I recently noticed the following message in Sentry’s pip installation step:
Using legacy ‘setup.py install’ for openapi-core, since package ‘wheel’ is not installed.
Upon some investigation, I noticed that the package wheel was not being installed. After making some changes, I can now guarantee that our development environment installs it by default and it’s given us about 40–50% speed gain.
Timings from before and after installing wheel
The screenshot above shows the steps from two different Github workflows; it installs Sentry’s Python packages inside of a fresh virtualenv and the pip cache is available.
If you see a message saying that wheelpackage is not installed, make sure to attend to it!
Soon after Big Sur came out, I received my new work laptop. I decided to upgrade to it. Unfortunately, I quickly discovered that the Python set up needed for Sentry required some changes. Since it took me a bit of time to figure it out I decided to document it for anyone trying to solve the same problem.
If you are curious about all that I went through and see references to upstream issues you can visit this issue. It’s a bit raw. Most important notes are in the first comment.
On Big Sur, if you try to install older versions of Python you will need to tell pyenv to patch the code. For instance, you can install Python 3.8.7 the typical way ( pyenv install 3.8.7 ), however, if you try to install 3.8.0, or earlier, you will have to patch the code before building Python.
I’m happy to announce that at the end of 2020 I joined Sentry.io as their second Developer Productivity engineer \o/
Screenshot from Sentry.io landing page
I’m excited to say that it’s been a great fit and that I can make use of most of the knowledge I’ve gained in the last few years. I like the ambition of the company and that they like to make work fun.
So far, I have been able to help to migrate to Python 3, enabled engineers to bootstrap their Python installation on Big Sur, migrated some CI from Travis to Github actions amongst many other projects.
If you ship software, I highly recommend you trying Sentry as part of your arsenal of tools to track errors and app performance. I used Sentry for many years at Mozilla and it was of great help!
If you are interested in joining Sentry please visit the careers page.
The summer of 2020 marked the end of 12 years of working for Mozilla. My career with Mozilla began with an internship during the summer of 2008 when I worked from Building K in 1981 Landings Drive, Mountain View, CA.
One of the two buildings Mozilla used at Landings Drive
Writing this post is hard since Mozilla was such a great place to work at, not only for its altruistic mission, but mostly because of the fantastic people I met during my time there.
I’m eternally grateful to my Lord Jesus Christ, Who placed me in a workplace where I could grow so much, both as a person and as an engineer.
Photo taken during the Release Engineering work week (Pre-internship)
I can count dozens of Mozillians I’ve talked and laughed with over the years. I could try unsuccessfully to list each and every one, however I believe it’s better to simply say that I’ve enjoyed every moment with each one of you.
It’s been a long time since I’ve spoken with many of you and some of you I may never get the chance to talk with again. Nevertheless, if you ever see me somewhere online, please be sure to say hi. I would love to hear from you.
Presentation slide from London All Hands
Mozilla, thank you for the opportunity to help further your mission. I wish you success in 2021 and beyond.
After 15 years, today is my final working day at Mozilla.
When people leave Mozilla, they frequently exercise their privilege to send one final email to the entire company saying goodbye. I’ve elected not to do that and am instead posting my thoughts here. Call it hubris, but there aren’t many people left at Mozilla who can appreciate what 15 years means. Most of my colleagues have already moved on.
2020 has been hard. Layoffs at Mozilla, and the threat of more layoffs, made this a particularly rough year. As a manager, putting on a brave face for others has left me emotionally spent at the end of every week. This is on top of the malaise associated with a decade of declining market share (and associated relevance) for Firefox.
As I reach the end of my tenure at Mozilla, inevitably I look back to try to figure out what I could have done differently to make Mozilla more successful. Did I miss a window of opportunity somewhere to help Firefox succeed? Might this year have been avoided, or its impact softened?
In broad strokes, sure, I could have worked longer or harder, pushed to get projects completed faster or to a higher standard. More specifically, if we had accelerated our transition from tinderbox to buildbot, or from buildbot to Taskcluster, could we have kept better pace with competitors? Maybe we could have recognized the scaling needs sooner and avoided migrating our entire continuous integration infrastructure twice?
The safe answer is that, yes, there are many things I could have done differently, but hindsight is also 20/20.
When I started this reminiscence, I felt like maybe my impact had decreased over time. It was tempting to think that my influence peaked back in 2005 when it was just 25 of us hacking together on Firefox under the Can Bridge in Ellis St.
But that’s absolutely not true.
Mozilla, at its core, is about people. The manifesto is an invitation. This is a long game; the changes that Mozilla wants to affect in the world aren’t best measured in quarterly earnings reports.
As a manager at Mozilla, I’ve had the opportunty to hire dozens of people. I’ve helped interns develop into kick-ass engineers. I’ve touched the careers of countless people and hopefully instilled some fundamental values along the way. Many of those people are no longer with Mozilla. This is a good thing, both for them and for Mozilla.
The world needs more Mozilla. In an industry largely bereft of introspection and in many cases lacking a moral compass, the Mozilla diaspora has some serious work to do. At the end of the day, if all I’ve done is helped spread Mozilla values out into the wider world, I’m happy with that legacy.
Mozilla has gone through big changes this year. I don’t know if those changes are enough for it to be successful, but I am hopeful. As part of the old guard, I am happy to step aside at this juncture to create space and opportunity for the new guard in my stead.
I’m starting a new adventure as a Senior Development Manager at Unity in January. I’ll be taking my Mozilla values with me.
My team at Mozilla has been working towards something special for over two years.
When I joined the team, we felt that we had a pretty good internal product in Taskcluster, the task execution framework that supports Mozilla’s continuous integration (CI) and release processes. It served Mozilla’s CI needs well, and was scaling admirably compared to previous solutions.
But could it be more?
Would people outside of Mozilla benefit from Taskcluster, and could they deploy it? Perhaps more importantly, could we develop a community of users around Taskcluster that would be self-sustaining?
We were determined to find out.
We started by taking a hard look at the Taskcluster platform and found a few big impediments to wider adoption. First, we would need to reduce the setup complexity. We would also need to reduce the number of cloud accounts required to get started. At the time, Taskcluster required at least two separate cloud providers (AWS and Azure) and a Heroku account to launch.
Over the past year, we removed the need for Azure as a back-end data store and removed the need for Heroku for deployments. Now if you have a Kubernetes environment setup, you’re ready to install Taskcluster. You’ll still need AWS S3 access for artifact storage, but we’re working to make that configurable too.
While we were making all these changes behind the scenes, we were thinking about how we would actually try to garner more interest in Taskcluster outside of Mozilla. In true Mozilla fashion, we have always been developing Taskcluster in the open, but that doesn’t necessarily mean we were discoverable. How could we specifically target the kinds of users who would benefit the most from Taskcluster?
Out of the blue in August, a developer from a mobile game company contacted us to let us know that she had successfully deployed Taskcluster, and had a few suggestions for improvements, complete with patches.
Just like that, Taskcluster was in the wild.
Is Taskcluster right for you?
From talking with Ricky, the co-founder and principal programmer at Well Played Games who was the first to successfully deploy Taskcluster outside Mozilla, we learned a lot about the decision points that might lead someone to choose Taskcluster:
Taskcluster has given us more flexibility than any of the CI solutions we’ve used in the past. It is well engineered, letting us easily pick and choose the components we need, and quickly replace any that don’t suit our use cases. Its native support for Kubernetes meshes perfectly with our tech stack.Ricky Taylor, Co-Founder, Well Played Games
So, is Taskcluster right for you? The short answer is “maybe.”
If your build and test pipeline is straightforward, there are simpler solutions out there for you. If you only support one platform, there is probably a more targetted solution for your use case.
However, if your CI needs are more complex, Taskcluster may be exactly what you need.
Here are some examples of use cases where Taskcluster might make sense for you:
You already have a person or team of people dedicated to your CI pipeline.
You currently support >1 CI system, probably for different platforms.
You have on-premise or custom hardware that you need to integrate into your CI pipeline.
Your current CI system is hitting a bottleneck or ceiling.
You are considering writing your own bespoke CI system to address any of the above concerns.
All of those are pretty good indications of CI complexity in our experience.
We’ve adopted “CI for Engineers” as the tagline for Taskcluster. Taskcluster will not solve your CI problems on it’s own, out-of-the-box, but a software engineer who understands your CI needs can make it do just about anything.
Better still, your software engineer doesn’t have to go it alone. We’re already building a community of Taskcluster users who can offer support to each other. Ricky from Well Played Games has already contributed new features that have been incorporated into Taskcluster and consulted on others.
If Taskcluster seems like a good fit for your CI needs, we encourage you to join other Taskcluster users and developers in Matrix or in Discourse.
If you’d like to investigate a live instance, the Mozilla Taskcluster deployment for community projects can be found here (no sign-in required): https://community-tc.services.mozilla.com/
One of my biggest challenges when I began managing the Taskcluster team was simply getting my reports to talk to each other in a productive way. Per Conway’s Law, the micro-service architecture of Taskcluster reflected the knowledge silos on the team. Communication was erratic at best. Fortunately, transitions offer an ideal opportunity to establish norms, revisit old ways of work, and perhaps even try something new.
Following the lead of a colleague, at the start of my tenure I sat my new team down for an entire day and hashed out the communications issues. What emerged at the end of that discussion was a document that recorded all the expectations we had for each other as teammates. The document was part aspiration and part contract, but was essential for establishing a baseline of trust that we could use to work together going forward.
Fast-forward to 2020, and Mozilla is going through yet another transition. As the make-up and scope of my team changes again, it is useful to revisit the expectations document to make sure everyone is still on the same page. After consulting with the team, I also decided to publish our Team Expectations doc on Github in the hopes that it might benefit others.
This is partially self-serving: the Taskcluster team has many community contributors and the occasional intern, and we hope that by sharing our expectations more widely, we’ll foster a better contribution environment around our project.
If you’re interested in performing a similar exercise with your own team, be prepared to devote the time. I’d budget at least 4 hours to this process, depending on your team’s current level of dysfunction. We had the fortune in the before times to be able to do this in-person, but a series of video calls would accomplish the same goal.
Content-wise, the headings we came up with — Accountability, Communications, Planning and The Design Process: RFCs, Implementation and Review, Triage, Dealing with outages — are a good jumping-off point for the discussion but may or may not make sense depending on your field or responsibilities. Having done the process with a few different teams now, it’s important not to over-structure this at the start. There is a lot of value here in digression because that’s where you are most likely to find the areas where expectations are currently mismatched or unmet.
If you do try out, please let me know how it went, especially if you end up evolving the process. Hopefully it meets your expectations. ;)
If you use Treeherder on repositories that are not Try, you might have used the backfill action. The backfill action takes a selected task and schedules it nine pushes back from the selected task. You can see the original work here and the follow up here.
The mda task on push 48a10a9249b0 has been backfilled
In the screenshot above you can see that the task mdaturned orange (implying that it failed). In the screenshot we can see that a Mozilla code sheriff has both retriggered the task four more times (you can see four more running tasks on the same push) and has backfilled the task on previous pushes. This is to determine if the regression was introduced on previous pushes or if the failure is due to an intermittent test failure.
Once you select a task and click on the hamburguer menu you can get to the backfill action
The difference with the old backfill action is threefold:
The backfilled tasks include -bk in their symbol and group and it includes the revision of the originating task that was backfilled
The backfilled tasks schedule the same set of manifests as the starting task
The backfill action schedules a support action called backfill-task
Modified symbol for backfilled tasks
The modified symbol and group name for backfilled tasks is to:
Show that it is a backfilled task (rather than schedule by normal scheduling) and that it can have a modified set of manifests (see next section)
Show from which task it was backfilled from (by including the revision)
Group backfilled tasks together to make it clear that they were not scheduled by normal means
I’ve also landed a change on Treeherder to handle this new naming and allow to filter out normal tasks plus backfilled tasks.
From this link you can filter out mda tasks plus mda backfilled tasks
Manifest-level backfilling
Point number two from the above list is what changes the most. Soon we will be landing a change on autoland that will schedule some test tasks with a dynamic set of manifests. This means that a task scheduled on push A will have a set of manifests (e.g. set X) and the same task on push B can have a different set of manifests (e.g. set Y).
The new backfill takes this into account by looking at the env variable MOZHARNESS_TEST_PATHS which contains the list of manifests and re-uses that value on backfilled tasks. This ensures that we’re scheduling the same set of manifests in every backfilled task.
Support actions
You can skip reading this section as this is more of an architectural change. This fixes the issue that backfilled tasks could not be re-run.
Backfilled tasks are now scheduled by a support action called backfill-task. If on Treeherder we filter by backfill tasks you can see both the initial backfillaction and the backfill-tasksupport action:
Two backfill actions were triggered on push 48a10a9249b0
The action backfill has scheduled nine backfill-task and those are in charge of scheduling the mda task on that push.
Thanks for reading. Please file a bug and CC me if you notice anything going wrong with it.
I want to highlight the process between a conversation and a deployed feature. Many times, it is an unseen part of the development process that can be useful for contributors and junior developers who are trying to grow as developers.
Back in the Fall of 2019 I started inquiring into developers’ satisfaction with Treeherder. This is one of the reasons I used to go to the office once in a while. One of these casual face-to-face conversations led to this feature. Mike Conley explained to me how he would look through various logs to find a test path that had failed on another platform (see referenced post for further details).
After I understood the idea, I tried to determine what options we had to implement it. I wrote a Google Doc with various alternative implementations and with information about what pieces were needed for a prototype. I requested feedback from various co-workers to help discover blind spots in my plans.
