will tell you if an epic is in the backlog or work in progress.
If you’d like to know what we’re working on right now, check out our sprint board.
Contribute by Triaging GitHub Issues
One way to contribute to Thunderbird for Android is by triaging open GitHub Issues. In March, we did a major triage with over 150 issues closed as duplicates, marked with ‘works for me,’ or elevating them up to the efforts and features described in the roadmap above. Especially since we’re a small team, triaging issues helps us know where to act on incoming issues. This is a great way to get started as a Thunderbird for Android contributor.
To start triaging bugs, have a look at the ‘unconfirmed’ issues. Try to reproduce the issue to help verify that the issue exists. Then add a comment with your results and any other information you found that might help narrow down the issue. If you see users generally saying “it doesn’t work”, ask them for more details or to enable logs. This way we know when to remove the unconfirmed label. If you have questions along the way or need someone to confirm a thought you had, feel free to ask in the community support channel.
Account Drawer
Our main engineering focus in March has been the account drawer we shared screenshots on in the January/February update. Given the settings design includes a few non-standard components, we took the opportunity to write a modern settings framework based on Jetpack Compose and make use of it for the new drawer. There will be some opportunities to contribute here in the future, as we’d like to migrate our old settings UI to the new system.
We have a few crashes and rough edges to polish, but are very close to enabling the feature flag in beta. If you aren’t already using it and want to get early access, install our beta today.
I’d also like to call out a pull request by Clément, who contributed support for a folder hierarchy. The amazing thing here—our design folks were working out a proposal because we were interested in this as well, and without knowing, Clément came up with the same idea and came in with a pull request that really hit the spot. Great work!
Community Contributions
In addition to the folder hierarchy mentioned above, here are a few community activities in March:
Shamim made sure the Unified Inbox shows up when you add your second account, retained scroll position in the drawer when rotating, removed font size customizations in favor of Android OS controls, flipped the default for being notified about new email and helped out with a few refactorings to make our codebase more modern.
Sergio has improved back button navigation when editing drafts.
Salkinnoma made our workflow runs more efficient and fixed an issue in the find folders view where a menu item was incorrectly shown.
Smatek improved our edge to edge support by making the bottom Android navigation bar background transparent
Husain fixed some inconsistencies when toggling “Show Unified Inbox”.
Vayun has begun work to update the Thunderbird for Android app widgets to Jetpack compose (including dark theming)
SttApollo has made the logo size more dynamic in the onboarding screen.
This is quite a list, great work! When you think about Thunderbird for Android or K-9 Mail, what was the last major annoyance you stumbled upon? If you are an Android developer, now is a good time to fix it. You’ll see your name up here next time as well
Hello again Thunderbird Community! It’s been almost a year since I joined the project and I’ve recently been enjoying the most rewarding and exciting work days in recent memory. The team who works on making Thunderbird better each day is so passionate about their work and truly dedicated to solving problems for users and supporting the broader developer community. If you are reading this and wondering how you might be able to get started and help out, please get in touch and we would love to get you off the ground!
Paddling Upstream
As many of you know, Thunderbird relies heavily on the Firefox platform and other lower-level code that we build upon. We benefit immensely from the constant flow of improvements, fixes, and modernizations, many of which happen behind the scenes without requiring our input.
The flip side is that changes upstream can sometimes catch us off guard – and from time to time we find ourselves firefighting after changes have been made. This past month has been especially busy as we’ve scrambled to adapt to unexpected shifts, with our team hunting down places to adjust Content Security Policy (CSP) handling and finding ways to integrate a new experimental whitespace normalizer. Very much not part of our plan, but critical nonetheless.
Calendar UI Rebuild
The implementation of the new event dialog is moving along steadily with the following pieces of the puzzle recently landing:
Title
Border
Location Row
Join Meeting button
Time & Recurrence
The focus has now turned to loading data into the various containers so that we can enable this feature later this month and ask our QA team and Daily users to help us catch early problems.
We’re aiming to get a 0.2 release into the hands of Daily and QA testers by the end of April so a number of remaining tasks are in the queue – but March saw a number of features completed and pushed to Daily
This feature was “preffed on” as the default experience for the Daily build but recent changes to our Oauth process have required some rework to this user experience, so it won’t hit beta until the end of the month. It’s beautiful and well worth considering a switch to Daily if you are currently running beta.
Global Message Database
The New Zealand team completed a successful work week and have since pushed through a significant chunk of the research and refactoring necessary to integrate the new database with existing interfaces.
The patches are pouring in and are enabling data adapters, sorting, testing and message display for the Local Folders Account, with an aim to get all existing tests to pass with the new database enabled. The path to this goal is often meandering and challenging but with our most knowledgeable and experienced team members dedicated to the project, we’re seeing inspiring progress.
The team maintains their documentation in Sourcedocs which are visible here.
In-App Notifications
A few last-minute changes were made and uplifted to our ESR version early this month so if you use the ESR and are in the lucky 2% of users targeted, watch out for an introductory notification! We’ve also wrapped up work on two significant enhancements which are now on Daily and will make their way to other releases over the course of the month:
Granular control of notifications by type via EnterprisePolicy
Enhanced triggering mechanism to prevent launch when Thunderbird is in the background
A number of requested features and important fixes have reached our Daily users this month. We want to give special thanks to the contributors who made the following possible…
As usual, if you want to see and use new features as they land, and help us squash some early bugs, you can try running daily and check the pushlog to see what has recently landed. This assistance is immensely helpful for catching problems early.
Today we’re pleased to announce what many in our open source contributor community already know. The Thunderbird team is working on an email service called “Thundermail” as well as file sharing, calendar scheduling and other helpful cloud-based services that as a bundle we have been calling “Thunderbird Pro.”
First, a point of clarification: Thunderbird, the email app, is and always will be free. We will never place features that can be delivered through the Thunderbird app behind a paywall. If something can be done directly on your device, it should be. However, there are things that can’t be done on your computer or phone that many people have come to expect from their email suites. This is what we are setting out to solve with our cloud-based services.
All of these new services are (or soon will be) open source software under true open source licenses. That’s how Thunderbird does things and we believe it is our super power. It is also a major reason we exist: to create open source communication and productivity software that respects our users. Because you can see how it works, you can know that it is doing the right thing.
The Why for offering these services is simple. Thunderbird loses users each day to rich ecosystems that are both products and services, such as Gmail and Office365. These ecosystems have both hard vendor lock-ins (through interoperability issues with 3rd-party clients) and soft lock-ins (through convenience and integration between their clients and services). It is our goal to eventually have a similar offering so that a 100% open source, freedom-respecting alternative ecosystem is available for those who want it. We don’t even care if you use our services with Thunderbird apps, go use them with any mail client. No lock-in, no restrictions – all open standards. That is freedom.
What Are The Services?
Thunderbird Appointment
Appointment is a scheduling tool that allows you to send a link to someone, allowing them to pick a time on your calendar to meet. The repository for Appointment has been public for a while and has seen pretty remarkable development so far. It is currently in a closed Beta and we are letting more users in each day.
Appointment has been developed to make meeting with others easier. We weren’t happy with the existing tools as they were either proprietary or too bloated, so we started building Appointment.
Thunderbird Send
Send is an end-to-end encrypted file sharing service that allows you to upload large files to the service and share links to download those files with others. Many Thunderbird users have expressed interest in the ability to share large files in a privacy-respecting way – and it was a problem we were eager to solve.
Thunderbird Send is the rebirth of Firefox Send – well, kind of. At this point, we have a bit of a Ship of Theseus situation – having rebuilt much of the project to allow for a more direct method of sharing files (from user-to-user without the need to share a link). We opened up the repo to the public earlier this week. So we encourage everyone interested to go and check it out.
Thunderbird Send is currently in Alpha testing, and will move to a closed Beta very soon.
Thunderbird Assist
Assist is an experiment, developed in partnership with Flower AI, a flexible open-source framework for scalable, privacy-preserving federated learning, that will enable users to take advantage of AI features. The hope is that processing can be done on devices that can support the models, and for devices that are not powerful enough to run the language models locally, we are making use of Flower Confidential Remote Compute in order to ensure private remote processing (very similar to Apple’s Private Cloud Compute).
Given some users’ sensitivity to this, these types of features will always be optional and something that users will have to opt into. As a reminder, Thunderbird will never train AI with your data. The repo for Assist is not public yet, but it will be soon.
Thundermail
Thundermail is an email service (with calendars and contacts as well). We want to provide email accounts to those who love Thunderbird, and we believe that we are capable of providing a better service than the other providers out there. Email that aligns with our values of privacy, freedom and respect of our users. No ads, no selling or training AI on your data – just your email and it is youremail.
With Thundermail, it is our goal to create a next generation email experience that is completely, 100% open source and built by all of us, our contributors and users. Unlike the other services, there will not be a single repository where this work is done. But we will try and share relevant places to contribute in future posts like this.
The email domain for Thundermail will be Thundermail.com or tb.pro. Additionally, you will be able to bring your own domain on day 1 of the service.
Heading to thundermail.com you will see a sign up page for the beta waitlist. Please join it!
Final Thoughts
Don’t services cost money to run?
You may be thinking: “this all sounds expensive, how will Thunderbird be able to pay for it?” And that’s a great question! Services such as Send are actually quite expensive (storage is costly). So here is the plan: at the beginning, there will be paid subscription plans at a few different tiers. Once we have a sufficiently strong base of paying users to sustainably support our services, we plan to introduce a limited free tier to the public. You see this with other providers: limitations are standard as free email and file sharing are prone to abuse.
It’s also important to highlight again that Thunderbird Pro will be a completely separate offering from the Thunderbird you already use. While Thunderbird and the additional new services may work together and complement each other for those who opt in, they will never replace, compromise, or interfere with the core features or free availability of Thunderbird. Nothing about your current Thunderbird experience will change unless you choose to opt in and sign up with Thunderbird Pro. None of these features will be automatically integrated into Thunderbird desktop or mobile or activated without your knowledge.
The Realization of a Dream
This has been a long time coming. It is my conviction that all of this should have been a part of the Thunderbird universe a decade ago. But it’s better late than never. Just like our Android client has expanded what Thunderbird is (as will our iOS client), so too will these services.
Thunderbird is unique in the world. Our focus on open source, open standards, privacy and respect for our users is something that should be expressed in multiple forms. The absence of Thunderbird web services means that our users must make compromises that are often uncomfortable ones. This is how we correct that.
I hope that all of you will check out this work and share your thoughts and test these things out. What’s exciting is that you can run Send or Appointment today, on your own server. Everything that we do will be out in the open and you can come and help us build it! Together we can create amazing experiences that enhance how we manage our email, calendars, contacts and beyond.
Thank you for being on this journey with us.
—
Ryan Sipes Managing Director of Product Thunderbird
In this month’s Community Office Hours, Laurel Terlesky, Design Manager, is talking about the new Thunderbird Design System. In her talk from FOSDEM, “Building a Cross-Platform, Scalable, Open-Source Design System,” Laurel describes the Thunderbird design journey. If you are interested in how the desktop and mobile apps have gotten their new look, or in the open source design process (and how to take part), this talk is for you!
Next month, we’ll be chatting with Vineet Deo, a Software Engineer on the Desktop team who will walk us through the new Account Hub on the Desktop app. If you want a sneak peak at this new streamlined experience, you can find it in the Daily channel now and the Beta channel starting March 25.
February Office Hours: The Thunderbird Design System
As Thunderbird has grown over the past few years, so has its design needs. The most recent 115 and 128 releases, Supernova and Nebula, have introduced a more modern, streamlined look to the Thunderbird desktop application. Likewise, the Thunderbird for Android app has incorporated Material 3 in its development from the K-9 Mail app. When we begin working on the iOS app, we’ll need to work with Apple’s Human Interface Guidelines. Thus, Laurel and her team have built a design system that provides consistency across our existing and future products. This system’s underlying principles also embrace user choice and privacy while emphasizing human collaboration and high design standards.
Watch, Read, and Get Involved
We’re so grateful to Laurel for joining us! We hope this video helps explain more about how we design our Thunderbird products. Want to know more about this new Thunderbird design system? Want to find out how to contribute to the design process? Watch the video and check out our resources below!
Hello again Thunderbird Community! Despite the winter seeming to last forever and the world being in a state of flux, the Thunderbird team has been hard at work both in development and planning strategic projects. Here’s the latest from the team dedicated to making Thunderbird better each day:
Monthly Releases are here!
The concept of a stable monthly release channel has been in discussion for many years and I’m happy to share that we recently changed the default download on Thunderbird.net to point at our most feature-rich and up-to-date stable version. A lot of work went into this release channel, but for good reason – it brings the very latest in performance and UX improvements to users with a frequent cadence of updates. Meaning that you don’t have to wait a year to benefit from features that have been tested and already spent time on our more experimental Daily and Beta release channels. Some examples of features that you’ll find on the monthly release channel (but not on ESR) are:
As privacy and security legislation evolves, the Thunderbird team often finds itself in the heart of discussions that have the potential to define industry solutions to emerging problems. In addition to the previously-mentioned research underway to develop post-quantum encryption support, we’re also currently considering solutions to EU laws (EU NIS2) that require multi-factor authentication be in place for critical digital infrastructure and services. We’re committed to solving these issues in a way that gives users and system administrators other options besides Google & Microsoft, and we’ll be sharing our thoughts on the matter soon, with the resulting decisions documented in our new ADR process.
For now, you can follow a healthy and colourful discussion on the topic of OAuth2 Dynamic Client Registration here.
Calendar UI Rebuild is underway
The long awaited UI/UX rebuild of the calendar has begun, with our first step being a new event dialog that we’re hoping to get into the hands of users on Daily via a preference switch. Turning the pref on will allow the existing calendar interface to launch the new dialog once complete. The following pieces of work have already landed:
A big focus for February has been to grow our team so we’ve been busy interviewing and evaluating the tremendously talented individuals who have stepped forward to show interest in joining the team. In the remaining time, the team has managed to deliver another set of features and is heading toward a release on Daily that will result in most email features being made available for testing. Here’s what landed and started in February:
Since my last update, tasks related to density and font awareness, the exchange add-on and keyboard navigation were completed, with the details of each step available to view in our Meta bug & progress tracking. Watch out for this feature being rolled out as the default experience for the Daily build this week and on beta after the next merge on March 25th!
Global Message Database
The New Zealand team are in the middle of a work week to shout at the code together, have a laugh and console each other plan out work for the next several weeks. Their focus has been a sprint to prototype the integration of the new database with existing interfaces with a positive outcome meaning we’re a little closer to producing a work breakdown that paints a more accurate picture of what lies ahead. Onward!
In-App Notifications
Phase 3 of the project is underway to finalize our uplift stack and add in last-minute features! It is expected that our ESR version will have this new feature enabled for a small percentage of users at some point in April. If you use the ESR release, watch out for an introductory notification!
As usual, if you want to see things as they land, and help us squash some early bugs, you can always check the pushlog and try running daily, which would be immensely helpful for catching things early.
If you’re interested in joining the technical discussion around Thunderbird development, consider joining one or several of our mailing list groups here.
Hello, everyone, and welcome to the first Android Progress Report of 2025. We’re ready to hit the ground running improving Thunderbird for Android experience for all of our users. Our January/February update involves a look at improvements to the account drawer and folders on our roadmap, an update on Google and K-9 Mail, and explores our first step towards Thunderbird on iOS.
Account Drawer Improvements
As we noted in our last post on the blog, improving the account drawer experience is one of our top priorities for development in 2025. We heard your feedback and want to make sure we provide an account drawer that lets you navigate between accounts easily and efficiently. Let’s briefly go into the most common feedback:
The accounts on the same domains or with similar names are difficult to distinguish from the two letters provided.
It isn’t clear how the account name influences the initials.
The icons seemed to be jumping around, especially obvious with 3–5 accounts.
There is a lot of spacing in the new drawer.
Users would like more customization options, such as an account picture or icon.
Some users would like to see a broader view that shows the whole account name.
With just one account, the accounts sidebar isn’t very useful.
Our design folks are working on some mockups on where the journey is taking us. We’re going to share them on the beta topicbox where you can provide more targeted feedback, but for a sneak peek here is a medium-fidelity mockup of what the new drawer and settings could look like:
On the technical side, we’ve integrated an image loader for the upcoming pictures. We now need to gradually adapt the mockups. We will begin with the settings screen changes and then adapt the drawer itself to follow.
Notifications and Error States
Some of you had the feeling your email was not arriving quick enough. While email delivery is reliable, there are a few settings in Thunderbird for Android and K-9 mail that aren’t obvious leading to confusion. When permissions are not granted, functionality is simply turned off instead of telling the user they actually need to grant the alarms permission for us to do a regular sync. Or maybe the sync interval is simply set to the default of 1 hour.
We’re still in the process of mapping out the best experience here, but will have more updates soon. See the notifications support article in case you are experiencing issues. A few things we’re aiming for this year:
Show an indicator in foreground service notification when push isn’t working for all configured folders
Show more detailed information when foreground service notification is tapped
Move most error messages from the system notifications to an area in-app to clearly identify when there is an error
Make authentication errors, certificate errors, and persistent connectivity issues use the new in-app mechanism
Make the folder synchronization settings more clear (ever wondered why there is “sync” and “push” and if you should have both enabled or not?)
Prompt for permissions when they are needed, such as aforementioned alarms permission
Indicate to the user if permissions are missing for their folder settings.
Better debug tool in case of notification issues.
Road(map) to the Highway
Our roadmap is currently under review from the Thunderbird council. Once we have their final approval, we’ll update the roadmap documentation. While we’re waiting, we would like to share some of the items we’ve proposed:
Listening to community feedback on Mozilla Connect and implementing HTML signatures and quick filter actions, similar to the Thunderbird Desktop
Backend refactoring work on the messages database to improve synchronization
Improving the message display so that you’ll see fewer prompts to download additional messages
Adding Android 15 compatibility, which is mainly Edge to Edge support
Improving the QR code import defaults (relates to notification settings as well)
Making better product decisions by (re-)introducing a limited amount of opt-in telemetry.
Does that sound exciting to you? Would you like to be a part of this but don’t feel you have the time? Are you good at writing Android apps in Kotlin and have an interest in muti-platform work? Well, do I have a treat for you! We’re hiring an Android Senior Software Engineer to work on Thunderbird for Android!
K-9 Mail Blocked from Gmail
We briefly touched on this in the last update as well: some of our users on K-9 Mail have noticed issues with an “App Blocked” error when trying to log into certain Gmail accounts. Google is asking K-9 Mail to go through a new verification process and has introduced some additional requirements that were not needed before. Users that are already logged in or have logged in recently should not be affected currently.
Meeting these requirements depended on several factors beyond our control, so we weren’t able to resolve this immediately.
If you are experiencing this issue on K-9 Mail, the quickest workaround is to migrate to Thunderbird for Android, or check out one of the other options on the support page. For those interested, more technical details can be found in issue 8598. We’re using keys on this application that have so far not been blocked. Our account import feature will make this transition pretty seamless.
We’ve been able to make some major progress on this, we have a vendor for the required CASA review and expect the letter of validation to be shared soon. We’re still hitting a wall with Google, as they are giving us inconsistent information on the state of the review, and making some requirements on the privacy policy that sound more like they are intended for web apps. We’ve made an effort to clarify this further and hope that Google will accept our revised policy.
If all goes well we’ll get approval by the end of the month, and then need to make some changes to the key distribution so that Thunderbird and K-9 use the intended keys.
Our Plans for Thunderbird on iOS
If you watched the Thunderbird Community Office Hours for January, you might have noticed us talking about iOS. You heard right – our plans for the Thunderbird iOS app are getting underway! We’ve been working on some basic architectural decisions and plan to publish a barebones repository on GitHub soon. You can expect a readme and some basic tools, but the real work will begin when we’ve hired a Senior Software Engineer who will lead development of a Thunderbird app for the iPhone and iPad. Interviews for some candidates have started and we wish them all the best!
With this upcoming hire, we plan to have alpha code available on Test Flight by the end of the year. To set expectations up front, functionality will be quite basic. A lof of work goes into writing an email application from scratch. We’re going to be focusing on a basic display of email messages, and then expanding to triage actions. Sending basic emails is also on our list.
FOSDEM
Our team recently attended FOSDEM in Brussels, Belgium. For those unfamiliar with FOSDEM, it’s the Free and Open Source Software Developers’ European Meeting—an event where many open-source enthusiasts come together to connect, share knowledge and ideas, and showcase the projects they’re passionate about.
We received a lot of valuable feedback from the community on Thunderbird for Android. Some key areas of feedback included the need for Exchange support, improvements to the folder drawer, performance enhancements, push notifications (and some confusion around their functionality), and much more.
Our team was highly engaged in listening to this feedback, and we will take all of it into account as we plan our future roadmap. Thunderbird has always been a project developed in tandem with our community and it was exciting for us to be at FOSDEM to connect with our users, contributors and friends.
In other news…
As always, you can join our Android-related mailing lists on TopicBox. And if you want to help us test new features, you can become a beta tester.
This blog post talks a lot about the exciting things we have planned for 2025. We’re also hiring for two positions, and may have a third one later in the year. While our software is free and open source, creating a world class email application isn’t without a cost. If you haven’t already made a contribution in January, please consider supporting our work with a financial contribution. Thunderbird for Android relies entirely on user funding, so without your support we could likely only get to a fraction of what you see here. Making a contribution is really easy if you have Thunderbird for Android or K-9 Mail installed, just head over to the settings and sign up directly from your device.
The monthly Release channel is ready to help you move from annual to monthly updates in Thunderbird. This update lets you know how to switch from the annual update (ESR) to monthly updates (Release), why you might have to wait, and what features you’ll get first!
How do I switch from annual to monthly updates (ESR to Release)?
Right now, you can switch to the Release channel through manual installs only from the Thunderbird website Downloads page. Other installation sources will have the Release version in the future such as Windows Store, 3rd-party sites and various Linux packages such as Snap and Flatpak.
However, if you use add-ons, we strongly suggest staying on the ESR for now.
First, back up your profile data, as you should always do before making major changes. And check that your computer meets the System Requirements for version 136. Then go to the Downloads page of the website. If Release Channel does not show “Thunderbird Release” then correct it. Click the ‘Download’ button. For Windows and macOS, run the downloaded file to install the monthly release into the same directory where the ESR is currently installed. (If you have installed Thunderbird ESR into a directory that is different from the default location, then you must do a custom installation to that directory.) For Linux, consult the Linux installation knowledge base (KB) article.
I switched to Release but I want to switch back to ESR. How do I do this?
If you switched to Release but want to switch back, for example, because of Add-ons, follow the steps below. Please note, this is valid for the current Release and ESR channels, and we will update here in the event of an underlying database change in ESR that would not make this possible:
Now that you know how to make the switch, here’s some reasons to make the change. Here are some of the key features you’ll get as soon as you upgrade to the Release channel:
Improved Dark Reader
Enable dark reader for the message pane with `mail.dark-reader.enabled` preference
Hello again Thunderbird Community! As January drew to a close, the team was closing in on the completion of some important milestones. Additionally, we had scoped work for our main Q1 priorities. Those efforts are now underway and it feels great to cross things off the list and start tackling new challenges.
A modest contingent from the Thunderbird team joined our Mozilla counterparts for an educational and inspiring weekend at Fosdem recently. We talked about standards, problems, solutions and everything in between. However, the most satisfying part of the weekend being standing at the Thunderbird booth and hearing the gratitude, suggestions and support from so many users.
With such important discussions among leading voices, we’re keen to help in finding or implementing solutions to some of the meatier topics such as:
OAuth 2.0 Dynamic Client Registration Protocol
Support for unicode email addresses
Support for OpenPGP certification authorities and trust delegation
Exchange Web Services support in Rust
With a reduction in team capacity for part of January, the team was able to complete work on the following tasks that form some of the final stages in our 0.2 release:
We completed the second and final milestone in the First Time User Experience for email configuration via the enhanced Account Hub over the course of January. Tasks included density and font awareness, refactoring of state management, OAuth prompts, enhanced error handling and more which can be followed via Meta bug & progress tracking. Watch out for this feature being unveiled in daily and beta in the coming weeks!
Global Message Database
With a significant number of the research and prototyping tasks now behind us, the project has taken shape over the course of January with milestones and tasks mapped out. Recent progress has been related to live view, sorting and support for Unicode server and folder names.
Next up is to finally crack the problem of “non-unique unique IDs” mentioned previously, which is important preparatory groundwork required for a clean database migration.
In-App Notifications
Phase 2 is now complete, and almost ready for uplift to ESR, pending underlying Firefox dependencies scheduled in early March. Features and user stories in the latest milestone include a cache-control mechanism, a thorough accessibility review, schema changes and the addition of guard rails to limit notification frequency. Meta Bug & progress tracking.
New Features Landing Soon
Several requested features and fixes have reached our Daily users and include…
More folder compaction fixes and performance improvements!
To see things as they land, and help squash early bugs, you can check the pushlog and try running daily. This would be immensely helpful for catching things early.
UPDATE (March 4, 2025): The Release Channel is now default! See our update post on how to make the switch with a manual install and what’s new in 136.
We have an exciting announcement! Starting with the 136.0 release in March 2025, the Thunderbird Desktop Release channel will be the default download.
If you’re not already familiar with the Release channel, it will be a supported alternative to the ESR channel. It will provide monthly major releases instead of annual major releases. This provides several benefits to our users:
Frequent Feature Updates: New features will potentially be available each month, versus the annual Extended Support Release (ESR).
Smoother Transitions: Moving from one monthly release to the next will be less disruptive than updating between ESR versions.
Consistent Bug Fixes: Users will receive all available bug fixes, rather than relying on patch uplifts, as is the case with ESR.
We’ve been publishing monthly releases since 124.0. We added the Thunderbird Desktop Release Channel to the download page on Oct 1st, 2024.
The next step is to make the release channel an officially supported channel and the default download. We don’t expect this step alone to increase the population significantly. We’re exploring additional methods to encourage adoption in the future, such as in-app notifications to invite ESR users to switch.
One of our goals for 2025 is to increase daily active installations on the release channel to at least 20% of the total installations. At last check, we had 29,543 daily active installations on the release channel, compared to 20,918 on beta, and 5,941 on daily. The release channel installations currently account for 0.27% of the 10,784,551 total active installations tracked on stats.thunderbird.net.
To support this transition and ensure stability for monthly releases, we’re implementing several process improvements, including:
Pre-merge freezes: A 4-day soft code freeze of comm-central before merging into comm-beta. We continue to bake the week-long post-merge freeze of the release channel into the schedule.
Pre-merge reviews: We evaluate changes prior to both merges (central to beta and beta to release) where risky changes can be reverted.
New uplift template: A new and more thorough uplift template.
For more details on these release process details, please see the Release section of the developer docs.
The Thunderbird Mobile team are crafting the newest chapter of the Thunderbird story. In this month’s office hours, we sat down to chat with the entire mobile team! This includes Philipp Kewisch, Sr. Manager of Mobile Engineering (and long-time Thunderbird contributor), and Sr. Software Engineers cketti and Wolf Montwé (long-time K-9 Mail maintainer and developer, respectively). We talk about the journey from K-9 Mail to Thunderbird for Android, what’s new and what’s coming in the near future, and the first steps towards Thunderbird on your iOS devices!
Next month, we’ll be chatting with Laurel Terlesky, Manager of the UI/UX Design Studio! She’ll be sharing her FOSDEM talk, “Thunderbird: Building a Cross-Platform, Scalable Open-Source Design System.” It’s been a while since we’ve chatted with the design team, and it will be great to see what they’re working on.
January Office Hours: The Thunderbird Mobile Team
In June 2022, we announced that K-9 Mail would be joining the Thunderbird family, and would ultimately become Thunderbird for Android. After two years of development, the first beta release of Thunderbird for Android debuted in October 2024, shortly followed by the first stable release. Since then, over 200 thousand users have downloaded the app, and we’ve gotten some very nice reviews in ZDNet and Android Authority. If you haven’t tried us on your Android device yet, now is a great time! And if, like some of us, you’re waiting for Thunderbird to come to your iPhone or iPad, we have some exciting news at the end of our talk.
Want to know more about the Android development process and find out what’s coming soon to the app? Want the first look into our plans for Thunderbird on iOS? Let our mobile team guests provide the answers!
Watch, Read, and Get Involved
We’re so grateful to Philipp, cketti, and Wolf for joining us! We hope this video helps explain more about Thunderbird on Android (and eventually iOS), and encourages you to download the app if you haven’t already. If you’re a regular user, we hope you consider contributing code, translations, or support. And if you’re an iOS developer, we hope you consider joining our team!
Happy New Year Thunderbirders! With a productive December and a good rest now behind us, the team is ready for an amazing year. Since the last update, we’ve had some successes that have felt great. We also completed a retrospective on a major pain point from last year. This has been humbling and has provided an important opportunity for learning and improvement.
Exchange Web Services support in Rust
Prior to the team taking their winter break, a cascade of deliverables passed the patch review process and landed in Daily. A healthy cadence of task completion saw a number of features reach users and lift the team’s spirits:
The overhauled Account Hub passed phase 1 QA review! A smaller team is handling phase 2 enhancements now that the initial milestone is complete. Our current milestone includes tasks for density and font awareness, refactoring of state management, OAuth prompts and more, which you can follow via Meta bug & progress tracking.
Global Database & Conversation View
Progress on the global database project was significant in the tail end of 2024, with foundational components taking shape. The team has implemented a database for folder management, including support for adding, removing, and reordering folders, and code for syncing the database with folders on disk. Preliminary work on a messages table and live view system is underway, enabling efficient filtering and handling of messages in real time. We have developed a mock UI to test these features, along with early documentation. Next steps include transitioning legacy folder and message functionality to a new “magic box” system, designed to simplify future refactoring and ensure a smooth migration without a disruptive “Big Bang” release.
Encryption
The future of email encryption has been on our minds lately. We have planned and started work on bridging the gap between some of the factions and solutions which are in place to provide quantum-resistant solutions in a post-quantum world. To provide ourselves with the breathing room to strategize and bring stakeholders together, we’re looking to hire a hardening team member who is familiar with encryption and comfortable with lower level languages like C. Stay tuned if this might be you!
In-App Notifications
With phase 1 of this project complete, we uplifted the feature to 134.0 Beta and notifications were shared with a significant number of users on both beta and daily releases in December. Data collected via Glean telemetry uncovered a couple of minor issues that have been addressed. It also provided peace of mind that the targeting system works as expected. Phase 2 of the project is well underway, and we have already uplifted some features and now merged them with 135.0 Beta. Meta Bug & progress tracking.
Folder & Message Corruption
In the aftermath of our focused team effort to correct corruption issues introduced during our 2023 refactoring and solve other long-standing problems, we spent some time in self-reflection to perform a post mortem on the processes, decisions and situations which led to data loss and frustrations for users. While we regret a good number of preventable mistakes, it is also helpful to understand things outside of our control which played a part in this user-facing problem. You can find the findings and action plan here. We welcome any productive recommendations to improve future development in the more complex and arcane parts of the code.
New Features Landing Soon
Several requested features and fixes have reached our Daily users and include…
More folder compaction fixes and performance improvements!
As usual, if you want to see things as they land, and help us squash some early bugs, you can always check the pushlog and try running daily, which would be immensely helpful for catching things early.
Thunderbird’s rich history comes with a complex community of contributors. We care deeply about them and want to support them in the best way possible. But how does a project effectively do just that? This article will cover a project and partnership we’ve had for most of a year with a company called Bitergia. It helps inform the Thunderbird team on the health of our community by gathering and organizing publicly available contribution data.
In order to better understand what our contributors need to be supported and successful, we sought the ability to gather and analyze data that would help us characterize the contributions across several aspects of Thunderbird. And we needed some data experts that understood open source communities to help us achieve this endeavor. From our relationship with Mozilla projects, we recalled a past partnership between Mozilla and Bitergia, who helped it achieve a similar goal. Given Bitergia’s fantastic previous work, we explored how Thunderbird could leverage their expertise to answer questions about our community. Likewise, you can read Bitergia’s complimentary blog post on our partnership as well.
Thunderbird and Bitergia Join Forces
Thunderbird and Bitergia started comparing our data sources with their capabilities. We found a promising path forward on gathering data and presenting it in a consumable manner. The Bitergia platform could already gather information from some data sources that we needed, and we identified functionality that had to be added for some other sources.
We now have contribution data sets gathered and organized to represent these key areas where the community is active:
Thunderbird Codebase Contributions – Most code changes take place in the Mercurial codebase with Phabricator as the code reviewing tool. This Mercurial codebase is mirrored in GitHub which is more friendly and accessible to contributors. There are other important Thunderbird repositories in GitHub such as Thunderbird for Android, the developer documentation, the Thunderbird website, etc.
Bug Activity – Bugzilla is our issue tracker and an important piece of the contribution story.
Translations – Mozilla Pontoon is where users can submit translations for various languages.
Email List Discussions – Topicbox is where mailing lists exist for various areas of Thunderbird. Users and developers alike can watch for upcoming changes and participate in ongoing conversations.
Diving into the Dashboards
Once we identified the various data sets that made sense to visualize, Bitergia put together some dashboards for us. One of the key features that we liked about Bitergia’s solution is the interactive dashboard. Anyone can see the public dashboards, without even needing an account!
All of the data gathered for our dashboards was already publicly available. Now it’s well organized for understanding too! Let’s take a deeper look at what this data represents and see what insights it gives us on our community’s health.
Thunderbird Codebase Contributions
As stated earlier, the code contributions happen on our Mercurial repository, via the Phabricator reviewing tool. However, the Bitergia dashboard gathers all its data from GitHub, the Mercurial mirror pluss our other GitHub repositories. You can see a complete list of GitHub repositories that are considered at the bottom of the Git tab.
One of the most interesting things about the codebase contributions, across all of our GitHub repositories, is the breakdown of which organizations contribute. Naturally, most of the commits will come from people who are associated with Thunderbird or Mozilla. There are also many contributors who are not associated with any particular organization (the Unknown category).
One thing we hope to see, and will be watching for, is for the number of contributors outside of the Thunderbird and Mozilla organizations to increase over time. Once the Firefox and Thunderbird codebases migrate from Mercurial to git, this will likely attract new contributors and it will be interesting to see how those new contributions are spread across various organizations.
Another insightful dashboard is the graph that displays our incoming newcomers (seen from the Attracted Committers subtab). We can see that over the last year we’ve seen a steady increase in the number of people that have committed to our GitHub repositories for the first time. This is great news and a trend we hope to continue to observe!
Bug Activity
All codebases have bugs. Monitoring discovered and reported issues can help us determine not only the stability of the project itself, but also uncover who is contributing their time to report the issues they’ve seen. Perhaps we can even run some developer-requested test cases that help us further solve the user’s issue. Bug reporting is incredibly important and valuable, so it is obviously an area we were interested in. You can view these relevant dashboards on the Bugzilla tab.
Translations
Many newcomers’ first contribution to an open source project is through translations.. For the Firefox and Thunderbird projects, Pontoon is the translation management system, and you can find the Translation contribution information on the Pontoon tab.
Naturally, any area of the project will see some oscillating contribution pattern for several reasons and translations are no different. If we look at the last 5 years of translation contribution data, there are several insights we can take away. It appears that the number of contributors drop off after an ESR release, and increase in a few chunks in the months prior to the release of the next ESR. In other words, we know that historically translations tend to happen toward the end of the ESR development cycle. Given this trend, If we compare the 115 ESR cycle (that started in earnest around January 2023) to the recent 128 ESR cycle (that started around December 2023), then we see far more new contributors, indicating a healthier contributor community in 128 than 115.
User Support Forums
Thus far we have talked about various code contributions that usually come from developers, but users supporting users is also incredibly important. We aim to foster a community that happily helps one another when they can, so let’s take a look at what the activity on our user support forums looks like in the Support Forums tab.
For more context, the data range for these screenshots of the user support forum dashboards has been set to the last 2 years instead of just the last year.
The good news is that we are getting faster at providing the first response to new questions. The first response is often the most important because it helps set the tone of the conversation.
The bad news is that we are getting slower at actually solving the new questions, i.e. marking the question as “Solved”. In the below graph, we see that over the last two years, our average time to mark an issue as “Solved” is affecting a smaller percentage of our total number of questions.
The general take away is that we need help in answering user support questions. If you are a knowledgeable Thunderbird user, please consider helping out your fellow users when you can.
Email List Discussions
Many open source projects use public mailing lists that anyone can participate in, and Thunderbird is no different. We use Topicbox as our mailing list platform to manage several topic-specific lists. The Thunderbird Topicbox is where you can find information on planned changes to the UI and codebase, beta testing, announcements and more. To view the Topicbox contributor data dashboard, head over to the Topicbox tab.
With our dashboards, we can see the experience level of discussion participants. As you might expect, there are more seasoned participants in conversations. Thankfully, less experienced people feel comfortable enough to chime in as well. We want to foster these newer contributors to keep providing their valuable input in these discussions!
Takeaways
Having collated public contributor data has helped Thunderbird identify areas where we’re succeeding. It’s also indicated areas that need improvement to best support our contributor community. Through this educational partnership with Bitergia, we will be seeking to lower the barriers of contribution and enhance the overall contribution experience.
If you are an active or potential contributor and have thoughts on specific ways we can best support you, please let us know in the comments. We value your input!