Once I had some feedback from immediate co-workers, I made my idea available in a Google group (increasing the circle of people giving feedback). I described my intent to implement the idea and was curious to see if anyone else was already working on it or had better ideas on how to implement it. I did this to raise awareness in larger circles, reduce duplicate efforts and learn from prior work.
I also filed a bug to drive further technical discussions and for interested parties to follow up on the work. Fortunately, around the same time Andrew Halberstadt started working on defining explicitly what manifests each task executes before the tasks are scheduled (see bug). This is a major component to make the whole feature on Treeherder functional. In some cases, talking enough about the need can enlist others from their domains of expertise to help with your project.
At the end of 2019 I had time to work on it. Once I endlessly navigated through Treeherder’s code for a few days, I decided that I wanted to see a working prototype. This would validate its value and determine if all the technichal issues had been ironed out. In a couple of days I had a working prototype. Most of the code could be copy/pasted into Treeherder once I found the correct module to make changes in.
Finally, in January the feature landed. There were some small bugs and other follow up enhancements later on.
Stumbling upon this feature was great because on H1 we started looking at changing our CI’s scheduling to use manifests for scheduling instead of tasks and this feature lines up well with it.
At the beginning of this year we landed a new feature on Treeherder. This feature helps our users to filter jobs using test paths or manifest paths.
This feature is useful for developers and code sheriffs because it permits them to determine whether or not a test that fails in one platform configuration also fails in other ones. Previously, this was difficult because certain test suites are split into multiple tasks (aka “chunks”). In the screenshot below, you can see that the manifest path devtools/client/framework/browser-toolbox/test/browser.ini is executed in different chunks.
Showing tasks that executed a specific manifest path
NOTE: A manifest is a file that defines various test files, thus, a manifest path defines a group of test paths. Both types of paths can be used to filter jobs.
This filtering method has been integrated to the existing feature, “Filter by a job field” (the funnel icon). See below what the UI looks like:
Filter by test path
If you’re curious about the work you can visit the PR.
There’s a lot more coming around this realm as we move toward manifest-based scheduling in the Firefox CI instead of task-based scheduling. Stay tuned! Until then keep calm and filter away.
In the last few months I’ve worked with contributors who wanted to be selected to work on Treeherder during this year’s Google Summer of Code. The initial proposal was to improve various Treeherder developer ergonomics (read: make Treeherder development easier). I’ve had three very active contributors that have helped to make a big difference (in alphabetical order): Shubham, Shubhank and Suyash.
In this post I would like to thank them publicly for all the work they have accomplished as well as list some of what has been accomplished. There’s also listed some work from Kyle who tackled the initial work of allowing normal Python development outside of Docker (more about this later).
After all, I won’t be participating in GSoC due to burn-out and because this project is mostly completed (thanks to our contributors!). Nevertheless, two of the contributors managed to get selected to help with Treeherder (Suyash) and Firefox Accounts (Shubham) for GSoC. Congratulations!
Some of the developer ergonomics improvements that landed this year are:
Support running Treeherder & tests outside of Docker. Thanks to Kyle we can now set up a Python virtualenv outside of Docker and interact with all dependent services (mysql, redis and rabbitmq). This is incredibly useful to run tests and the backend code outside of Docker and to help your IDE install all Python packages in order to better analyze and integrate with your code (e.g., add breakpoints from your IDE). See PR here.
Support manual ingestion of data. Before, you could only ingest data when you would set up the Pulse ingestion. This mean that you could only ingest real-time data (and all of it!) and you could not ingest data from the past. Now, you can ingest pushes, tasks and even Github PRs. See documentation.
Add pre-commit hooks to catch linting issues. Prior to this, linting issues would require you to remember to run a script with all the linters or Travis to let you know. You can now get the linters to execute automatically on modified files (instead of all files in the repo), shortening the linting-feedback cycle. See hooks in pre-commit file
Use Poetry to generate the docs. Serving locally the Treeherder docs is now as simple as running “poetry install && poetry run mkdocs serve.” No more spinning up Docker containers or creating and activating virtualenvs. We also get to introduce Poetry as a modern dependency and virtualenv manager. See code in pyproject.toml file
Automatic syntax formatting. The black pre-commit hook now formats files that the developer touches. No need to fix the syntax after Travis fails with linting issues.
Ability to run the same tests as Travis locally. In order to reduce differences between what Travis tests remotely and what we test locally, we introduced tox. The Travis code simplifies, the tox code can even automate starting the Docker containers and it removed a bash script that was trying to do what tox does (Windows users cannot execute bash scripts).
Share Pulse credentials with random queue names. In the past we required users to set up an account with Pulse Guardian and generate their own PULSE_URL in order to ingest data. Last year, Dustin gave me the idea that we can share Pulse credentials; however, each consumer must ingest from dynamically generated queue names. This was initially added to support Heroku Review Apps, however, this works as well for local consumers. This means that a developer ingesting data would not be taking away Pulse messages from the queue of another developer.
Automatically delete Pulse queues. Since we started using shared credentials with random queue names, every time a developer started ingesting data locally it would leave some queues behind in Pulse. When the local consumers stopped, these queues would overgrow and send my team and I alerts about it. With this change, the queues would automatically be destroyed when the consumers ceased to consume.
Docker set up to automatically ingest data. This is useful since ingesting data locally required various steps in order to make it work. Now, the Docker set up ingests data without manual intervention.
Use pip-compile to generate requirement files with hashes. Before, when we needed to update or add a Python package, we also had to add the hashes manually. With pip-compile, we can generate the requirement files with all hashes and subdepencies automatically. You can see the documentation here.
There’s many more changes that got fixed by our contributors, however, I won’t cover all of them. You can see the complete list in here.
Thank you for reading this far and thanks again to our contributors for making development on Treeherder easier!
For over a decade Mozilla has been using IRC to publicly chat with anyone interested to join the community. Recently, we’ve launched a replacement for it by creating a Mozilla community Matrix instance. I will be focusing on simply documenting what the process looks like to join in as a community member (without an LDAP account/Mozilla email address). For the background of the process you can read it here. Follow along the photos and what each caption says.
This is the landing page. Read the participation guideline and click on the “Sign In” buttonFollow the sign-in button. If none of the listed options in the next page works for you come back try “Create account”Use one of the listed services or go back and create an account. Use the email address field only if you have an LDAP account (generally a Mozilla email address)After you sign in you will get a system alert. You will need to accept the Privacy Notice and Terms and Conditions before you can use the serviceUse the “Explore” button to find the room you’re interested in
If you have managed to get this far, Welcome to Mozilla’s Matrix! 😄
NOTE: If there’s an official page documenting the process I’m not aware of it. I will add it once it is published.
In June we discovered that Treeherder’s UI slowdowns were due to database slow downs (For full details you can read this post). After a couple of months of investigations, we did various changes to the RDS set up. The changes that made the most significant impact were doubling the DB size to double our IOPS cap and adding Heroku auto-scaling for web nodes. Alternatively, we could have used Provisioned IOPS instead of General SSD storage to double the IOPS but the cost was over $1,000/month more.
Looking back, we made the mistake of not involving AWS from the beginning (I didn’t know we could have used their help). The AWS support team would have looked at the database and would have likely recommended the parameter changes required for a write intensive workload (the changes they recommended during our November outage — see bug 1597136 for details). For the next four months we did not have any issues, however, their help would have saved a lot of time and it would have prevented the major outage we had in November.
There were some good things that came out of these two episodes: the team has learned how to better handle DB issues, there’s improvements we can do to prevent future incidents (see bug 1599095), we created an escalation path and we worked closely as a team to go through the crisis (thanks bobm, camd, dividehex, ekyle, fubar, habib, kthiessen & sclements for your help!).
See the video there, if it doesn’t display up here.
Context
Why Taskcluster?
It’s a fairly common practice to build and test every time someone makes a change in the code. In the industry, we call this process “Continuous Integration” (CI). Another good practice is to automate the deployment of your builds to end-users. This process is called “Continuous Deployment” (CD). There are several CI/CD products on the market. Mozilla has used some of them for years and still uses them in some projects. About 6 years ago, Mozilla needed a CI/CD product that did more than what was available and started Taskcluster. If you’re interested in knowing more about why we made Taskcluster, please let me know in the comments and I’ll write a dedicated post.
Since then, we’ve entirely migrated many Android projects like Firefox, Firefox Focus, Firefox for Amazon’s Fire TV, Android-Components, and the upcoming Firefox Preview to Taskcluster. The rationale for migrating off another CI/CD was usually the following: we want to ensure what we’re shipping to end-users comes from Mozilla, while still providing the development team an easy and consistent way to configure their tasks.
Taskcluster and task definitions
A task is an arbitrary piece of code that is executed by Taskcluster. We tell Taskcluster to execute a task by submitting some configuration, that we call the “task definition”. A task definition contains data about version control repository it deals with or what commands to run. As your project grows, it will likely need more than a single task to perform all actions. In this case, you need a graph of task definitions. You can submit a graph in different ways:
either by manually entering each task on the task creator,
by defining them all in a .taskcluster.yml file in your repository
by defining a single task in .taskcluster.yml and letting this task generate the rest of the graph. We call this single task a “decision task”. It can be implemented:
either by using one of the Taskcluster libraries (the Python one for instance),
or by using a higher-level framework: taskgraph.
The above graph submission options are ordered by complexity. You may not want to start with option 3 immediately. Although, if your CI/CD pipeline deals with multiple platforms, multiple types of tests, and/or multiple types of pipelines, you may want solution 3b. More on this below.
Solution 1
Solution 2
Solution 3
Solution 3a: What’s inside the decision task
Solution 3b: Inside the decision task
Taskgraph was originally built for the most complex project, Firefox itself, and it was strongly tied to it. So, when a simpler project - Firefox Focus - came up a year and a half ago, we - the Development Team and Release Engineering - agreed on going with solution 2 and later on then 3a. Firefox Focus went great and became the base of a lot of Android projects. They have grown quite big since Firefox Focus started. The way CI/CD is configured there has grown on top of a code which wasn’t meant to be that big, and which was duplicated across projects.
Taskcluster and people
Moreover, people started to come from our main repository (where Firefox for Android is) to our other Android projects. With each project, they had to figure out how things work and Release Engineering has had to be involved in many changes, so we were losing the “provide the development team an easy way to configure their tasks” feature.
Here enters taskgraph
We know Android projects are becoming more and more complex, in terms of CI/CD. We know taskgraph is able to support thousands of jobs by splitting the complexity in small and dedicated files. We know Firefox developers have more or less knowledge about taskgraph to be able to add/modify their job without compromising the rest of the graph. So we decided to make taskgraph a more generic framework so Android projects can reuse it.
Taskgraph, the tour
In a few words
Like its name infers, taskgraph generates graphs of tasks for all types of events. Events can be “someone just pushed a new commit on the repository” or “someone just triggered a release”. Taskgraph knows what type of event happened and submits the corresponding graph to Taskcluster.
Main features
It’s fast! Tens of thousands of tasks are generated in under a minute
It deals with default values. Oftentimes you have to provide the same data for each task, taskgraph knows about the right defaults, so you can focus on what’s really important to your task
It validates data before submitting anything to Taskcluster.
It’s deterministic. You’ll get the exact same result by reusing a set of parameters from a run on another machine.
It’s both configuration-oriented and programming-oriented. Want to avoid repeating the same configuration lines over and over? You can write a python function in a separate file
On Android projects, when we first implemented our simple solution based off of taskcluster libraries, we did have feature #1 (easy, when you deal with a handful of tasks), but we started to wait minutes to get a hundred tasks submitted. At some point, we needed feature #2, so we had to implement our own default values. We’ve never had feature #3 and #4. Depending on the Android project, feature #5 was more or less implemented.
Other features I like
Docker images! We can create our build environments directly on Taskcluster as docker images and have our build tasks using them. We don’t need to publish the images somewhere, like on Docker hub.
Cached tasks. Sometimes you just want to rebuild something when a subset of the code changes (for instance a Dockerfile). Taskgraph knows where to find these tasks and reuse them in the graph it submits
Graphs that depend on other graphs. Cached tasks are for single tasks, but you can reuse entire graphs. This is useful in Firefox. We generate all the shippable builds whenever a push to the repository happens. Then, if we think they’re good enough, we promote them to be actually shipped.
To me, re-using taskgraph instead of reimplementing a new framework is today a huge win just for the sake of these features, even for small projects. We didn’t do it a year and a half ago, because taskgraph wasn’t a self-served module. Tom Prince put a lot of effort to make taskgraph generic enough to serve other projects than Firefox.
Introduction to taskgraph
Data flow, part 1
Hacking taskgraph is usually dealing with that part of the data flow
Kind.yml
In order to help taskgraph to tell if a task should end up in a graph, tasks are grouped in “kinds”. Kinds group tasks that are similar.
For instance: You’d like to have 2 compilation tasks, one for a debug build and the other for an optimized one. Chances are both builds are generated with the same command, modulo a flag. In taskgraph, you will define both tasks under the same kind.
Each kind is stored in its own kind.yml file. It’s the configuration-oriented part of taskgraph. You usually put raw data in them. There are some bits of simple logic that you can put in them.
For example: job-defaults provides some default values for all jobs defined in the kind, it can be useful if the build tasks are generated with the same command.
Loader
The loader is in charge of taking every task in the kind, applying job-defaults and finding what are the right upstream dependencies. The dependency links are what make the graphs of tasks.
For instance: In addition to having common values, both of your build tasks may depend on Docker images, where your full build environment is stored. The loader will output the 2 build tasks and set the docker image as their dependencies,
Transforms
Here comes the programming oriented part of taskgraph. The configuration defined in kind.yml is usually defined to be as simple as possible. Transforms take them and translate them into actual task definitions. Transforms can be shared among kinds, which gives a way to factorize common logic. Some transforms validate their input, ensuring the dataflow is sane.
For example: For the sake of cost, Taskcluster enforces tasks to be deleted after a certain amount of time. The last transform ensures this value is valid and if it’s not defined (which usually happens) sets it to a year from now.
Data flow, part 2
You may not need it, but that’s how optimization happens!
Target tasks
Taskgraph always generates the full graph, then it filters out what’s not needed. That’s what the target task phase does.
For instance: If you want to ship a nightly build, target_tasks will only select the right tasks to build, sign, and publish this build.
Optimized tasks
Some tasks may have been already scheduled. If so, taskgraph takes them out of the target tasks.
For example: If the nightly build task was made at the same time as the debug one, taskgraph can reuse the task and just submit the signing and publishing tasks.
Taskcluster client
At this point, taskgraph knows exactly what subgraph to submit. It delegates the submission to taskcluster via one of its client libraries. Tasks are then generated.
What’s next?
I really enjoyed “taskgraph-ifying” the most important mobile projects. We have leveraged a codebase that can scale while being able to handle edge cases. We’ve been able to factorize some of the common logic, which wasn’t possible with our initial solution. There’s still some improvement we can, and Mitch, Tom and I are working on improving the quality of life.
Moreover, having taskgraph enables a better release workflow for Firefox Preview: we may have finer grained permission on who can ship a release. It requires more work and more blog posts, but taskgraph is a necessary stepping stone.
At this time last year, I had just moved on from Release Engineering to start managing the Sheriffs and the Developer Workflow teams. Shortly after the release of Firefox Quantum, I also inherited the Taskcluster team. The next few months were *ridiculously* busy as I tried to juggle the management responsibilities of three largely disparate groups.
By mid-January, it became clear that I could not, in fact, do it all. The Taskcluster group had the biggest ongoing need for management support, so that’s where I chose to land. This sanity-preserving move also gave a colleague, Kim Moir, the chance to step into management of the Developer Workflow team.
Meet the Team
Let me start by introducing the Taskcluster team. We are:
We are an eclectic mix of curlers, snooker players, pinball enthusiasts, and much else besides. We also write and run continous integration (CI) software at scale.
What are we doing?
The part I understand is excellent, and so too is, I dare say, the part I do not understand…
One of the reasons why I love the Taskcluster team so much is that they have a real penchant for documentation. That includes their design and post-mortem processes. Previously, I had only managed others who were using Taskcluster…consumers of their services. The Taskcluster documentation made it really easy for me to plug-in quickly and help provide direction.
If you’re curious about what Taskcluster is at a foundational level, you should start with the tutorial.
The Taskcluster team currently has three, big efforts in progress.
1. Redeployability
Many Taskcluster team members initially joined the team with the dream of building a true, open source CI solution. Dustin has a great post explaining the impetus behind redeployability. Here’s the intro:
Taskcluster has always been open source: all of our code is on Github, and we get lots of contributions to the various repositories. Some of our libraries and other packages have seen some use outside of a Taskcluster context, too.
But today, Taskcluster is not a project that could practically be used outside of its single incarnation at Mozilla. For example, we hard-code the name taskcluster.net in a number of places, and we include our config in the source-code repositories. There’s no legal or contractual reason someone else could not run their own Taskcluster, but it would be difficult and almost certainly break next time we made a change.
The Mozilla incarnation is open to use by any Mozilla project, although our focus is obviously Firefox and Firefox-related products like Fennec. This was a practical decision: our priority is to migrate Firefox to Taskcluster, and that is an enormous project. Maintaining an abstract ability to deploy additional instances while working on this project was just too much work for a small team.
The good news is, the focus is now shifting. The migration from Buildbot to Taskcluster is nearly complete, and the remaining pieces are related to hardware deployment, largely by other teams. We are returning to work on something we’ve wanted to do for a long time: support redeployability.
We’re a little further down that path than when he first wrote about it in January, but you can read more about our efforts to make Taskcluster more widely deployable in Dustin’s blog.
2. Support for packet.net
packet.net provides some interesting services, like baremetal servers and access to ARM hardware, that other cloud providers are only starting to offer. Experiments with our existing emulator tests on the baremetal servers have shown incredible speed-ups in some cases. The promise of ARM hardware is particularly appealing for future mobile testing efforts.
Over the next few months, we plan to add support for packet.net to the Mozilla instance of Taskcluster. This lines up well with the efforts around redeployability, i.e. we need to be able to support different and/or multiple cloud providers anyway.
3. Keeping the lights on (KTLO)
While not particularly glamorous, maintenance is a fact of life for software engineers supporting code that in running in production. That said, we should actively work to minimize the amount of maintenance work we need to do.
One of the first things I did when I took over the Taskcluster team full-time was halt *all* new and ongoing work to focus on stability for the entire month of February. This was precipitated by a series of prolonged outages in January. We didn’t have an established error budget at the time, but if we had, we would have completely blown through it.
Our focus on stability had many payoffs, including more robust deployment stories for many of our services, and a new IRC channel (#taskcluster-bots) full of deployment notices and monitoring alerts. We needed to put in this stability work to buy ourselves the time to work on redeployability.
What are we *not* doing?
With all the current work on redeployability, it’s tempting to look ahead to when we can incorporate some of these improvements into the current Firefox CI setup. While we do plan to redeploy Firefox CI at some point this year to take advantage of these systemic improvements, it is not our focus…yet.
One of the other things I love about the Taskcluster team is that they are really good at supporting community contribution. If you’re interested in learning more about Taskcluster or even getting your feet wet with some bugs, please drop by the #taskcluster channel on IRC and say Hi!
You manage or are part of a team that is responsible for a certain functional area of code. Everyone on the team is at different points in there career. Some people have only been there a few years, or maybe even only a few months, but they’re hungry and eager to learn. Other team members have been around forever, and due to that longevity, they are go-to resources for the rest of your organization when someone needs help in that functional area. More-senior people get buried under a mountain of review requests, while those less-senior engineers who are eager to help and grow their reputation get table scraps.
This was the first time that Mozilla had organized a majority (4) of build module peers in one group. There are still isolated build peers in other groups still, but we’ll get to that in a bit.
With apologies to Ted, he’s the elder statesman of the group, having once been the build module owner himself before handing that responsiblity off to Greg (gps), the current module owner. Ted has been around Mozilla for so long that he is a go-to resource for not only build system work but many other projects, e.g. crash analysis, he’s been involved with. In his position as module owner, Greg bears the brunt of the current review workload for the build system. He needs to weigh-in on architectural decisions, but also receives a substantial number of drive-by requests simply because he is the module owner.
Chris Manchester and Mike Shal by contrast are relatively new build peers and would frequently end up reviewing patches for each other, but not a lot else. How could we more equitably share the review load between the team without creating more work for those engineers who were already oversubscribed?
Enter the shared bug queue
When I first came up with this idea, I thought that certainly this must have been tried at some point in the history of Mozilla. I was hoping to plug into an existing model in bugzilla, but alas, such a thing did not already exist. It took a few months of back-and-forth with our reisdent Bugmaster at Mozilla, Emma, to get something setup, but by early October, we had a shared queue in place.
How does it work?
We created a fictitious meta-user, core-build-config-reviews@mozilla.bugs. Now whenever someone submits a patch to the Core::Build Config module in bugzilla, the suggested reviewer always defaults to that shared user. Everyone on the teams watches that user and pulls reviews from “their” queue.
That’s it. No, really.
Well, okay, there’s a little bit more process around it than that. One of the dangers of a shared queue is that since no specific person is being nagged for pending reviews, the queue could become a place where patches go to die. As with any defect tracking system, regular triage is critically important.
Is it working?
In short: yes, very much so.
Subjectively, it feels great. We’ve solved some tricky people problems with a pretty straightforward technical/process solution and that’s amazing. From talking to all the build peers, they feel a new collective sense of ownership of the build module and the code passing through it. The more-senior people feel they have more time to concentrate on higher level issues or deeper reviews. The less-senior people are building their reputations, both among the build peers and outside the group to review requesters.
Numerically speaking, the absolute number of review requests for the Core::Build Config module is consistent since the adoption of the shared queue. The distribution of actual reviewers has changed a lot though. Greg and Ted still end up reviewing their share of escalated requests — it’s still possible to assign reviews to specific people in this system — but Mike Shal and Chris have increased their review volume substantially. What’s even more awesome is that the build peers who are *NOT* in the Developer Workflow team are also fully onboard, regularly pulling reviews off the shared queue. Kudos to Nick Alexander, Nathan Froyd, Ralph Giles, and Mike Hommey for also embracing this new system wholeheartedly.
The need for regular triage has also provided another area of growth for the less-senior build peers. Mike Shal and Chris Manchester have done a great job of keeping that queue empty and forcing the team to triage any backlog each week in our team meeting.
Teh Future
When we were about to set this up in October, I almost pulled the plug.
Phabricator will undoubtedly enable a host of quality-of-life improvements for developers when it is deployed, but I’m glad we didn’t wait for the new system. Mozilla engineers are already getting accustomed to the new workflow and we’re reaping the benefits *right now*.
This post is *ahem* several months overdue, but I’m happy to welcome Connor Sheehan to the team.
Connor was a two-time intern with the Mozilla release engineering team. In that capacity, he became well acquainted with some of the bottlenecks in our CI system. We’ve brought him onboard to assist gps with stabilizing and scaling our mercurial infrastructure.
We often optimize work week location around where the fewest people would need to travel to attend. While this does make things logistically easier, it also introduces imbalance. Some people will have traveled very far, while some people will be able to sleep in their own beds. Conversely, the local people may feel they need to go home every night in order to be with their partners/families/cats and may miss out on the informal bonding that can happen at group dinners and such.
We had originally intended to meet in San Francisco, but other conferences had jacked up hotel rates, so we decided to decamp to the Valley. I offered to have the SF residents book rooms to avoid the daily commute up and down the peninsula. They didn’t all take me up on it, but it was an opportunity to put everyone on more equal footing.
Schedule-wise, I set things up so that we had our discussion and planning pieces in the morning each day while we were still fresh and caffeinated. After lunch, we would get down to hacking on code. Ted threw together a tracking tool to help visualize the Makefile burndown. Ted is also great at facilitating meetings, keeping us on track especially later in the week as we all started to fade.
Accomplishments
So what did we actually get done? Like the old adage about station wagon full of tapes, never underestimate the review bandwidth of 4 build peers hacking in a room together for an afternoon. We accomplished quite a bit during our time together.
Aside from the 2018 planning detailed in the previous post, we also met with mobile build peer Nick Alexander and planned how to handle mobile Makefiles. The mobile version of Firefox now builds with gradle, so it was important not to step on each others toes. Another huge proportion of the remaining Makefiles involve l10n. We figured out how to work-around l10n for now, i.e. don’t break repacks, to get a tup build working, and we’ve setup a meeting with l10n team for Austin to discuss their plans for langpacks and a future that might not involve makefiles at all. The l10n stuff is hairy, and might be partially my fault (see previous comment re: cargo-culting), so thanks to my team for not shying away from it.
On a concrete level, Ted reports that we’ve removed 13 Makefiles and ~100 lines of other Makefile content in the past month, much of which happened over the past few weeks. Greg has also managed to remove big pieces of complexity from client.mk, assisted by reviews from Chris, Mike, Nick and other build peers. We’re getting into the trickier bits now, but we’re persevering.
All in all, a very successful work week with my “new” team. I continue to find subtle ways to make these get-togethers more effective.
I’ve neglected to write about the *other* half of my team, not for any lack of desire to do so, but simply because the code sheriffing situation was taking up so much of my time. Now that the SoftVision contractors have gained the commit access required to be fully functional sheriffs, I feel that I can shift focus a bit.
Meet the team
The other half of my team consists of 4 Firefox build system peers. My team consists of:
When the group was first established, we talked a lot about what we wanted to work on, what we needed to work on, and what we should be working on. Those discussions revealed the following common themes:
We have a focus on developers. Everything we work on is to help developers be more productive, and go more quickly.
We accomplish this through tooling to support better/faster
workflows.
Some of these improvements can also assist in automation, but that isn’t our primary focus, except where those improvements are also wins for developers, e.g. faster time to first feedback on commit.
We act as consultants/liaisons to many other groups that also touch the build system, e.g. Servo, WebRTC, NSS etc.
Based on that list of themes, we’ve adopted the moniker of “Developer Workflow.” We are all build peers, yes, but to pigeon-hole ourselves as the build system group seemed short-sighted. Our unique position at the intersection of the build system, VCS, and other services meant that our scope needed to match what people expect of us anyway.
While new to me, Developer Workflow is a logical continuation of build system tiger team organized by David Burns in 2016. This is the same effort that yielded sea change improvements such as artifact builds and sccache.
In many ways, I feel extremely fortunate to be following on the heels of that work. During the previous year, all the members of my team formed the working relationships they would need to be more successful going forward. All the hard work for me as their manager was already done! ;)
What are we doing
We had our first, dedicated work week as a team last week in Mountain View. Aside from getting to know each other a little better, during the week we hashed out exactly what our team will be focused on next year, and made substantial progress towards bootstrapping those efforts.
Next year, we’ll be tackling the following projects:
Finish the migration from Makefiles to moz.build files: A lot of important business logic resides in Makefiles for no good reason. As someone who has cargo-culted large portions of l10n Makefile logic during my tenure at Mozilla, I may be part of the problem.