If you are a leader in an open source project and wish to gather similar data on your community, please contact Bitergia for an excellent partnership experience. Tell them that Thunderbird sent you!
It’s been a while since our last update in August, and we’re glad to be back to share what’s been happening. Over the past few months, we’ve been fully focused on the Thunderbird for Android release, and now it’s time to catch you up. In this update, we’ll talk about how the launch went, the improvements we’ve made since then, and what’s next for the project.
A Milestone Achieved
Launching Thunderbird for Android has been an important step in extending the Thunderbird ecosystem to mobile users. The release went smoothly, with no hiccups during the Play Store review process, allowing us to deliver the app to you right on schedule.
Since its launch a month ago, the response has been incredible. Hundreds of thousands of users have downloaded Thunderbird for Android, offering encouragement and thoughtful feedback. We’ve also seen an influx of contributors stepping up to make their mark on the project, with around twenty people making their first contribution to the Thunderbird for Android and K-9 Mail repository since 8.0b1. Their efforts, along with your support, continue to inspire us every day.
Listening to Feedback
When we launched, we knew there were areas for improvement. As we’ve been applying our updates to both K-9 Mail and Thunderbird for Android, it won’t magically have all the bugs fixed with a new release over night. We’ve been grateful for the feedback in the beta testing group and the reviews, but also especially excited about those of you who spent a moment to appreciate by leaving a positive review. Your feedback has helped us focus on key issues like account selection, notifications, and app stability.
For account selection, the initial design used two-letter abbreviations from domain names, which worked for many users but caused confusion for users managing many similar accounts. A community contributor updated this to use letters from account names instead. We’re now working on adding custom icons for more personalization while keeping simple options available. Additionally, we resolved the confusing dynamic reordering of accounts, keeping them fixed while clearly indicating the active one.
Notifications have been another priority. Gmail users on K-9 faced issues due to new requirements from Google, which we’re working on. As a stop gap we’ve added a support article which will also be in the login flow from 8.2 onwards. Others have had trouble setting up push notifications or emails not arriving immediately, which you can read more about as well. Missed system error alerts have also been a problem, so we’re planning to bring notifications into the app itself in 2025, providing a clearer way to address actions.
There are many smaller issues we’ve been looking at, also with the help of our community, and we look forward to making them available to you.
Addressing Stability
App stability is foundational to any good experience, and we regularly look at the data Google provides to us. When Thunderbird for Android launched, the perceived crash rate was alarmingly high at 4.5%. We found that many crashes occurred during the first-time user experience. With the release of version 8.1, we implemented fixes that dramatically reduced the crash rate around 0.4%. The upcoming 8.2 update will bring that number down further.
The Year Ahead
The mobile team at MZLA is heading into well deserved holidays a bit early this year, but next year we’ll be back with a few projects to keep you productive while reading email on the go. Our mission is for you to fiddle less with your phone. If we can reduce the time you need between reading emails and give you ways to focus on specific aspects of your email, we can help you stay organized and make the most of your time. We’ll be sharing more details on this next year.
While we’re excited about these plans, the success of Thunderbird for Android wouldn’t be possible without you. Whether you’re using the app, contributing code, or sharing your feedback, your involvement is the lifeblood of this project.
If K-9 Mail or Thunderbird for Android has been valuable to you, please consider supporting our work with a financial contribution. Thunderbird for Android relies entirely on user funding, and your support is essential to ensure the sustainability of open-source development. Together, we can continue improving the app and building a better experience for everyone.
Thunderbird turns 20 today. Such a huge milestone invites reflection on the past and excitement for the future. For two decades, Thunderbird has been more than just an email application – it has been a steadfast companion to millions of users, offering communication, productivity, and privacy.
20 Years Ago Today…
Thunderbird’s journey began in 2003, but version 1.0 was officially released on December 7, 2004. It started as an offshoot of the Mozilla project and was built to challenge the status quo – providing an open-source, secure and customizable alternative to proprietary email clients. What began as a small, humble project soon became the go-to email solution for individuals and organizations who valued control over their data. Thunderbird was seen as the app for those in the ‘know’ and carved a unique space in the digital world.
Two Decades of Ups and Downs and Ups
The path hasn’t always been smooth. Over the years, Thunderbird faced its share of challenges – from the shifting tides of technology and billion dollar competitors coming on the scene to troubles funding the project. In 2012, Mozilla announced that support for Thunderbird would end, leaving the project largely to fend for itself. Incredibly, a passionate group of developers, users, and supporters stepped up and refused to let it fade away. Twenty million people continued to rely on Thunderbird, believing in its potential, rallying behind it, and transforming it into a project fueled by its users, for its users.
In 2017, the Mozilla Foundation, which oversaw Thunderbird along with a group of volunteers in the Thunderbird Council, once again hired a small 3 person team to work on the project, breathing new life into its development. This team decided to take matters into their own hands and let the users know through donation appeals that Thunderbird needed their support. The project began to regain strength and momentum and Thunderbird once again came back to life. (More on this story can be found in our previous post, “The History of Thunderbird.”)
The past few years, in particular, have been pivotal. Thunderbird’s user interface got a brand new facelift with the release of Supernova 115 in 2023. The 2024 Nebula release fixed a lot of the back-end code and technical debt that was plaguing faster innovation and development. The first-ever Android app launched, extending Thunderbird to mobile users and opening a new chapter in its story. The introduction of Thunderbird Pro Services, including tools like file sharing and appointment booking, signals how the project is expanding to become a comprehensive productivity suite. And with that, Thunderbird is gearing up for the next era of growth and relevance.
Thank You for 20 Amazing Years
As we celebrate this milestone, we want to thank you. Whether you’ve been with Thunderbird since its earliest days or just discovered it recently, you’re part of a global movement that values privacy, independence, and open-source innovation. Thunderbird exists because of your support, and with your continued help, it will thrive for another 20 years and beyond.
Here’s to Thunderbird: past, present, and future. Thank you for being part of the journey. Together, let’s build what’s next.
Happy 20th, Thunderbird!
20 Years of Thunderbird Trivia!
It Almost Had a Different Name
Before Thunderbird was finalized, the project was briefly referred to as “Minotaur.” However, that name didn’t stick, and the team opted for something more dynamic and fitting for its vision.
Beloved By Power Users
Thunderbird has been a favorite among tech enthusiasts, system administrators, and privacy advocates because of its extensibility. With add-ons and customizations, users can tweak Thunderbird to do pretty much anything.
Supports Over 50 Languages
Thunderbird is loved world-wide! The software is available in more than 50 languages, making it accessible to users all across the globe.
Launched same year as Gmail
Thunderbird and Gmail both launched in 2004. While Gmail revolutionized web-based email, Thunderbird was empowering users to manage their email locally with full control and customization.
Donation-Driven Independence
Thunderbird relies entirely on user donations to fund its development. Remarkably, less than 3% of users donate, but their generosity is what keeps the project alive and independent for the other 97% of users.
Robot Dog Regeneration
The newly launched Thunderbird for Android is actually the evolution of the K-9 Mail project, which was acquired by Thunderbird in 2022. It was smarter to work with an existing client who shared the same values of open source, respecting the user, and offering customization and rich feature options.
Hello Thunderbird Community! Another adventurous month is behind us, and the team has emerged victorious from a number of battles with code, quirks, bugs and performance issues. Here’s a quick summary of what’s been happening across the front and back end teams as some of the team heads into US Thanksgiving:
Exchange Web Services support in Rust
November saw an increase in the number of team members contributing to the project and to the number of features shipped! Users on our Daily release channel can help to test newly-released features such as copy and move messages from EWS to another protocol, marking a message as read/unread, and local storage functionality. Keep track of feature delivery here.
If you aren’t already using Daily or Beta, please consider downloading to get early access to new features and fixes, and to help us uncover issues early.
Account Hub
Development of a refreshed account hub has reached the end of an important initial stage, so is entering QA review next week while we spin up tasks for phase 2 – taking place in the last few weeks of the year. Meta bug & progress tracking.
Global Database & Conversation View
Work to implement a long term database replacement is moving ahead despite some team members being held up in firefighting mode on regressions from patches which landed almost a year ago. Preliminary patches on this large-scale project are regularly pumped into the development ecosystem for discussion and review, with the team aiming to be back to full capacity before the December break.
In-App Notifications
With phase 1 of this project now complete, we’ve uplifted the feature to 134.0 Beta and notification tests will be activated this week. Phase 2 of the project is well underway, with some features accelerated and uplifted to form part of our phase 1 testing plan. Meta Bug & progress tracking.
Folder & Message Corruption
Some of the code we manage is now 20 years old and efforts are constantly under way to modernize, standardize and make things easier to maintain in the future. While this process is very rewarding, it often comes with unforeseen consequences which only come to light when changes are exposed to the vast number of users on our “ESR” channel who have edge cases and ways of using Thunderbird that are hard to recreate in our limited test environments.
The past few months have been difficult for our development team as they have responded to a wide range of issues related to message corruption. After a focused team effort, and help from a handful of dedicated users and saintly contributors, we feel that we have not only corrected any issues that were introduced during our recent refactoring, but also uncovered and solved problems that have been plaguing our users for years. And long may that continue! We’re here to improve things!
New Features Landing Soon
Several requested features have reached our Daily users and include…
Folder compaction fixes and performance improvements
If you want to see things as they land, and help squash early bugs, you can check the pushlog and try running daily. This would be immensely helpful for catching things early.
For the past two decades, I’ve been trying to get on Jeopardy. This is harder than answering a Final Jeopardy question in your toughest subject. Roughly a tenth of people who take the exam get invited to auditions, and only a tenth of those who make it to auditions make it to the Contestant Pool and into the show. During this time, there are two emails you DON’T want to miss: the first saying you made it to auditions, and the second that you’re in the Contestant Pool. (This second email comes with your contestant form, and yes, I have my short, fun anecdotes to share with host Ken Jennings ready to go.)
The next time I audition, reader, I am eliminating refreshing my inbox every five minutes. Instead, I’ll use Thunderbird Filters to make any emails from the Jeopardy Contestant department STAND OUT.
Whether you’re hoping to be called up for a game show, waiting on important life news, or otherwise needing to be alert, Thunderbird is here to help you out.
Make Important Messages Stand Out with Filters
Most of our previous posts have focused on cleaning out your inbox. Now, in addition to showing you how Thunderbird can clear visual and mental clutter out of the way, we’re using filters to make important messages stand out.
Click the Application menu button, then Tools. followed by Message Filters.
Click New. A Filter Rules dialog box will appear.
In the “Filter Name” field, type a name for your filter.
Under “Apply filter when”, check one of the options or both. (You probably won’t want to change from the default “Getting New Mail” and “Manually Run” options.)
In the “Getting New Mail: ” dropdown menu, choose either Filter before Junk Classification or Filter after Junk Classification. (As for me, I’m choosing Filter before Junk Classification. Just in case)
Choose a property, a test and a value for each rule you want to apply:
A property is a message element or characteristic such as “Subject” or “From”
A test is a check on the property, such as “contains” or “is in my address book”
A value completes the test with a specific detail, such as an email address or keyword
Choose one or more actions for messages that meet those criteria. (For extra caution, I put THREE actions on my sample filter. You might only need one!)
<figcaption class="wp-element-caption">(Note – not the actual Jeopardy addresses!)</figcaption>
Find (and Filter) Your Important Messages
Thunderbird also lets you create a filter directly from a message. Say you’re organizing your inbox and you see a message you don’t want to miss in the future. Highlight the email, and click on the Message menu button. Scroll down to and click on ‘Create Filter from Message.’ This will open a New Filter window, automatically filled with the sender’s address. Add any other properties, tests, or values, as above. Choose your actions, name your filter, and ta-da! Your new filter will help you know when that next important email arrives.
Resources
As with last month’s article, this post was inspired by a Mastodon post (sadly, this one was deleted, but thank you, original poster!). Many thanks to our amazing Knowledge Base writers at Mozilla Support who wrote our guide to filters. Also, thanks to Martin Brinkmann and his ghacks website for this and many other helpful Thunderbird guides!
Last month we had a great chat with two members of the Thunderbird Council, our community governance body. This month, we’re looking at the relationship between Thunderbird and our parent organization, MZLA, and the broader Mozilla Foundation. We couldn’t think of a better way to do this than sitting down for a Q&A with Mark Surman, president of the Mozilla Foundation.
We’d love to hear your suggestions for topics or guests for the Thunderbird Community Office Hours! You can always send them to officehours@thunderbird.org.
October Office Hours: Q&A with Mark Surman
In many ways, last month’s office hours was a perfect lead-in to this month’s, as our community and Mozilla have been big parts of the Thunderbird Story. Even though this year marks 20 years since Thunderbird 1.0, Thunderbird started as ‘Minotaur’ alongside ‘Phoenix,’ the original name for Firefox, in 2003. Heather, Monica, and Mark all discuss Thunderbird’s now decades-long journey, but this chat isn’t just about our past. We talk about what we hope is a a long future, and how and where we can lead the way.
If you’ve been a long-time user of Thunderbird, or are curious about how Thunderbird, MZLA, and the Mozilla Foundation all relate to each other, this video is for you.
Watch, Read, and Get Involved
We’re so grateful to Mark for joining us, and turning an invite during a chat at Mozweek into reality! We hope this video gives a richer context to Thunderbird’s past as it highlights one of the main characters in our long story.
Want to keep current with Mark and the rest of the Mozilla Foundation? Check out the Mozilla Blog, which details initiatives to keep the internet open and accessible to all: https://blog.mozilla.org/en/latest/
Hello again Thunderbird Community! The last few months have involved a lot of learning for me, but I have a much better appreciation (and appetite!) for the variety of challenges and opportunities ahead for our team and the broader developer community. Catch up with last month’s update, and here’s a quick summary of what’s been happening across the different teams:
Exchange Web Services support in Rust
An important member of our team left recently and while we’ll very much miss the spirit and leadership, we all learned a lot and are in a good position to carry the project forwards. We’ve managed to unstick a few pieces of the backlog and have a few sprints left to complete work on move/copy operations, protocol logging and priority two operations (flagging messages, folder rename & delete, etc). New team members have moved past the most painful stages and have patches that have landed. Kudos to the patient mentors involved in this process!
QR Code Cross-Device Account Import
Thunderbird for Android launched this week, and the desktop client (Daily, Beta & ESR 128.4.0) now provides a simple and secure account transfer mechanism, so that account settings don’t have to be re-entered for new users of the mobile app. Download Thunderbird for Android from the Play store
Account Hub
Development of a refreshed account hub is moving forward apace and with the critical path broken down into sprints, our entire front end team is working to complete things in the next two weeks. Meta bug & progress tracking.
Clean up on aisle 2
In addition to our project work, we’ve had to be fairly nimble this month, with a number of upstream changes breaking our builds and pipelines. We get a ton of benefit from the platforms we inherit but at times it feels like we’re dealing with many things out of our control. Mental note: stay calm and focus on future improvements!
Global Database, Conversation View & folder corruption issues
On top of the conversation view feature and core refactoring to tackle the inner workings of thread-safe folder and message manipulation, work to implement a long term database replacement is well underway. Preliminary patches are regularly pumped into the development ecosystem for discussion and review, for which we’re very excited!
In-App Notifications
With phase 1 of this project now complete, we’ve scoped out additions that will make it even more flexible and suitable for a variety of purposes. Beta users will likely see the first notifications coming in November, so keep your eyes peeled. Meta Bug & progress tracking.
New Features Landing Soon
Several requested features are expected to debut this month (or very soon) and include…
As usual, if you want to see things as they land, and help us squash some early bugs, you can always check the pushlog and try running daily, which would be immensely helpful for catching things early.
Just over two years ago, we announced our plans to bring Thunderbird to Android by taking K-9 Mail under our wing. The journey took a little longer than we had originally anticipated and there was a lot to learn along the way, but the wait is finally over! For all of you who have ever asked “when is Thunderbird for Android coming out?”, the answer is – today! We are excited to announce that the first stable release of Thunderbird for Android is out now, and we couldn’t be prouder of the newest, most mobile member of the Thunderbird family.
Community Support Forum: Thunderbird for Android has its own home on the official Mozilla Support (SUMO) forums. Find the help you need to configure and use the newest Thunderbird from our community on a mobile friendly site.
Import Settings: Whether you’re importing your information from K-9 Mail or Thunderbird on the desktop, transfer your information quickly and easily with our guide.
System Requirements: Thunderbird for Android runs on mobile devices running Android 5 and above.
Platform Availability: Download Thunderbird for Android from the following places.
Get Involved: Thunderbird for Android thrives thanks to community support, and you can be part of the community! We are grateful to everyone who donates their skill and time to answer support questions, test releases, translate and more. Find out all the ways to get in where you fit in.
Support Us: We are 100% donor-supported. Your gift helps us develop new apps (like this one!), improve speed and stability, promote Thunderbird and software freedom, and provide downloads free-of-charge to millions. Donate on our webpage or in the app.
Suggest New Features: We know you have great ideas for future features. You can share them on Mozilla Connect, where community members can upvote and comment on them. Our team uses the feedback here to help shape our roadmap.
Thanks for Helping Thunderbird for Android Fly
Thank you for being a part of the community and sharing this adventure on Android with us! We’re especially grateful to all of you who have helped us test the beta and release candidate images. Your feedback helped us find and fix bugs, test key features, and polish the stable release. We hope you enjoy using the newest Thunderbird, now and for a long time to come!
For me, staying on top of my inbox has always seemed like an unattainable goal. I’m not an organized person by nature. Periodic and severe email anxiety (thanks, grad school!) often meant my inbox was in the quadruple digits (!).
Lately, something’s shifted. Maybe it’s working here, where people care a lot about making email work for you. These past few months, my inbox has stayed if not manageable, then pretty close to it. I’ve only been here a year, which has made this an easier goal to reach. Treating my email like laundry is definitely helping!
But how do you get a handle on your inbox when it feels out of control? R.L. Dane, one of our fans on Mastodon, reminded us Thunderbird has a powerful, built-in tool than can help: the ‘Grouped by Sort’ feature!
Email Management for All Brains
For those of us who are neurodiverse, email management can be a challenge. Each message that arrives in your inbox, even without a notification ding or popup, is a potential distraction. An email can contain a new task for your already busy to-do list. Or one email can lead you down a rabbit hole while other emails pile up around it. Eventually, those emails we haven’t archived, replied to, or otherwise processed take on a life of their own.
Staring at an overgrown inbox isn’t fun for anyone. It’s especially overwhelming for those of us who struggle with executive function – the skills that help us focus, plan, and organize. A full or overfull inbox doesn’t seem like a hurdle we can overcome. We feel frozen, unsure where to even begin tackling it, and while we’re stuck trying to figure out what to do, new emails keep coming. Avoiding our inboxes entirely starts to seem like the only option – even if this is the most counterproductive thing we can do.
So, how in the world do people like us dig out of our inboxes?
Feature for Focus: Grouped by Sort
We love seeing R.L. Dane’s regular Thunderbird tips, tricks, and hacks for productivity. In fact, he was the one who brought this feature to our attention on a Mastodon post! We were thrilled when we asked if we could turn it to a productivity post and got an excited “Yes!” in response.
As he pointed out, using Grouped by Sort, you can focus on more recently received emails. Sorting by Date, this feature will group your emails into the following collapsible categories:
Today
Yesterday
Last 7 Days
Last 14 Days
Older
Turning on Grouped by Sort is easy. Click the message list display options, then click ‘Sort by.’ (In the top third, toggle the ‘Date’ option. In the second third, select your preferred order of Descending or Ascending. Finally, in the bottom third, toggle ‘Grouped by Sort.’
Now you’re ready to whittle your way through an overflowing inbox, one group at a time.
And once you get down to a mostly empty and very manageable inbox, you’ll want to find strategies and habits to keep it there. Treating your email like laundry is a great place to start. We’d love to hear your favorite email management habits in the comments!
We’re back with another contributor highlight! We asked our most active contributors to tell us about what they do, why they enjoy it, and themselves. Last time, we talked with Arthur, and for this installment, we’re chatting with Toad Hall.
If you’ve used Support Mozilla (SUMO) to get help with Thunderbird, Toad Hall may have helped you. They are one of our most dedicated contributors, and their answers on SUMO have helped countless people.
How and Why They Use Thunderbird
Thunderbird has been my choice of email client since version 3, so I have witnessed this product evolve and improve over the years. Sometimes, new design can initially derail you. Being of an older generation, I appreciate it is not necessarily so easy to adapt to change, but I’ve always tried to embrace new ideas and found that generally, the changes are an improvement.
Thunderbird offers everything you expect from handling several email accounts in one location, filtering, address books and calendar, plus many more functionalities too numerous to mention. The built in Calendar with its Events and Tasks options is ideal for both business and personal use. In addition, you can also connect to online calendars. I find using the pop up reminders so helpful whether it’s notifying you of an appointment, birthday or that a TV program starts in 15 minutes! Personally, I particularly impressed that Thunderbird offers the ability to modify the view and appearance to suit my needs and preferences.
I use a Windows OS, but Thunderbird offers release versions suitable for Windows, MAC and Linux variants of Operating Systems. So there is a download which should suit everyone. In addition, I run a beta version so I can have more recent updates, meaning I can contribute by helping to test for bugs and reporting issues before it gets to a release version.
How They Contribute
The Thunderbird Support forum would be my choice as the first place to get help on any topic or query and there is a direct link to it via the ‘Help’ > ‘Get Help’ menu option in Thunderbird. As I have many years of experience using Thunderbird, I volunteer my free time to assist others in the Thunderbird Support Forum which I find a very rewarding experience. I have also helped out writing some Support Forum Help Articles. In more recent years I’ve assisted on the Bugzilla forum helping to triage and report potential bugs. So, people can get involved with Thunderbird in various ways.
Share Your Contributor Highlight (or Get Involved!)
Thanks to Toad Hall and all our contributors who have kept us alive and are helping us thrive!
If you’re a contributor who would like to share your story, get in touch with us at community@thunderbird.net. If you want to get involved with Thunderbird, read our guide to learn about all the ways to contribute.
Hello Thunderbird Community! I’m Toby Pilling, a new team member and I’ve spent the last couple of months getting up to speed, and have really enjoyed meeting the team and members of the community virtually, and some in person! September is now over (and so is the summer for many in our team), and we’re excited to share the latest adventures underway in the Thunderbird world. If you missed our previous update, go ahead and catch up! Here’s a quick summary of what’s been happening across the different teams:
Exchange
Progress continues on implementing move/copy operations, with the ongoing re-architecture aimed at making the protocol ecosystem more generic. Work has also started on error handling, protocol logging and a testing framework. A Rust starter pack has been provided to facilitate on-boarding of new team members with automated type generation as the first step in reducing the friction.
Account Hub
Development of a refreshed account hub is moving forward, with design work complete and a critical path broken down into sprints. Project milestones and tasks have been established with additional members joining the development team in October. Meta bug & progress tracking.
Global Database & Conversation View
The team is focused on breaking down the work into smaller tasks and setting feature deliverables. Initial work on integrating a unique IMAP ID is being rolled out, while the conversation view feature is being fast-tracked by a focused team, allowing core refactoring to continue in parallel.
In-App Notification
This initiative will provide a mechanism to notify users of important security updates and feature releases “in-app”, in a subtle and unobtrusive manner, and has advanced at break-neck speed with impressive collaboration across each discipline. Despite some last-minute scope creep, the team has moved swiftly into the testing phase with an October release in mind. Meta Bug & progress tracking.
Source Docs Clean-up
Work continues on source documentation clean-up, with support from the release management team who had to reshape some of our documentation toolset. The completion of this project will move much of the developer documentation closer to the actual code which will make things much easier to maintain moving forwards. Stay tuned for updates to this in the coming week and follow progress here.
Account Cross-Device Import
As the launch date for Thunderbird for Android gets closer, we’re preparing a feature in the desktop client which will provide a simple and secure account transfer mechanism, so that account settings don’t have to be re-entered for new users of the Android client. A functional prototype was delivered quickly. Now that design work is complete, the project entered the 2 final sprints this week. Keep track here.
Battling OAuth Changes
As both Microsoft and Google update their OAuth support and URLs, the team has been working hard to minimize the effect of these changes on our users. Extended logging in Daily will allow for better monitoring and issue resolution as these updates roll out.
New Features Landing Soon
Several requested features are expected to debut this month or very soon:
Encrypted draft messages even when no recipients are specified.
UI enhancements and bug fixes for the calendar, RSS, and mail modules.
As usual, if you want to see things as they land you can check the pushlog and try running daily. This would be immensely helpful for catching bugs early.
We’ve just released Thunderbird version 128, codenamed “Nebula”, our yearly stable release. So with that big milestone done, I wanted to take a moment and tell our community about the state of Thunderbird. In the past I’ve done a recap focused solely on the project’s financials, which is interesting – but doesn’t capture all of the great work that the project has accomplished. So, this time, I’m going to try something different. I give you the State of the Bird: Thunderbird Annual Report 2023-2024.
Before we jump into it, on behalf of the Thunderbird Team and Council, I wanted to extend our deepest gratitude to the hundreds of thousands of people who generously provided financial support to Thunderbird this past year. Additionally, Thunderbird would like to thank the many volunteers who contributed their time to our many efforts. It is not an exaggeration to say that this product would not exist without them. All of our contributors are the lifeblood of Thunderbird. They are the beacons shining brightly to remind us of the transformative power of open source, and the influence of the community that stands alongside it. Thank you for not just being on this journey with us, but for making the journey possible.
Supernova & Nebula
Thunderbird Supernova 115 blazed into existence on July 11, 2023. This Extended Support Release (ESR) not only introduced cool code names for releases, but also helped bring Thunderbird a modern look and experience that matched the expectation of users in 2023. In addition to shedding our outdated image, we also started tackling something which prevented a brisk development pace and steady introduction of new features: two decades of technical debt.
After three years of slow decline in Daily Active Users (DAUs), the Supernova release started a noticeable upward trend, which reaffirms that the changes we made in this release are putting us on the right track. What our users were responding to wasn’t just visual, however. As we’ve noted many times before – Supernova was also a very large architectural overhaul that saw the cleanup of decades of technical debt for the mail front-end. Supernova delivered a revamped, customizable mail experience that also gave us a solid foundation to build the future on.
Fast forwarding to Nebula, released on July 11, 2024, we built upon many of the pillars that made Supernova a success. We improved the look and feel, usability, customization and speed of the mail experience in truly substantial ways. Additionally, many of the investments in improving the Thunderbird codebase began to pay dividends, allowing us to roll in preliminary Exchange support and use native OS notifications.
All of the work that has happened with Supernova and Nebula is an effort to make Thunderbird a first-class email and productivity tool in its own right. We’ve spent years paying down technical debt so that we could focus more on the features and improvements that bring value to our users. This past year we got to leverage all that hard work to create a truly great Thunderbird experience.
K-9 Mail & Thunderbird For Android
In response to the enormous demand for Thunderbird on a phone, we’ve worked hard to lay a solid foundation for our Android release. The effort to turn K-9 Mail into something we can confidently call a great Thunderbird experience on-the-go is coming along nicely.
In April of 2023, we released K-9 6.600 with a message view redesign that brought K-9 and Thunderbird more in line. This release also had a more polished UI, among other fixes, improvements, and changes. Additionally, it integrated our new design system with reusable components that will allow quicker responses to future design changes in Android.
The 6.7xx Beta series, developed throughout 2023, primarily focused on improving account setup. The main reason for this change is to enable seamless email account setup. This also started the transition of K-9’s UI from traditional Android XML layouts to using the more modern and now recommended Jetpack Compose UI toolkit, and the adoption of Atomic Design principles for a cohesive, intuitive design. The 6.710 Beta release in August was the first to include the new account setup for more widespread testing. Introducing new account setup code and removing some of the old code was a step in the right direction.
In other significant events of 2023, we hired Wolf Montwé as a senior software engineer, doubling the K-9 Mail team at MZLA! We also conducted a security audit with 7ASecurity and OSTIF. No critical issues were found, and many non-critical issues were fixed. We began experimenting with Material 3 and based on positive results, decided to switch to Material 3 before renaming the app. Encouraged by our community contributors, we moved to Weblate for localization. Weblate is better integrated into K-9 and is open source. Some of our time was also spent on necessary maintenance to ensure the app works properly on the latest Android versions.
So far this year, we’ve shipped the account setup improvements to everyone and continued work on Material 3 and polishing the app in preparation for its transition to “Thunderbird for Android.” You can look at individual release details in our GitHub repository and track the progress we’ve made there. Suffice to say, the work on creating an amazing Android experience has been significant – and we look forward to sharing the first true Thunderbird release on Android in the next few months.
Services and Infrastructure
In 2023 we began working in earnest on delivering additional value to Thunderbird users through a suite of web services. The reasoning? There are some features that would add significant value to our users that we simply can’t do in the Thunderbird clients alone. We can, however, create amazing, open source, privacy-respecting services that enhance the Thunderbird experience while aligning with our values – and that’s what we’ve been doing.
The services that we’ve focused on are: Appointment, a calendar scheduling tool; Send, an encrypted large-file transfer service; and Thunderbird Sync, which will allow users to sync their Thunderbird settings between devices (both desktop and Android).
Thunderbird Appointment enables you to plan less and do more. You can add your calendars to the service, outline your weekly availability and then send links that allow others to grab time on your schedule. No more long back-and-forth email threads to find a time to meet, just send a link. We’ve just opened up beta testing for the service and look forward to hearing from early users what features our users would like to see. For more information on Thunderbird Appointment, and if you’d like to sign up to be a beta tester, check out our Thunderbird Appointment blog post. If you want to look at the code, check out the repository for the project on GitHub.
The Thunderbird team was very sad when Firefox Send was shut down. Firefox Send made it possible to send large files easily, maybe easier than any other tool on the Internet. So we’re reviving it, but not without some nice improvements. Thunderbird Send will not only allow you to send large files easily, but our version also encrypts them. All files that go through Send are encrypted, so even we can’t see what you share on the service. This privacy focus was important in building this tool because it’s one of our core values, spelled out in the Mozilla Manifesto (principle 4): “Individuals’ security and privacy on the internet are fundamental and must not be treated as optional.”
Finally, after many requests for this feature, I’m happy to share that we are working hard to make Thunderbird Sync available to everyone. Thunderbird Sync will allow you to sync your account and application settings between Thunderbird clients, saving time at setup and headaches when you use Thunderbird on multiple devices. We look forward to sharing more on this front in the near future.
2023 Financial Picture
All of the above work was made possible because of our passionate community of Thunderbird users. 2023 was a year of significant investment into our team and our infrastructure, designed to ensure the continued long-term stability and sustainability of Thunderbird. As previously mentioned these investments would not have been possible without the remarkable generosity of our financial contributors.
Contribution Revenue
Total financial contributions in 2023 reached $8.6M, reflecting a 34.5% increase over 2022. More than 515,000 transactions from over 300,000 individual contributors generated this financial support (26% of the transactions were recurring monthly contributions).
In addition to that incredible total, what stands out is that the majority of our contributions were modest. The average contribution amount was $16.90, and the median amount was $11.12.
We are often asked if we have “super givers” and the refreshing answer is “no, we simply have a super community.” To underscore this, consider that 61% of giving was $20 or less, and 95% of the transactions were $35 or less. The number of transactions $1000 and above accounted for only 56 transactions; that’s effectively 0.0007% of all contribution transactions.
And this super community helping us sustain and improve Thunderbird is very much a global one, with contributions pouring in from more than 200 countries! The top five giving countries — Germany, the United States, France, the United Kingdom, and Japan — accounted for 63% of our contribution revenue and 50% of transactions. We believe this global support is a testament to the universal value of Thunderbird and the core values the project stands for.
Expenses
Now, let’s talk about how we’re using these funds to keep Thunderbird thriving well into the future.
As with most organizations, employee-related expenses are the largest expense category. The second highest category for us are all the costs associated with distributing Thunderbird to tens of millions of users and the operations that help make that happen. You can see our spending across all categories below:
The Importance of Supporting Thunderbird
When I started at Thunderbird (in 2017), we weren’t on a sustainable path. The cost of building, maintaining and distributing Thunderbird to tens of millions of people was too great when compared against the financial contributions we had coming in. Fast forward to 2023 and we’re able to not only deliver Thunderbird to our users without worrying about keeping the lights on, but we are able to fix bugs, build new features and invest in new platforms (Android). It’s important for Thunderbird to exist because it’s not just another app, but one built upon real values.
Our values are:
We believe in privacy. We don’t collect your data or spy on you, what you do in Thunderbird is your business, not ours.
We believe in digital wellbeing. Thunderbird has no dark patterns, we don’t want you doomscrolling your email. Apps should help, not hurt, you. We want Thunderbird to help you be productive.
We believe in open standards. Email works because it is based on open standards. Large providers have undermined these standards to lock users into their platforms. We support and develop the standards to everyone’s benefit.
If you share these values, we ask that you consider supporting Thunderbird. The tech you use doesn’t have to be built upon compromises. Giving to Thunderbird allows us to create good software that is good for you (and the world). Consider giving to support Thunderbird today.
2023 Community Snapshot
As we’ve noted so many times in the previous paragraphs, it’s because of Thunderbird’s open source community that we exist at all. In order to better engage with and acknowledge everyone participating in our projects, this past year we set up a Bitergia instance, which is now public. Bitergia has allowed us to better measure participation in the community and find where we are doing well and improving, and areas where there is room for improvement. We’ve pulled out some interesting metrics below.
For reference, Github and Bugzilla measure developer contributions. TopicBox measures activity across our many mailing lists. Pontoon measures the activity from volunteers who help us translate and localize Thunderbird. SUMO measures the impact of Thunderbird’s support volunteers who engage with our users and respond to their varied support questions.
Contributor & Community Growth
Thank You
In conclusion, we’d simply like to thank this amazing community of Thunderbird supporters who give of their time and resources to create something great. 2023 and 2024 have been years of extraordinary improvement for Thunderbird and the future looks bright. We’re humbled and pleased that so many of you share our values of privacy, digital wellbeing and open standards. We’re committed to continuing to provide Thunderbird for free to everyone, everywhere – thanks to you!
The Thunderbird for Android beta is out and we’re asking our community to help us test it. Beta testing helps us find critical bugs and rough edges that we can polish in the next few weeks. The more people who test the beta and ensure everything in the testing checklist works correctly, the better!
Author’s Note (January 27, 2025): Even though it’s been a few months since we launched the stable version of Thunderbird for Android, we still need beta testers! As we launch new features and make needed improvements, beta testers help us know what’s working and what isn’t. With major beta releases, staff provides testing guidance similar to this blog post. To join us, download the beta from the links below, and follow the advice in ‘Where to Give Feedback.’
Help Us Test!
Anyone can be a beta tester! Whether you’re an experienced beta tester or you’ve never tested a beta image before, we want to make it easy for you. We are grateful for your time and energy, so we aim to make testing quick, efficient, and hopefully fun!!
The release plan is as follows, and we hope to stick to this timeline unless we encounter any major hurdles:
September 30 – First beta for Thunderbird for Android
Third week of October – first release candidate
Fourth week of October – Thunderbird for Android release
Download the Beta Image
Below are the options for where you can download with Beta and get started:
Download the latest pre-release version from our Github Releases page
We are still working on preparing F-Droid builds. In the meanwhile, please make use of the other two download mechanisms.
Use the Testing Checklist
Once you’ve downloaded the Thunderbird for Android beta, we’d like you to check that you can do the following:
Automatic Setup (user only provides email address and maybe password)
Manual Setup (user provides server settings)
Read Messages
Fetch Messages
Switch accounts
Move email to folder
Notify for new message
Edit drafts
Write message
Send message
Email actions: reply, forward
Delete email
NOT experience data loss
Test the K-9 Mail to Thunderbird for Android Transfer
If you’re already using K-9 Mail, you can help test an important feature: transferring your data from K-9 Mail to Thunderbird for Android. To do this, you’ll need to make sure you’ve upgraded to the latest beta version of K-9 Mail.
This transfer process is a key step in making it easier for K-9 Mail users to move over to Thunderbird. Testing this will help ensure a smooth and reliable experience for future users making the switch.
Later builds will additionally include a way to transfer your information from Thunderbird Desktop to Thunderbird for Android.
What we’re not testing
We know it’s tempting to comment about everything you notice in the beta. For the purpose of this short initial beta, we won’t be focusing on addressing longstanding issues. Instead, we ask you to be laser focused on critical bugs, the checklist above, and issues could prevent users from effectively interacting with the app, to help us deliver a great initial release.
Where to Give Feedback
Share your feedback on the Thunderbird for Android beta mailing list and see the feedback of other users. It’s easy to sign up and let us know what worked and more importantly, what didn’t work from the tasks above. For bug reports, please provide as much detail as possible including steps to reproduce the issue, your device model and OS version, and any relevant screenshots or error messages.
Want to chat with other community members, including other testers and contributors working on Thunderbird for Android? Join us on Matrix!
Do you have ideas you would like to see in future versions of Thunderbird for Android? Let us know on Mozilla Connect, our official site to submit and upvote ideas.
The wait is almost over! Thunderbird for Android will be here soon. As an open-source project, we could not succeed without the incredible volunteer contributors who help us along the way. Whether you’re a fan of problem-solving, localization, testing, development, or even just spreading the word, there’s a role for you in our community. Contributing doesn’t just benefit us – it’s a great way to grow your own skills and make a real difference in the lives of thousands of Thunderbird users worldwide. However you choose to contribute to Thunderbird for Android, we’re always happy to welcome new friends to the project!