Move build logic out of *.mk files: Greg recently announced his intent to remove client.mk, a foundational piece of code in the Mozilla recursive make build system that has existed since 1998. The other .mk files won’t be far behind. Porting true build logic to moz.build files and removing non-build tasks to task-based scripts will make the build system infinitely more hackable, and will allow us to pursue performance gains in many different areas. For example, decoupled tests like package tests could be run asynchronously, getting results to developers more quickly.
Stand-up a tup build in automation: this is our big effort for the near-term. A tup build is not necessarily an end goal in-and-of itself — we may very well end up on bazel or something else eventually — but since the Mike Shal created tup, we control enough of the stack to make quick progress. It’s a means of validating the Makefile migration.
Move our Linux builder in automation from Centos6 to Debian: This would move move us closer to deterministic builds, and has alignment with the TOR project, but requires we host our own package servers, CDN, etc. This would also make it easier for developers to reproduce automation builds locally. glandium has a proof-of-concept. We hope to dig into any binary compatibility issues next year.
Weening off mozharness for builds: mozharness was a good first step at putting automated build configuration information in the tree for developers. Now that functionality could be better encapsulated elsewhere, and largely hidden by mach. The ultimate goal would be to use the same workflow for developer builds and automation.
What are we *not* doing
It’s important to be explicit about things we won’t be tackling too, especially when it’s been unclear historically or where there might be different expectations.
The biggest one to call out here is github integration. Many teams at Mozilla are using github for developing standalone projects or even parts of Firefox. While we’ve had some historical involvement here and will continue to consult as necessary, other teams are better positioned to drive this work.
We are also not currently exploring moving Windows builds to WSL. This is something we experimented with in Q3 this year, but build performance is still so slow that it doesn’t warrant further action right now. We continue to follow the development of WSL and if Microsoft is able to fix filesystem performance, we may pick this back up.
In a github world, developers have certain baseline expectations about interacting with source code and the tooling around it. These expectations can color their choices about which projects to contribute to. If Mozilla wants to compete with other companies and open source projects for developer mindshare (and code), we need to evolve the way we develop and distribute software. Code sheriffing and its associated tooling is one piece of that puzzle.
I inherited the Mozilla code sheriff team back in April. I didn’t initially think anything needed to change with sheriffing at Mozilla. Things had been “fine” for a while, so why rock the boat?
By nature, I dug into the history of my new team when I inherited them. What follows is a brief retrospective of sheriffing at Mozilla, the changes we’re undergoing right now, and my vision for how it might change in the future.
Past
I’ve been at Mozilla long enough now to remember when developers themselves acted as code sheriffs. In the beginning, every developer at Mozilla (myself included) rotated through the position1. Some developers were quite conscientious about sheriffing, others never even realized it was their turn. There was no formal training. Not surprisingly, the results were…uneven.
As the number of developers and the volume of code increased, this model became untenable. Code sheriffing as a well-defined role didn’t exist at Mozilla until 2012, initially coming as a response to the staffing increase in the lead-up to Firefox 4. At the same time, Mozilla was moving away from a “strict” waterfall development model tied to Tinderbox. Our new buildbot-based approach to CI allowed us to land more code, more quickly. Dedicated sheriffs were needed to make sense of it all. Even then, in true Mozilla fashion, sheriffing was an activity that blurred the lines between community and staff. Some of the most dedicated code sheriffs we have ever had were/are volunteers.
Whether staff or community, code sheriffs became de facto stewards of code quality. They were responsible for daily merges, selecting changesets with the lowest number of intermittent failures that would be suitable for inclusion in Nightly releases. When things broke, the sheriffs were responsible for backing out code, and even closing the development trees if the situation became sufficiently dire.
With the opening of the Mozilla office in Taipei, and the associated re-tasking of two QA resources as code sheriffs in that office, Mozilla almost had around-the-clock (24/7) coverage for code sheriffing, provided no one ever got sick or took a vacation.
We persevered in this model for a few years, and our developers understandably became accustomed to the freedom it provided them. Developers could functionally land their code and not worry about the outcome: the code sheriffs would ping them if any follow-up action was required. Fire-and-forget, if you will.
Sadly, in June 2017 our last Taipei sheriff resigned, leaving us with a glaring hole in our coverage. Even with community assistance, there were 8-10 hours per day with *no* active sheriffing. This led to an increase in tree closing events as sheriffs often needed to determine the root cause for a failure that had many commits on top of it already. Complaints started coming in about delays in landing code, and also about classification errors, e.g. permanent failures wrongly triaged as intermittent due to the time pressures of working in this mode. People were not happy, least of all the sheriffs.
This is when I realized I needed to rethink how sheriffing at Mozilla should work.
Present
The knee-jerk reaction would have been to simply hire another sheriff in Taipei, but that still would have left us vulnerable to illness, vacation, and further employment changes. Luckily, another solution presented itself.
Mozilla has an established history of working with SoftVision. I enlisted their help myself a few years ago when I was working in releng to help address our buildduty problem. It came to my attention that SoftVision was creating a 24/7 support service, and I decided to give it a try. That’s where we are now.
The SoftVision sheriffing contractors started in late August. They have spent the last two months learning (and then practicing) how to classify automation failures. The harder piece is learning how to properly select mergeable changesets and perform backouts. Mozilla guards the kind of source control access required to perform these code sheriffing activities pretty closely; it’s not something we simply give away. The contractors are slowly building that trust the same as any other contributor would. We’re getting there though:
Once the SoftVision sheriffs are fully up-to-speed, they will be available 24/7 to assist developers, and to further the Mozilla mission with the usual array of merges, backouts, uplifts, and tree closures.
Right now, we are relying on the magnanimity of the former sheriffs and community sheriffs to help bridge the gap while the contractors are training up. It’s true, sheriffs throughput is still not back to the level before we lost our sheriff in Taipei, but I can see the light at the end of the tunnel.
Future
How can I be sure that light isn’t a train? Well, that’s the trick, isn’t it?
In retrospect, it was naïve of me to think that sheriffing could have existed for any length of time the way it was. Sheriffs felt enormous pressure to work longer hours than they should have because the trees needed to stay open, and “if not them, then who?” The human toll on those performing the work. whether staff or volunteer, was simply too high.
Yes, for the near-future at least, the SoftVision contractors will continue to perform merges and backouts as required in the model to which we’ve become accustomed. That work is still very operational, hands-on, and prone to burnout, and that’s where I think the biggest opportunity for change will come going forward.
Mozilla currently has two integrations branches – mozilla-inbound and autoland – in addition to mozilla-central. This makes life much harder for sheriffs because they need to merge code three-ways between the different branches. When bad code gets merged around accidentally, we are almost forced to close the trees while we recover.
The obvious change is to simplify the process and remove one of the integration branches. This might actually be feasible in the near future. With the announcement of Mozilla’s adoption of phabricator, 99.9% of code should eventually be able to land directly in the autoland repo, allowing us to decommission the mozilla-inbound repo. Once we return to a single integration branch, developer workflows can be much more streamlined, and streamlined workflows are ideal targets for automation.
My ideal future developer workflow would be:
Developer writes patch.
Developer compiles patch locally.
Patch posted to phabricator, triggers try run automatically.
If try run passes, suitable patch reviewers are selected automatically.
After successful review, patch is landed automatically on the autoland branch.
Autoland gets merged to mozilla-central automatically for changesets below the noise threshold for failures.
There are no code sheriffs in that picture at all. That’s a good thing.2
There’s a gulf of tooling improvements between where we are and that potential future, but if Mozilla wants to keep increasing the pace of development and attracting the best developers, I think the tooling investment is one we need to make.
The Release Engineering team fully-automated the publication of Firefox for Android in version 53.0. Let’s see what was already there and how things have changed since version 53.0.
This blog post is a part of a serial. Checkout the other posts:
The Release Engineering team fully-automated the publication of Firefox for Android in version 53.0. Let’s see what was already there and how things have changed since version 53.0.
This blog post is a part of a serial. Checkout the other posts:
5 things I would have loved knowing about Google Play
This part is more oriented to personal takeaways and a couple of questions that remain unanswered.
It is easy to publish an APK that is not localized
A few checks done in pushapk_scriptworker are actually because of previous errors. The number of locales is one of them. A few weeks after Fennec Aurora was shipped to Google Play, some users started to see their browser in English, even though their phone is set in a different locale and Aurora used to be in their own locales.
Like said previously, APKs were originally uploaded via a script. This was true also for the first Aurora APKs. Furthermore, automation on Taskcluster was first tried on Aurora. When I started to roll these bits out, there was a configuration issue. Pushapk_scriptworker picked the en-US-only-APK, instead of the multi-locale one. The fix was fairly simple: just change the APK locations.
Google Play has a lot of ways to detect wrong APKs: by signatures, by package name (none of the Firefox versions share the same one), by version code, and some others. Although, it doesn’t warn about a big change in:
Size. There is approximately a 10-MB-difference between a single locale build and a multi-locale one. Multi-locale APK are usually less than 40 MB. That APK shrunk by 25%, but not for good reasons.
The directory list of the archive. Manifest files were smaller, there were 90 times less files in some directories.
Of course, from one stable version to another, a lot of files may change in the archive. Asking Google to watch out for everything doesn’t seem reasonable. Although, when I started working on Google Play, it left me the feeling of being well-hardened. At that time, I thought Google Play did check the locales within an APK.
The consequence I take away: If your app has different build flavors (like single vs multi-locales), I recommend you write your own sanity checks, first.
Locales on the Play Store are independent from locales in APK
It might sound obvious after explaining of the previous issue, but this error message confused several Mozillians:
Tried to set recent changes text for APK version 12345678 for language es-US. Language is not associated with the app.
We hit it with a couple of locales, at pace of 1 per month, approximately. Like explained in the architecture part, locales are defined in an external service, stores_l10n. We have had many theories about it:
This locale is not supported by Google Play
The locale code (for instance “es-US”) expected by Google Play is not the one we provide. We may want to find the list of the locales officially supported
We don’t ship this locale within the APK, and the Play Store detects it
Actually, the fix ended up being simple. “Recent changes” is something we want to update on every new APK. But because the descriptions were more set in stone, they were not a part of the automated workflow. Actually, stores_l10n released had recently released new locales each time we hit the problem. That error message was actually telling us the descriptions of these new locales had never been uploaded. Once we figured this out, it became a part of the regular update workflow.
You cannot catch everything when you don’t commit transactions
The dry-run feature in MozApkPublisher, which just doesn’t commit the Google Play transaction, helps in detecting early failures. For instance: wrong version codes, wrong package names. Nevertheless, we have hit cases where dry runs went smoothly and we had to diagnose new issues at commit time.
Locales mismatch. The previous issue was not dectected at the upload time, likely for the reason that listings and the recent changes are 2 differentAPI calls. I assume, because you can call these API in whatever order within the same transaction, Google doesn’t check until the final state is fully known.
Permissions not granted to the account. Due to Firefox Aurora being stopped, we restricted the Google Play account in charge of Aurora to not be able to upload any APK anymore. Yet, we decided to publish Nightly to the same product as Aurora (in order to not strand users on a unmaintained version). Our tests went fine, Google Play accepted our APKs. But the day of the go-live, a new error came up saying we are not able to upload APKs after all. I don’t have any theory for this scenario, but if you do, I would love to hear it!
User fractions can also be specified on other tracks (but that’s not a feature)
Fennec Release 53.0 is the first version which was entirely published via Taskcluster. Mozilla also uses the rollout track on Release only. Beta is pushed to the production one (and that is actually something we are reviewing). Sadly, there was another configuration error: even though, the user fraction was specified, the configured track was the production one. Google Play didn’t raise any error (even at commit time), starting a full-throttled release. At that time, I contacted the Google Play support, to ask if it was possible to switch back to rollout. The person was very courteous. He explained they were not able to perform that kind of action. This is why they transmitted my request to the tech team, who will follow up by email.
In parallel, we have fixed the configuration error and implemented our own check in MozApkPublisher.
There is no way to rollback to previous APKs, even if you ask a human
The previous configuration error could have remained brieve, if somebody didn’t report what seemed like an important crash, 1 hour later. At that point, the Release Management team wanted to stall updates, in order to not spread the regression too much. We were still waiting on the support’s answer, but I reached out to them again since our request became different. I told the new contact I had about the previous issue, the new one, and the fact we were running against the clock. Sadly for us, the person only gave us the option to wait on the email follow up.
About 16 hours later, we got the email with the official answer:
Unfortunately, we cannot remove the APK in question, neither can we claw back the APK from the users that have already installed this update.
If you want to stop further users from installing this APK, then you need to make another release that deactivates this APK and add the APK that you want users to install instead.
The Release Engineering team fully-automated the publication of Firefox for Android in version 53.0. Let’s see what was already there and how things have changed since version 53.0.
This blog post is a part of a serial. Checkout the other posts:
Securely authenticate to it. It offers several ways to authenticate, including P12 certificates.
Securely store the authentication credentials.
Securely fetch the builds.
The solution
Based on Taskcluster
Mozilla, and more specifically the Release Engineering team, uses Taskcluster to implement the Firefox release workflow. The workflow can be summed up as:
Build Firefox with all supported locales (languages)
Sign these builds
Publish them everywhere (on https://archive.mozilla.org/, on https://www.mozilla.org/firefox/, via updates, etc.)
Each step is defined by its own set of tasks. These tasks are processed by specialized workers (represented by worker types). Those workers basically run a script against parameters given in the task definition.
Therefore, publishing to Google Play was a matter of creating a new Taskcluster task, which will be processed by a dedicated script and executed by its own worker type.
With some extra-security features
The aforementioned script must be bootstrapped to be integrated to the rest of Taskcluster. There are several ways to bootstrap scripts for Taskcluster. One of them is to create a docker image which Taskcluster pulls and run.
However, because of the needs stated above, we decided to go with a security-focused framework: scriptworker. Scriptworker was initially created to perform one of the most critical operation security-wise: sign builds. The framework has some great interesting features:
It securely downloads artifacts. Files are forced to be downloaded over https. Checksums and signatures are checked.
It validates that the task definitions were not changed between the time of creation and the time of execution. This prevents some tasks to be duplicated and edited to introduce extra-commands, which may be used to tamper a build, for instance.
It abstracts some of the Taskcluster details, thus you just have write a script (language-agnostic) that does what your worker has to do.
How pieces are wired together
0. Overview
Here’s a general view of how things are wired together:
1. The “decision task” creates a task for pushapk_scriptworker
2/3. Scriptworker polls for pending tasks and check their scopes. It downloads APKs via Chain of Trust. Scriptworker checks if the upstream tasks were altered.
4. Scriptworker defers valid tasks to pushapkscript. The latter validates APKs signatures, makes sure every APK architecture is present.
5. Pushapkscript calls MozApkPublisher with credentials and on-disk locations of APKs
6/7. MozApkPublisher verifies whether APKs contain several locales. It fetches localized strings displayed on Google Play Store (aka “listings” and “what’s new section”)
8. MozApkPublisher opens the Google play credentials.
9. MozApkPublisher publishes APKs, listings and “what’s new”
1. Task creation
There are many ways to submit the definition of a task to Taskcluster. For example, you can:
Call the Taskcluster API via one of the libraries (interesting if you want a bot that spawns tasks)
Generate the task via taskcluster/taskgraph that lives “in-tree”, that is to say, alonside the Firefox code.
Each of them was used at some point, but the ultimate solution relies on the last one. The taskgraph is a graph generator which, depending on given parameters, creates a graph of builds, tests and deployment tasks. Taskgraph generation is run on Taskcluster too, under what we commonly call “the decision task”. This solution benefits from being on hg.mozilla.org: it is versioned and only vouched people are able to modify it.
Moreover, taskgraph generates what is necessary for scriptworker to validate the task definitions and artifacts. To do so, taskgraph:
Creates a JSON representation of the graph,
Creates another JSON file that describes the artifacts generated (including the JSON of the graph) and signs it.
2. Scriptworker and new tasks
Scriptworker polls tasks from Taskcluster queue. That is actually one of the great things about Taskcluster: workers don’t have to open inbound (listening) ports. This reduces the potential surface of attack. Fetching new tasks is done via this bit of REST API which workers can poll. Speaking of which, workers are authenticated to Taskcluster, which prevents them from claiming a task that it isn’t meant to take.
Secure download of artifacts is done by the “Chain of Trust” feature of scriptworker. Once set up, if you define upstreamArtifacts within the task definition, scriptworker will:
Make sure the current task and its dependencies have not changed since its definition. This is done by comparing the JSON the taskgraph generated and the actual definition.
Check the signatures of every dependency, by looking at a special artifact Chain of Trust creates. This helps to verify no rogue worker processed a upstream task.
Download artifacts on the worker and verify the checksums.
If all goes well, scriptworker will call pushapkscript
3. Pushapkscript and APKs
Here starts the Android-specific bits. Pushapkscript performs some extra checks on the APKs:
APKs are signed with the correct certificates. In the previous steps, we have only checked the origin of the tasks. Now, we verify the APK itself. This may not sound extremely important because Google Play is vigilant about APK signatures and will refuse any APK for which the signature is not valid. However, it is safer to bail out before any outbound traffic is done to Google Play. Besides, with this check, Google acts as a second factor instead of being the only actor accountable for signatures.
No required processor architecture is missing, in order to upload them all in the same request. We have to publish them at the same time because some Android devices support several architectures. We have already had one big crash on these devices because an x86 APK was overseeded by its “brother in ARM”.
Pushapkscript knows about the location of the Google Play credentials (P12 certificates). It finally gives all the files (checked APKs and credentials) to MozApkPublisher.
4. MozApkPublisher, locales and Google Play
To be honest, MozApkPublisher could have been implemented within pushapkscript, but the split exists for historical reasons and still has a meaning today: this was the script Release Management used before this project got started. It also remains a way to let a human publish, in case of emergency.
It checks that APKs are multi-locale. We serve the same APK, which includes (almost) every locale in it. That’s a verification Google doesn’t do.
It also fetches the latest strings to display on the Play Store (like the localized descriptions). These strings are then posted on Google Play, alongside the APKs.
MozApkPublisher provides a dry-run mode thanks to the transaction mechanism exposed by Google’s API. Nothing is effectively published until the transaction is committed.
5. Pushapk_scriptworker: Scriptworker, Pushapkscript, and MozApkPublisher on the same machine
The 3 pieces live on the same Amazon EC2 instance, under the name pushapk_scriptworker. The configuration of this instance is managed by Puppet. The entire Puppet configuration is public on hg.mozilla.org, with the exception of secrets (Tascluster credentials, P12 certificates) which are encrypted on a seperate machine. Like the main Firefox repository, only vouched people can submit changes to the Puppet configuration.
5 things I would have loved knowing about Google Play
The Release Engineering team fully-automated the publication of Firefox for Android in version 53.0. Let’s see what was already there and how things have changed since version 53.0.
This blog post is a part of a serial. Checkout the other posts:
This is true for desktop (Windows, Linux, Mac) and Android. However, we don’t ship that often to every user. We have different channels, receiving updates at different frequencies:
Firefox Nightly (and Aurora until we stopped it) gets updated usually every day (unless an important breakage happens).
Firefox Beta and Developer Edition get two updates every week on Desktop. On Android, Beta is usually shipped once a week.
Firefox Release (also known as simply “Firefox”) gets one every six weeks.
About Firefox Aurora
You may have heard, Firefox Aurora has been discontinued in April 2017. Although, these blog posts will talk about it. The main reason is: Most of the experiments were done on Aurora, before it was stopped.
Today, the Android users who were on Aurora have been migrated to Nightly. New users are also given Nightly.
Why do we need Firefox for Android on app stores?
Unlike Firefox for desktop, Android apps have to be uploaded onto application stores (like Google Play Store). Otherwise, they have very low visibility. For instance, Firefox for Android Aurora (codenamed “Fennec Aurora”) was not on Google Play until September 2016, but it was downloadable from our official website (now redirected to Nightly). After we started publishing Aurora on Google Play, we increased our number of users by 5x.
Why are we automating the publication today?
Google didn’t offer a way to script a publication on Play Store, before July 2014. It had to be done manually, from their website. Around that time, a few people from Release Management implemented a first script. One person from the Release Management team ran it every time Beta or Release was ready, from his/her own machine. With Aurora being out, we now have several APKs (one per processor architecture/Android API level, which translates to 2 at the moment: one for x86 processors, the other for ARM) to publish each day.
The daily frequency was new for Fennec. It led to 2 concerns:
A human has to repeat the same task every day.
Pushing every day from a workstation increases the surface of security threats.
That is why we decided to make APK publication a part of the automated release workflow.
You may recall two short months ago when we moved Linux and Android nightlies from buildbot to TaskCluster. Due to the train model, this put us (release engineering) on a clock: either we’d be ready to release a beta version of Firefox 53 for Linux and Android using release promotion in TaskCluster, or we’d need to hold back our work for at least the next cycle, causing uplift headaches galore.
I’m happy to report that we were able to successfully release Firefox 53.0b1 for Linux and Android from TaskCluster last week. This is impressive for 3 reasons:
Mac and Windows builds were still promoted from buildbot, so we were able to seamlessly integrate the artifacts of two different continuous integration (CI) platforms.
The process whereby nightly builds are generated has always been different from how we generate release builds. Firefox 53.0b1 represents the first time a beta build was generated using the same taskgraph we use for a nightly, thereby reducing the delta between CI builds and release builds. More work to be done here, for sure.
Nobody noticed. With all the changes under the hood, this may be the most impressive achievement of all.
A round of thanks to Aki, Johan, Kim, and Mihai who worked hard to get the pieces in place for Android, and a special shout-out to Rail who handled the Linux beta while also dealing with the uplift requirements for ESR52. Of course, thanks to everyone else who has helped with the migration thus far. All of that foundational work is starting to pay off.
Much more to do, but I look forward to updating you about Mac and Windows progress soon.
I've had the opportunity to attend the Beyond the Code conference for the past two years. This year, the venue moved to a location in Toronto, the last two events had been held in Ottawa. The conference is organized by Shopify who again managed to have a really great speaker line up this year on a variety of interesting topics. It was a two track conference so I'll summarize some of the talks I attended.
The conference started off with Anna Lambert of Shopify welcoming everyone to the conference.
The first speaker was Atlee Clark, Director of App and Developer relations at Shopify who discussed the wheel of diversity.
The wheel of diversity is a way of mapping the characteristics that you're born with (age, gender, gender expression, race or ethnicity, national origin, mental/physical ability), along with those that you acquire through life (appearance, education, political belief, religion, income, language and communication skills, work experience, family, organizational role). When you look at your team, you can map how diverse it is by colour. (Of course, some of these characteristics are personal and might not be shared with others). You can see how diverse the team is by mapping different characteristics with different colours. If you map your team and it's mostly the same colour, then you probably will not bring different perspectives together when you work because you all have similar backgrounds and life experiences. This is especially important when developing products.
This wheel also applies to hiring too. You want to have different perspectives when you're interviewing someone. Atlee mentioned when she was hiring for a new role, she mapped out the characteristics of the people who would be conducting the hiring interviews and found there was a lot of yellow.
So she switched up the team that would be conducting the interviews to include people with more diverse perspectives.
She finished by stating that this is just a tool, keep it simple, and practice makes it better.
The next talk was by Erica Joy, who is a build and release engineer at Slack, as well as a diversity advocate. I have to admit, when I saw she was going to speak at Beyond the Code, I immediately pulled out my credit card and purchased a conference ticket. She is one of my tech heroes. Not only did she build the build and release pipeline at Slack from the ground up, she is an amazing writer and advocate for change in the tech industry. I highly recommend reading everything she has written on Medium, her chapter in Lean Out and all her discussions on twitter. So fantastic.
Her talk at the conference was "Building a Diverse Corporate Culture: Diversity and Inclusion in Tech". She talked about how literally thousands of companies say they value inclusion and diversity. However, few talk about what they are willing to give up to order to achieve it. Are you willing to give up your window seat with a great view? Something else so that others can be paid fairly? She mentioned that change is never free. People need both mentorship and sponsorship in in order to progress in their career.
I really liked her discussion around hiring and referrals. She stated that when you're hire people you already know you're probably excluding equally or better qualified that you don't know. By default, women of colour are underpaid.
Pay gap for white woman, African American women and Hispanic women compared to a white man in the United States.
Some companies have referral system to give larger referral bonuses to people who are underrepresented in tech, she gave the example of Intel which has this in place. This is a way to incentivize your referral system so you don't just hire all your white friends.
The average white American has 91 white friends and one black friend so it's not very likely that they will refer non-white people. Not sure what the numbers are like in Canada but I'd guess that they are quite similar.
In addition, don't ask people to work for free, to speak at conferences
or do diversity and inclusion work. Her words were "We can't pay rent
with exposure".
Spend time talking to diversity and inclusion experts. There are people that have spent their entire lives conducting research in this area and you can learn from their expertise. Meritocracy is a myth, we are just lucky to be in the right place in the right time. She mentioned that her colleague Duretti Hirpa at Slack points out the need for accomplices, not allies. People that will actually speak up for others. So people feeling pain or facing a difficult work environment don't have to do all the work of fighting for change.
In most companies, there aren't escalation paths for human issues either. If a person is making sexist or racist remarks, shouldn't that be a firing offense?
If people were really working hard on diversity and inclusion, we would see more women and people of colour on boards and in leadership positions. But we don't.
She closed with a quote from Beyonce:
"If everything was perfect, you would never learn and you would never grow"
💜💜💜
The next talk I attended was by Coraline Ada Ehmke, who is an application engineer at Github. Her talk was about the "Broken Promise of Open Source". Open source has the core principals of the free exchange of ideas, success through collaboration, shared ownership and meritocracy.
However, meritocracy is a myth. Currently, only 6% of Github users are women. The environment can be toxic, which drives a lot of people away. She mentioned that we don't have numbers for diversity in open source other than women, but Github plans to do a survey soon to try to acquire more data.
Gabriel Fayant from Assembly of Seven Generation's talk was entitled "Walking in Both Worlds, traditional ways of being and the world of technology". I found this quite interesting, she talked about traditional ceremonies and how they promote the idea of living in the moment, and thus looking at your phone during a drum ceremony isn't living the full experience. A question from the audience from someone who worked in the engineering faculty at the University of Toronto was how we can work with indigenous communities to share our knowledge of the technology and make youth both producers of tech, not just consumers.
If everything was perfect, you would never learn and you would never grow.
Read more at: http://www.brainyquote.com/quotes/quotes/b/beyoncekno596349.html
f everything was perfect, you would never learn and you would never grow.
Read more at: http://www.brainyquote.com/quotes/quotes/b/beyoncekno596349.html
The next talk was by Sandi Metz, entitled "Madame Santi tells your future". This was a totally fascinating look at the history of printing text from scrolls all the way to computers.
She gave the same talk at another conference earlier so you watch it here. It described the progression of printing technology from 7000 years ago until today. Each new technology disrupted the previous one, and it was difficult for those who worked on the previous technology to make the jump to work on the new one.
So according to Sandi, what is your future?