Support
If you’re a natural at getting to the root of problems, consider becoming a support contributor!
When you answer a support question, you’re not only helping the person who asked the question, you’re helping the hundreds if not thousands of people who read it. Or if you like writing and editing, you can help with our knowledge base (KB) articles!
Support for Thunderbird on Android will live on Mozilla Support, aka SUMO, just like support for the Desktop application, but under its own product tile. We’ve put together a guide to get you started on SUMO, from setting up an account and finding questions to best practices, whether you to decide to help in the question forums or in the KB articles. Want to talk to other support volunteers? Join us on our Support Crew Matrix channel.
Localization
Thunderbird’s users are all over the world, and our localization contributors put the app and support articles in their language. Thunderbird for Android’s localization lives on Weblate, copyleft libre continuous localization that powers many other open source projects. If you haven’t used Weblate before, they have a useful guide for getting started.
Testing
If you want to try the newest features and help us polish and perfect them before they make it to a general release, join us as a tester. Testers are comfortable using daily and beta releases and providing meaningful feedback to developers.
When they’re available, you can download the Thunderbird for Android Beta releases from the Google Play Store or from GitHub under the ‘Pre-Release’. F-Droid users will need to manually select beta versions. To get update notification for non-suggested versions you need to check ‘Settings > Expert mode > Unstable updates’ in the F-Droid app.
Just like Thunderbird for desktop, we have a mailing list where you can give feedback and talk to developers and fellow beta testers.
Development
Interested at helping at the code level? All our development happens on our GitHub page, where you can read our code contributor section in our CONTRIBUTING.md page.
Look for issues that are tagged ‘good first issue,’ even if you’re an experienced developer but are new to Thunderbird for Android. Use the android-planning mailing list to talk to and get feedback from other developers.
Promote Thunderbird for Android
Spreading the word about Thunderbird for Android is an essential way to contribute, and there are many ways to do this. You can leave us a positive review on the Google Play Store (if you had a positive experience, of course) and encourage others to download and try Thunderbird for Android. This could be friends or family, a local computer club, or any other group you could think of! We’d love to hear your ideas and find a way to support you on the android-planning mailing list.
Financial Support
Financial support is a fantastic way to ensure the project continues to thrive. Your gift goes toward improving features, fixing bugs, and expanding the app’s functionality for all of its users.
By supporting Thunderbird financially, you’re investing in open-source software that respects your privacy and gives you control over your data. Every contribution, no matter how small, helps us maintain our independence and stay true to our mission.
The Thunderbird Council is an important part of the Thunderbird story, and one of the main reasons we’re still around. In this month’s office hours, we sat down to chat with one of the very first Thunderbird Council members, Patrick Cloke, and one of the newest, Danny Colin, to discuss what this key group does and offers advice for those thinking about running in future elections.
Next month, we’ll put out a call for questions on socialmedia and on the relevant TopicBox mailing lists for our next Office Hours, which will feature Ryan Sipes, Managing Director of Product at MZLA and Mark Surman, executive director of the Mozilla Foundation!
September Office Hours: The Thunderbird Council
While Thunderbird has been around almost 20 years, the Council hasn’t always been a part of it. In 2012, Mozilla discontinued support for Thunderbird as a product, but our community stepped in. In 2014, core contributors met in Toronto and elected the first Thunderbird Council to guide the project. For many years, the council was responsible for the day-to-day responsibilities, including development, budgeting, and hiring. While MZLA now handles those operations, the council has an even more crucial role. In the video, Danny and Patrick explain how the modern-day council works with MZLA and serves as the community’s voice.
Want to know more about what council members do, or who can run for council? Our guests provide honest and encouraging answers to these questions. Basically, if you’re an active contributor who cares about Thunderbird, you might consider running!
Watch, Read, and Get Involved
We’re so grateful to Danny and Patrick for joining us! We hope this video helps explain more about the Thunderbird Council’s role, and even encourages some of you who are active Thunderbird contributors to consider running in the future. And if you’re not an active contributor yet, go to our website to learn how to get involved!
Thunderbird and its features help you do things. Crossing things off your to-do list means getting your time and energy back. Using Thunderbird and its Add-ons for productivity? Now that’s how you take your workflow to the next level.
One of Thunderbird’s biggest strengths is its vibrant, community-driven Add-ons. Many of those Add-ons are all about helping you get more out of Thunderbird. We asked our community what Add-ons they were using and would recommend to readers in this post. And did our community respond! You can read all of the recommendations from our community on Mastodon, Reddit, X (formerly Twitter) and LinkedIn.
We’re grateful for all the recommendations and for all of our Add-on developers! They put their personal time into making Thunderbird even more incredible through their extensions. The Add-ons in this list are only a small, small subset of all the active ones. We highly encourage you to check out the whole wide world of Add-ons out there.
(And if you’re wondering, I’ve downloaded Quicktext and Markdown Here Revival for my own workflow.)
Add-Ons to Try Today: Folders and Accounts
Border Colors D – Having all your email accounts in one app is already a productivity boost. What’s not productive is accidentally sending a message from the wrong account. Border Colors D allows you to assign a color and other visual indicators to the New Message window for each account. If you’re a “power user with many accounts [who] can’t afford an oops when you send with the wrong source address,” this is the Add-on for you.
Quick Folder Move – Sorting messages into folders is a great way to keep the information in your email organized. (We love using folders to sort our inbox down to zero!) This Add-on brings up a search bar or your recent folders, and allows you to move messages with ease – especially if you have a lot of folders
Add-ons to Try Today: Inbox Views and Message Composition
Thunderbird Conversations – When “you need to see quickly all received and sent mails…very important in a context of a shared mail box,” a conversation view is great. While that view is something we’d love to see built in to Thunderbird, there’s work on our underlying database we need to do first. But this Add-on brings that view to Thunderbird, and to your inbox, now.
Markdown Here Revival – Is Markdown part of your productivity and workflow toolbox? This Add-on will allow you to write emails in Markdown and send them as HTML with the click of a button! One of our recommenders said this Add-on is “absolutely mandatory.”
Send Later – Sometimes, part of your productivity routine involves scheduling things to be sent later. Or, as the recommendation added, you don’t want your boss to know you were working on something at 2 am. This add-on adds true send later functionality to Thunderbird, so you decide when that message gets sent, whether it’s one time or regularly. (But really, night owls, sleep is good!)
Our community loves Nostalgy++, especially on Reddit. Nostalgy++ brings the power of keyboard shortcuts to Thunderbird to let you manage, search, and archive emails. One user says they save hours every week thanks to Nostalgy++’s keybindings.
Add-Ons to Test Today!
A few of our community’s favorite Add-ons are in beta testing for their fully 128-compatible versions, as of September 2024. Testing is one of the best and most beginner-friendly ways to contribute to Thunderbird. If you’d like to boost your productivity AND make a developer’s day, we have an Add-on we’d encourage you to check out.
Remove Duplicate Message is another Add-on that is also seeking beta testers for their 128-compatible version. For anyone who has ever dealt with replies to a “catch-all” email address or anything else cluttering their inbox with duplicates, this Add-on can take care of those copies for you. Check out their latest release and provide feedback on their GitHub Issues.
Dealing with spam in our daily email routines can be frustrating, but Thunderbird has some tools to make unwanted messages less of a headache. It takes time, training, and patience, but eventually you can emerge victorious over that junk mail. In this article we’ll explain how Thunderbird’s spam filter works, and how to tune it for the most effective results.
What Powers Thunderbird’s Spam Filter?
Thunderbird’s adaptive filter uses one of the oldest methods around — a Bayes algorithm — to help decide which messages should be marked as junk. But in order to work efficiently and reliably, it also needs a little help from you.
Thunderbird’s documentation and support community have always mentioned that the spam filter needs some human intervention, but I never understood why until researching how a Bayes algorithm works.
Why A Bayes Algorithm Needs Your Help
It’s helpful to think about Thunderbird’s spam filter as a sort of inbox detective, but you’re instrumental in training it and making it smarter. That’s because a Bayes algorithm calculates the odds that an email is spam based on the words it contains, and uses past experience to make an educated guess.
Here’s an example: you receive an email that contains the words “Urgent, act now to claim your free prize!” The algorithm checks to see how frequently those words appear in known spam messages compared to known good messages. If it detects those words (especially ones like “free” and “prize,”) are frequently in messages you’ve marked as spam, but not present in good messages, it will mark it as junk.
This is why it’s equally important to mark messages as “Not Junk.” Then, it learns to recognize “good” words that are common across non-spam emails. And for each message you mark, the probability that Thunderbird’s spam filter accurately identifies spam only increases.
Of course, it’s not perfect. A message you mark as junk might not consistently be marked as junk. A reliable, fail-safe way to ensure certain messages are marked as junk is to create filters manually.
Do you want to ensure important messages are never marked as junk? Try whitelisting.
Since junk mail patterns are always changing, it’s a good idea to regularly train Thunderbird. Without frequent training, it may not provide great results.
Junk Filter Settings
Now that we understand what powers Thunderbird’s junk filter, let’s look at how to manage the settings, and how to train Thunderbird for more consistent results.
Global Junk Settings
Junk filtering is enabled by default, but you can fine-tune what should happen to messages marked as junk using the global settings. These settings apply to all email accounts, though some can be overridden in the Per Account Settings.
Click the menu button (≡) > Settings > Privacy & Security.
Scroll down to Junk and adjust the settings to your preference.
Per Account Settings
The junk settings for each of your email accounts will override similar settings in the Global Settings.
Click the menu button (≡) > Account Settings > Your email address > Junk Settings.
How to Turn Off Thunderbird’s Adaptive Filtering
To disable Thunderbird’s adaptive junk mail controls:
Uncheck Enable adaptive junk mail controls for this account.
Whitelisting
Under Do not automatically mark mail as junk if the sender is in, you can select address books to use as a whitelist. Senders whose email addresses are in a whitelisted address book won’t be automatically marked as junk. However, you can still manually mark a message from a whitelisted sender as junk.
Enabling whitelisting is recommended to help ensure messages from people you care about are not marked as junk.
Training the Junk Filter
This part is important: for Thunderbird’s junk filter to be effective, you must train it to recognize both junk and non-junk messages. If you only do one or the other, the filter won’t be very effective.
It’s important to mark messages as junk before deleting them. Just deleting a message doesn’t train the filter.
Press J on your keyboard to mark one or more selected messages as junk.
Once you mark a message as junk, if you’ve configured your Global Junk Settings or Per Account Settings to move junk email to a different folder, the email will disappear from the Message List Pane. Don’t worry, the email has moved to the folder you’ve configured for junk mail.
Thunderbird’s junk filter is designed to learn from the training data you provide. Marking more messages as Junk or Not Junk will improve the accuracy of your junk filter by adding more training data.
Tell Thunderbird What is NOT Junk
Sometimes Thunderbird’s junk filter might mark good messages as junk. It’s important to tell the filter which messages are not junk, especially on a new installation of Thunderbird.
Note: Frequently (daily or weekly) check your Junk folder for good messages wrongly marked as junk and mark them as Not Junk. This will recover the good messages and improve the filter’s accuracy.
There are several ways to mark messages as Not Junk:
Click the Not Junk button in the yellow junk notification below the message header in the Message List Pane:
Click the red junk icon in the Junk column of the Message List Pane to toggle the junk status of a message:
Press Shift+J on your keyboard to mark one or more messages as Not Junk.
Once you unmark a message as junk, it will disappear from the current folder but will return to its original folder.
Repeated Training
Regularly train the filter by marking several good messages as not junk. This includes messages in your inbox and those filtered into other folders. Use the keyboard shortcut Shift+J for this, as the Not Junk button only appears for messages already marked as junk. Marking several messages per week will be sufficient, and you can select many messages to mark all at once.
Unfortunately, the user interface doesn’t indicate whether a message has already been marked as “not junk.”
Other Ways to Block Unwanted Messages
Thunderbird’s adaptive junk filter is not an absolute barrier against messages from specific addresses or types of messages. You can use stronger mechanisms to block unwanted messages:
We’re back for an update on Thunderbird for Android/K-9 Mail, combining progress reports for July and August. Did you miss our June update? Check it out! The focus over these two months has been on quality over quantity—behind each improvement is significant groundwork that reduces our technical debt and makes future feature work easier to tackle.
Material 3 Update
As we head towards the release of Thunderbird for Android, we want you to feel like you are using Thunderbird, and not just any email client. As part of that, we’ve made significant strides toward compatibility with Material 3 to better control coloring and give you a native feel. What do you think so far?
The final missing piece is the navigation drawer, which we believe will land in September. We’ve heard your feedback that the unread emails have been a bit hard to see, especially in dark mode, and have made a few other color tweaks to accompany it.
Feature Modules
If you’ve considered contributing as a developer to Thunderbird for Android, you may have noticed many intertwined code modules that are hard to tackle without intricate knowledge of the application. To lower the barrier of entry, we’re continuing the move to a feature module system and have been refactoring code to use them. This shift improves maintainability and opens the door for unique features specific to Thunderbird for Android.
Ready to Play
Having a separate Thunderbird for Android app requires some setup in various app-stores, as well as changes to how apps are signed. While this isn’t the fun feature work you’d be excited to hear about, it is foundational to getting Thunderbird for Android out of the door. We’re almost ready to play, just a few legal checkboxes we need to tick.
Documentation
K-9 Mail user documentation has become outdated, still referencing older versions like K-9 Mail 6.4. Given our current resources, we’ve paused updates to the guide, but if you’re passionate about improving documentation, we’d love your help to bring it back online! If you are interested in maintaining our user documentation, please reach out on the K-9 Forums.
Community Contributions
We’ve had a bunch of great contributions come in! Do you want to see your name here next time? Learn how to contribute.
Many of us Thunderbird users often forget just how convenient using a mail client can be. But as webmail has become more popular over the last decade, some new users might not know the difference between the two, and why you would want to swap your browser for a dedicated app.
In today’s digital world, email remains a cornerstone of personal and professional communication. Managing emails, however, can be a daunting task especially when you have multiple email accounts with multiple service providers to check and keep track of. Thankfully, decades ago someone invented the email client application. While web-based solutions have taken off in recent years, they can’t quite replace the need for managing emails in one dedicated place.
Let’s go back to the basics: What is the difference between an email service provider and an email client application? And more importantly, can we make a compelling case for why an email client like Thunderbird is not just relevant in today’s world, but essential in maintaining productivity and sanity in our fast-paced lives?
An email service provider (ESP) is a company that offers services for sending, receiving, and storing emails. Popular examples include Gmail, Yahoo Mail, Hotmail and Proton Mail. These services offer web-based interfaces, allowing users to access their emails from any device with an internet connection.
On the other hand, an email client application is software installed on your device that allows you to manage any or all of those email accounts in one dedicated app. Examples include Thunderbird, Microsoft Outlook, and Apple Mail. Email clients offer a unified platform to access multiple email accounts, calendars, tasks, and contacts, all in one place. They retrieve emails from your ESP using protocols like IMAP or POP3 and provide advanced features for organizing, searching, and composing emails.
Despite the convenience of web-based email services, email client applications play a huge role in enhancing productivity and efficiency. Webmail is a juggling game of switching tabs, logins, and sometimes wildly different interfaces. This fragmented approach can steal your time and your focus.
So, how can an email client help with all of that?
One Inbox – All Your Accounts
As already mentioned, an email client eliminates the need to switch between different browser tabs or sign in and out of accounts. Combine your Gmail, Yahoo, and other accounts so you can read, reply to, and search through the emails using a single application. For even greater convenience, you can opt for a unified inbox view, where emails from all your different accounts are combined into a single inbox.
Work Offline – Anywhere
Email clients store your emails locally on your device, so you can access and compose emails even without an internet connection. This is really useful when you’re travelling or in areas with poor connectivity. You can draft responses, organize your inbox, and synchronize your changes once you’re back online.
Enhanced Productivity
Email clients come packed with features designed to boost productivity. These include advanced search capabilities across multiple accounts, customizable filters and rules, as well as integration with calendar and task management tools. Features like email templates and delayed sending can streamline your workflow even more.
Care About Privacy?
Email clients offer enhanced security features, such as encryption and digital signatures, to protect your sensitive information. With local storage, you have more control over your data compared to relying solely on a web-based ESP.
No More Clutter and Distractions
Web-based email services often come with ads, sometimes disguised as emails, and other distractions. Email clients, on the other hand, provide a cleaner ad-free experience. It’s just easier to focus with a dedicated application just for email. Not having to reply on a browser for this purpose means less chance of getting sidetracked by latest news, social media, and random Google searches.
All Your Calendars in One Place
Last but not least, managing your calendar, or multiple calendars, is easier with an email client. You can sync calendars from various accounts, set reminders, and schedule meetings all in one place. This is particularly useful when handling calendar invites from different accounts, as it allows you to easily shift meetings between calendars or maintain one main calendar to avoid double booking.
So, if you’re not already using an email client, perhaps this post has given you a few good reasons to at least try it out. An email client can help you organize your busy digital life, keep all your email and calendar accounts in one place, and even draft emails during your next transatlantic flight with non-existent or questionable Wi-Fi.
And just as email itself has evolved over the past decades, so have email client applications. They’ll adapt to modern trends and get enhanced with the latest features and integrations to keep everyone organized and productive – in 2024 and beyond.
Hello Thunderbird Community! It’s August, where did our summer go? (or winter for the folks on the other hemisphere).
Our August has been packed with ESR fixes, team conferences, and some personal time off, so this is gonna be a bit of a shorter update, tackling more upcoming efforts than what recently landed on daily. Miss our last update? Find it here.
More Rust
If you’ve been looking at our monthly metrics you might have noticed that the % of Rust code in our code base is slowly increasing.
We’re planning to push forward this effort in the near future with more protocol reworks and clean up of low level code.
Stay tuned for more updates on this matter and some dedicated posts from the engineers that are driving this effort.
Pushing forward with Exchange
Nothing new to report here, other than that we’re continuing with this implementation and we hope to be able to enable this feature by default in a not so far off Beta.
The general objective before next ESR is to have complete email support and start tapping into Calendar and Address Book integration to offer the full experience out of the box.
Global database
This is also one of the most important pieces of work that we’ve been planning for a while. Bringing this to completion will drastically reduce our most common data loss problems as well as drastically speeding up the performance of Thunderbird when it comes to internal message search and archiving.
Calendar rebuild
Another very large initiative we’re kicking off during this new ESR cycle is a complete rebuild of our Calendar.
Not only are we going to clean up and improve our back-end code handling protocols and synchronization, but we’re also taking a hard look at our UI and UX, in order to provide a more flexible and intuitive experience, reducing the amount of dialogs, and implementing those features that users have come to expect from any calendaring application.
As usual, if you want to see things as they land you can always check the pushlog and try running daily, which would be immensely helpful for catching bugs early.
See ya next month.
Alessandro Castellani(he, him) Director, Desktop and Mobile Apps
If you’re interested in joining the technical discussion around Thunderbird development, consider joining one or several of our mailing list groups here.
We’re excited to share a new project we’ve been working on at Thunderbird called Appointment. Appointment makes it simple to schedule meetings with anyone, from friends and family to colleagues and strangers. Escape the endless email threads trying to find a suitable meeting time across multiple time zones and organizations.
With Appointment, you can easily share your customized availability and let others schedule time on your calendar. It’s simple and straightforward, without any clutter.
If you have tried similar tools, Appointment will feel familiar, while capturing what’s unique about Thunderbird: it’s open source and built on our fundamental values of privacy, openness, and transparency. In the future, we intend for Appointment to be part of a wider suite of helpful products enhancing the core Thunderbird experience. Our ambition is to provide you with not only a first-rate email application but a hub of productivity tools to make your days more efficient and stress-free.
We’ll be rolling out Appointment in phases, continuing to improve it as we open up access to more people. It’s currently in closed beta, so we encourage you to sign up for our waiting list. Let us know what features you find valuable and any improvements you’d like to see. Your feedback will be invaluable as we make this tool as useful and seamless as possible.
To that end, the development repository for Appointment is publicly available on Github, and we encourage any future testers or contributors to get involved and build this with us.
Free yourself from cluttered scheduling apps and never-ending email threads. The simplicity of Appointment lets you find that perfect meeting time, without wasting your precious time.
Not all heroes wear capes. Some of our favorite superheroes are the community members who provide Thunderbird support on the Mozilla Support (SUMO) forums. The community members who help others get to the root of their problems are everyday heroes, and this video shows what it takes to become one of them. Spoiler – you don’t need a spider bite or a tragic origin story! All it takes is patience, curiosity, and a little work.
In our next Office Hours, we’ll be chatting with our Thunderbird Council! One week before we record, we’ll put out a call for questions on socialmedia and on the relevant TopicBox mailing lists. And if you have an idea for an Office Hours you’d like to see, let us know in the comments or email us at officehours@thunderbird.net.
Office Hours: Thunderbird Support (Part 2)
In the sleeper sequel hit of the summer, we sat down to chat with Wayne Mery, who in addition to his work with releases, is our Community Manager as well. Like Roland, Wayne has been with the project practically from the start, and was one of the first MZLA employees. If you’ve spent any time on SUMO, our subreddit, or Bugzilla, chances are you’ve seen Wayne in action helping users.
In this chat and demo, Wayne walks us through the steps to becoming a support superhero. The SUMO forums are community-driven, and (every additional contributor means more knowledge and hopefully fewer unanswered questions.) (This would be a good sport for something about the power of community in open source, and how many of us who got into open source as a career started as volunteers in forums like these.)
The video includes:
The structure and markup language of the SUMO Forums
How to find questions that need answering
Where to meet and chat with other volunteers online
A demonstration of the forum’s workflow
A very helpful DOs and DON’Ts guide
A demo where Wayne answers new questions to show his advice in action
Watch, Read, and Get Involved
This chat helps demystify how we and the global community provide support for Thunderbird users. We hope it and the included deck inspire you to share your knowledge, experience, and problem-solving skills. It’s a great way to get involved with Thunderbird – whether you’re a new or experienced user!
Hello! We’re back for the summer edition of our productivity series, and we’re here with a productivity tip that can save you time AND reduce email anxiety-induced procrastination. We’re talking about email templates.
Marketing and Comms Manager Natalie Ivanova shared why she’s a huge fan of email templates. When one of her three kids are sick, their school requires an email with lots of important details – their teacher’s name, their class number, and class division. She’d hunt through her sent messages for the last sick day email, then have to look up any new info for those key details. More often than not, this search led to procrastinating, which led to an annoyed phone call from her kid’s school.
To take the stress out of these emails, Natalie turned to templates. Templates take the hard work out of writing an email. Instead of facing a dreaded blank page, you have a structure you created, and all you have to do is fill in the blanks. In her case, she made a template for each kid, filled it with the info the school needed, and left blanks for any fields that would change.
Whether you’re updating teachers, sending regular updates to colleagues, or otherwise sending something over and over, let Thunderbird and the power of templates do the heavy lifting.
Creating a Template
Creating a template is a lot like writing an email. Click on ‘New Messages’ to get started. If your template is meant for one recipient – for example, your kid’s school – go ahead and enter the address. Your Subject Line will be how you find your template later – and can be part of the template itself! For a monthly report I send about Thunderbird in the media, I use ‘Media Sentiment Summary [MONTH YEAR]. It’s easy to find AND easy to change. You could almost say it’s magic!
The body of your email is where you put the power of templates to work. For the sick kid template, most of the information is already there. All you need to do is literally hit send. For that monthly report, I put the fields I need to fill in brackets (with text in ALL CAPS to help me notice it and avoid the shame of sending an unedited template), both in the subject and the body.
Writing an Email from Templates
So, you’ve made a template. Yay!
Now, how do you use it?
Thunderbird makes it very easy to find your new template. It lives in the ‘Templates’ folder in the Folder Pane window, just below the Drafts folder. Click on the Templates folder to open it, and click on the Message Menu in the upper right corner. Click ‘New Message from Template’, and your template is ready to edit and send. And every time you use your template, YOU are ready to have more time and less stress.
GUADEC is the annual GNOME conference and this year it was in beautiful Denver, Colorado. Why are we writing about this on the Thunderbird blog? I’m so glad you asked. Thunderbird was there and our very own Ryan Sipes gave a compelling keynote talk!
Ryan’s GUADEC 2024 Keynote
Ryan gave a brief history lesson of Thunderbird, detailed how we survived tough times, and what exciting new things we are working on, including our recent Supernova release.
<figcaption class="wp-element-caption">Thunderbird’s Ryan Sipes presenting at Guadec (Photo by: Dayne Pillow, 2024)</figcaption>
While Thunderbird is cross platform, Ryan highlighted our current focus on native integration with Linux systems, starting with an initial implementation of a Linux system tray icon. We are committed to our Linux users more than ever, no matter their choice of desktop environment, packaging type, or flavor of Linux.
<figcaption class="wp-element-caption">Thunderbird’s Ryan Sipes presenting at Guadec (Photo by: Dayne Pillow, 2024)</figcaption>
Thunderbird in the Hallway Track
Besides Ryan’s talk, there were several meaningful conversations, relevant to various aspects of Thunderbird.
There are shared struggles between our calendar and GNOME calendar, revealing opportunities to work together towards a common solution.
Since the Thunderbird flatpak is one of our supported packages for Linux systems, it was great to hear an update from the flatpak and xdg-desktop-portals developers. We can start to think of how we can leverage recent and upcoming changes to portals to improve the Thunderbird flatpak.
Ryan’s talk pointed out our need for privacy respecting telemetry, and it turns out that is shared by the GNOME app developers as well. Expect to hear more about this in future blog posts, as events develop.
Overall, this year’s GUADEC was an excellent week of collaboration, where we shared many wonderful ideas and strengthened our comradery. Thunderbird’s presence at this conference showed us where we can work with the broader GNOME community and support one another in a way that benefits all of our users. We thank the GNOME foundation for the excellent organization.
Hello Thunderbird Community! As we say goodbye to the month of July, we look back at our major accomplishments and the release of a new ESR version.
ESR Released!
Thunderbird 128 “Nebula” is finally out and we couldn’t be more thrilled.
We fixed more than 1400 bugs, included multiple new features, cleaned up a lot of old code, and enabled Rust development. There’s too much to list so if you’re interested please visit our fancy 128 What’s New Page, blog post, and Release notes to get a much deeper overview of all the juicy things you will get.
We do lots of QA and beta testing, but sometimes major issues are only exposed after significant public testing. That’s why we always roll out a new ESR release gradually. Once we’re confident no problems or regressions exist, we’ll turn on automatic updates — probably towards the end of August.
However, we have enabled manual updates for Windows and macOS users. If you open the About dialogue, you should receive a prompt to update.
If you’re using Flatpak or Snap on Linux, you are probably on version 128 already. For those who receive Thunderbird updates through their Linux distribution’s repositories, the experience may vary depending on the package maintainer. We don’t have control over that, so please reach out to your distro’s maintainer and ask if they have a timeline.
Linux System Tray
A 25-year-old bug was finally fixed!
If you’re running Daily on Linux, you probably noticed a fancy new system tray icon with a quick action to shut down Thunderbird. This is merely the first step towards a more native integration of Thunderbird inside your operating system, not just Linux.
Stay tuned for more improvements and expansion of this new feature. We promise we’ll try to not take another 25 years!
Folder Compaction Cleanup
Our fight to improve folder compaction and solve for good the issue of tmp files bubbling up in size seems to have come to an end. It was challenging to identify the problem, and even more to create a consistent reproducible scenario.
As all the users affected seem to confirm the disappearance of the issue, we took some time to create a migration to clean up those large leftover temporary files polluting your profile.
We’re gonna run this code in Daily and Beta for a few more weeks to make sure it’s safe and tested properly before uplifting it to ESR.
Exchange
As we continue the implementation of a few more features to make sure the full experience is reliable and complete-looking, we decided to switch the preference ON by default on Daily, in order to invite more testing and gather feedback and bugs as early as possible.
If you’re running Daily and have an Exchange account, please consider setting it up in Thunderbird and report any bug you might encounter.
As usual, if you want to see things as they land you can always check the pushlog and try running daily, which would be immensely helpful for catching bugs early.
See ya next month,
Alessandro Castellani(he, him) Director, Desktop and Mobile Apps
If you’re interested in joining the technical discussion around Thunderbird development, consider joining one or several of our mailing list groups here.
Welcome back to our Meet The Team series! I recently had a very entertaining conversation with Sol Valverde, one of the creative minds behind Thunderbird’s user experience and interface design. During our chat, Sol explained how growing up around developers influenced her career path, and discusses the thought process behind designing and improving Thunderbird’s visuals.
Sol also shared a hilarious and heartwarming anecdote about her family’s reaction to her joining our team. It’s a story that underscores the importance of maintaining core Thunderbird features that long-time users rely on, while still modernizing the interface.
For the best and most complete experience, listen to our entire conversation above. Or, you can read select excerpts below.
Q: Can you start by sharing your origin story? How did you end up in UI/UX design?
A: As a kid I always used to draw a lot. I did want to become uh some sort of artistic area professional. However, I do come from a family of programmers. My dad and uncle are both developers. My uncle, he’s been a huge Thunderbird fan for 20 years. But when he found out I got the job he was terrified. He was like “oh my God that’s cool! And also please don’t change anything. It’s perfect the way it is. Don’t touch it!”
Q: What does your role entail?
A: I tend to take the first pass at evaluating how a user is going to interact with something. Like for example the first user experience. When I look at the screen, of course I want to make sure it’s attractive. But I ask things like “will the user understand what they need to do in this screen? Is it intuitive?”
A good experience is potentially one that you will forget. Because if you remember, it probably means that you struggled.
Sol Valverde
Q: How do you ensure that a design is intuitive for users?
A: I love the example of a door. If you have a door without a handle, you can assume it should be pushed. But how do you interact with a door if you don’t know? A lot of doors have “Push” or “Pull” signs. But then you kind of also get the extra interaction with the handle. Sometimes it’s a handle you can grab, but sometimes it’s just a bar that has to be pushed. The design lets you know intuitively what should be done, without needing to read anything. We want to guide the user without hiding anything from the user.
I grew up and learned by grabbing things, breaking things, interacting with them. And that kind of learning for me is crucial. So if the user is going to come into this room and and learn what I want them to learn, I have to make it easy for them to figure it out. I do a lot of research. If I’m working on K-9 Mail, for example, I not only look at other email apps, but also at various social media apps. How easy it to switch accounts? What do I dislike about those applications?
Q: Are there any mobile apps that stand out? Where the user experience is so straightforward there wasn’t any kind of learning curve?
A: The simpler ones tend to be the most intuitive ones. So for example, when you’re using an app to read comics or manga, you tap the book you want, and then you swipe back and forth to turn the pages. Like mimicking the physical actions of reading.
<figcaption class="wp-element-caption">Sol played a big role in improving Thunderbird’s Cards View. </figcaption>
Q: What has been one of the most rewarding projects you’ve worked on at Thunderbird so far?
A: Definitely the Cards View revamp. We redid the first big chunk of code code, but then realized we hadn’t accounted for high contrast and other accessibility needs. We had to address those because accessibility is a must. So, when Micah and I started reworking the design, we thought, “What if we make it ten times better than we originally planned?” Thankfully, Alex was crazy enough to let us do it.
Q: How important is community feedback in your design process?
A: It’s invaluable! The community has a lot of opinions which is great. We design and extrapolate based on our own experiences and those of people we know. We do our best to put ourselves in others’ shoes and predict how they’ll interact with the design. Some comments were straightforward, like “I wish for this or that because it serves me better” or “I just like how it looks.” For UI, as long as it looks cohesive, I’m happy. However, some users provided deeper insights and explained their use personal use cases and concerns. That kind of feedback is so eye-opening, because it addresses things we hadn’t considered. I’m really grateful that they bring those perspectives forward.
Q: OK, big picture question: What’s your overall vision for the user experience in Thunderbird?
A: My whole desire for Thunderbird is it’s something easy to use. It’s something friendly and inviting. However, it can be as complicated or as easy as you want it to be. Intuitive at first glance, but powerful when you need it to be!
If you’re a regular follower of the Thunderbird blog, you might have wondered “what happened with the June office hours?” And while our teams were all pretty busy preparing for Thunderbird 128, we also have changed the Office Hours format. Instead of recording live, which sometimes made scheduling difficult, we’ll be prerecording most Office Hours and releasing a blog with the video and slides, just like this one!
One week before we record, we’ll put out a call for questions on socialmedia and on the relevant TopicBox mailing lists. And every few months, we’ll have open, live ‘ask us anything’ office hours. We are definitely keeping the community in the Community Office Hours, even with the new format.
June Office Hours: Thunderbird Support (Part 1)
In this first of two Office Hours, the Community Team sat down to talk with User Support Specialist Roland Tanglao. Roland has been a long-time Mozilla Support (SUMO) regular, as well as a member of the Thunderbird community. A large part of Roland’s current work is on the Thunderbird side of SUMO, writing and updating Knowledge Base (KB) articles and responding to user questions in the forums.
Roland takes us through the who, what, and how of writing, updating, and translating Thunderbird KB articles. If you’ve ever wanted to write or translate a KB article, or wanted to suggest updates to ones which are out of date, Roland shows you how and where to get started.
Documentation is great way to become an open source contributor, or to broaden your existing involvement.
Highlights of Roland’s discussion include:
The structure and markup language of the SUMO Wiki
How to find KB issues that need help
Where to meet and chat with other volunteers online
A demonstration of the KB revision workflow
Our KB sandbox where you can safely try things out
Watch, Read, and Get Involved
This chat helps demystify how we and the global community create, update, and localize KB articles. We hope it and the included deck inspire you to share your knowledge, eye for detail, or multilingual skills. It’s a great way to get involved with Thunderbird – whether you’re a new or experienced user!
On behalf of the entire team, the Thunderbird Council, and our global community of contributors, I’m excited to announce the initial release of Thunderbird 128 “Nebula.” This annual Extended Support Release (ESR) builds on the solid foundation established by Supernova last year.
Nebula ushers in significant improvements to Thunderbird’s code, stability, overall user experience, and the speed at which we can deliver new features to you.
Here’s a small sample of what you can look forward to in this initial release.
Thunderbird 128: A Rust Revolution
We’ve devoted significant development time integrating Rust — a modern programming language originally created by Mozilla Research — into Thunderbird. Even though this is a seemingly invisible change, it is a major leap forward because it enhances our code quality and performance. This overhaul will allow us to share features between the desktop and future mobile versions of Thunderbird, and speed up our development process. It’s a win for our developers and a win for you.
Redesigned Cards View
The Cards View, which debuted in 115 Supernova, has been tuned and refined for an even better experience. The new layout is more attractive and makes it easier to scan your email threads and glean information at a glance. Plus, the height of email cards adjusts automatically based on your settings, ensuring everything looks just right.
Enhanced Folder Pane
The Folder Pane has received several improvements, including faster rendering and searching of unified folders, better recall of message thread states, and multi-folder selection. We hope these changes make managing your folders faster and more intuitive.
Accent Colors
Thunderbird now offers improved theme compatibility, which is especially beneficial for our Linux users on Ubuntu and Mint. Your Thunderbird should blend seamlessly with your desktop environment, matching the system’s accent colors perfectly.
More Refinements & Updates
Account Color Customization: By popular demand, you can now customize the color of your account icons. These colors also appear in the “From” selection when composing emails, adding a light personal touch to your email experience.
Streamlined Menu Navigation: We’ve simplified menu navigation with better visual cues and reduced cognitive load. These enhancements make using Thunderbird more efficient and enjoyable.
Native Windows Notifications: Thunderbird’s native Windows notifications are now fully functional. Clicking a notification will dismiss it, bring Thunderbird to the foreground, and select the relevant message. Notifications also disappear when Thunderbird is closed, ensuring a seamless experience.
Improved Context Menu: The context menu has been reorganized for a smoother experience, with primary actions now displayed as icons for quick access.
Upcoming Exchange and Mozilla Sync Features
We plan to launch the first phase of built-in support for Exchange, as well as Mozilla Sync, in a future Nebula point release (e.g. Thunderbird 128.X). Although these features are very close to being finished, technical obstacles prevented them from being ready today. Alex will keep you updated in his monthly Thunderbird Monthly Dev Digests.
For advanced users who want to help test our initial implementation of Exchange (currently limited to Mail), it is now available in our Daily and Beta builds. This Wiki page has more information as well as instructions for enabling it. While we definitely welcome your testing and feedback, please keep in mind this feature is currently experimental, and you may run into unexpected behavior or errors.
Looking Forward
In space, a supernova creates the building blocks of creation. In a nebula, those elements nurture new possibilities. Thunderbird 128 Nebula brings together and builds on the best of Supernova! Expect more updates and useful new features in the coming months.
Thank you for being a part of the growing Thunderbird community and sharing this adventure with us. Your feedback and support motivate us to chase constant improvements and deliver the best email experience possible.
Thunderbird 128 Availability For Windows, Linux, and macOS
[Updated July 31] Even with QA and beta testing, any major software release may have issues exposed after significant public testing. That’s why we are slowly enabling automatic updates until we’re confident no such issues exist. As of July 29, we have enabled manual upgrade to 128 via Help > About, and some users will begin receiving automatic updates. Thunderbird version 128.0 is also offered as direct download from thunderbird.net. For users running Thunderbird from the snap or flatpak, 128 is also available.
This post has been automatically translated from English to other languages by DeepL. Please forgive any grammatical or spelling errors.
Is it July already? That means it’s time for another report on the progress of creating Thunderbird for Android.
Unfortunately, June has been one of these months without any flashy new features that would make for a nice screenshot to show off in a blog post. To not leave you hanging without any visuals, please enjoy this picture of Thunderbird team member Chris Aquino’s roommate Mister Betsy:
This year Thunderbird has hired a lot of new people. I’m very happy to report that this also included a manager who will coordinate all of our mobile efforts. Some of you may already know him. Philipp Kewisch has been working on the calendar integrated into Thunderbird for desktop and has been with the project in one capacity or another for a very long time. We’re very excited to have him (back).
Building two apps
In June we continued to work on making the necessary changes to be able to build two apps – K-9 Mail and Thunderbird for Android.
Volunteers working on translating the app have probably already noticed that we changed a lot of user-visible texts that included the app name. In cases where the app name wasn’t strictly necessary, we removed it. In other cases we added a placeholder, so the name of the app can be inserted dynamically.
We also worked on internal changes to make it easier to build multiple apps. However, there’s still quite a bit of work left. So don’t expect a fully working Thunderbird-branded version of the app to be available next week.
Material 3
We’re still in the middle of migrating the user interface to Material 3. So far there hasn’t been any fine-tuning. What you currently see in beta versions of K-9 Mail is likely to change in the future. So we’re not looking for feedback on the design just yet.
Targeting Android 14
In May the changes to target Android 14 were included in a beta release. After a few weeks of testing and not receiving any reports of problems, we included these changes in K-9 Mail 6.804, a maintenance release of the stable branch.
As a reminder, these changes are necessary so the app is not run in a compatibility mode on Android 14. It means the app supports the latest Android restrictions (e.g. when it comes to running in the background) and security features. Google Play enforces this by not allowing apps to publish updates without targeting Android 14 after the August 31 deadline.
More translations
Thanks to the work of volunteer translators we were able to add support for the following languages to beta releases:
I can’t believe it’s already the end of June. ESR is only a few days away, and things are moving faster than ever.
Preparing For ESR
This is going to be a slightly shorter update since the majority of our effort revolved around testing and polishing 128 beta, which will turn into ESR on July 10th.
We fixed a total of 127 bugs and a few more things are getting tackled.
Account Colors In Compose
You can now see the custom colors you chose for your accounts in the compose windows. This was an 18 year-old request that we were finally able to fulfill thanks to the incredible work that many core developers put in place during the past 2 years.
By implementing a much more reliable and modular code base, with a clearer separation between data and UI, we’re finally able to ship these long standing requested features much faster. There’s still a lot to do, but working on our code base is getting better and better.
Mozilla Sync
The client code is finished, everything is in place and we’re testing syncing server data against a temporary staging server.
We’re still working on spawning our own production server, which turned out more challenging than expected. This means that potentially we won’t enable Sync by default for the first ESR release and instead keep it hidden temporarily, with the objective of enabling it in a future point release (maybe 128.1 or 128.2) depending on when the production server will be ready.
We will keep you posted every step of the way.
Thunderbird Beta 128
If you haven’t downloaded 128 beta, please do so and help us test and report bugs if you spot them. You can download Thunderbird 128 Beta here, and if you find any issue, please open a bug report against this Meta Bug we’re using to track any potential regression specific to 128. Thank you!
See ya next month.
Alessandro Castellani(he, him) Director, Desktop and Mobile Apps
If you’re interested in joining the technical discussion around Thunderbird development, consider joining one or several of our mailing list groups here.
Imagine for a moment if we treated our laundry the same way we treat our email. It might look something like this: At least ten times an hour, we’d look in the dryer, sigh at the mix of wet and dry clothes, wonder where the shirt we needed was, and then close the dryer door again without emptying a thing. Laura Mae Martin, author of Uptime: A Practical Guide to Personal Productivity and Wellbeing, has a better approach. Treat your email like you would ideally treat your laundry.
How do we put this metaphor to work in our inboxes? Martin has some steps for getting the most out of this analogy, and the first is to set aside a specific time in your day to tackle your inbox. This is the email equivalent of emptying your dryer, not just looking in it, and sorting the clothes into baskets. You’re already setting future you up for a better day with this first step!
The Process
At this set time, you’ll have a first pass at everything in your inbox, or as much as you can, sorting your messages into one of four ‘baskets’ – Respond, To Read, Revisit, and Relax (aka, the archive where the email lives once you’ve acted on it from a basket, and the trash for deleted emails). Acting on those messages comes after the sorting is done. So instead of ‘touching’ your email a dozen times with your attention, you only touch it twice: sorting it, and acting on it.
Let’s discuss those first three baskets in a little more detail.
First, the ‘Respond’ basket is for emails that require a response from you, which need you and your time to complete. Next, the ‘To Read’ basket is for emails that you’d like to read for informative purposes, but don’t require a response. Finally, the ‘Revisit’ basket is for emails where you need to respond but can’t right now because you’re waiting for the appropriate time, a response from someone, etc.
Here’s more info on how treating your email like laundry looks in your inbox. You don’t have separate dryers for work clothes and personal clothes, so ideally you want your multiple inboxes in one place, like Thunderbird’s Unified Folders view. The baskets (Respond, To Read, Revisit) are labels, tags, or folders. Unread messages should not be in the same place with sorted email; that’s like putting in wet clothes with your nice, dry laundry!
Baskets and Batch Tasking
You might be wondering “why not just use this time to sort AND respond to messages?” The answer is that this kind of multitasking saps your focus, thanks to something called attention residue. Hopping between sorting and replying – and increasing the chance of falling down attention rabbit holes doing the latter – makes attention residue thicker, stickier, and ultimately harder to shake. Batch tasking, or putting related tasks together for longer stretches of time, keeps potentially distracting tasks like email in check. So, sorting is one batch, responding is another, etc. No matter how much you’re tempted, don’t mix the tasks!
Putting It Into Practice
You know why you should treat your email like laundry, and you know the process. Here’s some steps for day one and beyond to make this efficient approach a habit.
One-time Setup:
Put active emails in your inbox in one of the first three baskets (Respond, To Read, Revisit)
If email doesn’t need one of these baskets, archive or delete them
Daily Tasks
Remember the 4 Baskets are tasks to be done separately
Pick a time to sort your email each day – at least once, and hopefully no more than two or three more times. Remember, this is time ONLY to sort emails into your baskets.
Give future you the gift of a sorted inbox
Find and schedule time during the day to deal with the baskets – but only one basket at a time! Have slots just for responding, reading, or checking on the progress of your Revisit emails. Think of your energy flow during the day, and assign your most mentally strenuous boxes for your peak energy times.
One Last Fold
Thanks for joining us in our continuing journey to turn our inboxes, calendars, and tasks lists into inspiring productivity tools instead of burdens. We know opening our inboxes can sometimes feel overwhelming, which makes it easier for them to steal our focus and our time. But if you treat your email like laundry, this chore can help make your inbox manageable and put you in control of it, instead of the other way around.
We’re excited to try this method, and we hope you are too. We’re also eager to try this advice with our actual laundry. Watch out, inboxes and floor wardrobes. We’re coming for you!
In the last few months, I have been building up a new business called Trade Post 47. While we envision it as a little space station in orbit of a nice planet, to most people it will be a science fiction merchandise trading company, with an online shop and booths at events like local Comic-Cons in Central Europe, especially in Austria. If you want to learn more, we have put up a complete page about us on our shop website.
To manage our products, which we get from different vendors (sometimes the same product via different vendors) as well as plan and manage our orders, I built an internal, custom merchandise management in my own PHP framework or CMS CBSM (which is also used for this blog, for example). I did this mostly out of convenience as I have and maintain this system anyhow and I needed some database tables with fitting UI for managing our merchandise, vendors, and more (even conventions we may want to run booths at).
OTOH, the public shop is (as you may notice when looking at the website) an installation of Magento 2 (i.e. the open-source version of what is nowadays called "Adobe Commerce"). We decided to run that system because we are partnering closely with MCO Shop, which is a local ham radio and electronics shop, and they already had this software running previously on the servers we share and know how to work with it, run the upgrades, and maintain it. After all, when building a new business, as in so many areas of life, it always helps if you can share some resources and knowledge with others. First, I adapted the Magento theme to make it look more "space-like", mostly importantly, having a dark instead of light background. Once that worked well enough, I still had to get those products that we actually ordered from my custom management system into this Magento shop. Initially, I did this via creating a big CSV file and importing that into the shop, but it was clear that we needed a more fine-grained solution in the long run that can add and update entries individually.
Additionally, when we run booths on our "away missions" to events/conventions (or whenever we otherwise sell anything in person), Austrian law requires us to use a cash register system that follows strict rules and passes a certification so that the government can be sure we pay taxes for everything we sell. For that we decided to use a solution integrated into our bookkeeping system, which runs online as a web service as well, a specialized Austrian solution called FreeFinance. And of course, the cash register needs a full list of products and prices as well, which we also initially solved with a CSV creation and import in anticipation of a more fine-grained solution after our first big appearance at Austria Comic-Con in early June.
As icing on the cake, we also wanted to generate nicely styled invoice documents in FreeFinance for all online shop orders that weren't paid via the cash register, and in the future, we'll want to make the online shop automatically aware of merchandise sold at events so they are removed from available stock for online purchases.
To achieve that, I looked into the APIs that both Magento and FreeFinance provide, accessing them from the custom internal system that I have full access to and that is required for providing the merchandise data anyhow. I found that the FreeFinance API is relatively simple, well-documented and does authentication via OAuth2, which I already had some knowledge of (and code to access it) from other projects, including some code already in the CBSM system for facilitating its own logins. That said, Magento is a different beast: its product catalog feature set is way more complex, and so is its API. Also, there is no well-structured collective documentation that would explain what various things mean or what is preferably done in what way (often there are multiple paths to the same result), it's a lot of turning on developer mode so that a Swagger/OpenAPI UI is available on your installation and then trying around there and searching the web for what could work how and what value could mean what. In addition, authentication is done via OAuth1, which is more complicated than its successor, and which I didn't have any pre-existing code for, though I could build on some code from their tutorial. Also, as we're running Magento ourselves on the server side, I could more easily try around things than with FreeFinance, which is a hosted service and I needed to request access credentials from their team. But FreeFinance gave us access to a testing system, whereas for Magento, for various reasons, we only have a live system and no staging/testing environment, so we can't "play around" very much when testing.
I wrote quite a bit of code for all those cases, the simplest part was and is surely updating the cash register with our products, the only slight complication there is adding categories if needed. For adding products to the shop, I needed to respect all kinds of things, like creating and managing configurable products, adding values to some attributes, uploading images, managing categories, and more. And the curious structure of the Magento API, which requires way more detailed action than the CSV import route, did at times make this even more complicated - but it works now and I can just add or change a product in the merch management and at the latest on the next day, both the shop and the cash register have updated to those changes (I can trigger the sync jobs earlier if required). For creating the invoice documents, I could base some things on a make.com "blueprint" provided by FreeFinance, but for one thing, we don't want to use a paid third-party service if we can automate this ourselves, and for the other, we have some restrictions and specialties of our own there (like only generating invoices for orders actually paid via the web shop payment integration and not in person via the cash register). I did run into some curiosities there, like the Magento order API result containing several pieces of data multiple times, or us initially using a document layout template that didn't allow for different products having different VAT rates (which we require) - but that's working now as well. The reverse part about getting cash register purchases into the online shop is still on my plate, but I now have a good plan for how to do that, and some time until our next big "away mission" where this will be important to have.
All in all, this has been a quite interesting experience, and I'm sure now that I am comfortable with working with those systems and APIs, I will do more with them in the long run - and our Trade Post 47 hopefully will still grow as well and therefore have additional requirements in the future. If you are a developer and have questions about some details, feel free to contact me - and if you are running such systems yourself and need a developer who can adapt them in a similar fashion, I'm happy to offer those services as a contractor!
Searchfox (source, config source) is Mozilla’s primary code searching tool for Firefox introduced by Bill McCloskey in 2016 which built upon prior work on DXR. This roadmap post is the second of two posts attempting to lay out where my personal efforts to enhance searchfox are headed and the decision making framework that guides them. The first post was a more abstract product vision document and can be found here.
Discoverable, Extensible, Powerful Queries
Searchfox has a new “query” endpoint introduced in bug 1762817 which is intended to enable more powerful queries. Queries are parsed using :kats‘ query-parser crate which allows us to support our existing (secret) key:value syntax in a more rigorous way (and with automatic parse correction for the inevitable typos). In order to have a sane execution model, these key/value pairs are mapped through an extensible configuration file into a pipeline / graph execution model whose clap-based commands form the basis of our testing mechanism and can also be manually built and run from the command-line via searchfox-tool.
Above you will find a diagram rendering the execution pipeline of searching for foo manually created from the JSON insta crate check output for the query. Bug 1763005 will add automatically generated diagrams as well as further expanding on the existing capability to produce markdown explanations of what is happening in each stage of the pipeline and the values at each stage.
While a new query syntax isn’t exciting on its own, what is exciting is that this infrastructure makes it easier to add functionality with confidence (and tests!). Some particular details worth discussing:
Customizable, Shareable Queries
Bug 1799796: Do you really wish that you could issue a query like webidl:CacheStorage to search just our WebIDL files for “CacheStorage”? Does your team have terminology that’s specific to your team and it would be great to have special search terms/aliases but it would feel wrong to use up all the cool short prefixes for your team? The new query mechanism has plans for these situations!
The new searchfox query endpoint looks like /mozilla-central/query/default. You’ll note that default looks like something that implies there are non-default options. And indeed, the plan is to allow files like this example “preset” dom.toml file to layer additional “terms” and “aliases” onto the base query_core.toml file as well as any other presets you want to build off of. You will need to add your preset to the mozsearch-mozilla repository for the tree in question, but the upside is that any query links you share will work for other people as well!
Faceting in Search Results with Shareable URLs
Bug 1799802: The basic idea of faceted search/filtering is:
You start with a basic search query.
Your results come back, potentially quite a lot of them. Too many, even!
The faceting logic looks at the various attributes of the results and classifies or “facets” them. Does that sound too circular? We just throw things in bins. If a bin ends up having a lot of things in it and there’s some hierarchy to its contents, we recursively bin those contents.
The UI presents these facets (bins), giving you a high level overview of the shape of your results, and letting you limit your results to only include certain attribute values, or to exclude based on others.
The UI is able to react quickly because it already knows about the result set
The cool screenshot above is of a SIMILE Exhibit-based faceting UI I created for bugzilla a while back which may help provide a more immediate concept of how faceting works. See my exhibit blog tag for more in the space.
Here are some example facets that search can soon support:
Individual result paths: Categorize results by the path in which they happen. Do you not want to look at any results under devtools/? Push a button and filter out all those devtool results in an instant! Do you only care about layout/? Push a button and only see layout results!
Subsystem facets: moz.build files labels every file in mozilla-central so that it has an associated Bugzilla Component. As of Bug 1783761 searchfox now also derives a subsystem mapping from the bugzilla components, which really just means that if you have a component that looks like “Core :: Storage: IndexedDB”, searchfox transforms that first colon into a slash so we get “Core/Storage/IndexedDB”. This would let you restrict your results to “Core/Storage” without having to manually select every Storage bugzilla component or path by hand.
Symbol relationships: Did you search for a base class or virtual method which has a number of subclasses/overrides? Do you only care about some subset of the class hierarchy? Then restrict your results to whatever the portion of the set you care about.
Recency of changes: Do you only care about seeing results whose blame history indicates it happened recently? Can do! Or maybe you only want to see code that hasn’t been touched in a long time? Uh, that might work less well until we improve the blame situation in Bug 1517978, but it’s always nice to have something to dream about.
Code coverage: Only want to see results that runs a lot under our tests? Sure thing! Only want to see results that seem like we don’t have test coverage for? By looking at the result you’re now morally obligated to add test coverage!
Key to this enhancement is that the faceting state will be reflected in the URL (likely the hash) so that you can share it or navigate forward and back and the state will be the same. It’s all too common on the web for state like this to be local to the page, but key to my searchfox vision is that URLs are key. If you do a lot of faceting, the URL may become large an unwieldy, but continuing in the style of :arai‘s fantastic work on Bug 1769936 and follow-ups to make it easy to get usable markdown out of searchfox, we can help wrap your URL in markdown link syntax so that when you paste it somewhere markdown-aware, it looks nice.
Additional Query Constraints
A bunch of those facets mentioned above sound like things that it would be neat to query on, right? Maybe even put them in a preset that you can share with others? Yes, we would add explicit query constraints for those as well, as well as to provide a way to convert faceted query results into a specific query that does not need to be faceted in Bug 1799805.
A variety of other additional queries become possible as well:
Searching for lines of text that are near each other, or not near each other, or maybe both inside the same argument list.
Locating member fields by type (Bug 1733217), like if you wanted to find all member fields that are smart or raw pointer references to nsILoadInfo.
Result Context Lines For All Result Types, Including Automatic Context
<figcaption class="wp-element-caption">Current query results for C:4 AddOrPut</figcaption>
A major limitation for searchfox searches has been a lack of support for context lines. (Disclaimer: in Bug 1414954 I added secret support for fulltext-only queries by prefixing a search with context:4 or similar, but you would then want to force a fulltext query like context:4 text:my actual search or context:4 re:my.*regexp[y]?.*search.) The query mechanism already supports full context, as the above screenshot is taken from the query for C:4 AddOrPut but note that the UX needs more passes and the gathering mechanism currently needs optimization which I have a WIP for in Bug 1794177
The next steps in diagramming will happen in Bug 1773165 with a focus on making the graphs interactive and applying heuristics related to graph clustering based on work on the “fancy branch” prototype and my recent work to derive the sub-component mapping for files that can in turn be propagated to classes/methods so that we can automatically collapse edges that cross sub-component boundaries (but which can be interactively expanded). This has involved a bit of yak-shaving on Bug 1776522 and Bug 1783761 and others.
Note that we also support calls-to:'Identifier' in the query endpoint as well, but the graphs look a lot messier without the clustering heuristics, so I’m not including any in this post.
Most of my work on searchfox is motivated by my desire to use diagrams in system understanding, with much of the other work being necessary because to make useful diagrams, you need to have useful and deep models of the underlying data. I’ll try and write more about this in the future, but this is definitely a case where:
A picture is worth a thousand words and iterations on the diagrams are more useful than the relevant prose.
Providing screen-reader accessible versions of the underlying data is fundamental. I have not yet ported the tree-dual version of the diagram logic from the “fancy” branch and I think this is a precondition to an initial release that’s more than just a proof-of-sorta-works.
Documentation Integration
Our in-tree docs rendered at https://firefox-source-docs.mozilla.org/ are fantastic. Searchfox cannot replace human-authored documentation, but it can help you find them! Have you spent hours understanding code only to find that there was documentation that would help clarify what was going on only after the fact? Bug 1763532 will teach searchfox to index markdown so that documentation definitions and references show up in search and that we can potentially expose those in context menus. Subsequent steps could also index comment contents.
Bug 1458882 will teach searchfox how to link to the rendered documentation.
Improved Language Support
New Language Support via SCIP
With the advent of LSIF and SCIP and in particular the work by the team at sourcegraph to add language indexing built on existing analysis tools, there is now a tremendous amount of low hanging fruit in terms of off-the-shelf language indexing that searchfox can potentially ingest. Thanks to Emilio‘s initial work in Bug 1761287 we know that it’s reasonably straightforward to ingest SCIP data from these indexers.
For each additional language we want to index, we expect the primary effort required will be to make the indexer available in a taskcluster task and appropriately configure it to index the potentially many component roots within the mozilla-central mono-repo. There will also be some searchfox-specific effort required to map the symbols into searchfox’s symbol namespace.
Specific languages we can support (better):
Javascript / Typescript via scip-typescript (Bug 1740290): scip-typescript potentially allows us to expose the same enhanced understanding of JS code, especially module-based JS code, that you experience in VS code, including type inference/extraction from JSDoc. Additionally, in Bug 1775130 we can leverage the amazing eslint work already done to bring enhanced analysis to more confusing situations like our mochitests which deal with more complex global situations. Overall, this can allow us to move away from searchfox’s current “soupy” understanding of JS code where it assumes that all the JS it ever sees is running in a single global.
Searchfox’s strongest support is for C++ (and its interactions with XPIDL and IPDL), but there is still more to do here. Thankfully Botond is working to improve C++ template handling in Bug 1781178 and related bugs.
Other enhancements:
Bug 1419018: Allow distinguishing LHS/RHS usages of fields, with a prototype of relevance in Bug 1733217.
Improved Mozilla-Specific Language Support
mozilla-central contains a number of Mozilla-specific Interface Definition Languages (IDLs) and Domain Specific Languages (DSLs). Searchfox has existing support for:
XPIDL.idl files: Our C++ support here is pretty good because XPIDL files are not preprocessed (beyond in-language support of #include and the ability to put pass-through C++ code including preprocessor directives inside %{C++ and %}demarcated blocks. Bug 1761689 tracks adding support for constants/enums which is not currently supported, and I have WIPs for this. Bug 1800008 tracks adding awareness of the rust bindings.
IPDL.ipdl and .ipdlh files: Our C++ support here is good as long as the file is not pre-processed and the rust IPDL parser hasn’t fallen behind the Python parser. Unfortunately a lot of critical files like PContent.ipdl are pre-processed so this currently creates massive blind-spots in searchfox’s understanding of the system. Bug 1661067 will move us to having the Python parser/code generator emit data searchfox can ingest
Searchfox has planned support for:
WebIDL.webidl files: Bug 1416899 tracks indexing WebIDL files, and Bug 1525189 tracks the JS interaction side of this.
StaticPrefList.yaml and related preference bindings: Bug 1699048 with discussion in Bug 1727789 on which it certainly depends.
Searchfox’s language indexing is inherently a form of static analysis. Consistent with the searchfox vision saying that “searchfox is not the only tool”, it makes sense to attempt to integrate with and build upon the tools that Firefox engineers are already using. Mozilla’s code-coverage data is already integrated with searchfox, and the next logical step is to integrate with pernosco, why not. I created pernosco-bridge as an experimental means of extracting data from pernosco and allowing for interactive visualizations.
The screenshot above is an example of a timeline graph automatically extracted from a config file to show data relevant to IndexedDB. IndexedDB transactions were hierarchically related to their corresponding database and the origin that opened those databases. Within each transaction, ObjectStoreAddOrPutRequestOp and CommitOp operations are graphed. Clicking on the timeline would direct the pernosco tab to jump to those instants in time.
The above is a different visualization based on a config file for DocumentChannel to help group what’s going on in a pernosco trace and surface the relevant information. If you check out the config file, you will probably find it inscrutable, but with searchfox’s structured understanding of C++ classes landed last year in Bug 1641372 we can imagine leveraging searchfox’s understanding of the codebase to make this process friendly. More importantly, there is the potential to collaboratively build a shared knowledge base of what’s most relevant for classes, so everyone doesn’t need to re-do the same work.
Using the same information pernosco-bridge used to build the hierarchically organized timelines above with extracted values like URIs, it can also build graphs of the live objects at any moment in time in the trace. Above we can see the relationship between windowGlobalParent instances and their corresponding canonicalBrowsingContexts, plus the URIs of the canonicalBrowsingContexts. We can imagine using this to help visualize representative object graphs in searchfox.
We can also imagine doing something like the above screenshot from my prior experiment pecobro where we interleave graphs of function activity into source listings.
Token-Centric Blame / “hyperannotate” Support via Microannotate
<figcaption class="wp-element-caption">A demonstration of microannotate’s output</figcaption>
Quoting my dev-platform post about the unfortunate removal of searchfox’s first attempt at blame-skipping: “Revision history and the “annotate” / “blame” UIs for revision control are tricky because they’re built on a sequential, line-centric data-model where moving a function above another function in a file results in a destructive representational decision to treat one function as continuing through history and the other function as removed and then re-added as new code. Reformatting that maintains the overall sequence of tokens but changes how they are distributed across multiple lines also looks like removal of all of the old code and the addition of new code. Tools frequently perform heuristic-based post-passes to help identify intra-line changes which are reflected in diff UIs, as well as (entire) lines of code that are copied/moved in a revision (ex: Phabricator does this).”
The plan to move forward is to move to a token-centric approach using :marco‘s microannotate project as tracked in Bug 1517978. We would also likely want to combine this with heuristics that skip over backout pairs. The screenshot at the top of this section is of example output for nsWebBrowserPersist.cpp where colors distinguish between different blame revision origins. Note that the addition of specific arguments can be seen as well as changes to comments.
Source Listings
Bug 1781179: Improved syntax and semantic highlighting in C++ for the tip/head indexed revision.
Bug 1583635: Show expansion of C++ macros. Do you ever look at our XPCOM macrology and wish you weren’t about to spend several minutes clicking through those macros to understand what’s happening? This bug, my friend, this bug.
Bug 1796870: Adopt use of tree-sitter as a tokenizer which can improve syntax highlighting for other languages as well as position: sticky context for both the tip/head indexed revision but also for historical revisions!
Bug 1799557: Improved handling of links to source files that no longer exist by offering to show the last version of the file that existed or try and direct the user to the successor code.
Bug 1697671: Link resource:// and chrome:// URLs in source listings to the underlying source files
Test Info Boxes
Bug 1785129: Add an info box mechanism to indicate the need for data collection review (“data review”) in info boxes on searchfox source listing pages
Bug 1797855: Joel Maher and friends have been adding all kinds of great test metadata for searchfox to expose, and soon, this bug shall expose that information. Unfortunately there’s some yak shaving related to logging that remains underway.
Bug 1797857: Extend the “Go to header file”/”Go to source file” mechanism to support WPT `.headers` files and xpcshell/mochitest `^headers^` files.
Alternate Views of Data
Searchfox is able to provide more than source listings. The above screenshot shows searchfox’s understanding of the field layouts of C++ classes across all the platforms searchfox indexes on as rendered by the “fancy” branch prototype. Bug 1468445 tracks implementing a production quality version of this, noting that the data is already available, so this is straightforward. Bug 1799517 is a variation on this which would help us explicitly capture the destructor order of C++ fields.
Bug 1672307 tracks showing the binary size impact of a given file, class, etc.
Source Directory Listings
In the recently landed Bug 1783761 I moved our directory listings into rust after shaving a whole bunch of yaks. Now we can do a bunch of queries on data about files. Would you like to see all the tests that are disabled in your components? We could do this! Would you like to see all the files in your components that have been modified in the last month but have bad coverage? We could also do that! There are many possibilities here but I haven’t filed bugs for them.
Bug 1732585: Provide a way to search related (phabricator revision) review/bugzilla comments related to the current file
Bug 1657786: Create searchfox taskcluster mode/variant that can run the C++ indexer only against changed files for try builds / phabricator requests
Bug 1778802: Consider storing m-c analysis data in a git repo artifact with a bounded history via `git checkout –orphan` to enable try branch/code review features and recent semantic history support
Easier Contributions
The largest hurdle new contributors have faced is standing up a virtual machine. In Bug 1612525 we’ve added core support for docker, and we have additional work to do in that bug to document using docker and add additional support for using docker under WSL2 on Windows. Please feel free to drop by https://chat.mozilla.org/#/room/#searchfox:mozilla.org if you need help getting started.
Deeper Integration with Mozilla Infrastructure
Currently much of searchfox runs as EC2 jobs that exists outside of taskcluster, although C++ and rust indexing artifacts as well as all coverage data and test info data comes from taskcluster. Bug 1598502 tracks moving more of searchfox into taskcluster, although presumably the web-servers will still need to exist outside of taskcluster.
Searchfox (source, config source) is Mozilla’s primary code searching tool for Firefox introduced by Bill McCloskey in 2016 which built upon prior work on DXR. This product vision post describes my personal vision for searchfox and the rationale that underpins it. I’m also writing an accompanying road map that describes specific potential enhancements in support of this vision which I will publish soon and goes into the concrete potential features that would be implemented in the spirit of this vision.
Note that the process of developing searchfox is iterative and done in consultation with its users and other contributors, primarily in the searchfox channel on chat.mozilla.org and in its bugzilla component. Accordingly, these documents should be viewed as a basis for discussion rather than a strict project plan.
The Whys Of Searchfox
Searchfox is a Tool For System Understanding
Searchfox enables exploration and understanding of the Firefox codebase as it exists now, as it existed in the past, and to support understanding of the ramifications of potential changes.
Searchfox Is A Tool For Shared System Understanding
Firefox is a complex piece of software which has more going on than any one person can understand at a time. Searchfox enables Firefox’s contributors to leverage the documentation artifacts of other teams and contributors when exploring in isolation, and to communicate more effectively when interacting.
Searchfox Is Not The Only Tool
Searchfox integrates relevant data from automation and other tools in the Firefox development ecosystem where they make sense and provides deep links into those tools or first steps to help you get started without having to start from nothing.
The Hows Of Searchfox
Searchfox is Immediate: Low Latency and Complete
Searchfox’s results should be available in their entirety when the page load completes, ideally in much less than a second. There should be no asynchronous lazy loading or spinners. Practically speaking, if you could potentially see something on a page, you should be able to ctrl-f for it.
In situations where results are too voluminous to be practically useful, Searchfox should offer targeted follow-on searches that can relax limits and optionally provide for additional constraints so that iterative progress is made.
Searchfox is Accessible
Searchfox should always present a usable accessibility tree. This includes ensuring that any dynamically generated graphical representations such as graphviz-style diagrams have a directly usable accessibility tree or an alternate representation that maximally captures any hierarchy or clustering present in the visual presentation.
Searchfox Favors Iterative Exploration and Low Activation Energy
Searchfox seeks to avoid UX patterns where you have to metaphorically start from a blank sheet of paper or face decision paralysis choosing among a long list of options. Instead, start from whatever needle you have (an identifier name, a source file location, a string you saw in the UI) and searchfox will help you iterate and refine from there.
Searchfox Provides Stable, Useful URLs When Possible and Markdown For More Complex Situations
If you’re looking at something in searchfox, you should be able to share it as a URL, although there may be a few URLs to choose from such as whether to use a permalink which includes a specific revision identifier. More complicated situations may merit searchfox providing you with markdown that you can paste in tools that understand markdown.
After some behind-the-scenes discussions with Michael Kohler on what I could contribute at this year's FOSDEM, I ended up doing a presentation about my personal Suggestions for a Stronger Mozilla Community (video is available on the linked page). While figuring out the points I wanted to talk about and assembling my slides for that talk, I realized that one of the largest issues I'm seeing is that the Mozilla community nowadays feels very disconnected to me, like several islands, within each there is good stuff being done, but most people not knowing much about what's happening elsewhere. That has been helped a lot by a lot of interesting projects being split off Mozilla into separate projects in recent years (see e.g. Coqui, WebThings, and others) - which is often taking them off the radar of many people even though I still consider them as being part of this wider community around the Mozilla Manifesto and the Open Web.
Following the talk, I brought that topic to the Reps Weekly Call this last week (see linked video), esp. focusing on one slide from my FOSDEM talk that talks about finding some kind of communication channel to cross-connect the community. As Reps are already a somewhat cross-function community group, my hope is that a push from that direction can help getting such a channel in place - and figuring out what exactly is a good idea and doable with the resources we have available (I for example like the idea of a podcast as I like how those can be listened to while traveling, cooking, doing house work, and others things - but it would be a ton of work to organize and produce that).
Some ideas that came up in the Reps Call were for example a regular newsletter on Mozilla Discourse in the style of the MoCo-internal "tl;dr" (which Reps have access to via NDA), but as something that is public, as well as from and for the community - or maybe morphing some Reps Calls regularly into some sort of "Community News" calls that would highlight activities around the wider community, even bringing in people from those various projects/efforts there. But there may be more, maybe even better ideas out there.
To get this effort to the next level, we agreed that we'll first get the discussion rolling on a Discourse thread that I started after the meeting and then probably do a brainstorming video call. Then we'll take all that input and actually start experimenting with the formats that sound good and are practically achievable, to find what works for us the best way.
If you have ideas or other input on this, please join the conversation on Discourse - and also let us know if you can help in some form!
tl;dr: Happy 23rd birthday, Mozilla. And for the question: yes.
Here's a bit more rambling on this topic...
First of all, the Mozilla project was officially started on March 31, 1998, which is 23 years ago today. Happy birthday to my favorite "dino" out there! For more background, take a look at my Mozilla History talk from this year's FOSDEM, and/or watch the "Code Rush" documentary that conserved that moment in time so well and also gives nice insight into late-90's Silicon Valley culture.
Now, while Mozilla initially was there to "act as the virtual meeting place for the Mozilla code" as Netscape was still there with the target to win back the browser market that was slipping over to Micosoft. The revolutionary stance to develop a large consumer application in the open along with the marketing of "hack - this technology could fall into the right hands" as well as the general novenly of the open-source movement back then - and last not least a very friendly community (as I could find out myself) made this young project grow fast to be more than a development vehicle for AOL/Netscape, though. And in 2003, a mission to "preserve choice and innovation on the Internet" was set up for the project, shortly after backed by a non-profit Mozilla Foundation, and then with an independently developed Firefox browser, implementing "the idea [...] to design the best web browser for most people" - and starting to take back the web from the stagnation and lack of choice represented by >95% of the landscape being dominated by Microsoft Internet Explorer.
The exact phrasing of Mozilla's mission has been massages a few times, but from the view of the core contributors, it always meant the same thing, it currently reads:
Quote:
Our mission is to ensure the Internet is a global public resource, open and accessible to all. An Internet that truly puts people first, where individuals can shape their own experience and are empowered, safe and independent.
On the Foundation site, there's the sentence "It is Mozilla’s duty to ensure the internet remains a force for good." - also pretty much meaning the same thing with that, just in less specific terms. Of course, the spirit of the project was also put into 10 pretty concrete technical principles, prefaced by 4 social pledges, in the Mozilla Manifesto, which make it even more clear and concrete what the project sees as its core purpose.
So, if we think about the question whether we still need Mozilla nowadays, we should take a look if moving in that direction is still required and helpful, and if Mozilla is still able and willing to push those principles forward.
When quite a few communities I'm part of - or would like to be part of - are moving to Discord or are adding it as an additional option to Facebook groups, and I read the Terms of Services of those two tightly closed and privacy-unfriendly services, I have to conclude that the current Internet is not open, not putting people first, and I don't feel neither empowered, safe or independent in that space. When YouTube selects recommendations so I live in a weird bubble that pulls me into conspiracies and negativity pretty fast, I don't feel like individuals can shape their own experience. When watching videos stored on certain sites is cheaper or less throttled than other sources with any new data plan I can get for my phone, or when geoblocking hinders me from watching even a trailer of my favorite series, I don't feel like the Internet is equally accessible to all. Neither do I when political misinformation is targeted at certain groups of users in election ads on social networks without any transparency to the public. But I would long for that all to be different, and to follow the principles I talked of above. So, I'd say those are still required, and would be helpful to push for.
I definitely think we badly need a Mozilla that works on all those issues, and we need a whole lot of other projects and people help in the space as well. Be it in advocacy, in communication, in technology (links are just examples), or in other topics.
Can all that actually succeed in improving the Internet? Well, it definitely needs all of us to help, starting with using products like Firefox, supporting organizations like Mozilla, spreading the word, maybe helping to build a community, or even to contribute where we can.
We definitely need Mozilla today, even 23 years after its inception. Maybe we need it more than ever, actually. Are you in?
As mentioned in a previous post, I've been working with the Capacity Blockchain Solutions team on the Crypto stamp project, the first physical postage stamp with a unique digital twin, issued by the Austrian Postal Service (Österreichische Post AG). After a successful release of Crypto stamp 1, one of our core ideas for a second edition was to represent stamp albums (or stamp collections) in the digital world as well - and not just the stamps themselves.
We set off to find existing standards on Ethereum contracts for grouping NFTs (ERC-721 and potentially ERC-1155 tokens) together and we found that there are a few possibilities (like EIP-998) but those ares getting complicated very fast. We wanted a collection (a stamp album) to actually be the owner of those NFTs or "assets" but at the same time being owned by an Ethereum account and able to be transferred (or traded) as an NFT by itself. So, for the former (being the owner of assets), it needs to be an Ethereum account (in this case, a contract) and for the latter (being owned and traded) be a single ERC-721 NFT as well. The Ethereum account should not be shared with other collections so ownership of an asset is as transparent as people and (distributed) apps expect. Also, we wanted to be able to give names to collections (via ENS) so it would be easier to work with them for normal users - and that also requires every collection to have a distinct Ethereum account address (which the before-mentioned EIP-998 is unable to do, for example). That said, to be NFTs themselves, the collections need to be "indexed" by what we could call a "registry of Collections".
To achieve all that, we came up with a system that we think could be a model for future similar project as well and would ideally form the basis of a future standard itself.
At its core, a common "Collections" ERC-721 contract acts as the "registry" for all Crypto stamp collections, every individual collection is represented as an NFT in this "registry". Additionally, every time a new NFT for a collection is created, this core contract acts a "factory" and creates a new separate contract for the collection itself, connecting this new "Collection" contract with the newly created NFT. On that new contract, we set the requested ENS name for easier addressing of the Collection.