What you are working on now probably won't be relevant in 10 years
You will all die
All the people you love will die
Your body will start to fail you
Life is short
Tell people that you love them
Guard your health
Spend time with your kids
Get some exercise (she loves to bike)
We are bigger than tech
Community and schools need help
She gave the example of Habitat for Humanity where she volunteers
These organizations also need help to write code, they might not have the knowledge or time to do it right
The last talk I attended was by Sabrina Geremia of Google Canada. She talked about the factors that encourage a girl to consider computer science (encouragement, career perception, self-perception and academic exposure.)
I found that this talk was interesting but it focused a bit too much on the pipeline argument - that the major problem is that girls are not enrolling in CS courses. If you look at all the problems with environment, culture, lack of pay equity and opportunities for promotion due to bias, maybe choosing a career where there is more diversity is a better choice. For instance, law, accounting and medicine have much better numbers for these issues, despite there still being an imbalance.
At the end of the day, there was a panel to discuss diversity issues:
Moderator: Ariti Sharma, Shopify, Panelists: Mohammed Asaduallah, Format, Katie Krepps, Capital One Canada, Lateesha Thomas, Dev Bootcamp, Ramya Raghavan, Google, Kara Melton, TWG, Gladstone Grant, Microsoft Canada
Some of my notes from the panel
Be intentional about seeking out talent
Fix culture to be more diverse
Recruit from bootcamps. Better diversity today. Don't wait for universities to change the ratios.
Environment impacts retention
Conduct and engagement survey to see if underrepresented groups feel that their voices are being heard.
There is a need for sponsorship, not just mentoring. Define a role that doesn't exist at the company. A sponsor can make that role happen by advocating for it at higher levels
Mentors do better if matched with demographics. They will realize the challenges that you will face in the industry better than a white man who has never directly experienced sexism or racism.
Sponsors tend to be men due to the demographics of our industry
At Microsoft, when you reach a certain level your are expected to mentor an unrepresented person
Look at compensation and representation across diverse groups
Attrition is normal, it varies by region, especially acute in San Francisco.
Women leave companies at 2x the rate of men due to culture
You shouldn't stay at a place if you are burnt out, take care of yourself.
Compared to the previous two iterations of this conference, it seemed that this time it focused a lot more on solutions to have more diversity and inclusion in your company. The previous two conferences I attended seemed to focus more on technical talks by diverse speakers.
As a side note, there were a lot of Shopify folks in attendance because they ran the conference. They sent a bus of people from their head office in Ottawa to attend it. I was really struck at how diverse some of the teams were. I met group of women who described themselves as a team of "five badass women developers" 💯 As someone who has been the only woman on her team for most of her career, this was beautiful to see and gave me hope for the future of our industry. I've visited the Ottawa Shopify office several times (Mr. Releng works there) and I know that the representation of of their office doesn't match the demographics of the Beyond the Code attendees which tended to be more women and people of colour. But still, it is refreshing to see a company making a real effort to make their culture inclusive. I've read that it is easier to make your culture inclusive from the start, rather than trying to make difficult culture changes years later when your teams are all homogeneous. So kudos to them for setting an example for other companies.
Thank you Shopify for organizing this conference, I learned a lot and I look forward to the next one!
Last night, I attended my first Ottawa Python Authors Meetup. It was the first time that I had attended despite wanting to attend for a long time. (Mr. Releng also works with Python and thus every time there's a meetup, we discuss who gets to go and who gets to stay home and take care of little Releng. It depends on if the talk to more relevant to our work interests.)
The venue was across the street from Confederation Park aka land of Pokemon.
I really enjoyed it. The people I chatted with were very friendly and welcoming. Of course, I ran into some people I used to work with, as is with any tech event in Ottawa it seems. Nice to catch up!
The venue had the Canada Council for the Arts as a tenant, thus the quintessentially Canadian art.
The speaker that night was Emily Daniels, developer from Halogen Software who spoke on Artificial Intelligence with Python. (Slides here, github repo here). She mentioned that she writes Java during the day but works on fun projects in Python at night. She started the talk by going through some examples of artificial intelligence on the web. Perhaps the most interesting one I found was a recurrent neural network called Benjamin which generates movie script ideas and was trained on existing sci-fi movies and movie scripts. Also, a short film called Sunspring was made of one of the generated scripts. The dialogue is kind of stilted but it is interesting concept.
After the examples, Emily then moved on to how it all works.
Deep learning is a type of machine learning that drives meaning out of data using a hierarchy of multiple layers that mimics the neural networks of our brain.
She then spoke about a project she wrote to create generative poetry from a RNN (recurrent neural network). It was based on a RNN tutorial that she heavily refactored to meet her needs. She went through the code that she developed to generate artificial prose from the works of H.G. Wells and Jane Austen. She talked about how she cleaned up the text to remove EOL delimiters, page breaks, chapters numbers and so on. And then it took a week to train it with the data.
She then talked about another example which used data from Jack Kerouac and Virginia Woolf novels, which she posts some of the results to twitter.
She also created a twitter account which posts generated text from her RNN that consumes the content of Walt Whitman and Emily Dickinson. (I should mention at this point that she chose these authors for her projects because copyrights have expired on these works and they are available on the Gutenberg project)
After the talk, she field a number of audience questions which were really insightful. There were discussions on the inherent bias in the data because it was written by humans that are sexist and racist. She mentioned that she doesn't post the results of the model automatically to twitter because some of them are really inappropriate since these novels since they learned from text that humans wrote who are inherently biased.
One thing I found really interesting is that Emily mentioned that she felt a need to ensure that the algorithms and data continue to exist, and that they were faithfully backed up. I began to think about all the Amazon instances that Mozilla releng had automatically killed that day as our capacity had peaked and declined. And of the great joy I feel ripping out code when we deprecate a platform. I personally feel no emotional attachment to bring down machines or deleting used code.
Perhaps the sense of a need for a caretaker for these recurrent neural networks and the data they create is related to the fact that the algorithms that output text that is a simulacrum for the work of an author that we enjoy reading. And perhaps that is why we maybe we aren't as attached to a ephemeral pool of build machines as we are are to our phones. Because the phone provides a sense human of connection to the larger world when we may be sitting alone.
Thank you Emily for the very interesting talk, to the Ottawa Python Authors Group for organizing the meetup, and Shopify for sponsoring the venue. Looking forward to the next one!
I received this very kind email in my inbox this morning.
"David Williams has expired your commit rights to the
eclipse.platform.releng project. The reason for this change is:
We have all known this day would come, but it does not make it any easier.
It has taken me four years to accept that Kim is no longer helping us with
Eclipse. That is how large her impact was, both on myself and Eclipse as a
whole. And that is just the beginning of why I am designating her as
"Committer Emeritus". Without her, I humbly suggest that Eclipse would not
have gone very far. Git shows her active from 2003 to 2012 -- longer than
most! She is (still!) user number one on the build machine. (In Unix terms,
that is UID 500). The original admin, when "Eclipse" was just the Eclipse
Project.
She was not only dedicated to her job as a release engineer she was
passionate about doing all she could to make other committer's jobs easier
so they could focus on their code and specialties. She did (and still does)
know that release engineering is a field of its own; a specialized
profession (not something to "tack on" at the end) that just anyone can do)
and good, committed release engineers are critical to the success of any
project.
For anyone reading this that did not know Kim, it is not too late: you can
follow her blog at
You will see that she is still passionate about release engineering and
influential in her field.
And, besides all that, she was (I assume still is :) a well-rounded, nice
person, that was easy to work with! (Well, except she likes running for
exercise. :)
Thanks, Kim, for all that you gave to Eclipse and my personal thanks for
all that you taught me over the years (and I mean before I even tried to
fill your shoes in the Platform).
We all appreciate your enormous contribution to the success of Eclipse and
happy to see your successes continuing.
To honor your contributions to the project, David Williams has nominated
you for Committer Emeritus status."
Thank you David! I really appreciate your kind words. I learned so much working with everyone in the Eclipse community. I had the intention to contribute to Eclipse when I left IBM but really felt that I have given all I had to give. Few people have the chance to contribute to two fantastic open source communities during their career. I'm lucky to have that opportunity.
My IBM friends made this neat Eclipse poster when I left. The Mozilla dino displays my IRC handle.
The CFP for Releng 2016 is open! The workshop will be held November 18, 2016 in Seattle. It will be held in conjunction with FSE 2016. (Foundations of Software Engineering ACM conference)
Migrated to a new build or continuous integration system
Implemented a new release or deployment pipeline
Implemented tooling to simplify managing your apps in a mobile store
Significantly reduced build time with parallelization or some other interesting optimization!
Moved your build and test system to containers
Refactored your infrastructure code for a live production environment
... we'd love to see your submission to the workshop
We'd like to encourage people new to speaking to apply, as
well as those from underrepresented groups in tech. We'd love to hear from some new voices and new companies !
Submissions are due July 1, 2016. If you have questions on of the submission process, topics to submit, or anything else, I'm happy to help! I'm kmoir and I work at mozilla.com or contact me on twitter. Submit early and often!
Last week I attended DevOpsDays Toronto. It was my first time attending a DevOpsDays event and it was quite interesting. It was held at CBC's Glenn Gould studios which is a quick walk from the Toronto Island airport where I landed after an hour flight from Ottawa. This blog post is an overview of some of the talks at the conference.
Glenn Gould Studios, CBC, Toronto.
Statue of Glenn Gould outside the CBC studios that bear his name.
Day 1
The day started out with an introduction from the organizers and a brief overview of history of DevOps days. They also made a point about reminding everyone that they had agreed to the code of conduct when they bought their ticket. I found this explicit mention of the code of conduct quite refreshing.
The first talk of the day was John Willis, evangelist at Docker. He gave an overview of the state of enterprise devops. I found this a fresh perspective because I really don't know what happens in enterprises with respect to DevOps since I have been working in open source communities for so long. John providing an overview of what DevOps encompasses.
DevOps is a continuous feedback loop.
He talked a lot about how empathy is so important in our jobs. He mentions that at Netflix has a slide deck that describes company culture. He doesn't know if this is still the case, but it he had heard that if you hadn't read the company culture deck and show up for an interview at Netflix, you would be automatically disqualified for further interviews. Etsy and Spotify have similar open documents describing their culture.
Here he discusses the research by Christina Maslach on the six sources of burnout.
Christina Maslach
Christina Maslach
He gave us some reading to do. I've read the "Release It!" book which is excellent and has some fascinating stories of software failure in it, I've added the other books to my already long reading list.
The rugged manifesto and realizing that the code you write will always be under attack by malicious authors. ICE stands for Inclusivity, Complexity and Empathy.
He stated that it's a long standing mantra that you can have two of either fast, cheap or good but recent research shows that today we can many changes quickly, and if there is a failure the mean time to recovery is short.
He left us with some more books to read.
The second talk was a really interesting talk by Hany Fahim, CEO of VM Farms. It was a short mystery novella describing how VM Farms servers suddenly experienced a huge traffic spike when the Brazilian government banned Whatsapp as a result of a legal order. I love a good war story.
Hany discussed one day VMfarms suddenly saw a huge increase in traffic.
This was a really important point. When your system is failing to scale, it's important to decide if it's a valid increase in traffic or malicious.
Looking on twitter, they found that a court case in Brazil had recently ruled that Whatsup would be blocked for 48 hours. Users started circumventing this block via VPN. Looking at their logs, they determined that most of the traffic was resolving to ip addresses from Brazil and that there was a large connection time during SSL handshakes.
In conclusion, making changes to use multi-core HAProxy fixed a lot of issues. Also, twitter was and continues to be a great source of information on activity that is happening in other countries. Whatsapp was returned to service and then banned a second time, and their servers were able to keep up with the demand.
After lunch, we were back to to more talks. The organizers came on stage for a while to discuss the afternoon's agenda. They also remarked that one individual had violated the code of conduct and had been removed from the conference. So, the conference had a code of conduct and steps were taken if it was violated.
Next up, Bridget Kromhout from Pivotal gave a talk entitled Containers will not Fix your Broken Culture. I first saw Bridget speak at Beyond the Code in Ottawa in 2014 about scaling the streaming services for Drama Fever on AWS. At the time, I was moving our mobile test infrastructure to AWS so I was quite enthralled with her talk because 1) it was excellent 2) I had never seen another woman give a talk about scaling services on AWS. Representation matters.
The summary of the talk last week was that no matter what tools you adopt, you need to communicate with each other about the cultural changes are required to implement new services. A new microservices architecture is great, but if these teams that are implementing these services are not talking to each other, the implementation will not succeed.
Bridget pointing out that the technology we choose to implement is often about what is fashionable.
Shoutout to Jennifer Davis' and Katherine Daniel's Effective DevOps book. (note - I've read it on Safari online and it is excellent. The chapter on hiring is especially good)
Loved this poster about the wall of confusion between development and operations.
In the afternoon, there were were lightning talks and then open spaces. Open spaces are free flowing discussions where the topic is voted upon ahead of time. I attended ones on infrastructure automation, CI/CD at scale and my personal favourite, horror stories. I do love hearing how distributed system can go down and how to recover. I found that the conversations were useful but it seemed like some of them were dominated by a few voices. I think it would be better if the person that suggested to topic for the open space also volunteered to moderate the discussion.
Day 2
The second day started out with a fantastic talk by John Arthorne of Shopify speaking on scaling their deployment pipeline. As a side note, John and I worked together for more than a decade on Eclipse while we both worked at IBM so it was great to catch up with him after the talk.
He started by giving some key platform characteristics. Stores on
Shopify have flash sales that have traffic spikes so they need to be able to scale
for these bursts of traffic.