Now this Collection contract is the account that receives ERC-721 and ERC-1155 assets, and becomes their owner. It also does some bookkeeping so it can actually be queried for assets and has functionality so the owner of the Collection's own NFT (the actual owner of the Collection itself) and full control over those assets, including functions to safely transfer those away again or even call functions on other contracts in the name of the Collection (similar to what you would see on e.g. multisig wallets).
As the owner of the Collection's NFT in the "registry" contract ("Collections") is the one that has power over all functionality of this Collection contract (and therefore the assets it owns), just transferring ownership of that NFT via a normal ERC-721 transfer can give a different person control, and therefore a single trade can move a whole collection of assets to a new owner, just like handing a full album of stamps physically to a different person.
To go into more details, you can look up the code of our Collections contract on Etherscan. You'll find that it exposes an ERC-721 name of "Crypto stamp Collections" with a symbol of "CSC" for the NFTs. The collections are registered as NFTs in this contract, so there's also an Etherscan Token Tracker for it, and as of writing this post, over 1600 collections are listed there. The contract lets anyone create new collections, and optionally hand over a "notification contract" address and data for registering an ENS name. When doing that, a new Collection contract is deployed and an NFT minted - but the contract deployment is done with a twist: As deploying a lot of full contracts with a larger set of code is costly, an EIP-1167 minimal proxy contract is deployed instead, which is able to hold all the data for the specific collection while calling all its code via proxying to - in this case - our Collection Prototype contract. This makes creating a new Collection contract as cheap as possible in terms of gas cost while still giving the user a good amount of functionality. Thankfully, Etherscan for example has knowledge of those minimal proxy contracts and even can show you their "read/write contract" UI with the actually available functionality - and additionally they know ENS names as well, so you can go to e.g. etherscan.io/address/kairo.c.cryptostamp.eth and read the code and data of my own collection contract. For connecting that Collection contract with its own NFT, the Collections (CSC) contract could have a translation table between token IDs and contract addresses, but we even went a step further and just set the token ID to the integer value of the address itself - as an Ethereum address is a 40-byte hexadecimal value, this results in large integer numbers (like 675946817706768216998960957837194760936536071597 for mine) but as Ethereum uses 256-bit values by default anyhow, it works perfectly well and no translation table between IDs and addresses is needed. We still do have explicit functions on the main Collections (CSC) contract to get from token IDs to addresses and vice versa, though, even if in our case, it can be calculated directly in both ways.
Both the proxy contract pattern and the address-to-token-ID conversion scheme are optimizations we are using but if we were to standardize collections, those would not be in the core standard but instead to be recommended implementation practices instead.
Of course, users do not need to care about those details at all - they just go to crypto.post.at, click "Collections" and create their own collection for there (when logged in via MetaMask or a similar Ethereum browser module), and they also go the the website to look at its contents (e.g. crypto.post.at/collection/kairo). Ideally, they'll also be able to view and trade them on platforms like OpenSea - but the viewing needs specific support (which probably would need standardization to at least be in good progress), and the trading only works well if the platform can deal with NFTs that can change value while they are on auction or the trade market (and then any bids made before need to be invalidated or re-confirmed in some fashion). Because the latter needs a way to detect those value changes and OpenSea doesn't have that, they had to suspend trade for collections for now after someone exploited that missing support by transferring assets out of the collection while it was on auction. That said, there are ideas on how to get this back again the right way but it will need work on both the NFT creator side (us in the specific case of collections) and platforms that support trade, like OpenSea. Most importantly, the meta data of the NFT needs to contain some kind of "fingerprint" value that changes when any property changes that influences the value, and the trading platform needs to check for that and react properly to changes of that "fingerprint" so bids are only automatically processed as long as it doesn't change.
For showing contents or calculating such a "fingerprint", there needs to be a way to find out, which assets the collection actually owns. There are three ways to do that in theory: 1) Have a list of all assets you care about, and look up if the collection address is listed as their owner, 2) look at the complete event log on the blockchain since creation of the collection and filter all NFT Transfer events for ones going to the collection address or away from it, or 3) have some way of so the collection itself can record what assets it owns and allow enumeration of that. Option 1 is working well as long as your use case only covers a small amount of different NFT contracts, as e.g. the Crypto stamp website is doing right now. Option 2 gives general results and is actually pretty feasible with the functionality existing in the Ethereum tool set, but it requires a full node and is somewhat slow.
So, for allowing general usage with decent performance, we actually implemented everything needed for option 3 in the collections contract. Any "safe transfer" of ERC-721 or ERC-1155 tokens (e.g. via a call to the safeTransferFrom() function) - which is the normal way that those are transferred between owners - does actually test if the new owner is a simple account or a contract, and if it actually is a contract, it "asks" if that contract can receive tokens via a contract function call. The collection contract does use that function call to register any such transfer into the collection and puts such received assets into a list. As for transferring away an asset, you need to make a function call on the collection contract anyhow, removing from that list can be done there. So, this list can be made available for querying and will always be accurate - as long as "safe" transfers are used. Unfortunately, ERC-721 allows "unsafe" transfers via transferFrom() even though it warns that NFTs "MAY BE PERMANENTLY LOST" when that function is used. This was probably added into the standard mostly for compatibility with CryptoKitties, which predate this standard and only supported "unsafe" transfers. To deal with that, the collections contract has a function to "sync" ownership, which is given a contract address and token ID, and it adjusts it assets list accordingly by either adding or removing it from there. Note that there is a theoretical possibility to also lose an assets without being able to track it there, that's why both directions are supported there. (Note: OpenSea has used "unsafe" transfers in their "gift" functionality at least in the past, but that hopefully has been fixed by now.)
So, when using "safe" transfers or - when "unsafe" ones are used - "syncing" afterwards, we can query the collection for its owned assets and list those in a generic way, no matter which ERC-721 or ERC-1155 assets are sent to it. As usual, any additional data and meta data of those assets can then be retrieved via their NFT contracts and their meta data URLs.
I mentioned a "notification contract" before which can be specified at creation of a collection. When adding or removing an assets from the internal list in the collection, it also calls to that notification contract (if one is set) as a notification of this asset list change. Using that feature, it was possible to award achievements directly on the blockchain for e.g. collecting a certain number of NFTs of a specific type or one of each motif of Crypto stamps. Unfortunately, this additional contract call costs even more gas on Ethereum, as does tracking and awarding of achievements themselves, so rising gas costs forced us to remove that functionality and not set a notification contract for new collections as well as offer an "optimization" feature that would remove it from collections already created with one. This removal made transaction costs for using collections more bearable again for users, though I still believe that on-chain achievements were a great idea and probably a feature that was ahead of its time. We may come back to that idea when it can be done with an acceptably small impact on transaction cost.
One thing I also mentioned before is that the owner of a Collection can actually call functions in other contracts in the name of the Collection, similar to functionality that multisig wallets provide. This is done via an externalCall() function, to which the caller needs to hand over a contract address to call and an encoded payload (which can relatively easily be generated e.g. via the web3.js library). The result is that the Collection can e.g. call the function for Crypto stamps sold via the OnChain shop to have their physical versions sent to a postage address, which is a function that only the owner of a Crypto stamp can call - as the Collection is that owner and its own owner can call this "external" function, things like this can still be achieved.
To conclude, with Crypto stamp Collections we have created a simple but feature-rich solution to bring the experience of physical stamp albums to the digital world, and we see a good possibility to use the same concept generally for collecting NFTs and enabling a whole such collection of NFTs to be transferred or traded easily as one unit. And after all, NFT collectors would probably expect a collection of NFTs or a "stamp album" to have its own NFT, right? I hope we can push this concept to larger adoption in the future!
The FOSDEM conference in Brussels has become a bit of a ritual for me. Ever since 2002, there has only been a single year of the conference that I missed, and any time I was there, I did take part in the Mozilla devroom - most years also with a talk, as you can see on my slides page.
This year, things were a bit different as for obvious reasons the conference couldn't bring together thousands of developers in Brussels but almost a month ago, in its usual spot, the conference took place in a virtual setting instead. The team did an incredibly good job of hosting this huge conference in a setting completely run on Free and Open Source Software, backed by Matrix (as explained in a great talk by Matthew Hodgson) and Jitsi (see talk by Saúl Ibarra Corretgé).
On short notice, I also added my bit to the conference - this time not talking about all the shiny new software, but diving into the past with "Mozilla History: 20+ Years And Counting". After that long a time that the project exists, I figured many people may not realize its origins and especially early history, so I tried to bring that to the audience, together with important milestones and projects on the way up to today.
The video of the talk has been available for a short time now, and if you are interested yourself in Mozilla's history, then it's surely worth a watch. Of course, my slides are online as well.
If you want to watch more videos to dig deeper into Mozilla history, I heavily recommend the Code Rush documentary from when Netscape initially open-sourced Mozilla (also an awesome time capsule of late-90s Silicon Valley) and a talk on early Mozilla history from Mitchell Baker that she gave at an all-hands in 2012.
The Firefox part of the history is also where my song "Rock Me Firefox" (demo recording on YouTube) starts off, for anyone who wants some music to go along with all this!
We’re working on a thing to make Firefox start faster! It appears to work! Here’s a video showing off a before (left) and after (right):
Improving Firefox Startup Time With The about:home Startup Cache
For the past year or so, the Firefox Desktop Front-End Performance team has been concentrating on making improvements to browser startup performance.
The launching of an application like Firefox is quite complex. Meticulous profiling of Firefox startup in various conditions has, thankfully, helped reveal a number of opportunities where we can make improvements. We’ve been evaluating and addressing these opportunities, and several have made it into the past few Firefox releases.
This blog post is about one of those improvements that is currently in the later stages of development. I’m going to describe the improvement, and how we went about integrating it.
In a default installation of Firefox, the first (and only) tab that loads is about:home1.
The about:home page is actually the same thing that appears when you open a new tab (about:newtab). The fact that they have different addresses allows us to treat their loading differently.
Your about:home might look slightly different from the above — depending on your locale, it may or may not include the Pocket stories.
Do not be fooled by what appears to be a very simple page of images and text. This page is actually quite sophisticated under the hood. It is designed to be customized by the user in the following ways:
Users can
Collapse or expand sections
Remove sections entirely
Reorganize the order of their Top Sites by dragging and dropping
Pin and unpin Top Sites to their positions
Add their own custom Top Sites with custom thumbnails
Add or remove search engines from their Top Sites
Change the number of rows in the Top Sites and Recommended by Pocket sections
Choose to have the Highlights composed of any of the following:
Visited pages
Recent bookmarks
Recent downloads
Pages recently saved to Pocket
The user can customize these things at any time, and any open copies of the page are expected to reflect those customizations immediately.
There are further complexities beyond user customization. The page is also designed to be easy for our design and engineering teams to experiment with reorganizing the layout and composition of the page so that they can test variations on its layout in the wild.
The about:home page also has special privileges not afforded to normal websites. It can
Save and remove bookmarks
Add pages to Pocket
Cause the URL bar to be focused and selected
Show thumbnails for pages that the user has visited
Access both high and normal resolution favicons
Render information about the user’s recent activity (recent page visits, downloads, saves to Pocket, etc.)
So while at first glance, this appears to be a static page of just images and text, rest assured that the page can do much more.
Like the Firefox Developer Tools UI, about:home is written with the help of the React and Redux libraries. This has allowed the about:home development team to create sophisticated, reusable, and composable components that could be easily tested using modern JavaScript testing methods.
Unsurprisingly, this complexity and customizability comes at a cost. The page needs to request a state object from the parent process in order to have the Redux store populated and to have React render it. Essentially, the page is dynamically rendering itself after the markup of the page loads.
Startup is a critical time for an application. The user has expressed a need for their browser, and we have an obligation to serve the user as quickly and efficiently as possible. The user’s time is a resource that we should not squander. Similarly, because so much needs to occur during startup,2 disk reads, disk writes, and CPU time are also considered precious resources. They should only be used if there’s no other choice.
In this case, we believed that the CPU time and disk accesses spent constructing the state object and dynamically rendering the about:home page was competing with all of the other CPU and disk access happening during startup, and this was slowing us down from presenting about:home to the user in a timely way.
Generally speaking, in my mind there are four broad approaches to performance problems once a bottleneck has been identified.
You can widen the bottleneck (make the operations more efficient)
You can divide the bottleneck (split the work into smaller slices that can be done over a longer period of time with rests in between)
You can move the bottleneck (defer work until later when it seems that there is less competition for resources, or move it to a different thread)
You can remove the bottleneck (don’t do the work)
We started by trying to apply the last two approaches, wondering what startup performance would be like if the page did not render itself dynamically, but was instead a static page generated periodically and pulled off of the disk at startup.
Prototype when possible
The first step to improving something is finding a way to measure it. Thankfully, we already have a number of logged measurements for startup. One of those measurements gives us the time from process start to rendering the Top Sites section of about:home. This is not a perfect measurement—ideally, we’d measure to the point that the page finally “settles” and stops changing3—but for this project, this measurement served our purposes.
Before investing a bunch of time into a potential improvement, it’s usually a good idea to try to see if what you’re gaining is worth the development time. It’s not always possible to build a prototype for performance improvements, but in this case it was.
So, with that information, we thought we had a real improvement opportunity here. We decided to proceed with the idea, and began a long arduous search for “the right way to do it.”
Pre-production
As I mentioned earlier, about:home is complex. The infrastructure that powers it is complex. Coupled with the fact that no one on the Firefox Front-End Performance team had spent much time studying React and Redux meant that we had a lot of learning to do.
The first step was to get some React and Redux fundamentals under our belt. This meant building some small toy applications and getting familiar with the framework idioms and how things are organized.
With that grounding, the next step was to start reading the code — starting from the entrypoint into the code that powers about:home when the browser starts. This was an intense period of study that branched into many different directions. Part of the complexity was because much of the code is asynchronous and launched work on different threads, which introduced some non-determinism. While it is generally good for responsiveness to move work off of the main thread, it can lead to some complex reading and interpretation of the code when more than two threads are involved.
A tool we used during this analysis was the Firefox Profiler, to get a realistic sense of the order of executions during startup. These profiles helped to inform much of our reading of the code.
This analysis helped us solidify our mental model of how about:home loads. With that model in place, it was much easier to propose practical approaches for introducing a static about:home document into the ecosystem of pre-existing code. The Firefox Front-End Performance team documented our findings and recommendations and then presented them to the team that originally built the about:home system to ensure that we were all on the same page and that we hadn’t missed anything critical. They were already aware that we were investigating potential performance improvements, and had very useful feedback for us, as well as historical product decision context that clarified our understanding.
Critically, we presented our recommendation for loading a static about:home page at startup and ensured that there were no upcoming plans for about:home that would break our mental model or render the recommendation no longer valid. Thankfully, it sounded like we were aligned and fine to proceed with our plan.
So what was the plan? We knew that since about:home is quite dynamic and can change over time4 we needed a startup cache for about:home that could be periodically updated during the course of a browsing session. We would then load from that cache at startup. Clearly, I’m glossing over some details here, but that was the general plan.
As usual, no plan survives breakfast, and as we started to architect our solution, we identified things we would need to change along the way.
Development
We knew that the process that loads about:home would need to be able to read from the about:home startup cache. We also knew that about:home can potentially contain information about what pages the user has visited, and that about:home can do privileged things that normal web pages cannot. It seemed that this project would be a good opportunity to finish a project that was started (and mothballed) a year or so earlier: creating a special privileged content process for about:home. We would load about:home in that process, and add assertions to ensure that privileged actions from about:home could only happen from that content process type5
So getting the “privileged about content process”6 fixed up and ready for shipping was the first step.
This also paved the way for solving the next step, which was to enable the moz-page-thumb:// protocol for the “privileged about content process.” The moz-page-thumb:// protocol is used to show the screenshot thumbnails for pages that the user has visited in the past. The previous implementation was using Blob URLs to send those thumbnails down to the page, and those Blob URLs exist only during runtime and would not work properly after a restart.
The next step was figuring out how to build the document that would be stored in the cache. Thankfully, ReactDOMServer has the ability to render a React application to a string. This is normally used for server-side rendering of React-powered applications. This feature also allows the React library to passively attach to the server-side page without causing the DOM to be modified. With some small modifications, we were able to build a simple mechanism in a Web Worker to produce this cached document string off of the main thread. Keeping this work off of the main thread would help maintain responsiveness.
With those pieces of foundational work out of the way, it was time to figure out the cache storage mechanism. Firefox already has a startupcache module that it uses for static resources like markup and JavaScript, but that cache is not designed to be written to periodically at runtime. We would need something different.
We had originally supposed that we would need to give the privileged about content process special access to a file on the filesystem to read from and to write to (since our sandbox prevents content processes from accessing disks directly). Initial experiments along this line worried us — we didn’t like the idea of poking holes in the sandbox if we didn’t need to. Also, adding yet another read from the filesystem during startup seemed counter to our purposes.
We evaluated IndexedDB as a storage mechanism, but the DOM team talked us out of it. The performance characteristics of IndexedDB, especially during startup, were unlikely to work for us.
Finally, after some consulting, we were directed to the HTTP cache. The HTTP cache’s job is to cache pages that the user visits (when appropriate) and to offer those caches to the user instead of hitting the network when retrieving the resource within the expiration time7. Functionally speaking, this seemed like a storage mechanism perfectly suited to our purposes.
After consulting with the Necko team and building a few proof-of-concepts, we figured out how to tie the whole system together. Importantly, we figured out how to get the initial about:home load to pull a document out from the HTTP cache rather than reading it from the application resource package.
We also figured out the cache writing mechanism. The cached document that would periodically get built inside of the privileged about content process inside of a Worker off of the main thread, would then send that data back up to the parent to stream into the cache.
At this point, we felt we had all of the pieces that we needed. Construction on each component began.
One of the more gratifying parts of implementation was when we modified one of our startup tests to use the new caching mechanism.
In this graph, the Y axis is the geometric mean time to render the about:home Top Sites over 20 restarts of the browser, in milliseconds. Lower is better. The dots along the top are without the cache. The dots along the bottom are with the cache enabled. According to our measurements, we improved the rendering time from process start to Top Sites by just over 20%! We beat our prototype!
Noticeable differences
But the real proof will be if there’s actually a noticeable visual change. Here’s that screen recording again from one of our reference devices8.
The screen on the left is with the cache disabled, and on the right with the cache enabled. Looks to me like we made a noticeable dent!
Try it out!
We haven’t yet enabled the about:home startup cache in Nightly by default, but we hope to do so soon. In the meantime, Nightly users can try it out right now by going to about:preferences#experimental and toggling it on. If you find problems and have a Bugzilla account, here’s a form for submitting bugs to the right place.
You can tell if the about:home you’re looking at is from the cache by opening up the DevTools Inspector and looking for a <!-- Cached: <some date> --> comment just above the <body> tag.
Caveat emptor
There are a few cases where the cache isn’t used or is invalidated.
The first case is if you’ve configured something other than about:home as your home page (where the cache isn’t used). In this case, the cache won’t be read from, and the code to create the cache won’t ever run. If the user ever resets about:home to be their home page, then the caching code will start working for them.
The second case is if you’ve configured Firefox to restore your previous session by default. In this case, it’s unlikely that the first tab you’ll see is about:home, so the cache won’t be read from, and the code to create the cache won’t ever run. As before, if the user switches to not loading their previous session by default, then the cache will start working for them.
Another case is when the Firefox build identifier doesn’t match the build identifier from when the cache was created. This is also how the other startupcache module for static resources works. This ensures that when an update is applied, we don’t accidentally load old assets from the cache. So the first time you launch Firefox after you apply an update will not pull the about:home document from the cache, even if one exists (and will throw the cache out if it does). For Nightly users that generally receive updated builds twice a day, this makes the cache somewhat useless. Beta and Release users update much less frequently, so we expect to see a greater impact there.
The last case is in the event that your disk was in a situation such that reading the dynamic code from the asset bundle was faster than reading from the cache. If by the time the about:home document attempts to load and the cache isn’t ready, we fall back to loading it the old way. We don’t expect this to happen too often, but it’s theoretically possible, so we handle the case.
Future work
The next major step is to get the about:home startup cache turned on by default on Nightly and get it tested by a broader audience. At that point, hopefully we’ll get a better sense of its behaviour out in the wild via bug reports and Telemetry. Then our improvement will either ride the release train, or we might turn it on for subsets of the Beta or Release populations to measure its impact on more realistic restart scenarios. Once we’re confident that it’s helping more than hindering, we’ll turn it on by default for everyone.
After that, I think it would be worth seeing if we can load from the cache more often. Perhaps we could load about:newtab from there as well, for example.
One step at a time!
Thanks to
Florian Quèze and Doug Thayer, both of whom independently approached me with the idea of creating a static about:home
Jay Lim and Ursula Sarracini, both of whom wrote some of the groundwork code that was needed for this feature (namely, the infrastructure for the privileged about content process, and the first version of the moz-page-thumbs support)
Gijs Kruitbosch, Kate Hudson, Ed Lee, Scott Downe, and Gavin Suntop for all of the consulting and reviews
Honza Bambas and Andrew Sutherland for storage consultations
Markus Stange, Andrew Creskey, Eric Smyth, Asif Youssuff, Dan Mosedale, Emily Derr for their generous feedback on this post
This is only true if the user hasn’t just restarted after applying an update, and if they haven’t set a custom home page or configured Firefox to restore their previous session on start. ↩
You can think of startup like a traveling circus coming to town. You have to get the trucks and trailers parked, get the tents set up, hook up power, then lighting and sound … it’s a big, complex operation, and we haven’t even shot a clown out of a cannon yet. ↩
As the user browses, bookmarks and downloads things, their Highlights and Top Sites sections might change. If Pocket is enabled, new stories will also be downloaded periodically. ↩
It’s vitally important that content processes have limited abilities. That way, if they’re ever compromised by a bad actor, there are limits to what damage they can do. The assertions mentioned in this case mean that if a compromised content process tries to “pretend” to be the privileged about content process by sending one of its messages, that the parent process will terminate that content process immediately. ↩
This has changed slightly in the past few years with a feature called Race Cache With Network, which races the disk cache with the network instead of relying on the disk entirely. ↩
Thunderbird Conversations is an add-on for Thunderbird that provides a conversation view for messages. It groups message threads together, including those stored in different folders, and allows easier reading and control for a more efficient workflow.
Over the last couple of years, Conversations has been largely rewritten to adapt to changes in Thunderbird’s architecture for add-ons. Conversations 3.1 is the result of that effort so far.
<figcaption>Message Controls Menu</figcaption>
The new version will work with Thunderbird 68, and Thunderbird 78 that will be released soon.
<figcaption>Attachment preview area with gallery view available for images.</figcaption>
The one feature that is currently missing after the rewrite is inline quick reply. This has been of lower priority, as we have focussed on being able to keep the main part of the add-on running with the newer versions of Thunderbird. However, now that 3.1 is stable, I hope to be able to start work on a new version of quick reply soon.
More rewriting will also be continuing for the foreseeable future to further support Thunderbird’s new architecture. I’m planning a more technical blog post about this in future.
If you find an issue, or would like to help contribute to Conversations’ code, please head over to our GitHub repository.
Last year, I worked with the Capacity team on the Crypto stamp project, the first physical postage stamp with a unique digital twin, issued by the Austrian Postal Service (Österreichische Post AG). Those stamps are mainly intended as collectibles, but their physical "half" can be used as valid postage on packages or letters, and a QR code on that physical stamp links to a website presenting the digital collectible. Our job (at Capacity Blockchain Solutions) was to build that digital collectible, the website at crypto.post.at, and the back-end service delivering both public meta data and the back end for the website. I specifically did most of the work on the EthereumSmart Contract for the digital collectible, a "non-fungible token" (NFT) using the ERC-721 standard (publicly visible), as well as the back-end REST service, which I implemented in Python (based on Flask and Web3.py). The coding for the website was done by colleagues, of course using JavaScript for the dynamic elements.
One feature we have in this project is that people can purchase Crypto stamps directly from the blockchain, with the website guiding those with an Ethreum-enabled browser (e.g. with the MetaMask add-on) through that. By sending Ether cryptocurrency to the right address (the OnChainShop contract), they will directly receive the digital NFT - but then, every Crypto stamp consists of both a digital and physical item, so what about the physical part?
Of course, we cannot send a physical item to an Ethereum address (which is just a mostly-random number) so we needed a way for the owner of the NFT to give us (or actually Post AG) a postal address to send the physical stamp to. For this, we added a form to allow them to enter the postal address for stamps that were bought via the OnChain shop - but then the issue arose of how would we would verify that the sender was the actual owner of the NFT. Additionally, we had to figure out how do we do this without requiring a separate database or authentication in the back end, as we also did not need those features for anything else, since authentication for purchases are already done via signed transactions on the blockchain, and any data that needs to be stored is either static or on the blockchain.
We can easily verify the ownership if we send the information to a Smart Contract function on the blockchain, given that the owner has proven to be able to do such calls by purchasing via the OnChain shop already, and anyone sending transactions there has to sign those. To not need to store the whole postage address in the blockchain state database, which is expensive, we just emit an event and therefore put it in the event log, which is much cheaper and can still be read by our back end service and forwarded to Post AG. But then, anything sent to the public Ethereum blockchain (no matter if we put it into state or logs afterwards) is also visible to everyone else, and postal address are private data, so we need to ensure others reading the message cannot actually read that data.
So, our basic idea sounded simple: We generate a public/private key pair, use the public key to encrypt the postage address on the website, call a Smart Contract function with that data, signed by the user, emit an event with the data, and decrypt the information on the back-end service when receiving the event, before forwarding it to the actual shipping department in a nice format. As someone who has heard a lot about encryption but not actually coded encryption usage, I was surprised how many issues we ran into when actually writing the code.
So, first thing I did was seeing what techniques there are for sending encrypted messages, and pretty soon I found ECIES and was enthusiastic that sending encrypted messages was standardized, there are libraries for this in many languages and we just need to use implementations of that standard on both sides and it's all solved! Yay!
So I looked for ECIES libraries, both for JavaScript to be used in the browser and for Python, making sure they are still maintained. After some looking, I settled for eccrypto (JS) and eciespy, which both sounded pretty decent in usage and being kept up to date. I created a private/public key pair, trying to encrypt back and forth via eccrypto worked, so I went for trying to decrypt via eciespy, with great hope - only to see that eccrypto.encrypt() results in an object with 4 member strings while eciespy expects a string as input. Hmm.
With some digging, I found out that ECIES is not the same as ECIES. Sigh. It's a standard in terms of providing a standard framework for encrypting messages but there are multiple variants for the steps in the standardized mechanism, and both sides (encryption and decryption) need to agree on using the same to make it work correctly. Now, both eccrypto and eciespy implement exactly one variant, and of course two different ones, of course. Things would have been too easy if the implementations would be compatible, right?
So, I had to unpack what ECIES does to understand better what happens there. For one thing, ECIES basically does an ECDH exchange with the receiver's public key and a random "ephemeral" private key to derive a shared secret, which is then used as the key for AES-encrypting the message. The message is sent over to the recipient along with the AES parameters (IV, MAC) and the "ephemeral" public key. The recipient can use that public key along with their private key in ECDH, get the same shared secret, and do another round of AES with the given parameters to decrypt (as AES is symmetric, i.e. encryption and decryption are the same operation).
While both libraries use the secp256k1 curve (which incidentally is also used by Ethereum and Bitcoin) for ECDH, and both use AES-256, the main difference there, as I figured, is the AES cipher block mode - eccrypto uses CBC while eciespy uses GCM. Both modes are fine for what we are doing here, but we need to make sure we use the same on both sides. And additional difference is that eccrypto gives us the IV, MAC, ciphertext, and ephemeral public key as separate values while eciespy expects them packed into a single string - but that would be easier to cope with.
In any case, I would need to change one of the two sides and not use the simple-to-use libraries. Given that I was writing the Python code while my collegues working on the website were already busy enough with other feature work needed there, I decided that the JavaScript-side code would stay with eccrypto and I'd figure out the decoding part on the Python side, taking apart and adapting the steps that ecies would have done.
We'd convert the 4 values returned from eccrypto.encrypt() to hex strings, stick them into a JSON and stringify that to hand it over to the blockchain function - using code very similar to this:
var data = JSON.stringify(addressfields);
var eccrypto = require("eccrypto");
eccrypto.encrypt(pubkey, Buffer(data))
.then((encrypted) => {
var sendData = {
iv: encrypted.iv.toString("hex"),
ephemPublicKey: encrypted.ephemPublicKey.toString("hex"),
ciphertext: encrypted.ciphertext.toString("hex"),
mac: encrypted.mac.toString("hex"),
};
var finalString = JSON.stringify(sendData);
// Call the token shipping function with that final string.
OnChainShopContract.methods.shipToMe(finalString, tokenId)
.send({from: web3.eth.defaultAccount}).then(...)...
};
So, on the Python side, I went and took the ECDH bits from eciespy, and by looking at eccrypto code as an example and the relevant Python libraries, implemented code to make AES-CBC work with the data we get from our blockchain event listener. And then I found out that it still did not work, as I got garbage out instead of the expected result. Ouch. Adding more debug messages, I realized that the key used for AES was already wrong, so ECDH resulted in the wrong shared secret. Now I was really confused: Same elliptic curve, right public and private keys used, but the much-proven ECDH algorithm gives me a wrong result? How can that be? I was fully of disbelief and despair, wondering if this could be solved at all.
But I went for web searches trying to find out why in the world ECDH could give different results on different libraries that all use the secp256k1 curve. And I found documents ofthat same issue. And it comes down to this: While standard ECDH returns the x coordinate of the resulting point, the libsecp256k1 developers (I believe that's a part of the Bitcoin community) found it would be more secure to instead return the SHA256 hash of both coordinates of that point. This may be a good idea when everyone uses the same library, but eccrypto uses a standard library while eciespy uses libsecp256k1 - and so they disagree on the shared secret, which is pretty unhelpful in our case.
In the end, I also replaced the ECDH pieces from eciespy with equivalent code using a standard library - and suddenly things worked! \o/
I was fully of joy, and we had code we could use for Crypto stamp - and since the release in June 2019, this mechanism has been used successfully for over a hundred shipments of stamps to postal addresses (note that we had a limited amount available in the OnChainShop).
So, here's the Python code used for decrypting (we pip install eciespy cryptography in our virtualenv - not sure if eciespy is still needed but it may for dependencies we end up using):
from Crypto.Cipher import AES
import hashlib
import hmac
from cryptography.hazmat.primitives.asymmetric import ec
from cryptography.hazmat.backends import default_backend
def ecies_decrypt(privkey, message_parts):
# Do ECDH via the cryptography module to get the non-libsecp256k1 version.
sender_public_key_obj = ec.EllipticCurvePublicNumbers.from_encoded_point(ec.SECP256K1(), message_parts["ephemPublicKey"]).public_key(default_backend())
private_key_obj = ec.derive_private_key(Web3.toInt(hexstr=privkey),ec.SECP256K1(), default_backend())
aes_shared_key = private_key_obj.exchange(ec.ECDH(), sender_public_key_obj)
# Now let's do AES-CBC with this, including the hmac matching (modeled after eccrypto code).
aes_keyhash = hashlib.sha512(aes_shared_key).digest()
hmac_key = aes_keyhash[32:]
test_hmac = hmac.new(hmac_key, message_parts["iv"] + message_parts["ephemPublicKey"] + message_parts["ciphertext"], hashlib.sha256).digest()
if test_hmac != message_parts["mac"]:
logger.error("Mac doesn't match: %s vs. %s", test_hmac, message_parts["mac"])
return False
aes_key = aes_keyhash[:32]
# Actual decrypt is modeled after ecies.utils.aes_decrypt() - but with CBC mode to match eccrypto.
aes_cipher = AES.new(aes_key, AES.MODE_CBC, iv=message_parts["iv"])
try:
decrypted_bytes = aes_cipher.decrypt(message_parts["ciphertext"])
# Padding characters (unprintable) may be at the end to fit AES block size, so strip them.
unprintable_chars = bytes(''.join(map(chr, range(0,32))).join(map(chr, range(127,160))), 'utf-8')
decrypted_string = decrypted_bytes.rstrip(unprintable_chars).decode("utf-8")
return decrypted_string
except:
logger.error("Could not decode ciphertext: %s", sys.exc_info()[0])
return False
So, this mechanism has caused me quite a bit of work and you probably don't want to know the word I shouted at my computer at times while trying to figure this all out, but the results works great, and if you are ever in need of something like this, I hope I could shed some light on how to achieve it!
For further illustration, here's a flow graph of how the data gets from the user to Post AG in the end - the ECIES code samples are highlighted with light blue, all encryption-related things are blue in general, red is unencrypted data, while green is encrypted data:
Thanks to Post AG and Capacity for letting me work on interesting projects like that - and keep checking crypto.post.at for news about the next iteration of Crypto stamp!
Ever since I was on a tour to Star Trek filming sites in 2016 with Geek Nation Tours and Larry Nemecek, I've become ever more interested in finding out to which actual real-world places TV/film crews have gone "on location" and shot scenes for our favorite on-screen stories. While the background of production of TV and film is of interest to me in general, I focus mostly on everything Star Trek and I love visiting locations they used and try to catch pictures that recreate the base setting of the shots in the production - but just the way the place looks "in the real world" and right now.
This has gone as far as me doing several presentations about the topic - two of which (one in German, one in English language) I will give at this year's FedCon as well, and creating an experimental website at filmingsites.com where I note all locations used in Star Trek productions as soon as I become aware of them.
In the last few years, around the Star Trek Las Vegas Conventions, I did get the chance to have a few days traveling around Los Angeles and vicinity, visit a few locations and take pictures there. And after Discovery being filmed up in the Toronto area (and generally using quite few locations outside the studios), Picard is back producing in Southern California and using plenty of interesting places! And now with the first half of season 1 in the books (or at least ready to watch for us via streaming), here are a few filming sites I found in those episodes:
And we actually get started with our first location (picture is a still from the series) in "Remembrance" right after Picard wakes up from the "cold open" dream sequence: Château Picard was filmed at Sunstone Winery's Villa this time (after different places were used in its TNG appearances). The Winery's general manager even said "We encourage all the Trekkies and Trekkers to come visit us." - so I guess I'll need to put it in my travels plans soon.
Another one I haven't seen yet but will need to put in my plans to see is One Culver, previously known as Sony Pictures Plaza. That's where the scenes in the Daystrom Institute were shot - interestingly, in walking distance to the location of the former Desilu Culver soundstages (now "The Culver Studios") and its backlot (now a residential area), where the original Star Trek series shot its first episodes and several outdoor scenes of later ones as well. One Culver's big glass front structure and the huge screen on its inside are clearly visible multiple times in Picard's Daystrom Institute scenes, as is the rainbow arch behind it on the Sony Studios parking lot. Not having been there, I could only include a promotional picture from their website here.
Now a third filming site that appears in "Remembrance" is actually one I do have my own pictures of: After seeing the first trailer for Picard and getting a hint where that building depicted that clip is, I made my way last summer to a place close to Disneyland and took a few pictures of Anaheim Convention Center. Walking by to the main entrance, I found the attached Arena to just look good, so I also got one shot of that one in - and then I see that in this episode, they used it as the Starfleet Archive Museum!
Of course, in the second episode, "Maps and Legends", we then see the main entrance, where Picard goes to meet the C-in-C, so presumably Starfleet headquarters. It looks like the roof scenes with Dahj would actually be on the same building, on satellite pictures, there seems to be an area with those stairs South of the main entrance. I'm still a bit sad though that Starfleet seems to have moved their headquarters and it's not the Tillman administration building any more that was used in previous series (actually, for both headquarters and the Academy - so maybe it comes back in some series as the Academy, with its beautiful Japanese garden).
Of course, at the end of this episode we get to Raffi's home, and we stay there for a bit and see more of it in "The End is the Beginning". The description in the episode tells us it's located at a place called "Vasquez Rocks" - and this time, that's actually the real filming site! Now, Trekkies know this of course, as a whole lot of Trek has been filmed there - most famously the fight between Kirk and the Gorn captain in "Arena". Vasquez Rocks has surely been of the most-used Star Trek filming sites over the years, though - at least before Picard - I'd say that it ranked second behind Bronson Canyon. How what's nowadays a Natural Area park becomes a place to live in by 2399 is up to anyone's speculation.
I guess in the 3 introductory episodes we had more different filming sites than in any of the two whole seasons of Discovery seen so far, but right in the next episode, Absolute Candor, we got yet another interesting place! A lot of that episode plays on the planet Vashti, with three sets of scenes on their main place with the bar setting: In the "cold open" / flashback, when Picard beams down to the planet again in the show's present, and before he leaves, including the fight scene. Given that there were multiple hints of shooting taking place at Universal Studios Hollywood, and the sets having a somewhat familiar look, more Mexican than totally alien, it did not take long to identify where those scenes were filmed: It's the standing "Mexican Street" / "Old Mexico Place" set on Universal's backlot - which you usually can visit with the Studio Tour as an attraction of their Theme Park. The pictures, of the bar area, and basically from there in the direction of Picard's beam-in point, are from a one of those tours I took in 2013.
In the following two episodes, I could not make out any filming sites, so I guess they pretty much filmed those at Santa Clarita Studios where the production of the series is based. I know we will have some location(s) to talk about in the second half of the season though - not sure if there's as many as in the first few episodes, but I hope we'll have a few good ones!
I've been meaning to blog again for some time, and just looked in disbelief at the date of my last post. Yes, I'm still around. I hope I get to write more often in the future.
Ludo just posted his thoughts on FOSDEM, which I also attended last weekend as a volunteer for Mozilla. I have been attending this conference since 2002, when it first went by that exact name, and since then AFAIK only missed the 2010 edition, giving talks in the Mozilla dev room almost every year - though funnily enough, in two of the three years where I've been a member of the Mozilla Tech Speakers program, my talks were not accepted into that room, while I made it all the years before. In fact, that's more telling a story of how interested speakers are in getting into this room nowadays, while in the past there were probably fewer submissions in total. So, this year I helped out Sunday's Mozilla developer room by managing the crowd entering/leaving at the door(s), similar to what I did in the last few years, and given that we had fewer volunteers this year, I also helped out at the Mozilla booth on Saturday. Unfortunately, being busy volunteering on both days meant that I did not catch any talks at all at the conference (I hear there were some good ones esp. in our dev room), but I had a number of good hallway and booth conversations with various people, esp. within the Mozilla community - be it with friends I had not seen for a while, new interesting people within and outside of Mozilla, or conversations clearing up lingering questions.
(pictures by Rabimba & Bob Chao)
Now, this was the 20th conference by the FOSDEM team (their first one went by "OSDEM", before they added the "F" in 2002), and the number 20 is coming up for me all over the place - not just that it works double duty in the current year's number 2020, but even in the months before, I started my row of 20-year anniversaries in terms of my Mozilla contributions: first bug reported in May, first contribution contact in December, first German-language Mozilla suite release on January 1, and will will continue with the 20th anniversaries of my first patches to shared code this summer - see 'My Web Story' post from 2013 for more details. So, being part of an Open-Source project with more than 20 years of history, celebrating a number of 20th anniversaries in that community, I see that number popping up quite a bit nowadays. Around the turn of the century/millennium, a lot of change happened, for me personally but all around as well. Since then, it has been a whirlwind, and change is the one constant that really stayed with me and has become almost a good friend. A lot of changes are going on in the Mozilla community right now as well, and after a bit of a slump and trying to find my new place in this community (since I switched back from staff to volunteer in 2016), I'm definitely excited again to try and help building this next chapter of the future with my fellow Mozillians.
There's so much more going around in my mind, but for now I'll leave it at that: In past times, when I was invited as volunteer or staff, the Mozilla Summits and All-hands were points that energized me and gave me motivation to push forward on making Mozilla better. This year, FOSDEM, with my volunteering and the conversations I had, did the same job. Let's build a better Internet and a better Mozilla community!
I’m writing this in lieu of a traditional Firefox Front-end Performance Update, as I think this will be more useful in the long run than just a snapshot of what my team is doing.
I want to talk about main thread disk access (sometimes referred to more generally as “main thread IO”). Specifically, I’m going to argue that main thread disk access is lethal to program responsiveness. For some folks reading this, that might be an obvious argument not worth making, or one already made ad nauseam — if that’s you, this blog post is probably not for you. You can go ahead and skip most or all of it, if you’d like. Or just skim it. You never know — there might be something in here you didn’t know or hadn’t thought about!
For everybody else, scoot your chairs forward, grab a snack, and read on.
Disclaimer: I wouldn’t call myself a disk specialist. I don’t work for Western Digital or Seagate. I don’t design file systems. I have, however, been using and writing software for computers for a significant chunk of my life, and I seem to have accumulated a bunch of information about disks. Some of that information might be incorrect or imprecise. Please send me mail at mike dot d dot conley at gmail dot com if any of this strikes you as wildly inaccurate (though forgive me if I politely disregard pedantry), and then I can update the post.
The mechanical parts of a computer
If you grab a screwdriver and (carefully) open up a laptop or desktop computer, what do you see? Circuit boards, chips, wires and plugs. Lots of electrons flowing around in there, moving quickly and invisibly.
Notably, there aren’t many mechanical moving parts of a modern computer. Nothing to grease up, nowhere to pour lubricant. Opening up my desktop at home, the only moving parts I can really see are the cooling fans near the CPU and power supply (and if you’re like me, you’ll also notice that your cooling fans are caked with dust and in need of a cleaning).
There’s another moving part that’s harder to see — the hard drive. This might not be obvious, because most mechanical drives (I’ve heard them sometimes referred to as magnetic drives, spinny drives, physical drives, platter drives and HDDs. There are probably more terms.) hide their moving parts inside of the disk enclosure.1
If you ever get the opportunity to open one of these enclosures (perhaps the disk has failed or is otherwise being replaced, and you’re just about to get rid of it) I encourage you to.
As you disassemble the drive, what you’ll probably notice are circular parts, layered on top of one another on a motor that spins them. In between those circles are little arms that can move back and forth. This next image shows one of those circles, and one of those little arms.
<figcaption>There are several of those circles stacked on top of one another, and several of those arms in between them. We’re only seeing the top one in this photo.</figcaption>
Does this remind you of anything? The circular parts remind me of CDs and DVDs, but the arms reaching across them remind me of vinyl players.
<figcaption>Vinyl’s back, baby!</figcaption>
The comparison isn’t that outlandish. If you ignore some of the lower-level details, CDs, DVDs, vinyl players and hard drives all operate under the same basic principles:
The circular part has information encoded on it.
An arm of some kind is able to reach across the radius of the circular part.
Because the circular part is spinning, the arm is able to reach all parts of it.
The end of the arm is used to read the information encoded on it.
There’s some extra complexity for hard drives. Normally there’s more than one spinning platter and one arm, all stacked up, so it’s more like several vinyl players piled on top of one another.
Hard drives are also typically written to as well as read from, whereas CDs, DVDs and vinyls tend to be written to once, and then used as “read-only memory.” (Though, yes, there are exceptions there.)
Lastly, for hard drives, there’s a bit I’m skipping over involving caches, where parts of the information encoded on the spinning platters are temporarily held elsewhere for easier and faster access, but we’ll ignore that for now for simplicity, and because it wrecks my simile.2
So, in general, when you’re asking a computer to read a file off of your hard drive, it’s a bit like asking it to play a tune on a vinyl. It needs to find the right starting place to put the needle, then it needs to put the needle there and only then will the song play.
For hard drives, the act of moving the “arm” to find the right spot is called seeking.
Contiguous blocks of information and fragmentation
Have you ever had to defragment your hard drive? What does that even mean? I’m going to spend a few moments trying to explain that at a high-level. Again, if this is something you already understand, go ahead and skip this part.
Most functional hard drives allow you to do the following useful operations:
Write data to the drive
Read data from the drive
Remove data from the drive
That last one is interesting, because usually when you delete a file from your computer, the information isn’t actually erased from the disk. This is true even after emptying your Trash / Recycling Bin — perhaps surprisingly, the files that you asked to be removed are still there encoded on the circular platters as 1’s and 0’s. This is why it’s sometimes possible to recover deleted files even when it seems that all is lost.
Allow me to explain.
Just like there are different ways of organizing a sock drawer (at random, by colour, by type, by age, by amount of damage), there are ways of organizing a hard drive. These “ways” are called file systems. There are lots of different file systems. If you’re using a modern version of Windows, you’re probably using a file system called NTFS. One of the things that a file system is responsible for is knowing where your files are on the spinning platters. This file system is also responsible for knowing where there’s free space on the spinning platters to write new data to.
When you delete a file, what tends to happen is that your file system marks those sectors of the platter as places where new information can be written to, but doesn’t immediately overwrite those sectors. That’s one reason why sometimes deleted files can be recovered.
Depending on your file system, there’s a natural consequence as you delete and write files of different sizes to the hard drive: fragmentation. This kinda sounds like the actual physical disk is falling apart, but that’s not what it means. Data fragmentation is probably a more precise way of thinking about it.
Imagine you have a sheet of white paper broken up into a grid of 5 boxes by 5 boxes (25 boxes in total), and a box of paints and paintbrushes.
Each square on the paper is white to start. Now, starting from the top-left, and going from left-to-right, top-to-bottom, use your paint to fill in 10 of those boxes with the colour red. Now use your paint to fill in the next 5 boxes with blue. Now do 3 more boxes with yellow.
So we’ve got our colour-filled boxes in neat, organized rows (red, then blue, then yellow), and we’ve got 18 of them filled, and 7 of them still white.
Now let’s say we don’t care about the colour blue. We’re okay to paint over those now with a new colour. We also want to fill in 10 boxes with the colour purple. Hm… there aren’t enough free white boxes to put in that many purple ones, but we have these 5 blue ones we can paint over. Let’s paint over them with purple, and then put the next 5 at the end in the white boxes.
So now 23 of the boxes are filled, we’ve got 2 left at the end that are white, but also, notice that the purple boxes aren’t all together — they’ve been broken apart into two sections. They’ve been fragmented.
This is an incredibly simplified model, but (I hope) it demonstrates what happens when you delete and write files to a hard drive. Gaps open up that can be written to, and bits and pieces of files end up being distributed across the platters as fragments.
This also occurs as files grow. If, for example, we decided to paint two more white boxes red, we’d need to paint the ones at the very end, breaking up the red boxes so that they’re fragmented.
So going back to our vinyl player example for a second — the ideal scenario is that you start a song at the beginning and it plays straight through until the end, right? The more common case with disk drives, however, is you read bits and pieces of a song from different parts of the vinyl: you have to lift and move the arm each time until eventually you have heard the song from start to finish. That seeking of the arm adds overhead to the time it takes to listen to the song from beginning to end.
When your hard drive undergoes defragmentation, what your computer does is try to re-organize your disk so that files are in contiguous sectors on the platters. That’s a fancy way of saying that they’re all in a row on the platter, so they can be read in without the overhead of seeking around to assemble it as fragments.
Skipping that overhead can have huge benefits to your computer’s performance, because the disk is usually the slowest part of your computer.
On the relative input / output speeds of modern computing components
I mentioned in the disclaimer at the start of this post that I’m not a disk specialist or expert. Scott Davis is probably a better bet as one of those. His bio lists an impressive wealth of experience, and mentions that he’s “a recognized expert in virtualization, clustering, operating systems, cloud computing, file systems, storage, end user computing and cloud native applications.”
I don’t know Scott at all (if you’re reading this, Hi, Scott!), but let’s just agree for now that he probably knows more about disks than I do.
I’m picking Scott as an expert because of a particularly illustrative analogy that was posted to a blog for a company he used to work for. The analogy compares the speeds of different media that can be used to store information on a computer. Specifically, it compares the following:
RAM
The network with a decent connection
Flash drives
Magnetic hard drives — what we’ve been discussing up until now.
For these media, the post claims that input / output speed can be measured using the following units:
RAM is in nanoseconds
10GbE Network speed is in microseconds (~50 microseconds)
Flash speed is in microseconds (between 20-500+ microseconds)
Disk speed is in milliseconds
That all seems pretty fast. What’s the big deal? Well, it helps if we zoom in a little bit. The post does this by supposing that we pretend that RAM speed happens in minutes.
If that’s the case, then we’d have to measure network speed in weeks.
And if that’s the case, then we’d want to measure the speed of a Flash drive in months.
And if that’s the case, then we’d have to measure the speed of a magnetic spinny disk in decades.
Update (May 23, 2019): My Uncle Mark, who also works in computing, sent me links that show similar visualizations of computing latency: this one has a really excellent infographic, and this one has more discussion. These articles highlight network latency as the worst offender, which is true especially when the quality of service is low, but I’m mostly writing this post for folks who hack on Firefox where the vast majority of networking occurs off of the main thread.
I wish I had some ACM paper, or something written by a computer science professor that I could point to you to bolster the following claim. I don’t, not because one doesn’t exist, but because I’m too lazy to look for one. I hope you’ll forgive me for that, but I don’t think I’m saying anything super controversial when I say:
In the common case, for a personal computer, it’s best to assume that reading and writing to the disk is the slowest operation you can perform.
Sure, there are edge cases where other things in the system might be slower. And there is that disk cache that I breezed over earlier that might make reading or writing cheaper. And sometimes the operating system tries to do smart things to help you. For now, just let it go. I’m making a broad generalization that I think covers the common cases, and I’m talking about what’s best to assume.
Single and multi-threaded restaurants
When I try to describe threading and concurrency to someone, I inevitably fall back to the metaphor of cooks in a kitchen in a restaurant. This is a special restaurant where there’s only one seat, for a single customer — you, the user.
Single-threaded programs
Let’s imagine a restaurant that’s very, very small and simple. In this restaurant, the cook is also acting as the waiter / waitress / server. That means when you place your order, the server / cook goes into the kitchen and makes it for you. While they’re gone, you can’t really ask for anything else — the server / cook is busy making the thing you asked for last.
This is how most simple, single-threaded programs work—the user feeds in requests, maybe by clicking a button, or typing something in, maybe something else entirely—and then the program goes off and does it and returns some kind of result. Maybe at that point, the program just exits (“The restaurant is closed! Come back tomorrow!”), or maybe you can ask for something else. It’s really up to how the restaurant / program is designed that dictates this.
Suppose you’re very, very hungry, and you’ve just ordered a complex five-course meal for yourself at this restaurant. Blanching, your server / cook goes off to the kitchen. While they’re gone, nobody is refilling your water glass or giving you breadsticks. You’re pretty sure there’s activity going in the kitchen and that the server / cook hasn’t had a heart attack back there, but you’re going to be waiting a looooong time since there’s only one person working in this place.
Maybe in some restaurants, the server / cook will dash out periodically to refill your water glass, give you some breadsticks, and update you on how things are going, but it sure would be nice if we gave this person some help back there, wouldn’t it?
Multi-threaded programs
Let’s imagine a slightly different restaurant. There are more cooks in the kitchen. The server is available to take your order (but is also able to cook in the kitchen if need be), and you make your request from the menu.
Now suppose again that you order a five-course meal. The server goes to the kitchen and tells the cooks what you just ordered. In this restaurant, suppose the kitchen staff are a really great team and don’t get in each other’s way3, so they divide up the order in a way that makes sense and get to work.
The server can come back and refill your water glass, feed you breadsticks, perhaps they can tell you an entertaining joke, perhaps they can take additional orders that won’t take as long. At any rate, in this restaurant, the interaction between the user and the server is frequent and rarely interrupted.
The waiter / waitress / server is the main thread
In these two examples, the waiter / waitress / server is what is usually called the main thread of execution, which is the part of the program that the user interacts with most directly. By moving expensive operations off of the main thread, the responsiveness of the program increases.
Have you ever seen the mouse turn into an hourglass, seen the “This program is not responding” message on Windows? Or the spinny colourful pinwheel on macOS? In those cases, the main thread is off doing something and never came back to give you your order or refill your water or breadsticks — that’s how it generally manifests in common operating systems. The program seems “unresponsive”, “sluggish”, “frozen”. It’s “hanging”, or “stuck”. When I hear those words, my immediate assumption is that the main thread is busy doing something — either it’s taking a long time (it’s making you your massive five course meal, maybe not as efficiently as it could), or it’s stuck (maybe they fell down a well!).
In either case, the general rule of thumb to improving program responsiveness is to keep the server filling the user’s water and breadsticks by offloading complex things on the menu to other cooks in the kitchen.
Accessing the disk on the main thread
Recall that in the common case, for a personal computer, it’s best to assume that reading and writing to the disk is the slowest operation you can perform. In our restaurant example, reading or writing to the disk on the main thread is a bit like having your server hop onto their bike and ride out to the next town over to grab some groceries to help make what you ordered.
And sometimes, because of data fragmentation (not everything is all in one place), the server has to search amongst many many shelves all widely spaced apart to get everything.
And sometimes the grocery store is very busy because there are other restaurants out there that are grabbing supplies.
And sometimes there are police checks (anti-virus / anti-malware software) occurring for passengers along the road, where they all have to show their IDs before being allowed through.
It’s an incredibly slow operation. Hopefully by the time the server comes back, they don’t realize they have to go back out again to get more, but they might if they didn’t realize they were missing some more ingredients.4
Slow slow slow. And unresponsive. And a great way to lose a hungry customer.
For super small programs, where the kitchen is well stocked, or the ride to the grocery store doesn’t need to happen often, having a single-thread and having it read or write is usually okay. I’ve certainly written my fair share of utility programs or scripts that do main thread disk access.
Firefox, the program I spend most of my time working on as my job, is not a small program. It’s a very, very, very large program. Using our restaurant model, it’s many large restaurants with many many cooks on staff. The restaurants communicate with each other and ship food and supplies back and forth using messenger bikes, to provide to you, the customer, the best meals possible.
But even with this large set of restaurants, there’s still only a single waiter / waitress / server / main thread of execution as the point of contact with the user.
Part of my job is to help organize the workflows of this restaurant so that they provide those meals as quickly as possible. Sending the server to the grocery store (main thread disk access) is part of the workflow that we absolutely need to strike from the list.
Start-up main-thread disk access
Going back to our analogy, imagine starting the program like opening the restaurant. The lights go on, the chairs come off of the tables, the kitchen gets warmed up, and prep begins.
While this is occurring, it’s all hands on deck — the server might be off in the kitchen helping to do prep, off getting cutlery organized, whatever it takes to get the restaurant open and ready to serve. Before the restaurant is open, there’s no point in having the server be idle, because the customer hasn’t been able to come in yet.
So if critical groceries and supplies needed to open the restaurant need to be gotten before the restaurant is open, it’s fine to send the server to the store. Somebody has to do it.
For Firefox, there are various things that need to take place before we can display any UI. At that point, it’s usually fine to do main-thread disk access, so long as all of the things being read or written are kept to an absolute minimum. Find how much you need to do, and reduce it as much as possible.
But as soon as UI is presented to the user, the restaurant is open. At that point, the server should stay off their bike and keep chatting with the customer, even if the kitchen hasn’t finished setting up and getting all of their supplies. So to stay responsive, don’t do disk access on the main thread of execution after you’ve started to show the user some kind of UI.
Disk contention
There’s one last complication I want to capture here with our restaurant example before I wrap up. I’ve been saying that it’s important to send anyone except the server to the grocery store for supplies. That’s true — but be careful of sending too many other people at the same time.
Moving disk access off of the main thread is good for responsiveness, full stop. However, it might do nothing to actually improve the overall time that it takes to complete some amount of work. Put it another way: just because the server is refilling your glass and giving you breadsticks doesn’t mean that your five-course meal is going to show up any faster.
Also, disk operations on magnetic drives do not have a constant speed. Having the disk do many things at once within a single program or across multiple programs can slow the whole set of operations down due to the overhead of seeking and context switching, since the operating system will try to serve all disk requests at once, more or less.5
Disk contention and main thread disk access is something I think a lot about these days while my team and I work on improving Firefox start-up performance.
Some questions to ask yourself when touching disk
So it’s important to be thoughtful about disk access. Are you working on code that touches disk? Here are some things to think about:
Is UI visible, and responsiveness a goal?
If so, best to move the disk access off of the main-thread. That was the main thing I wanted to capture, and I hope I’ve convinced you of that point by now.
Does the access need to occur?
As programs age and grow and contributors come and go, sometimes it’s important to take a step back and ask, “Are the assumptions of this disk access still valid? Does this access need to happen at all?” The fastest code is the code that doesn’t run at all.
What else is happening during this disk access? Can disk access be prioritized more efficiently?
This is often trickier to answer as a program continues to run. Thankfully, tools like profilers can help capture recordings of things like disk access to gain evidence of simultaneous disk access.
Start-up is a special case though, since there’s usually a somewhat deterministic / reliably stable set of operations that occur in the same way in roughly the same order during start-up. For start-up, using a tool like a profiler, you can gain a picture of the sorts of things that tend to happen during that special window of time. If you notice a lot of disk activity occurring simultaneously across multiple threads, perhaps ponder if there’s a better way of ordering those operations so that the most important ones complete first.
Can we reduce how much we need to read or write?
There are lots of wonderful compression algorithms out there with a variety of performance characteristics that might be worth pondering. It might be worth considering compressing the data that you’re storing before writing it so that the disk has to write less and read less.
Of course, there’s compression and decompression overhead to consider here. Is it worth the CPU time to save the disk time? Is there some other CPU intensive task that is more critical that’s occurring?
Can we organize the things that we want to read ahead of time so that they’re more likely to be read contiguously (without seeking the disk)?
If you know ahead of time the sorts of things that you’re going to be reading off of the disk, it’s generally a good strategy to store them in that read order. That way, in the best case scenario (the disk is defragmented), the read head can fly along the sectors and read everything in, in exactly the right order you want them. If the user has defragmented their disk, but the things you’re asking for are all out of order on the disk, you’re adding overhead to seek around to get what you want.
Supposing that the data on the disk is fragmented, I suspect having the files in order anyways is probably better than not, but I don’t think I know enough to prove it.
Flawed but useful
One of my mentors, Greg Wilson, likes to say that “all models are flawed, but some are useful”. I don’t think he coined it, but he uses it in the right places at the right times, and to me, that’s what counts.
The information in this post is not exhaustive — I glossed over and left out a lot. It’s flawed. Still, I hope it can be useful to you.
Thanks
Thanks to the following folks who read drafts of this and gave feedback:
Mandy Cheang
Emily Derr
Gijs Kruitbosch
Doug Thayer
Florian Quèze
There are also newer forms of disks called Flash disks and SSDs. I’m not really going to cover those in this post. ↩
The other thing to keep in mind is that the disk cache can have its contents evicted at any time for reasons that are out of your control. If you time it right, you can maybe increase the probability of a file you want to read being in the cache, but don’t bet the farm on it. ↩
When writing multi-threaded programs, this is much harder than it sounds! Mozilla actually developed a whole new programming language to make that easier to do correctly. ↩
Keen readers might notice I’m leaving out a discussion on Paging. That’s because this blog post is getting quite long, and because it kinda breaks the analogy a bit — who sends groceries back to a grocery store? ↩
I’ve never worked on an operating system, but I believe most modern operating systems try to do a bunch of smart things here to schedule disk requests in efficient ways. ↩
Hello, folks. I wanted to give a quick update on what the Firefox Front-end Performance team is up to, so let’s get into it.
The name of the game continues to be start-up performance. We made some really solid in-roads last quarter, and this year we want to continue to apply pressure. Specifically, we want to focus on reducing IO (specifically, main-thread IO) during browser start-up.
Reducing main thread IO during start-up
There are lots of ways to reduce IO – in the best case, we can avoid start-up IO altogether by not doing something (or deferring it until much later). In other cases, when the browser might be servicing events on the main thread, we can move IO onto another thread. We can also re-organize, pack or compress files differently so that they’re read off of the disk more efficiently.
If you want to change something, the first step is measuring it. Thankfully, my colleague Florian has written a rather brilliant test that lets us take accounting of how much IO is going on during start-up. The test is deterministic enough that he’s been able to write a whitelist for the various ways we touch the disk on the main thread during start-up, and that whitelist means we’ve made it much more difficult for new IO to be introduced on that thread.
That whitelist has been processed by the team, and have been turned into bugs, bucketed by the start-up phasewheretheIO is occurring. The next step is to estimate the effort and potential payoff of fixing those bugs, and then try to whittle down the whitelist.
And that’s effectively where we’re at. We’re at the point now where we’ve got a big list of work in front of us, and we have the fun task of burning that list down!
Being better at loading DLLs on Windows
While investigating the warm-up service for Windows, Doug Thayer noticed that we were loading DLLs during start-up oddly. Specifically, using a tool called RAMMap, he noticed that we were loading DLLs using “read ahead” (eagerly reading the entirety of the DLL into memory) into a region of memory marked as not-executable. This means that anytime we actually wanted to call a library function within that DLL, we needed to load it again into an executable region of memory.
Doug also noticed that we were unnecessarily doing ReadAhead for the same libraries in the content process. This wasn’t necessary, because by the time the content process wanted to load these libraries, the parent process would have already done it and it’d still be “warm” in the system file cache.
We’re not sure why we were doing this ReadAhead-into-unexecutable-memory work – it’s existence in the Firefox source code goes back many many years, and the information we’ve been able to gather about the change is pretty scant at best, even with version control. Our top hypothesis is that this was a performance optimization that made more sense in the Windows XP era, but has since stopped making sense as Windows has evolved.
UPDATE: Ehsan pointed us to this bug where the change likely first landed. It’s a long and wind-y bug, but it seems as if this was indeed a performance optimization, and efforts were put in to side-step effects from Prefetch. I suspect that later changes to how Prefetch and SuperFetch work ultimately negated this optimization.
Doug hacked together a quick prototype to try loading DLLs in a more sensible way, and the he was able to capture quite an improvement in start-up time on our reference hardware:
<figcaption>This graph measures various start-up metrics. The scatter of datapoints on the left show the “control” build, and they tighten up on the right with the “test” build. Lower is better. </figcaption>
At this point, we all got pretty excited. The next step was to confirm Doug’s findings, so I took his control and test builds, and tested them independently on the reference hardware using frame recording. There was a smaller1, but still detectable improvement in the test build. At this point, we decided it was worth pursuing.
We’re also seeing the impact reflected in Telemetry. The first Nightly build with Doug Thayer’s patch went out on April 14th, and we’re starting to see a nice dip in some of our graphs here:
<figcaption>This graph measures the time at which the browser window reports that it has first painted. April 14th is the second last date on the X axis, and the Y axis is time. The top-most line is plotting the 95th percentile, and there’s a nice dip appearing around April 14th. </figcaption>
We expect this improvement to have the greatest impact on weaker hardware with slower disks, but we’ll be avoiding some unnecessary work for all Windows users, and that gets a thumbs-up in my books.
If all goes well, this fix should roll out in Firefox 68, which reaches our release audience on July 9th!
My test machine has SuperFetch disabled to help reduce noise and inconsistency with start-up tests, and we suspect SuperFetch is able to optimize start-up better in the test build ↩
With Firefox 67 only a few short weeks away, I thought it might be interesting to take a step back and talk about some of the work that the Firefox Front-end Performance team is shipping to users in that particular release.
To be clear, this is not an exhaustive list of the great performance work that’s gone into Firefox 67 – but I picked a few things that the front-end team has been focused on to talk about.
Stop loading things we don’t need right away
The fastest code is the code that doesn’t run at all. Sometimes, as the browser evolves, we realize that there are components that don’t need to be loaded right away during start-up, and can instead of deferred until sometime after start-up. Sometimes, that means we can wait until the very last moment to initialize some component – that’s called loading something lazily.
Here’s a list of things that either got deferred until sometime after start-up, or made lazy:
The Hidden Window is a mysterious chunk of code that manages the state of the global menu bar on macOS when there are no open windows. The Hidden Window is also sometimes used as a singleton DOM window where various operations can take place. On Linux and Windows, it turns out we were creating this Hidden Window far early than needs be, and now it’s quite a bit lazier.
Page style
Page Style is a menu you can find under View in the main menu bar, and it’s used to switch between alternative style sheets on a page. It’s a pretty rarely used feature from what we can tell, but we were scanning pages for their alternative stylesheets far earlier than we needed to. We were also scanning pages that we know don’t have alternative stylesheets, like the about:home / about:newtab page. Now we only scan normal web pages, and we do so only after we service the idle event queue.
Cache invalidation
The Startup Cache is an important part of Firefox startup performance. It’s primary job is to cache computations that occur during each startup so that they only have to happen every once in a while. For example, the mark-up of the browser UI often doesn’t change from startup to startup, so we can cache a version of the mark-up that’s faster to read from disk, and only invalidate that during upgrades.
We were invalidating the whole startup cache every time a WebExtension was installed or uninstalled. This used to be necessary for old-style XUL add-ons (since those could cause changes to the UI that would need to go into the cache), but with those add-ons no longer available, we were able to remove the invalidation. This means faster startups more often.
Don’t touch the disk
The disk is almost always the slowest part of the system. Reading and writing to the disk can take a long time, especially on spinning magnetic drives. The less we can read and write, the better. And if we’re going to read, best to do it off of the main thread so that the UI remains responsive.
Old XUL icons code
We were reading from the disk on the main thread to search for window-specific icons to display in the window titlebar.
We noticed that when we were checking that a directory exists on Windows (to write a file to it), we were using the CreateDirectoryW Windows API. This API checks each folder on the way down to the last one to see if they exist. That’s a lot of disk IO! We can avoid this if we assume that the parent directories exist, and only fall into the slow path if we fail to write our file. This means that we hit the faster path with less IO more often, which is good for responsiveness and start-up time.
Enjoy your Faster Fox!
Firefox 67 is slated to ship with these improvements on May 14th – just a little over a month away. Enjoy!
Firefox 66 has been released, Firefox 67 is out on the beta channel, and Firefox 68 is cooking for the folks on the Nightly channel! These trains don’t stop!
With that, let’s take a quick peek at what the Firefox Front-end Performance team has been doing these past few weeks…
Document Splitting Foundations for WebRender (In-Progress by Doug Thayer)
An impressive set of patches were recently queued to land, which should bring document splitting to WebRender, but in a disabled state. The gfx.webrender.split-render-roots pref is what controls it, but I don’t think we can reap the full benefits of document splitting until we get retained display lists enabled in the parent process for the UI. I believe, at that point, we can start enabling document splitting, which means that updating the browser UI area will not involve sending updates to the content area for WebRender.
In other WebRender news, it looks like it should be enabled by default for some of our users on the release channel in Firefox 67, due to be released in mid-May!
Warm-up Service (In-Progress by Doug Thayer)
Doug has written the bits of code that tie a Firefox preference to an HKLM registry key, which can be read by the warm-up service at start-up. The next step is to add a mode to the Firefox executable that loads its core DLLs and then exits, and then have the warm-up service call into that mode if enabled.
Once this is done, we should be in a state where we can user test this feature.
Startup Cache Telemetry (In-Progress by Doug Thayer)
Two things of note here:
With the probes having now uplifted to Beta, data will slowly trickle in these next few days that will show us how the Firefox startup cache is behaving in the wild for users that aren’t receiving two updates a day (like our Nightly users). This important, because oftentimes, those updates cause some or all of the startup cache to be invalidated. We’re eager to see how the startup caches are behaving in the wild on Beta.
One of the tests that was landed for the startup cache Telemetry appears to have caught an issue with how the QuantumBar code works with it – this is useful, because up until now, we’ve had very little automated testing to ensure that the startup cache is working as expected.
Smoother Tab Animations (Paused by Felipe Gomes)
UX, Product and Engineering have been having discussions about how the new tab animations work, and one thing has been decided upon: we want our User Research team to run some studies to see how tab animations are perceived before we fully commit to changing one of the fundamental interactions in the browser. So, at this time, Felipe is pausing his efforts here until User Research comes back with some information on guidance.
Browser Adjustment Project (Concluded by Gijs Kruitbosch)
We originally set out to see whether or not we could do something for users running weaker hardware to improve their browsing experience. Our initial hypothesis was that by lowering the frame rate of the browser on weaker hardware, we could improve the overall page load time.
This hypothesis was bolstered by measurements done in late 2018, where it appeared that by manually lowering the frame rate on a weaker reference laptop, we could improve our internal page load benchmarks by a significant degree. This measurement was reproduced by Denis Palmeiro on Vicky Chin’s team, and so Gijs started implementing a runtime detection mechanism to do that lowering of the frame rate for machines with 2 or fewer cores where each core’s clockspeed was 1.8Ghz or slower1.
However, since then, we’ve been unable to reproduce the same positive effect on page load time. Neither has Denis. We suspect that recent work on the RefreshDriver, which changes how often the RefreshDriver runs during the page load window, is effectively getting the same kind of win2.
We did one final experiment to see whether or not lowering the frame rate would improve battery life, and it appeared to, but not to a very high degree. We might revisit that route were we tasked with trying to improve power usage in Firefox.
Better about:newtab Preloading (Completed by Gijs Kruitbosch)
The patch to preload about:newtab in an idle callback has landed and stuck! This means that we don’t preload about:newtab immediately after opening a new tab (which is good for responsiveness right around the time when you’re likely to want to do something), and also means that we have the possibility of preloading the first new tab in new windows! Great job, Gijs!
Experiments with the Process Priority Manager (In-Progress by Mike Conley)
I had a meeting today with Saptarshi, one of our illustrious Data Scientists, to talk about the upcoming experiment. One of the things he led me to conclude was that this experiment is going to have a lot of confounds, and it will be difficult to conclude things from.
Part of the reason for that is because there are often times when a background tab won’t actually have its content process priority lowered. The potential reasons for this are:
The tab is running in a content process which is also hosting a tab that is running in the foreground of either the same or some other browser window.
The tab is playing audio or video.
Because of this, we can’t actually do things like measure how page load is being impacted by this feature because we don’t have a great sense of how many tabs have their content process priorities lowered. That’s just not a thing we collect with Telemetry. It’s theoretically possible, either due to how many windows or videos or tabs our Beta users have open, that very few of them will ever actually have their content process priorities lowered, and then the data we’d draw from Telemetry would be useless.
I’m working with Saptarshi now to try to find ways of either altering the process priority manager or adding new probes to reduce the number of potential confounds.
We’re only a few weeks away from Firefox 67 merging from the Nightly channel to Beta, and since my last update, a number of things have landed.
It’s the end of a long week for me, so I apologize for the brevity here. Let’s check it out!
Document Splitting Foundations for WebRender (In-Progress by Doug Thayer)
dthayer is still trucking along here – he’s ironed out a number of glitches, and kats is giving feedback on some APZ-related changes. dthayer is also working on a WebRender API endpoint for generating frames for multiple documents in a single transaction, which should help reduce the window of opportunity for nasty synchronization bugs.
Warm-up Service (In-Progress by Doug Thayer)
dthayer is pressing ahead with this experiment to warm up a number of critical files for Firefox shortly after the OS boots. He is working on a prototype that can be controlled via a pref that we’ll be able to test on users in a lab-setting (and perhaps in the wild as a SHIELD experiment).
Startup Cache Telemetry (In-Progress by Doug Thayer)
dthayer landed this Telemetry early in the week, and data has started to trickle in. After a few more days, it should be easier for us to make inferences on how the startup caches are operating out in the wild for our Nightly users.
Smoother Tab Animations (In-Progress by Felipe Gomes)
After a few rounds of landings and backouts, this appears to have stuck! The hidden window is now created after the main window has finished painting, and this has resulted in a nice ts_paint (startup paint) win on our Talos benchmark!
<figcaption>This is a graph of the ts_paint startup paint Talos benchmark. The highlighted node is the first mozilla-central build with the hidden window work. Lower is better, so this looks like a nice win!</figcaption>
Browser Adjustment Project (In-Progress by Gijs Kruitbosch)
This project appears to be reaching its conclusion, but with rather unsatisfying results. Denis Palmeiro from Vicky Chin’s team has done a bunch of testing of both the original set of patches that Gijs landed to lower the global frame rate (painting and compositing) from 60fps to 30fps for low-end machines, as well as the new patches that decrease the frequency of main-thread painting (but not compositing) to 30fps. Unfortunately, this has not yielded the page load wins that we wanted1. We’re still waiting to see if there’s a least a power-usage win here worth pursuing, but we’re almost ready the pull the plug on this one.
Better about:newtab Preloading (In-Progress by Gijs Kruitbosch)
Unfortunately, there’s a small snag with a test failure in automation, but Gijs is on the case.
Experiments with the Process Priority Manager (In-Progress by Mike Conley)
The Process Priority Manager has been enabled in Nightly for a number of weeks now, and no new bugs have been filed against it. I filed a bug earlier this week to run a pref-flip experiment on Beta after the Process Priority Manager patches are uplifted later this month. Our hope is that this has a neutral or positive impact on both page load time and user retention!
Make the PageStyleChild load lazily (Completed by Mike Conley)
There’s an infrequently used feature in Firefox that allows users to switch between different CSS stylesheets that a page might offer. I’ve made the component that scans the document for alternative stylesheets much lazier, and also made it skip non web-pages, which means (at the very least) less code running when loading about:home and about:newtab
This was unexpected – we ran an experiment late in 2018 where we noticed that lowering the frame rate manually via the layout.frame_rate pref had a positive impact on page load time… unfortunately, this effect is no longer being observed. This might be due to other refresh driver work that has occurred in the meantime. ↩
It’s been just a little over two weeks since my last update, so let’s see where we are!
A number of our projects are centered around trying to improve start-up time. Start-up can mean a lot of things, so we’re focused specifically on cold start-up on the Windows 10 2018 reference device when the machine is at rest.
If you want to improve something, the first thing to do is measure it. There are lots of ways to measure start-up time, and one of the ways we’ve been starting to measure is by doing frame recording analysis. This is when we capture display output from a testing device, and then analyze the videos.
This animated GIF shows eight videos. The four on the left are Firefox Nightly, and the four on the right are Google Chrome (71.0.3578.98). The videos are aligned so that both browsers are started at the same time.
<figcaption>The four on the left are Firefox Nightly, and the four on the right are Google Chrome (71.0.3578.98)</figcaption>
Some immediate observations:
Firefox Nightly is consistently faster to reach first paint (that’s the big white window)
Firefox Nightly is consistently faster to draw its toolbar and browser UI
Google Chrome is faster at painting its initial content
This last bullet is where the team will be focusing its efforts – we want to have the initial content painted and settled much sooner than we currently do.