From commit to deploy in 10 minutes. Everyone can deploy. This has two purposes: Make sure the developer stays involved in the deploy process. If it only takes 10 minutes, they can watch to make sure that their deploy succeeds. If it takes longer, they might move on to another task. Another advantage of this quick deploy process is that it can delight customers with the speed of deployment. They also deploy in small batches to ensure that the mean time to recover is small if the change needs to be rolled back.
BuildKite is a third party build and test orchestration service. They wrote a tool called Scrooge that monitors the number of EC2 nodes based on current demand to reduce their AWS bills. (Similar to what Mozilla releng does with cloud-tools)
Shopify uses a open source orchestration tool called ShipIt. I was sitting next to my colleague Armen at the conference and he started chuckling at this point because at Mozilla we also wrote an application called ship-it which release management uses to kick off Firefox releases. Shopify also has a overall view of the ship it deployment process which allows developers to see the percentages of nodes where their change has been deployed. One of the questions after the talk was why they use AWS for their deployment pipeline when they have use machines in data centres for their actual customers. Answer: They use AWS where resilency is not an issue.
Building containers is computationally expensive. He noted that a lot of
engineering resources went into optimizing the layers in the Docker
containers. To isolate changes to the smallest layer. They build
service called Locutus to build the containers on commit, and push to a
registry. It employs caching to make the builds smaller.
One key point that John also mentioned is that they had a team dedicated to optimizing their deployment pipeline. It is unreasonable to expect that developers working on the core Shopify platform to also optimize the pipeline.
In the afternoon , there were a series of lightning talks. Roderick Randolph from Capital One gave an amazing talk about Supporting Developers through DevOps.
It was an interesting perspective. I've seen quite a few talks about bringing devops culture and practices to the operations side of the house, but the perspective of teaching developers about it is discussed less often.
He emphasized the need to empower developers to use DevOp practices by giving them tools, and showing them how to use them. For instance, if they needed to run docker to test something, walk them through it so they will know how to do it next time.
The final talk I'll mention is by Will Weaver. He talks about how it is hard to show prospective clients how he had CI and tests experience when that experience is not open to the public. So he implemented tests and CI for his dotfiles on github.
He had excellent advice on how to work on projects outside of work to showcase skills for future employers.
Diversity and Inclusion
As an aside, whenever I'm at a conference I note the number of people in the "not a white guy" group. This conference had an all men organizing committee but not all white men. (I recognize the fact that not all diversity is visible i.e. mental health, gender identity, sexual orientation, immigration status etc) They was only one woman speaker, but there were a few non-white speakers. There were very few women attendees. I'm not sure what the process was to reach out to potential speakers other than the CFP.
There were slides that showed diverse developers which was refreshing.
Loved Roderick's ops vs dev slide.
I learned a lot at the conference and am thankful for all the time that the speakers took to prepare their talks. I enjoyed all the conversations I had learning about the challenges people face in the organizations implementing continuous integration and deployment. It also made me appreciate the culture of relentless automation, continuous integration and deployment that we have at Mozilla.
I don't know who said this during the conference but I really liked it
Shipping is the heartbeat of your company
It was interesting to learn how all these people are making their companies heart beat stronger via DevOps practices and tools.
We're delighted to have Francis Kang and Connor Sheehan join the Mozilla release engineering team as summer interns. Francis is studying at the University of Toronto while Connor attends McMaster University in Hamilton, Ontario. We'll have another intern (Anthony) join us later on in the summer who will be working from our San Francisco office.
Francis and Connor will be working on implementing some new features in release promotion as well as migratingsome builds to taskcluster. I'll be mentoring Francis, while Rail will be mentoring Connor. If you are in the Toronto office, please drop by to say hi to them. Or welcome them on irc as fkang or sheehan.
Kim, Francis, Connor and Rail
They are both already off to a great start and have pull requests merged into production that fixed some release promotion issues. Their code was used in the Firefox 47.0 beta 5 release promotion that we ran last night so their first week was quite productive.
Mentoring an intern provides an opportunity to see the systems we run from a fresh perspective. They both have lots of great questions which makes us revisit why design decisions were made, could we do things better? Like all teaching roles, I always find that I learn a tremendous amount from the experience, and hope they have fun learning real world software engineering concepts with respect to running large distributed systems.
It was a busy week with many releases in flight, as well as preparation for running beta 1 with release promotion next week. We also are in the process of adding more capacity to certain test platform pools to lower wait times given all the new e10s tests that have been enabled.
Improve Release Pipeline:
Nick ran a staging release for 46.0b1 to check for issues before the merge, preventing some bustage for Fennec and ensuring we can fall back to the old system if any unexpected issues show up with release promotion
Dustin deployed a new version of the TaskCluster tools/login system with much improved UI for handling signing in and out and editing clients and roles. He also simplified the existing roles, with the result that the set of roles now fits on one screen, and is entirely composed of human-readable names. All of this works toward two important goals: building a sign-in system that is useful and usable by all mozillians; and configuring the access-control system to give everyone their appropriate permissions and no more.
Release:
The releases calendar is getting busier as we get closer to the end of the cycle. Many releases were shipped or are still in-flight:
Firefox 45.0b10
Fennec 45.0b11
Fennec 45.0 (in-progress)
Firefox 45.0 (in-progress) - we shipped the RC to the beta channel
It was a busy week for release engineering as several team members travelled to the Vancouver office to sprint on the release promotion project. The goal of the release promotion project is to promote continuous integration builds to release channels, allowing us to ship releases much more quickly.
Improve Release Pipeline:
Chris, Jordan, Callek (remotely), Kim, Mihai and Rail had a sprint on Release Promotion. We made so much progress on this project that we decided to use the new process for Firefox 46.0b1. https://bugzil.la/1118794 So many green jobs!
Mihai added a functionality in tctalker to walk the graph and cancel all pending/running tasks. He also added release sanity check logic for en-US binaries within promotion.
Alin landed changes to run mochitest-push-e10s tests on Windows 7 https://bugzil.la/1248729. This is another step toward completing the enabling of e10s tests.
I'm not a manager (but I interview Mozilla releng candidates)
I'm not looking for a new job.
These are just my observations after working in the tech industry for a long time.
I'm kind of a resume and interview nerd. I like helping friends fix their resumes and write amazing cover letters. In the past year I've helped a few (non-Mozilla) friends fix up their resumes, write cover letters, prepare for interviews as they search for new jobs. This post will discuss some things I've found to be helpful in this process.
Preparation
Everyone tends to jump into looking at job descriptions and making their resume look pretty. Another scenario is that people have a sudden realization that they need to get out of their current position and find a new job NOW and frantically start applying for anything that matches their qualifications. Before you do that, take a step back and make a list of things that are important to you. For example, when I applied at Mozilla, my list was something like this
learn release engineering at scale + associated tools/languages
open source
no relocation
work on a team of release engineers (not be the only one)
good team dynamics - people happy to share knowledge and like to ship
work in an organization where release engineering is valued for increasing the productivity of the organization as a whole and is funded (hardware/software/services/training) accordingly
support to attend and present at conferences
People spend a lot of time at work. Life is too short to be unhappy every day. Writing a list of what is important serves as a checklist to when you are looking at job descriptions and immediately weed out the ones that don't match your list.
People tend focus a lot on the technical skills they want to use or new ones you want to learn. You should also think about what kind of culture where you want to work. Do the goals and ethics of the organization align with your own? Who will you be working with? Will you enjoy working with this team? Are you interested in remote work or do you want to work in an office? How will a long commute impact or relocation your quality of life? What is the typical career progression of someone in this role? Are there both management and technical tracks for advancement?
To summarize, itemize the skills you'd like to use or learn,
the culture of the company and the team and why you want to work there.
Cover letter
Your cover letter should succinctly map your existing skills to the role you are applying for and convey enthusiasm and interest. You don't need to have a long story about how you worked on a project at your current job that has no relevance to your potential new employer. Teams that are looking to hire have problems to solve. Your cover letter needs to paint a picture that your have the skills to solve them.
Picture by Jim Bauer - Creative Commons Attribution-NonCommercial-NoDerivs 2.0 Generic (CC BY-NC-ND 2.0) https://www.flickr.com/photos/lens-cap/10320891856/sizes/l
Refactoring your resume
Developers have a lot of opportunities these days, but if you intend to move from another industry, into a tech company, it can be more tricky. The important thing is to convey the skills you have in a a way that people can see they can be applied to the problems they want to hire you to fix.
Many people describe their skills and accomplishments in a way that is too company specific. They may have a list of acronyms and product names on their resume that are unlikely to be known by people outside the company. When describing the work you did in a particular role, describe the work that you did in a that is measurable way that highlights the skills you have. An excellent example of a resume that describes the skills that without going into company specific detail is here. (Julie Pagano also has a terrific post about how she approached her new job search.)
Another tip is to leave out general skills that are very common. For instance, if you are a technical writer, omit the fact that you know how to use Windows and Word and focus on highlighting your skills and accomplishments.
Non-technical interview preparation
Every job has different technical requirements and there are many books and blog posts on how to prepare for this aspect of the interview process. So I'm going to just cover the non-technical aspects.
When I interview someone, I like to hear lots of questions. Questions about the work we do and upcoming projects. This indicates that have taken the time to research the team, company and work that we do. It also shows that enthusiasm and interest.
Here is a list suggestions to prepare for interviews
1. Research the company make a list of relevant questions
Not every company is open about the work that they do, but most will be
have some public information that you can use to formulate questions
during the interviews. Do you know anyone you can have coffee or skype with to who works for the company and can provide insight? What products/services do the company produce? Is the product nearing end of life? If so, what will it be replaced by? What is the companies market share, is it declining, stable or experiencing growth? Who are their main competitors? What are some of the challenges they face going forward? How will this team help address these challenges?
2. Prepare a list of questions for every person that interviews you ahead of time
Many companies will give you the list of names of people who will interview you.
Have they recently given talks? Watch the videos online or read the slides.
Does the team have github or other open repositories? What are recent projects are they working on? Do they have a blog or are active on twitter? If so, read it and formulate some questions to bring to the interview.
Do they use open bug tracking tools? If so, look at the bugs that have recent activity and add them to the list of questions for your interview.
A friend of mine read the book of a person that interviewed him had written and asked questions about the book in the interview. That's serious interview preparation!
Photo by https://www.flickr.com/photos/wocintechchat/ https://www.flickr.com/photos/wocintechchat/22506109386/sizes/l
3. Team dynamics and tools
Is the team growing or are you hiring to replace somebody who left?
What's the onboarding process like? Will you have a mentor?
How is this group viewed by the rest of the company? You want to be in a role where you can make a valuable contribution. Joining a team where their role is not valued by the company or not funded adequately is a recipe for disappointment.
What does a typical day look like? What hours do people usually work?
What tools do people use? Are there prescribed tools or are you free to use what you'd like?
4. Diversity and Inclusion
If you're a member of an underrepresented group in tech, the numbers are lousy in this industry with some notable exceptions. And I say that while recognizing that I'm personally in the group that is the lowest common denominator for diversity in tech.
I don't really have good advice for this area other than do your research to ensure you're not entering a toxic environment. If you look around the office where you're being interviewed and nobody looks like you, it's time for further investigation. Look at the company's website - is the management team page white guys all the way down? Does the company support diverse conferences, scholarships or internships? Ask on a mailing list like devchix if others have experience working at this company and what it's like for underrepresented groups. If you ask in the interview why there aren't more diverse people in the office and they say something like "well, we only hire on merit" this is a giant red flag. If the answer is along the lines of "yes, we realize this and these are the steps we are taking to rectify this situation", this is a more encouraging response.
A final piece of advice, ensure that you meet with your manager that you're going to report to as part of your hiring process. You want to ensure that you have rapport with them and can envision a productive working relationship.
What advice do you have for people preparing to find a new job?
You may have noticed that Windows has had no updates for Nightly for the last week or so. We’ve had a few issues with signing the binaries as part of moving from a SHA-1 certificate to SHA-2. This needs to be done because Windows won’t accept SHA-1 signed binaries from January 1 2016 (this is tracked in bug 1079858).
Updates are now re-enabled, and the update path looks like this
older builds → 20151209095500 → latest Nightly
Some people may have been seeing UAC prompts to run the updater, and there could be one more of those when updating to the 20151209095500 build (which is also the last SHA-1 signed build). Updates from that build should not cause any UAC prompts.
November 13th, I attended the USENIX Release Engineering Summit in Washington, DC. This summit was along side the larger LISA conference at the same venue. Thanks to Dinah McNutt, Gareth Bowles, Chris Cooper, Dan Tehranian and John O'Duinn for organizing.
I gave two talks at the summit. One was a long talk on how we have scaled our Android testing infrastructure on AWS, as well as a look back at how it evolved over the years.
Picture by Tim Norris - Creative Commons Attribution-NonCommercial-NoDerivs 2.0 Generic (CC BY-NC-ND 2.0)
https://www.flickr.com/photos/tim_norris/2600844073/sizes/o/
I gave a second lightning talk in the afternoon on the problems we face with our large distributed continuous integration, build and release pipeline, and how we are working to address the issues. The theme of this talk was that managing a large distributed system is like being the caretaker for the water, or some days, the sewer system for a city. We are constantly looking system leaks and implementing system monitoring. And probably will have to replace it with something new while keeping the existing one running.
Picture by Korona Lacasse - Creative Commons 2.0 Attribution 2.0 Generic https://www.flickr.com/photos/korona4reel/14107877324/sizes/l
In preparation for this talk, I did a lot of reading on complex systems
design and designing for recovery from failure in distributed systems. In particular, I read Donatella Meadows' book Thinking in Systems. (Cate Huston reviewed the book here).