Document Splitting Foundations (In-Progress by Doug Thayer)
After some pretty significant refactorings to work better with APZ, Doug posted a new stack of patches late last week which will sit upon the already large stack of patches that have already landed. There are still a number of reviews pending on the main stack, but this work appears to be getting pretty close to conclusion, as the patches are in the final review and polish stage.
After this, once retained display lists are enabled in the parent process, and an API is introduced to WebRender to generate frames for multiple documents in a single transaction, we can start thinking about enabling document splitting by default.
Warm-up Service (In-Progress by Doug Thayer)
A Heartbeat survey went out a week or so back to get some user feedback about a service that would speed up the launching of Firefox at the cost of adding some boot time to Windows. The responses we’ve gotten back have been quite varied, but can be generally bucketed into three (unsurprising) groups:
Users who say they do not want to make this trade
Users who say they would love to make this trade
Users who don’t care at all about this trade
Each group is sufficiently large to warrant further exploration. Our next step is to build a version of this service that we can turn on and off with a pref and test either in a lab and/or out in the wild with a SHIELD study.
Startup Cache Telemetry (In-Progress by Doug Thayer)
We do a number of things to try to improve real and perceived start-up time. One of those things is to cache things that we calculate at runtime during start-up to the disk, so that for subsequent start-ups, we don’t have to do those calculations again.
There are a number of mechanisms that use this technique, and Doug is currently adding some Telemetry to see how they’re behaving in the wild. We want to measure cache hits and misses, so that we know how healthy our cache system is out in the wild. If we get signals back that our start-up caches are missing more than we expect, this will highlight an important area for us to focus on.
Smoother Tab Animations (In-Progress by Felipe Gomes)
UX has gotten back to us with valuable feedback on the current implementation, and Felipe is going through it and trying to find the simplest way forward to address their concerns.
Having been available (though disabled by default) on Nightly, we’ve discovered one bug where the tab strip can become unresponsive to mouse events. Felipe is currently working on this.
Lazy Hidden Window (In-Progress by Felipe Gomes)
Under the hood, Firefox’s front-end has a notion of a “hidden window”. This mysterious hidden window was originally introduced long long ago1 for MacOS, where it’s possible to close all windows yet keep the application running.
Since then, it’s been (ab)used for Linux and Windows as well, as a safe-ish place to do various operations that require a window (since that window will always be around, and not go away until shutdown).
Browser Adjustment Project (In-Progress by Gijs Kruitbosch)
Gijs updated the patch so that the adjustment causes the main thread to skip every other VSync rather than swithing us to 30fps globally2.
We passed the patch off to Denis Palmeiro, who has a sophisticated set-up that allows him to measure a pageload benchmark using frame recording. Unfortunately, the results we got back suggested that the new approach regressed visual page load time significantly in the majority of cases.
We’re in the midst of using the same testing rig to test the original global 30fps patch to get a sense of the magnitude of any improvements we could get here. Denis is also graciously measuring the newer patch to see if it has any positive benefits towards power consumption.
Better about:newtab Preloading (In-Progress by Gijs Kruitbosch)
By default, users see about:newtab / a.k.a Activity Stream when they open new tabs. One of the perceived performance optimizations we’ve done for many years now is to preload the next about:newtab in the background so that the next time that the user opens a tab, the about:newtab is all ready to roll.
This is a perceived performance optimization where we’re moving work around rather than doing less work.
Right now, we preload a tab almost immediately after the first tab is opened in a window. That means that the first opened tab is never preloaded, but the second one is. This is for historical reasons, but we think we can do better.
Gijs is working on making it so that we choose a better time to preload the tab – namely, when we’ve found an idle pocket of time where the user doesn’t appear to be doing anything. This should also mean that the first new tab that gets opened might also be preloaded, assuming that enough idle time was made available to trigger the preload. And if there wasn’t any idle time, that’s also good news – we never got in the users way by preloading when it’s clear they were busy doing something else
Experiments with the Process Priority Manager (In-Progress by Mike Conley)
The Process Priority Manager has been enabled on Nightly for a few weeks now. Except for a (now fixed) issue where audio playing in background tabs would drop samples periodically, it’s been all quiet for regression reports.
The next step is to file a bug to run an experiment on Beta to see how this work impacts page load time.
Enable the separate Activity Stream content process by default (Stalled by Mike Conley)
This work is temporarily stalled while I work on other things, so there’s not too much to report here.
Well, here I am again – apologizing about a late update. Lots of stuff has been going on performance-wise in the Firefox code-base, and I’ll just be covering a small section of it here.
You might also notice that I changed the title of the blog series from “Firefox Performance Update” to “Firefox Front-end Performance Update”, to reflect that the things the Firefox Front-end Performance team is doing to keep Firefox speedy (though I’ll still add a grab-bag of other performance related work at the end).
So what are we waiting for? What’s been going on?
Migrate consumers to the new Places Observer system (Paused by Doug Thayer)
Doug was working on this later in 2018, and successfully ported a good chunk of our bookmarks code to use the new batched Places Observer system. There’s still a long-tail of other call sites that need to be updated to the new system, but Doug has shifted focus from this to other things in the meantime.
This has been a pretty long-haul task, but Doug has been plugging away, and landed a significant chunk of the infrastructure for this. At this time, Doug is working with kats to make Document Splitting integrate nicely with Async-Pan-Zooming (APZ).
The current plan is for Document Splitting to land disabled by default, since it’s blocked by parent-process retained display lists (which still have a few bugs to shake out).
Warm-up Service (In-Progress by Doug Thayer)
Doug is investigating the practicalities of having a service run during Windows start-up to preload various files that Firefox will need when started.
We’re still researching this at multiple levels, and haven’t yet determined if this is a thing that we’d eventually want to ship. Stay tuned.
Smoother Tab Animations (In-Progress by Felipe Gomes)
After much ado, simplification, and review back-and-forth, the initial set of new tab animations have landed in Nightly. You can enable them by setting browser.tabs.newanimations to true in about:config and then restarting the browser. These new animations run entirely on the compositor, instead of painting at each refresh driver tick, so they should be smoother than the current animations that we ship.
There are still some cases that need new animations, and Felipe is waiting on UX for those.
Overhauling about:performance (V1 Completed by Florian Quèze)
The new about:performance shipped late last year, and now shows both energy as well as memory usage of your tabs and add-ons.
The current iteration allows you to close the tabs that are hogging your resources. Current plans should allow users to pause JavaScript execution in busy background tabs as well.
Browser Adjustment Project (In-Progress by Gijs Kruitbosch)
Gijs has landed some patches in Nightly (which have recently uplifted to Beta, and are only enabled on early Betas), which lowers the default frame rate of Firefox from 60fps to 30fps on devices that are considered “low-end”1.
This has been on Nightly for a while, but as our Nightly population tends to skew to more powerful hardware, we expect not a lot of users have experienced the impact there.
While the lowered frame rate seemed to have a positive impact on page load time in the lab on our “low-end” reference hardware, we’re having a much harder time measuring any appreciable improvement in CI. We have scheduled an experiment to see if improvements are detectable via our Telemetry system on Beta.
We need to be prepared that this particular adjustment will either not have the desired page load improvement, or will result in a poorer quality of experience that is not worth any page load improvement. If that’s the case, we still have a few ideas to try, including:
Lowering the refresh driver tick, rather than the global frame rate. This would mean things like scrolling and videos would still render at 60fps, but painting the UI and web content would occur at a lower frequency.
Use the hardware vsync again (switching to 30fps turns hardware vsync off), but just paint every other time. This is to test whether or not software vsync results in worse page load times than hardware vsync.
Avoiding spurious about:blank loads in the parent process (Completed by Gijs Kruitbosch)
Gijs short-circuited a bunch of places where we were needlessly creating about:blank documents that we were just going to throw away (see this bug and dependencies). There are still a long tail of cases where we still do this in some cases, but they’re not the common cases, and we’ve decided to apply effort for other initiatives in the meantime.
Experiments with the Process Priority Manager (In-Progress by Mike Conley)
This was originally Doug Thayer’s project, but I’ve taken it on while Doug focuses on the epic mountain that is WebRender Document Splitting.
If you recall, the goal of this project is to lower the process priority for tabs that are only sitting in the background. This means that if you have tabs in the background that are attempting to use system resources (running JavaScript for example), those tabs will have less priority at the operating system level than tabs that are in the foreground. This should make it harder for background tabs to cause foreground tabs to be starved of processing resources.
After clearing a few finalblockers, we enabled the Process Priority Manager by default last week. We also filed a bug to keep background tabs at a higher priority if they’re playing audio and video, and the fix for that just landed in Nightly today.
So if you’re on Windows on Nightly, and you’re curious about this, you can observe the behaviour by opening up the Windows Task Manager, switching to the “Details” tab, and watching the “Base priority” reading on your firefox.exe processes as you switch tabs.
Cheaper tabs in titlebar (Completed by Mike Conley)
After an epic round of review (thanks, Dao!), the patches to move our tabs-in-titlebar logic out of JS and into CSS landed late last year.
Enable the separate Activity Stream content process by default (In-Progress by Mike Conley
There’s one known bug remaining that’s preventing us from letting the privileged content process from being enabled by default.
Thankfully, the cause is understood, and a fix is being worked on. Unfortunately, this is one of those bugs where the proper solution involves refactoring a bit of old crufty stuff, so it’s taking longer than I’d like.
Still, if all goes well, this bug should be closed out soon, and we can see about letting the privileged content process ride the trains.
Grab bag of notable performance work
This is an informal list of things that I’ve seen land in the tree lately that I believe will have a positive performance impact for our users. Have you seen something that you’d like to nominate for a future list? Submit the bug here!
Also, keep in mind that some of these landed months ago and already shipped to release. That’s what I get for taking so long to write a blog post.
Gabriele Svelto made it so that the minidump analyzer, which runs after a crash has occurred to produce stack dumps for crash pings, runs with much lower process priority. This means that the CPU is being hogged less after a crash, when you’re likely to want to get right back to what you were doing.
Hey folks – another Performance Update coming at you! It’s been a few weeks since I posted one of these, mostly due to travel, holidays and the Mozilla SF All-Hands. However, we certainly haven’t been idle during that time. Much work has been done Performance-wise, and there’s a lot to tell. So strap in! But first…
This Performance Update is brought to you by: promiseDocumentFlushed
promiseDocumentFlushed is a utility that’s available for browser engineers in chrome documents on the window global. The goal of promiseDocumentFlushed is to help avoid synchronous layout flushes in our JavaScript code by scheduling work to only occur after the next “natural” layout flush occurs1.
promiseDocumentFlushed takes a function and returns a Promise. The function it takes will run the next time a natural layout flush and paint has finished occurring. At this point, the DOM should not be “dirty”, and size and position queries should be very cheap to calculate. It is critically important for the callback to not modify the DOM. I’ve filed bugs to make modifying the DOM inside that callback enter some kind of failure state, but it hasn’t been resolved yet.
The return value of the callback is what promiseDocumentFlushed’s returned Promise resolves with. Once the Promise resolves, it is then safe to modify the DOM.
This mechanism means that if, for some reason, you need to gather information about the size or position of things in the DOM, you can do it without forcing a synchronous layout flush – however, a paint will occur before that information is given to you. So be on the look-out for flicker, since that’s the trade-off here.
And now, here’s a list of the projects that the team has been working on lately:
ClientStorage (In-Progress by Doug Thayer)
The ClientStorage project should allow Firefox to communicate with the GPU more efficiently on macOS, which should hopefully reduce jank on the compositor thread2. This is right on the verge of landing3, and we’re very excited to see how this impacts our macOS users!
Init WindowsJumpLists off-main-thread (Completed by Doug Thayer)
The JumpList is a Windows-only feature – essentially an application-specific context menu that opens when you right-click on the application in the task bar. Adding entries to this context menu involves talking to Windows, and unfortunately, the way we were originally doing this involved writing to the disk on the main thread. Thankfully, the API is thread-safe, so Doug was able to move the operation onto a background thread. This is good, because arewesmoothyet was reporting the Windows JumpList code as one of the primary causes of main-thread hangs caused by our front-end code.
Reduce painting while scrolling panels on macOS (Completed by Doug Thayer)
Matt Woodrow noticed that the recently added All Tabs list was performing quite poorly when scrolling it on macOS. After turning on paint-flashing for our browser UI, he noticed that we were re-painting the entire menu every time it scrolled. After some investigation, Matt realized that this was because our Graphics code was skipping some optimizations due to the rounded corners of the panels on macOS. We briefly considered removing the rounded corners on macOS, but then Doug found a more general fix, and now we only re-paint the minimum necessary to scroll the menu, and it’s much smoother!
Make the RemotePageManager lazy (In-Progress by Felipe Gomes)
Overhauling about:performance (In-Progress by Florian Quèze)
Florian is working on improving about:performance, with the hopes of making it more useful for browser engineers and users for diagnosing performance problems in Firefox. Here’s a screenshot of what he has so far:
Apparently, mining cryptocurrency takes a lot of CPU!
Thanks to the work of Tarek Ziade, we now have a reliable mechanism for getting information on which tabs are consuming CPU cycles. For example, in the above screenshot, we can see that the coinhive tab that Firefox has open is consuming a bunch of CPU in some workers (mining cryptocurrency). Florian has also been clearing out some of the older code that was supporting about:performance, including the subprocess memory table. This table was useful for our browser engineers when developing and tuning the multi-process project, but we think we can replace it now with something more actionable and relevant to our users. In the meantime, since gathering the memory data causes jank on the main thread, he’s removed the table and the supporting infrastructure. The about:performance work hasn’t landed in the tree yet, but Florian is aiming to get it reviewed and landed (preffed off) soon.
Browser Adjustment Project (In-Progress by Gijs Kruitbosch)
This is a research project to find ways that Firefox can classify the hardware it’s running on, which should make it easier for the browser to make informed decisions on how to deal with things like CPU scheduling, thread and process priority, graphics and UI optimizations, and memory reclamation strategies. This project is still in its early days, but Gijs has already identified prior art and research that we can build upon, and is looking at lightweight ways we can assign grades to a user’s CPU, disk, and graphics hardware. Then the plan is to try hooking that up to the toolkit.cosmeticAnimations pref, to test disabling those animations on weaker hardware. He’s also exploring ways in which the user can override these measurements in the event that they want to bypass the defaults that we choose for each environment.
Avoiding spurious about:blank loads in the parent process (In-Progress by Gijs Kruitbosch)
When we open new browser windows, the initial browser tab inside them runs in the parent process and loads about:blank. Soon after, we do a process flip to load a page in the content process. However, that initial about:blank still has cost, and we think we can avoid it. There’s a test failure that Gijs is grappling with, but after much thorough detective work deep in the complex ball of code that supports our window opening infrastructure, he’s figured out a path forward. We expect this project to be wrapped up soon, which should hopefully make window opening cheaper and also produce less flicker.
Load Activity Stream scripts from ScriptPreloader (Completed by Jay Lim)
Defer calculating Activity Stream state until idle (In-Progress by Jay Lim)
When Firefox starts up, one of the first things it prepares to do is show you the Activity Stream page, since that’s the default home and new tab page. Jay thinks we might be able to save the state of Activity Stream at shutdown, and load it again quickly during startup within the content process, and then defer the calculations necessary to produce a more recent state until after the parent process has become idle. We’re unsure yet what this will buy us in terms of start-up speed, but Jay is hacking together a prototype to see. I’m eager to find out!
Grab bag of Notable Performance Work
Luca Greco landed all of the infrastructure to move the WebExtension storage.local backend from a file in the profile directory to indexedDB. This should particularly help the performance of the browser when WebExtensions write small changes to large storage structures, since historically this would cause the entire JSON object for the structure to be recomputed and flushed to disk. This should also help with memory consumption. The infrastructure is disabled by default, and once this bug is fixed, it will be switched on.
Dave Townsend fixed an issue where we were requesting the favicon for new pages twice instead of once. This resulted in a 2%-3% win on our internal session restoration bench on 64-bit Linux!
As I draw this update to a close, I want to give a shout-out to my intern and colleague Jay Lim, whose internship is ending in a few short days. Jay took to performance work like a duck in water, and his energy, ideas and work were greatly appreciated! Thank you so much, Jay!
By “natural”, I mean a layout flush triggered by the refresh driver, and not by some JavaScript requesting size or position information on a dirty DOM ↩
And when it comes to smoothness and responsiveness, jank on the compositor thread is deadly ↩
it landed and bounced once due to a crash test failure, but Doug has just gotten a fix for it approved ↩
As I mentioned previously, the Mixed Reality "virus" has caught me recently and I spend a good portion of my Mozilla contribution time with presenting and writing demos for WebVR/XR nowadays.
The prime driver for writing my first such demo was that I wanted to do something meaningful with A-Frame. Previously, I had only played around with the Hello WebVR example and some small alterations around the basic elements seen in that one, which is also pretty much what I taught to others in the WebVR workshops I held in Vienna last year. Now, it was time to go beyond that, and as I had recently bought a HTC Vive, I wanted something where the controllers could be used - but still something that would fall back nicely and be usable in 2D mode on a desktop browser or even mobile screens.
While I was thinking about what I could work on in that area, another long-standing thought crossed my mind: How feasible is it to render OpenStreetMap (OSM) data in 3D using WebVR and A-Frame? I decided to try and find out.
First, I built on my knowledge from Lantea Maps and the fact that I had a tile cache server set up for that, and created a layer of a certain set of tiles on the ground to for the base. That brought me to a number of issue to think about and make decisions on: First, should I respect the curvature of the earth, possibly put the tiles and the viewer on a certain place on a virtual globe? Should I respect the terrain, especially the elevation of different points on the map? Also, as the VR scene relates to real-world sizes of objects, how large is a map tile actually in reality? After a lot of thinking, I decided that this would be a simple demo so I would assume the earth is flat - both in terms of curvature or "the globe" and terrain, and the viewer would start off at coordinates 0/0/0 with x and z coordinates being horizontal and y the vertical component, as usual in A-Frame scenes. For the tile size, I found that with OpenStreetMap using Mercator projection, the tiles always stayed squares, with different sizes based on the latitude (and zoom level, but I always use the same high zoom there). In this respect, I still had to take account of the real world being a globe.
Once I had those tiles rendering on the ground, I could think about navigation and I added teleport controls, later also movement controls to fly through the scene. With W/A/S/D keys on the desktop (and later the fly controls), it was possible to "fly" underneath the ground, which was awkward, so I wrote a very simple "position-limit" A-Frame control later on, which prohibits that and also is a very nice example for how to build a component, because it's short and easy to understand.
All this isn't using OSM data per se, but just the pre-rendered tiles, so it was time to go one step further and dig into the Overpass API, which allows to query and retrieve raw geo data from OSM. With Overpass Turbo I could try out and adjust the queries I wanted to use ad then move those into my code. I decided the first exercise would be to get something that is a point on the map, a single "node" in OSM speak, and when looking at rendered maps, I found that trees seemed to fit that requirement very well. An Overpass query for "node[natural=tree]" later and some massaging the result into a format that JavaScript can nicely work with, I was able to place three-dimensional A-Frame entities in the places where the tiles had the symbols for trees! I started with simple brown cylinders for the trunks, then placed a sphere on top of them as the crown, later got fancy by evaluating various "tags" in the data to render accurate height, crown diameter, trunk circumference and even a different base model for needle-leaved trees, using a cone for the crown.
But to make the demo really look like a map, it of course needed buildings to be rendered as well. Those are more complex, as even the simpler buildings are "ways" with a variable amount of "nodes", and the more complex ones have holes in their base shape and therefore require a compound (or "relation" in OSM speak) of multiple "ways", for the outer shape and the inner holes. And then, the 2D shape given by those properties needs to be extruded to a certain height to form an actual 3D building. After finding the right Overpass query, I realized it would be best to create my own "building" geometry in A-Frame, which would get the inner and outer paths as well as the height as parameters. In the code for that, I used the THREE.js library underlying A-Frame to create a shape (potentially with holes), extrude it to the right height and rotate it to actually stand on the ground. Then I used code similar to what I had for trees to actually create A-Frame entities that had that custom geometry. For the height, I would use the explicit tags in the OSM database, estimate from its levels/floors if given or else fall back to a default. And I would even respect the color of the building if there was a tag specifying it.
With that in place, I had a pretty nice demo that uses data directly from OpenStreetMap to render Virtual Reality scenes that could be viewed in the desktop or mobile browser, or even in a full VR headset!
It's available under the name of "VR Map" at vrmap.kairo.at, and of course the source code can also be expected, copied and forked on GitHub.
Again, this is intended as a demo, not a full-featured product, and e.g. does at this time only render an area of a defined size and does not include any code to load additional scenery as you are moving around. Also, it does not support "building parts", which are the way to specify in OSM that a different pieces of a building have e.g. different heights or colors. It could also be extended to actually render models of the buildings when they exist and are referred in the database (so e.g. the Eiffel Tower would look less weird when going to the Paris preset). There are a lot of things that still can be done to improve on this demo for sure, but as it stands, it's a pretty simple piece of code that shows the power of both A-Frame and the OpenStreetMap data, and that's what I set out to do, after all.
My plan is to take this to multiple meetups and conferences to promote both underlying projects and get people inspired to think about what they can do with those ideas. Please let me know if you know of a good event where I can present this work. The first of those presentations happened a at the ViennaJS May Meetup, see the slides and video.
I'm also in an email conversation with another OSM contributor who is using this demo as a base for some of his work, e.g. on rendering building models in 3D and VR and allowing people to correct their position data.
I hope that this demo spawns more ideas of what people can do with this toolset, and I'll also be looking into more demos that will probably move into different directions.
Ever since a close encounter with burning out (thankfully, I didn't quite get there) forced me to leave my job with Mozilla more than two years ago, I have been looking for a place and role that feels good for me in the Mozilla community. I immediately signed up to join Tech Speakers as I always loved talking about Mozilla tech topics and after all breaking down complicated content and communicating it to different groups is probably my biggest strength - but finding the topics I want to present at conferences and other events has been a somewhat harder journey.
I knew I had to keep my distance to crash stats, despite knowing the area in and out and having developed some passion for it, but staying in the same area as a volunteer than in a job that almost burned me out was just not a good idea, from multiple points of view. I thought about building up some talks about working with data but it still was a bit too close to that past and not what I presently do a lot (I work in blockchain technology mostly today), so that didn't go far (but maybe it will happen at some point).
On the other hand, I got more and more interested in some things the Open Innovation group at Mozilla was doing, and even more in what the Emerging Technologies teams bring into the Mozilla and web sphere. My talk (slides) at this year's local "Linuxwochen Wien" conference was a very quick run-through of what's going on there and it's a whole stack of awesomeness, from Mixed Reality via codecs, Rust, Voice and whatnot to IoT. I would love to dig a bit into the latter but I didn't yet find the time.
What I did find some time for is digging into WebVR (now WebXR, where "XR" means "Mixed Reality") and the A-Frame library that Mozilla has created to make it dead simple to create your own VR/XR experiences. Last year I did two workshops in Vienna on that area, another one this year and I'm planning more of them. It's great how people with just some HTML knowledge can build something easily there as well as people who are more into JS programming, who can dig even deeper. And the immersiveness of VR with a real headset blows people away again and again in any case, so a good thing to show off.
While last year I only had cardboards with some left-over Sony Z3C phones (thanks to Mozilla) to show some basic 3DoF (rotation only) VR with low resolution, this proved to be interesting already to people I presented to or made workshops with. Now, this year I decided to buy a HTC Vive, seeing its price go down somewhat before the next generation of headsets would be shipped. (As a side note, I chose the Vive over the Rift because of Linux drivers being available and because I don't want to give money to Facebook.) Along with a new laptop with a high-end GPU that can drive the VR headset, I got into fully immersive 6DoF VR and, I have to say, got somewhat addicted to the experience.
I ran a demo booth with A-Painter at "Linuxwochen Wien" in May, and people were both awed at the VR experience and that this was all running in plain Firefox! Spreading the word about new web technologies can be really fun and rewarding with experiences like that! Next to showing demos and using VR myself, I also got into building WebVR/XR demos myself (I'm more the person to do demos and prototypes and spread the word, rather than building long-lasting products) - but I'll leave that to another blog post that will be upcoming very soon!
So, for the moment, I have found a place I feel very comfortable with in the community, doing demos and presentations about WebVR or "Mixed Reality" (still need to dig into AR but I don't have fitting hardware for that yet) as well as giving people and overview of the Emerging Technologies "we" (MoCo and the Mozilla community) are bringing to the web, and trying to make people excited and use the technologies or hopefully even contribute to them. Being at the forefront of innovation for once feels really good, I hope it lasts long!
Hello, Internet! Here we are with yet another Firefox Performance Update for your consumption. Hold onto your hats – we’re going in!
But first a word from our sponsor: ScriptPreloader!
A lot of the Firefox front-end is written using JavaScript. With the possible exception of system add-ons that update outside of the normal release cycle, these scripts tend to be the same until you update.
About a year ago, Mozilla developer Kris Maglione had an idea: let’s try to optimize browser start time by noticing which scripts are being loaded during start-up, and then converting those scripts into a binary representation1 that we can cache on disk. That way, next time we start up, we can just grab the cached binaries off of the disk, skip the parsing step and start executing the JavaScript right away.
Long-time Mozillians might know that we already do some aggressive caching to improve start time for things like XUL, XBL, manifests and other things that are read at start-up. I think we actually were already caching JavaScript files too – but I don’t think we were storing them pre-parsed. And the old caching stuff was definitely not caching scripts that were loading in content processes (since content processes didn’t exist when the old caching stuff was designed).
At any rate, my understanding is that the ScriptPreloader pays attention to script loads between main process start and the point where the first browser window fires the “browser-delayed-startup-finished” observer notification (after the window paints and does post-painting script loading). At that point, the ScriptPreloader examines the list of scripts that the parent and content processes have loaded, and2 writes their pre-parsed bytecode representation to disk.
After that cache is written, the next time the main process or content processes start up, the cache is checked for the binary data. If it exists, this means that we can skip the parsing step. The ScriptPreloader goes one step further and starts to “decode”3 that binary format off of the main thread, even before those scripts are requested. Then, when the scripts are finally requested, they’re very much ready to execute right away.
I’m now working on a series of patches in this bug that will widen the window of time where we note scripts that we can cache. This will hopefully improve the speed of privileged scripts that run up until the idle point of the first browser window.
And now for some Performance Project updates!
Early first blank paint (lead by Florian Quèze)
User Research has hired a contractor to perform a study to validate our hypothesis that the early first blank paint perceived performance optimization will make Firefox seem like it’s starting faster. More data to come out of that soon!
Faster content process start-up time (lead by Felipe Gomes)
The patchesthatFelipe wrote a few weeks back have landed and have had a positive impact! The proof is in the pudding – let’s look at some graphs:
The cpstartup impact. Those two clusters are test runs “before” and “after” Felipe’s patches landed, respectively.
The above graph shows a nice drop in the cpstartup Talos test. The cpstartup test measures the time it takes to boot up the content process and have it be ready to show you web pages.
This is a screen capture of a Base Content JS improvement in the AreWeSlimYet test. This graph measures the amount of memory that content processes consume via JavaScript not long after starting up.
In the graph above, we can see that the patches also helped reduce the memory that content processes use by default, by making more scripts only load when they’re needed.
It’s always nice to see our work have an impact in our graphs. Great work, Felipe! Keep it up!
The good news is that it appears that this has had a significant and positive impact on tab switch times – tab switch times went down, and the number of Nightly instances reporting tab switch spinners went down by about 10%. Great work, Doug!
A numberofbugswere filed against the original bug due to some glitchy edge-cases that we don’t handle well just yet.
We also detected a ~8% resident memory regression in our automated testing suites. This was expected (keeping layers around isn’t free!) and gave us a sense of how much memory we might consume were we to enable this by default.
The experiment is concluded for now, and we’re going to disable the cache for a bit while we think about ways to improve the implementation.
ClientStorageTextureSource for macOS (lead by Doug Thayer)
Swapping DataURLs for Blobs in Activity Stream (lead by Jay Lim)
Jay’s patch to swap out DataURLs for Blobs for Activity Stream images has passed a first round of review from Mardak! He’s now waiting for a second review from k88hudson, and then hopefully this can land and give us a bit of a memory win. Having done some analysis, we expect this buy back quite a bit of memory that was being contained within those long DataURL strings.
Caching Activity Stream JS in the JS Bytecode Cache (lead by Jay Lim)
After examining the JavaScript Bytecode Cache that’s used for Web Content, Jay has determined that it’s really not the right mechanism for caching the Activity Steam scripts.
However, that ScriptPreloader that I was talking about earlier sounds like a much more reasonable candidate. Jay is now doing a deep dive on the ScriptPreloader to see whether or not the Activity Stream scripts are already being cached – and if not, why not.
Tab warming (lead by Mike Conley)
No news is good news here. Tab warming continues to ride and no new bugs have been filed. The work to reduce the number of paints when warming tabs has stalled a bit while I dealt with a rather strange cpstartup Talos regression. Ultimately, I think I can get rid of the second paint when warming by keeping background tabs display port suppressed4, and then only triggering the display port unsuppression after a tab switch. This will happily take advantage of a painting mechanism that Doug Thayer put in as part of the LRU cache experiment.
Firefox’s Most Wanted: Performance Wins (lead by YOU!)
Before we go into the grab-bag list of performance-related fixes – have you seen any patches landing that should positively impact Firefox’s performance? Let me know about it so I can include it in the list, and give appropriate shout-outs to all of the great work going on! That link again!
Grab-bag time
And now, without further ado, a list of performance work that took place in the tree:
Ryan Hunt made it so that paint threads (see Off Main Thread Painting) no longer block Display List and Frame Layer building. This means we can get more done before offloading instructions to the paint threads, and this gives paint threads more time to finish up their work, increasing the probability that they’ll be free by the time the transaction to the paint thread needs to take place.
This is an optimization that we do that shrinks the painted area to just the region that’s visible to the browser. We normally paint a bit outside the viewable area so that it’s ready when a user starts scrolling ↩
We’ve just released a new Thunderbird Conversations (previously know as Gmail Conversation View) with full support for Thunderbird 52. We’re sorry for the delay, but the good news is it should now work fine.
I’d like to thank Jonathan for letting me help out with the release process, and for all those who contributed to release or filed issues.
The add-on should work with the current Thunderbird Beta versions (56), but won’t currently work in Daily (57) due to some compatibility issues. We’re hoping to get those resolved in the next week or so.
If you want to help out with future releases, then find the source code here and come and help us with supporting users or fixing issues.
On Monday, I, along with several million other people, decided to view the Great American Eclipse. Since I presently live in Urbana, IL, that meant getting in my car and driving down I-57 towards Carbondale. This route is also what people from Chicago or Milwaukee would have taken, which means traffic was heavy. I ended up leaving around 5:45 AM, which puts me around the last clutch of people leaving.
Our original destination was Goreville, IL (specifically, Ferne Clyffe State Park), but some people who arrived earlier got dissatisfied with the predicted cloudy forecast, so we moved the destination out to Cerulean, KY, which meant I ended up arriving around 11:00 AM, not much time before the partial eclipse started.
Partial eclipses are neat, but they're very much a see-them-once affair. When the moon first entered the sun, you get a flurry of activity as everyone puts on the glasses, sees it, and then retreats back into the shade (it was 90°F, not at all comfortable in the sun). Then the temperature starts to drop—is that the eclipse, or this breeze that started up? As more and more gets covered, then it starts to dim: I had the impression that a cloud had just passed in front of the sun, and I wanted to turn and look at that non-existent cloud. And as the sun really gets covered, then trees start acting as pinhole cameras and the shadows take on a distinctive scalloped pattern.
A total eclipse though? Completely different. The immediate reaction of everyone in the group was to start planning to see the 2024 eclipse. For those of us who spent 10, 15, 20 hours trying to see 2-3 minutes of glory, the sentiment was not only that it was time well spent, but that it was worth doing again. If you missed the 2017 eclipse and are able to see the 2024 eclipse, I urge you to do so. Words and pictures simply do not do it justice.
What is the eclipse like? In the last seconds of partiality, everyone has their eyes, eclipse glasses on of course, staring at the sun. The thin crescent looks first like a side picture of an eyeball. As the time ticks by, the tendrils of orange slowly diminish until nothing can be seen—totality. Cries come out that it's safe to take the glasses off, but everyone is ripping them off anyways. Out come the camera phones, trying to capture that captivating image. That not-quite-perfect disk of black, floating in a sea of bright white wisps of the corona, not so much a circle as a stretched oval. For those who were quick enough, the Baily's beads can be seen. The photos, of course, are crap: the corona is still bright enough to blot out the dark disk of the moon.
Then, our attention is drawn away from the sun. It's cold. It's suddenly cold; the last moment of totality makes a huge difference. Probably something like 20°F off the normal high in that moment? Of course, it's dark. Not midnight, all-you-see-are-stars dark; it's more like a dusk dark. But unlike normal dusk, you can see the fringes of daylight in all directions. You can see some stars (or maybe that's just Venus; astronomy is not my strong suit), and of course a few planes are in the sky. One of them is just a moving, blinking light in the distance; another (chasing the eclipse?) is clearly visible with its contrail. And the silence. You don't notice the usual cacophony of sounds most of the time, but when everyone shushes for a moment, you hear the deafening silence of insects, of birds, of everything.
Naturally, we all point back to the total eclipse and stare at it for most of the short time. Everything else is just a distraction, after all. How long do we have? A minute. Still more time for staring. A running commentary on everything I've mentioned, all while that neck is craned skyward and away from the people you're talking to. When is it no longer safe to keep looking? Is it still safe—no orange in the eclipse glasses, should still be fine. How long do we need to look at the sun to damage our eyes? Have we done that already? Are the glasses themselves safe? As the moon moves off the sun, hold that stare until that last possible moment, catch the return of the Baily's beads. A bright spark of sun, the photosphere is made visible again, and then clamp the eyes shut as hard as possible while you fumble the glasses back on to confirm that orange is once again visible.
Finally, the rush out of town. There's a reason why everyone leaves after totality is over. Partial eclipses really aren't worth seeing twice, and we just saw one not five minutes ago. It's just the same thing in reverse. (And it's nice to get back in the car before the temperature gets warm again; my dark grey car was quite cool to the touch despite sitting in the sun for 2½ hours). Forget trying to beat the traffic; you've got a 5-hour drive ahead of you anyways, and the traffic is going to keep pouring onto the roads over the next several hours anyways (10 hours later, as I write this, the traffic is still bad on the eclipse exit routes). If you want to avoid it, you have to plan your route away from it instead.
I ended up using this route to get back, taking 5 hours 41 minutes and 51 seconds including a refueling stop and a bathroom break. So I don't know how bad I-57 was (I did hear there was a crash on I-57 pretty much just before I got on the road, but I didn't know that at the time), although I did see that I-69 was completely stopped when I crossed it. There were small slowdowns on the major Illinois state roads every time there was a stop sign that could have been mitigated by sitting police cars at those intersections and effectively temporarily signalizing them, but other than that, my trip home was free-flowing at speed limit the entire route.
Some things I've learned:
It's useful to have a GPS that doesn't require cellphone coverage to figure out your route.
It's useful to have paper maps to help plan a trip that's taking you well off the beaten path.
It's even more useful to have paper maps of the states you're in when doing that.
The Ohio River is much prettier near Cairo, IL than it is near Wheeling, WV.
The Tennessee River dam is also pretty.
Driving directions need to make the "I'm trying to avoid anything that smells like a freeway because it's going to be completely packed and impassable" mode easier to access.
Passing a car by crossing the broken yellow median will never not be scary.
Being passed by a car crossing the broken yellow median is still scary.
Driving on obscure Kentucky state roads while you're playing music is oddly peaceful and relaxing.
The best test for road hypnosis is seeing how you can drive a long, straight, flat, featureless road. You have not seen a long, straight, flat, featureless road until you've driven something like an obscure Illinois county road where the "long, straight" bit means "20 miles without even a hint of a curve" and the "featureless" means "you don't even see a house, shed, barn, or grain elevator to break up corn and soy fields." Interstates break up the straight bit a lot, and state highways tend to have lots of houses and small settlements on them that break up endless farm fields.
Police direction may not permit you to make your intended route work.














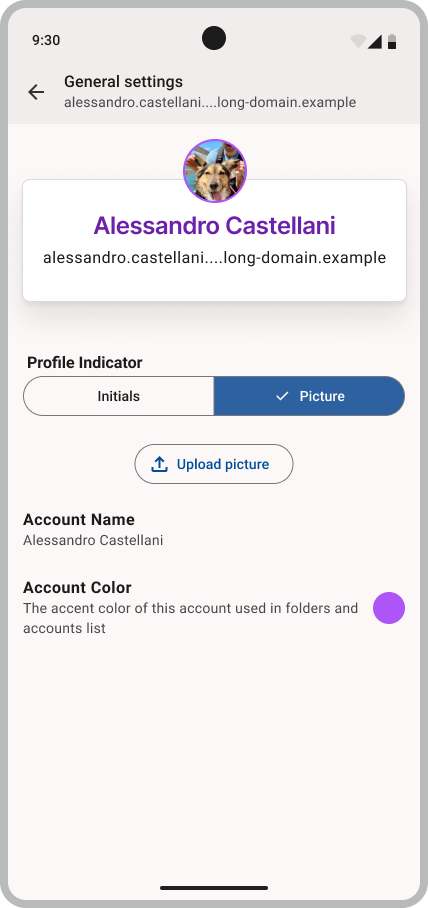
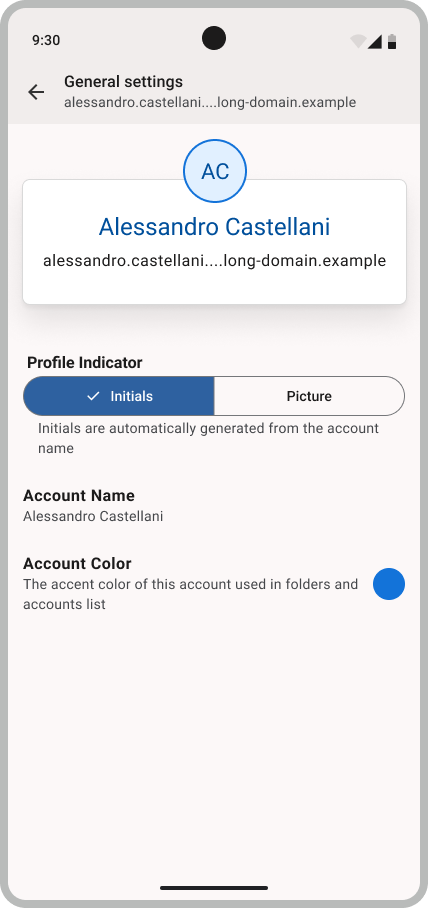






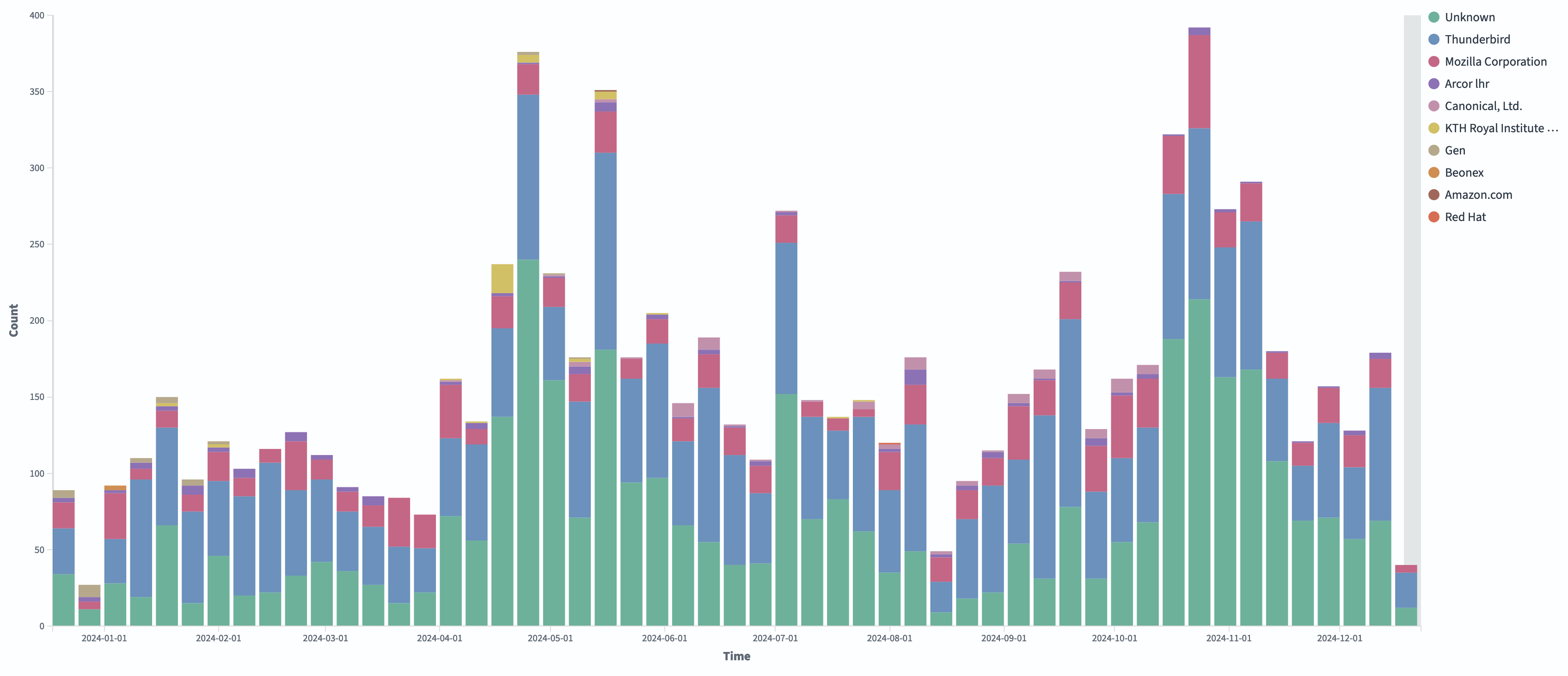
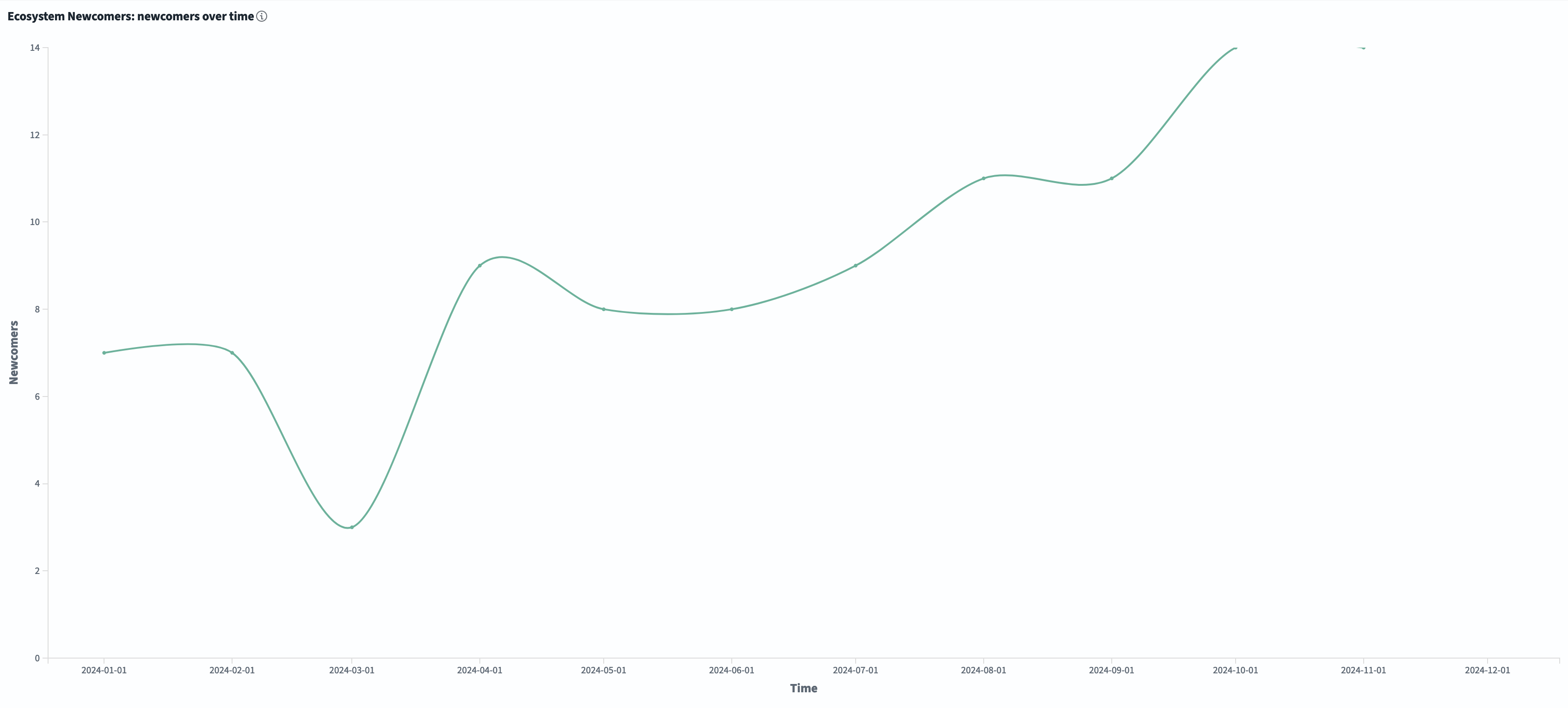
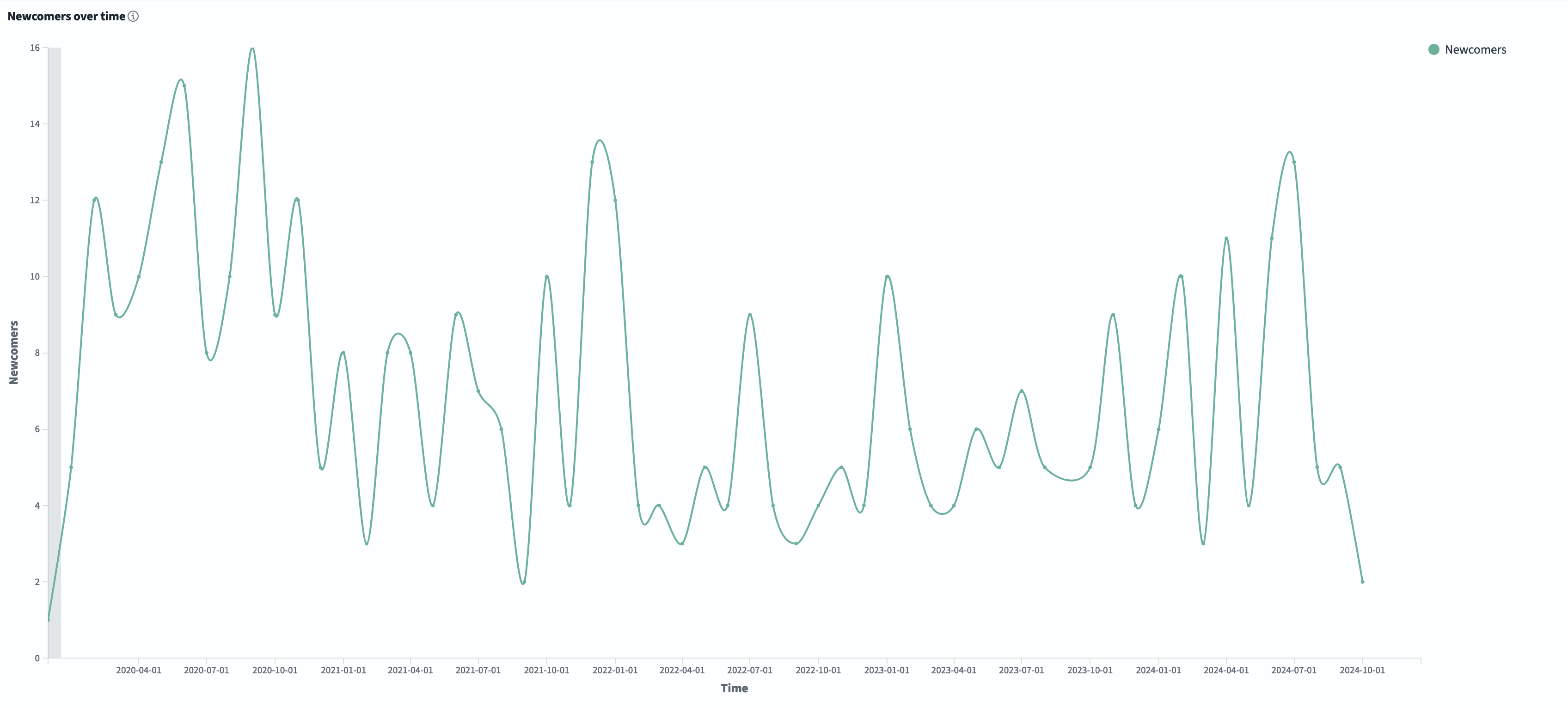
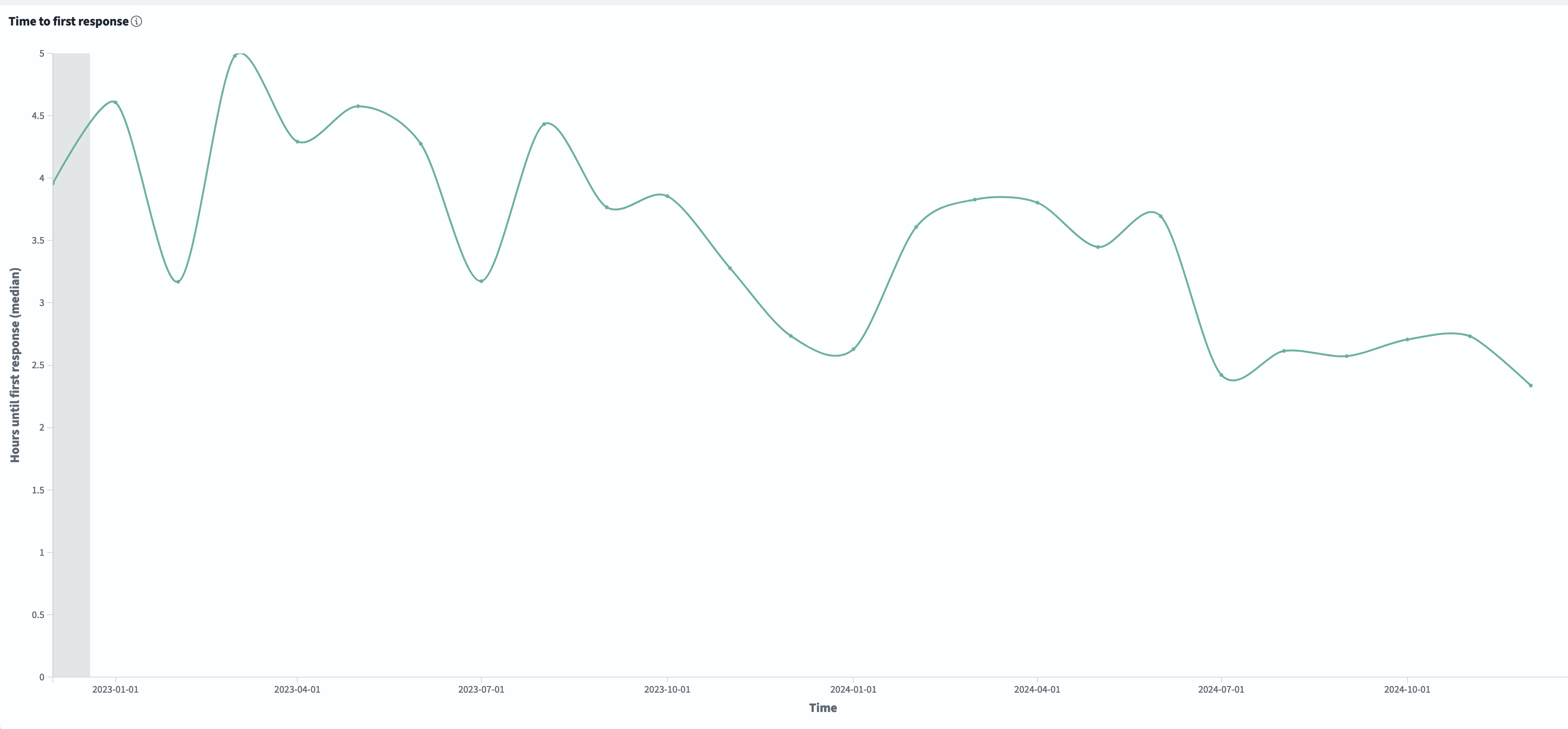
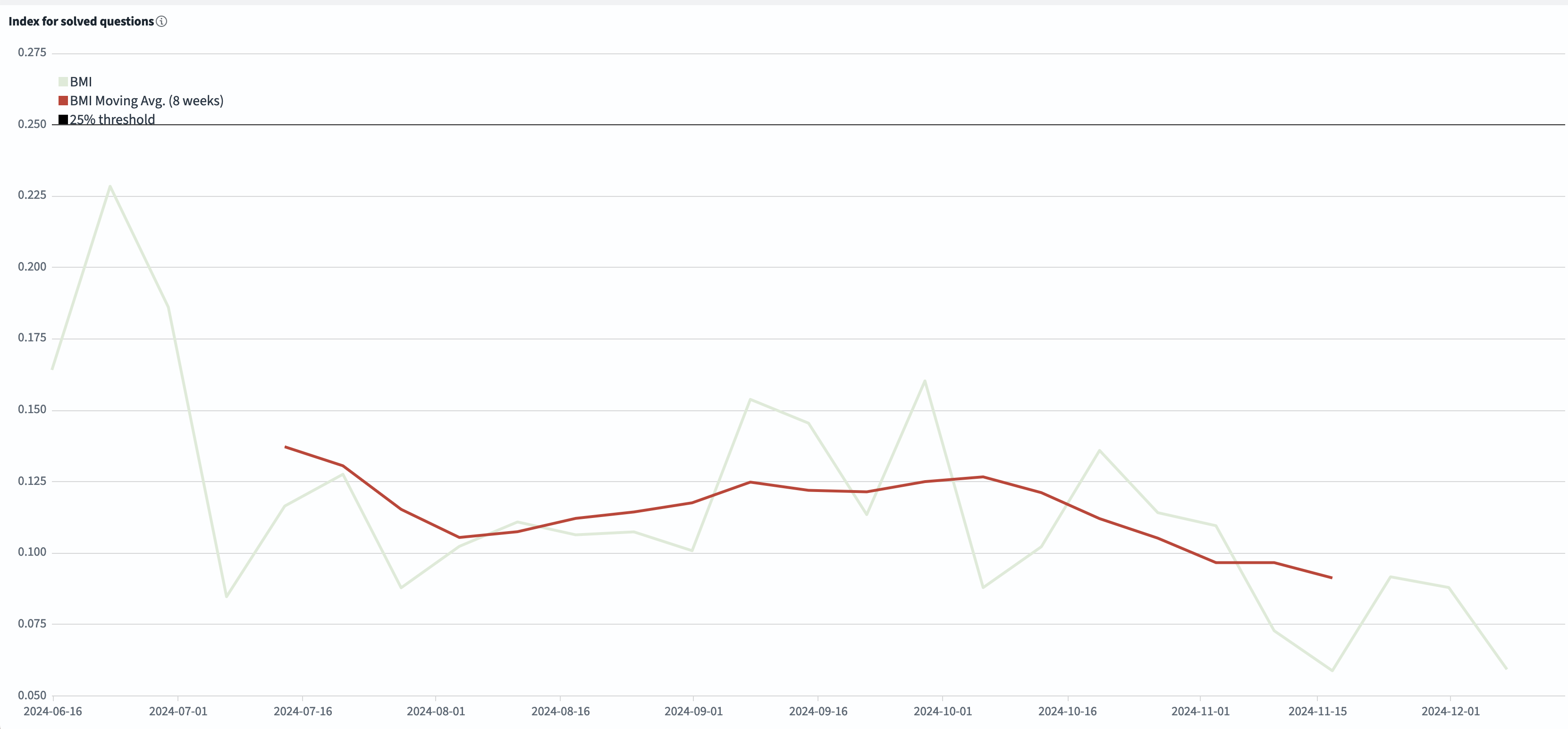








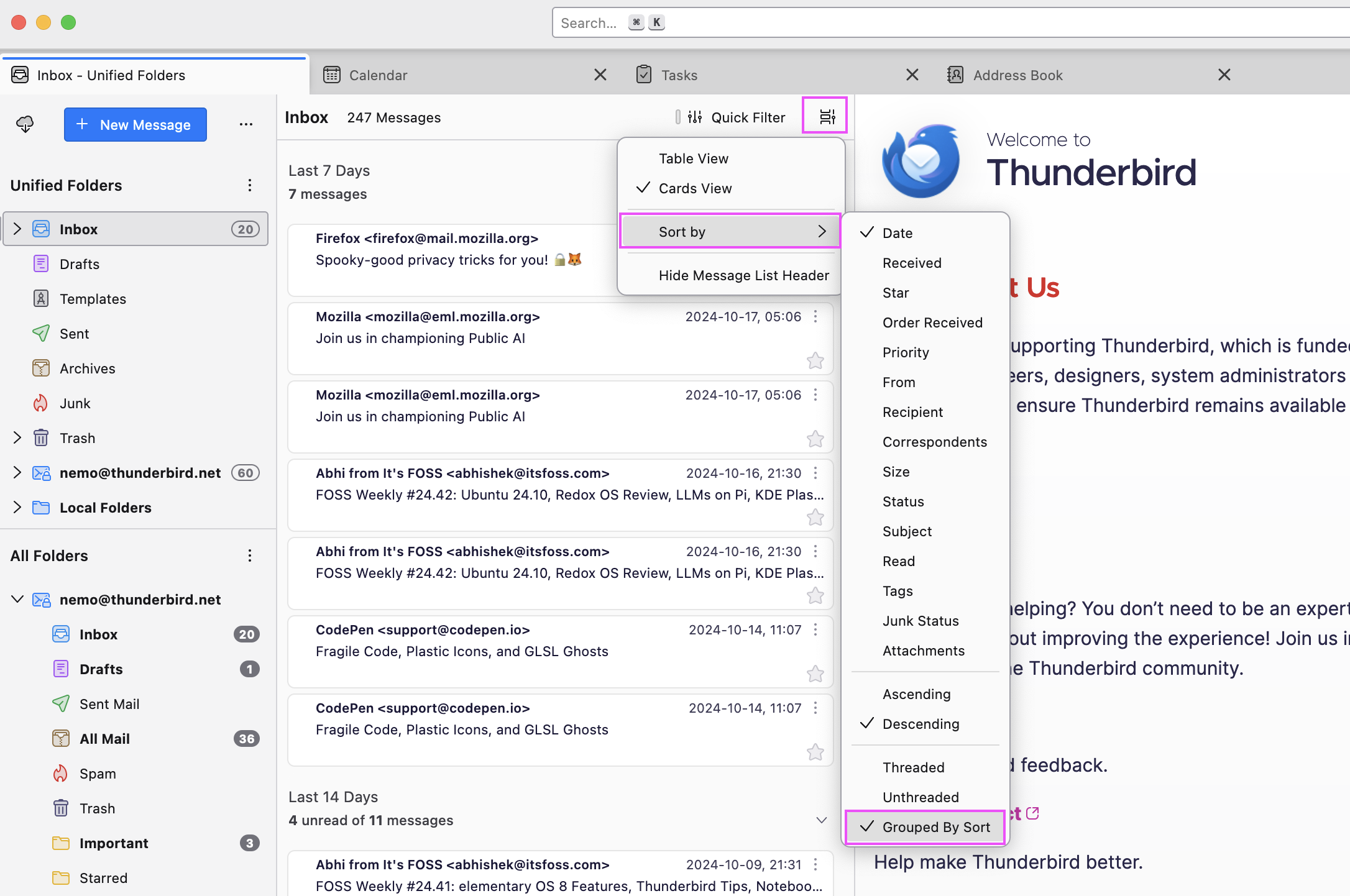









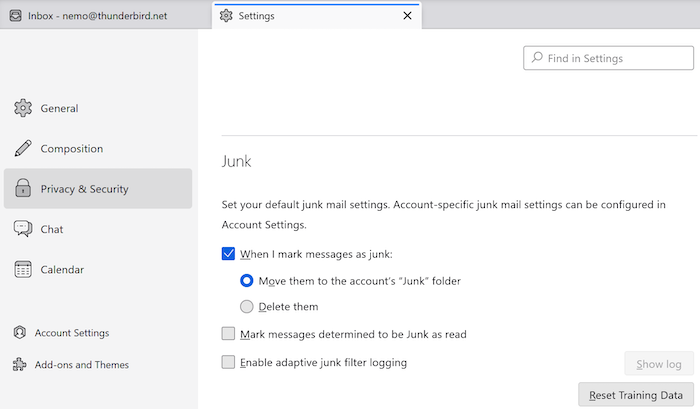
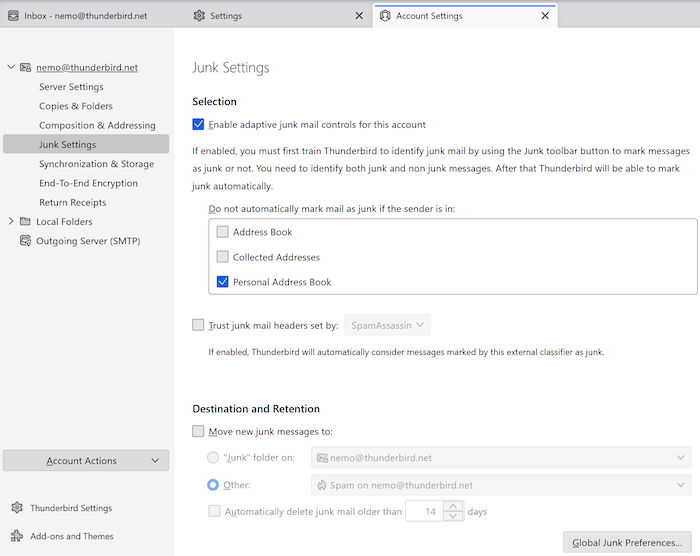







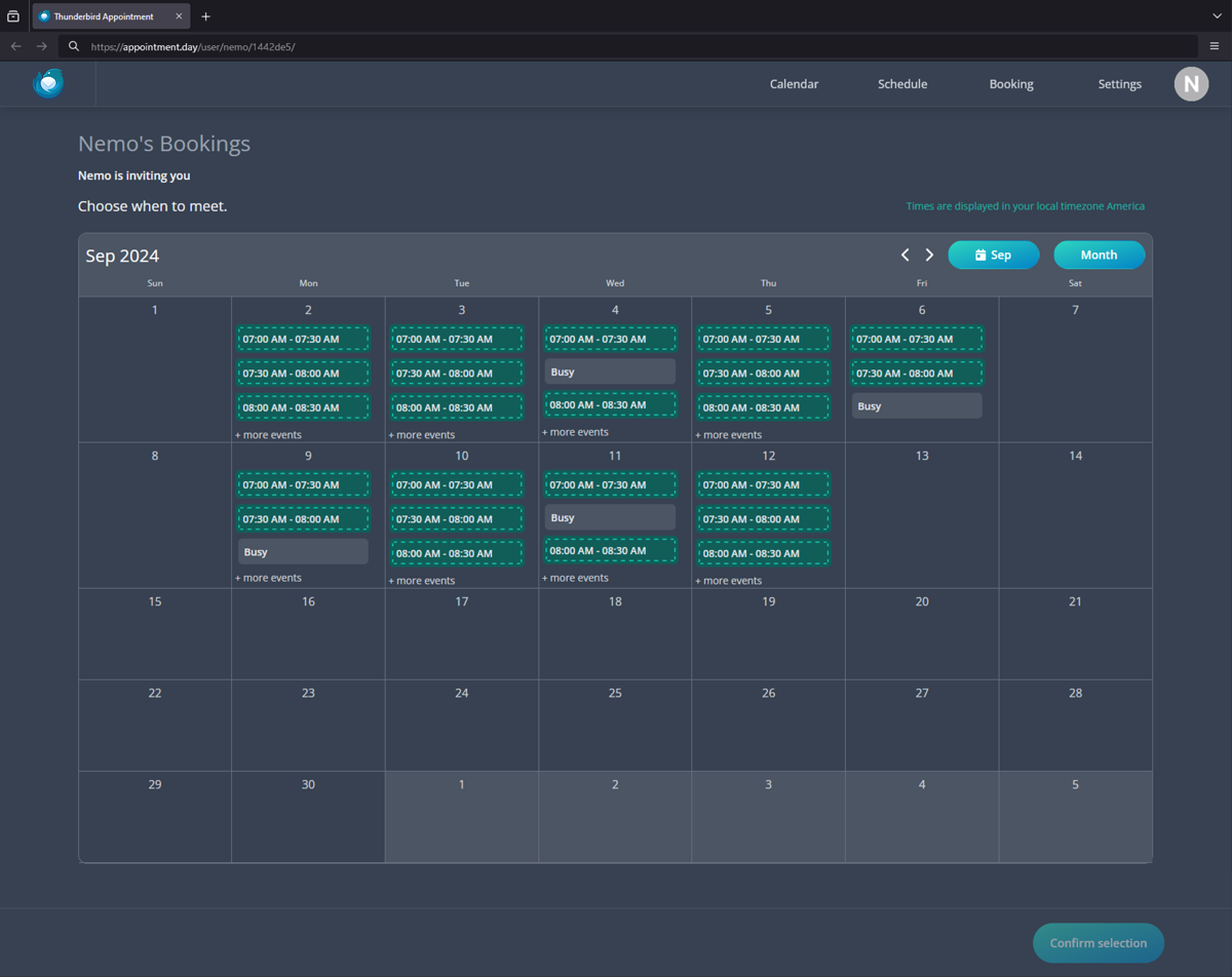
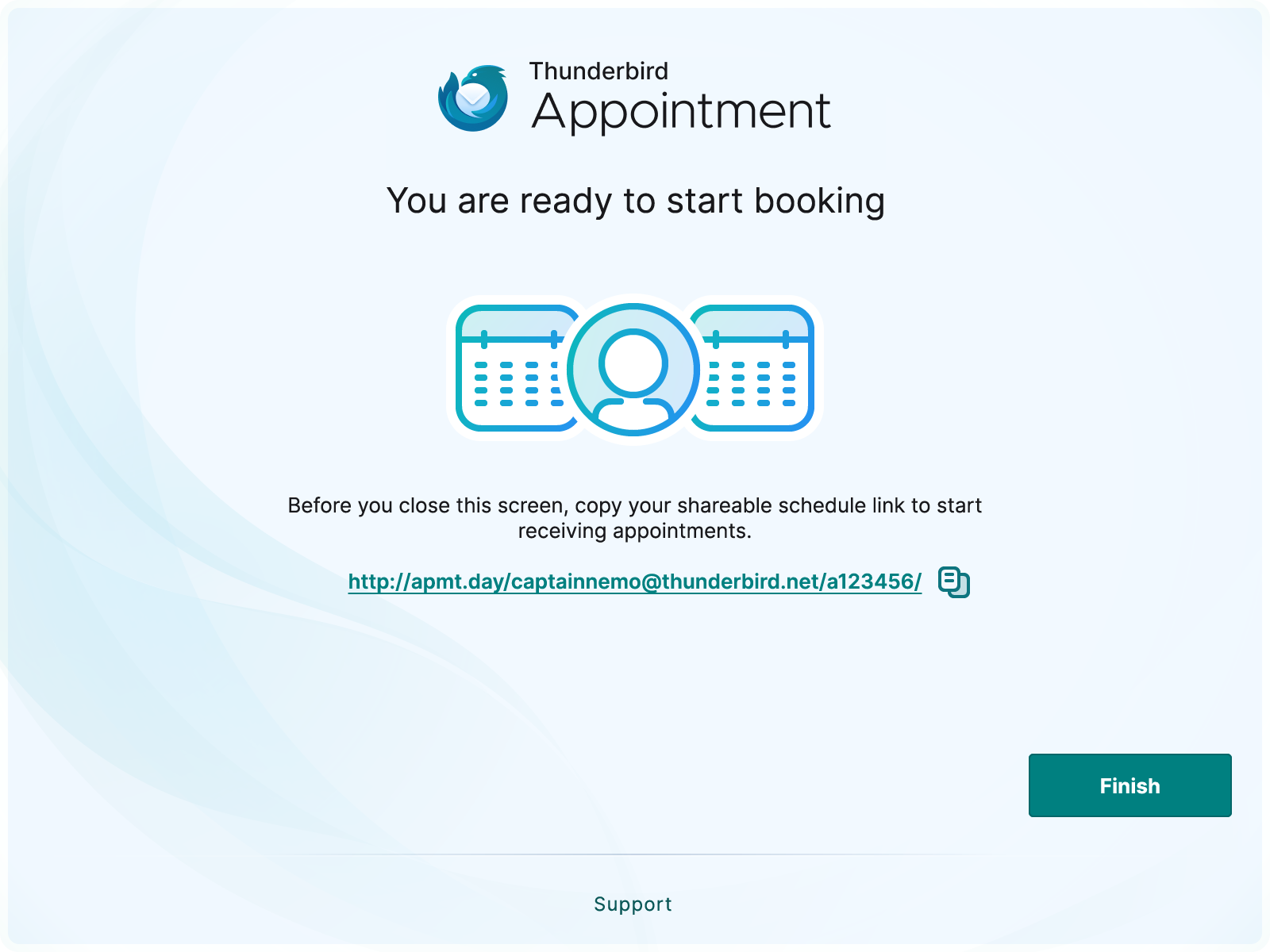
















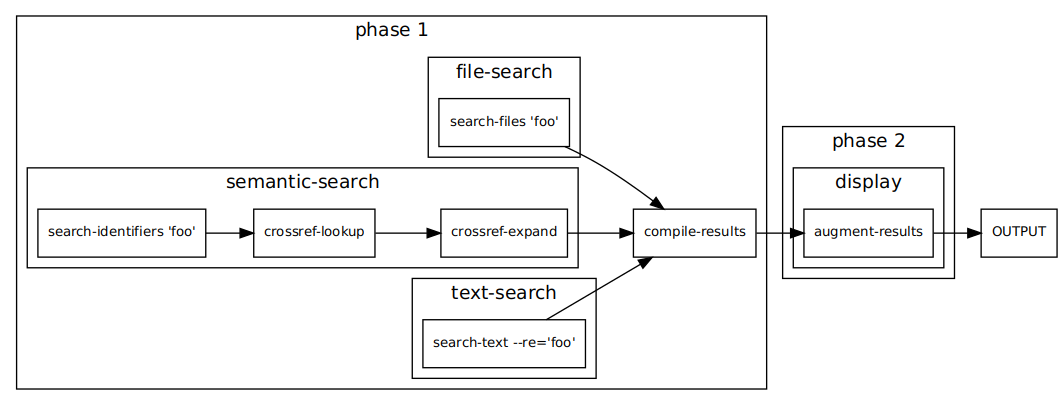




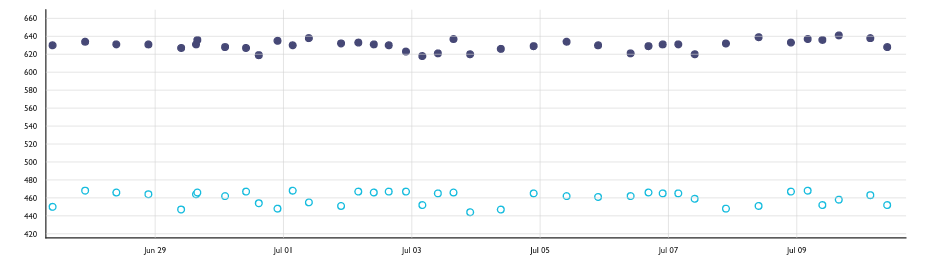
 <figcaption>Conversations’ threaded message layout</figcaption>
<figcaption>Conversations’ threaded message layout</figcaption> <figcaption>Message Controls Menu</figcaption>
<figcaption>Message Controls Menu</figcaption> <figcaption>Attachment preview area with gallery view available for images.</figcaption>
<figcaption>Attachment preview area with gallery view available for images.</figcaption> <figcaption>There are several of those circles stacked on top of one another, and several of those arms in between them. We’re only seeing the top one in this photo.</figcaption>
<figcaption>There are several of those circles stacked on top of one another, and several of those arms in between them. We’re only seeing the top one in this photo.</figcaption> <figcaption>Vinyl’s back, baby!</figcaption>
<figcaption>Vinyl’s back, baby!</figcaption>
 <figcaption>This graph measures various start-up metrics. The scatter of datapoints on the left show the “control” build, and they tighten up on the right with the “test” build. Lower is better.
<figcaption>This graph measures various start-up metrics. The scatter of datapoints on the left show the “control” build, and they tighten up on the right with the “test” build. Lower is better. <figcaption>This graph measures the time at which the browser window reports that it has first painted. April 14th is the second last date on the X axis, and the Y axis is time. The top-most line is plotting the 95th percentile, and there’s a nice dip appearing around April 14th.
<figcaption>This graph measures the time at which the browser window reports that it has first painted. April 14th is the second last date on the X axis, and the Y axis is time. The top-most line is plotting the 95th percentile, and there’s a nice dip appearing around April 14th. <figcaption>This is a graph of the ts_paint startup paint Talos benchmark. The highlighted node is the first mozilla-central build with the hidden window work. Lower is better, so this looks like a nice win!</figcaption>
<figcaption>This is a graph of the ts_paint startup paint Talos benchmark. The highlighted node is the first mozilla-central build with the hidden window work. Lower is better, so this looks like a nice win!</figcaption> <figcaption>The four on the left are Firefox Nightly, and the four on the right are Google Chrome (71.0.3578.98)</figcaption>
<figcaption>The four on the left are Firefox Nightly, and the four on the right are Google Chrome (71.0.3578.98)</figcaption>
 indicates a volunteer contributor)
indicates a volunteer contributor)