I also watched several talks by people who talked about the challenges
they face managing their distributed systems including the following:
I'd also like to thank all the members of Mozilla releng/ateam who reviewed my slides and provided feedback before I gave the presentations.
The attendees of the summit attended the same keynote as the LISA attendees. Jez Humble, well known for his Continuous Delivery and Lean Enterprise books provided a keynote on Lean Configuration Management which I really enjoyed. (Older version of slides from another conference, are available here and here.)
In particular, I enjoyed his discussion of the cultural aspects of devops. I especially like that he stated that "You should not have to have planned downtime or people working outside business hours to release". He also talked a bit about how many of the leaders that are looked up to as visionaries in the tech industry are known for not treating people very well and this is not a good example to set for others who believe this to be the key to their success. For instance, he said something like "what more could Steve Jobs have accomplished had he treated his employees less harshly".
Another concept he discussed which I found interesting was that of the strangler application. When moving from a large monolithic application, the goal is to split out the existing functionality into services until the originally application is left with nothing. Exactly what Mozilla releng is doing as we migrate from Buildbot to taskcluster.
At the release engineering summit itself, Lukas Blakk from Pinterest gave a fantastic talk Stop Releasing off Your Laptop—Implementing a Mobile App Release Management Process from Scratch in a Startup or Small Company. This included grumpy cat picture to depict how Lukas thought the rest of the company felt when that a more structured release process was implemented.
Lukas also included a timeline of the tasks that implemented in her first six months working at Pinterest. Very impressive to see the transition!
Another talk I enjoyed was Chaos Patterns - Architecting for Failure in Distributed Systems
by Jos Boumans of Krux. (Similar slides from an earlier conference here). He talked about some high profile distributed systems that failed and how chaos engineering can help illuminate these issues before they hit you in production.
For instance, it is impossible for Netflix to model their entire system outside of production given that they consume around one third of nightly downstream bandwidth consumption in the US.
Evan Willey and Dave Liebreich from Pivotal Cloud Foundry gave a talk entitled "Pivotal Cloud Foundry Release Engineering: Moving Integration Upstream Where It Belongs". I found this talk interesting because they talked about how the built Concourse, a CI system that is more scaleable and natively builds pipelines. Travis and Jenkins are good for small projects but they simply don't scale for large numbers of commits, platforms to test or complicated pipelines. We followed a similar path that led us to develop Taskcluster.
There were many more great talks, hopefully more slides will be up soon!
to provide a stable location for scripted downloads. There are similar links for betas and extended support releases for organisations. Read on to learn how these directories have changed, and how you can continue to download the latest releases.
Until recently these directories were implemented using a symlink to the current version, for example firefox/releases/42.0/. The storage backend has now changed to Amazon S3 and this is no longer possible. To implement the same functionality we’d need a duplicate set of keys, which incurs more maintenance overhead. And we already have a mechanism for delivering files independent of the current shipped version – our download redirector Bouncer. For example, here’s the latest release for Windows 32bit, U.S. English:
Modifying the product, os, and/or lang allow other combinations. This is described in the README.txt files for beta, release, and esr, as well as the Thunderbird equivalents release and beta.
Please adapt your scripts to use download.mozilla.org links. We hope it will help you simplify at the same time, as scraping to determine the current version is no longer necessary.
PS. We’ve also removed some latest- directories which were old and crufty, eg firefox/releases/latest-3.6.
Today we started serving an important set of directories on ftp.mozilla.org using Amazon S3, more details on that over in the newsgroups. Some configuration changes landed in the tree to make that happen.
Please rebase your try pushes to use revision 0ee21e8d5ca6 or later, currently on mozilla-inbound. Otherwise your builds will fail to upload, which means they won’t run any tests. No fun for anyone.
In September, Mozilla release engineering started experiencing high pending counts on our test pools, notably Windows, but also Linux (and consequently Android). High pending counts mean that there are thousands of jobs queued to run on the machines that are busy running other jobs. The time developers have to wait for their test results is longer than ideal.
Usually, pending counts clear overnight as less code is pushed during the night (in North America) which invokes fewer builds and tests. However, as you can see from the graph above, the Windows test pending counts were flat last night. They did not clear up overnight. You will also note that try, which usually comprises 63% of our load, has very highest pending counts compared to other branches. This is because many people land on try before pushing to other branches, and tests aren't coalesced on try.
The work to determine the cause of high pending counts is always an interesting mystery.
Are end to end times for tests increasing?
Have more tests been enabled recently?
Are retries increasing? (Tests the run multiple times because the initial runs fail due to infrastructure issues)
Are jobs that are coalesced being backfilled and consuming capacity?
Are tests being chunked into smaller jobs that increase end to end time due to the added start up time?
Joel Maher and I looked at the data for this last week and discovered what we believe to be the source of the problem. We have determined that since the end of August a
number of new test jobs were enabled that increased the compute time per push on
Windows by 13% or 2.5 hours per push. Most of these new test jobs are for
e10s.
Increase in seconds that new jobs added to the total compute time per push. (Some existing jobs also reduced their compute time for a total difference about about 2.5 more hours per push on Windows)
The e10s initiative is an important initiative for Mozilla to make Firefox performance and security even better. However, since new e10s and old tests will continue to run in parallel, we need to get creative on how to have acceptable wait times given the limitations of our current Windows tests pools. (All of our Windows test run on bare metal in our
datacentre, not on Amazon).
Release engineering is working to reduce this pending counts given our current hardware constraints with the following initiatives:
To reduce Linux pending counts:
Added 200 new instances to the tst-emulator64 pool (run Android test jobs on Linux emulators) (bug 1204756)
In process of adding more Linux32 and Linux64 buildbot masters (bug 1205409) which will allow us to expand our capacity more
Ongoing work to reduce the Windows pending counts:
Disable Linux32 Talos tests and redeploy these machines as Windows test machines (bug 1204920 and bug 1208449)
Reduce the number of talos jobs by running SETA on talos (bug 1192994)
Developer productivity team is investigating whether non-operating specific tests that run on multiple windows test platforms can run on fewer platforms.
How can you help?
Please be considerate when invoking try pushes and
only select the platforms that you explicitly require to test. Each
try push for all platforms and all tests invokes over 800 jobs.
This spring, I took several online courses on the topic of data science. I became interested in expanding my skills in this area because as release engineers, we deal with a lot of data. I wanted to learn new tools to extract useful information from the distributed systems behemoth we manage.
This xckd reminded me of the challenges of managing our buildfarm somedays :-)
From http://xkcd.com/1546/
I took three courses from Coursera's Data Science track from John Hopkins University. As with previous coursera classes I took, all the course material is online (lecture videos and notes). There are quizzes and assignments that are due each week. Each course below was about four weeks long.
The Data Scientist's Toolbox - This course was pretty easy. Basically a introduction to the questions that data scientists deal as well a primer on installing R, RStudio (IDE for R), and using GitHub. R Programming - Introduction to R. Most of the quizzes and examples used publicly available data for the programming exercises. I found I had to do a lot of reading in the R API docs or on stackoverflow to finish the assignments. The lectures didn't provide a lot of the material needed to complete the assignments. Lots of techniques to learn how to subset data using R which I found quite interesting, reminded me a lot of querying databases with SQL to conduct analysis. Getting and Cleaning Data - More advanced techniques using R. Using publicly available data sources to clean different data sources in different formats, XML, excel spreadsheets, comma or tab delimited. Given this data, we had to answer many questions and conduct specific analysis by writing R programs. The assignments were pretty challenging and took a long time. Again, the course material didn't really cover all the material you needed to do the assignments so a lot of additional reading was required.
There are six more courses in the Data Science track that I'll start tackling again in the fall that cover subjects such as reproducible research, statistical inference and machine learning. My next coursera class is Introduction to Systems Engineering which I'll start in a couple of weeks. I've really become interested in learning more about this subject after reading Thinking in Systems.
The other course I took this spring was the Software Carpentry Instructor training course. The Software Carpentry Foundation teachers researchers basic software skills. For instance, if you are a biologist analyzing large data sets it would be useful to learn how to use R, Python, and version control to store the code you wrote to share with others. These are not skills that many scientists acquire in their formal university training, and learning them allows them to work more productively. The instructor course was excellent, thanks Greg Wilson for your work teaching us.
We read two books for this course: Building a Better Teacher: An interesting overview of how teacher is taught in different countries and how to make it more effective. Most important: Have more opportunities for other teachers to observe your classroom and provide feedback which I found analogous to how code review makes us better software developers. How Learning Works: Seven Research-Based Principles for Smart Teaching: A book summarizing the research in disciplines such as education, cognitive science and psychology on the effective techniques for teaching students new material. How assessing student's prior knowledge can help you better design your lessons, how to to ask questions to determine what material students are failing to grasp, how to understand student's motivation for learning and more. Really interesting research.
For the instructor course, we met every couple of weeks online where Greg would conduct a short discussion on some of the topics on a conference call and we would discuss via etherpad interactively. We would then meet in smaller groups later in the week to conduct practice teaching exercises. We also submitted example lessons to the course repo on GitHub. The final project for the course was to conduct a short lesson to a group of instructors that gave feedback, and submit a pull request to update an existing lesson with a fix. Then we are ready to sign up to teach a Software Carpentry course!
In conclusion, data science is a great skill to have if you are managing large distributed systems. Also, using evidence based teaching methods to help others learn is the way to go!
In an earlier post, I wrote how we had reduced the amount of test jobs that run on two branches to allow us to scale our infrastructure more effectively. We run the tests that historically identify regressions more often. The ones that don't, we skip on every Nth push. We now have data on how this reduced the number of jobs we run since we began implementation in April.
We run SETA on two branches (mozilla-inbound and fx-team) and on 18 types of builds. Collectively, these two branches represent about 20% of pushes each month. Implementing SETA allowed us to move from ~400 -> ~240 jobs per push on these two branches1 We run the tests identified as not reporting regressions on every 10th commit or 90 minutes since the last test was scheduled. We run the critical tests on every commit.2
Reduction in number of jobs per push on mozilla-inbound as SETA scheduling is rolled out
A graph for the fx-team branch shows a similar trend. It was a staged rollout starting in early April, as I enabled platforms and as the SETA data became available. The dip in early June reflects where I enabled SETA for Android 4.3.
This data will continue to be updated in our scheduling configuration as it evolves and is updated by the code that Joel and Vaibhav wrote to analyze regressions. The analysis identifies that there were
Jobs to ignore: 440
Jobs to run: 114
Total number of jobs: 554
which is significant. Our buildbot configurations are updated the latest SETA data with every reconfig, which occurs usually occurs every couple of days.
The platforms configured to run fewer tests for both opt and debug are
MacOSX (10.6, 10.10)
Windows (XP, 7, 8)
Ubuntu 12.04 for linux32, linux64 and ASAN x64
Android 2.3 armv7 API 9
Android 4.3 armv7 API 11+
Additional info 1Tests may have been disabled/added at the same time, this is not taken into account 2There still some scheduling issues to be fixed see bug 1174870 and bug 1174746 for further details
Running a large continuous integration farm forces you to deal with many dynamic inputs coupled with capacity constraints. The number of pushes increase. People add more tests. We build and test on a new platform. If the number of machines available remains static, the computing time associated with a single push will increase. You can scale this for platforms that you build and test in the cloud (for us - Linux and Android on emulators), but this costs more money. Adding hardware for other platforms such as Mac and Windows in data centres is also costly and time consuming.
Do we really need to run every test on every commit? If not, which tests should be run? How often do they need to be run in order to catch regressions in a timely manner (i.e. able to bisect where the regression occurred)
Several months ago, jmaher and vaibhav1994, wrote code to analyze the test data and determine the minimum number of tests required to run to identify regressions. They named their software SETA (search for extraneous test automation). They used historical data to determine the minimum set of tests that needed to be run to catch historical regressions. Previously, we coalesced tests on a number of platforms to mitigate too many jobs being queued for too few machines. However, this was not the best way to proceed because it reduced the number of times we ran all tests, not just less useful ones. SETA allows us to run a subset of tests on every commit that historically have caught regressions. We still run all the test suites, but at a specified interval.
In the last few weeks, I've implemented SETA scheduling in our our buildbot configs to use the data that the analysis that Vaibhav and Joel implemented. Currently, it's implemented on mozilla-inbound and fx-team branches which in aggregate represent around 19.6% (March 2015 data) of total pushes to the trees. The platforms configured to run fewer tests for both opt and debug are
MacOSX (10.6, 10.10)
Windows (XP, 7, 8)
Ubuntu 12.04 for linux32, linux64 and ASAN x64
Android 2.3 armv7 API 9
As we gather more SETA data for newer platforms, such as Android 4.3, we can implement SETA scheduling for it as well and reduce our test load. We continue to run the full suite of tests on all platforms other branches other than m-i and fx-team, such as mozilla-central, try, and the beta and release branches. If we did miss a regression by reducing the tests, it would appear on other branches mozilla-central. We will continue to update our configs to incorporate SETA data as it changes.
How does SETA scheduling work?
We specify the tests that we would like to run on a reduced schedule in our buildbot configs. For instance, this specifies that we would like to run these debug tests on every 10th commit or if we reach a timeout of 5400 seconds between tests.
Previously, catlee had implemented a scheduling in buildbot that allowed us to coallesce jobs on a certain branch and platform using EveryNthScheduler. However, as it was originally implemented, it didn't allow us to specify tests to skip, such as mochitest-3 debug on MacOSX 10.10 on mozilla-inbound. It would only allow us to skip all the debug or opt tests for a certain platform and branch.
I modified misc.py to parse the configs and create a dictionary for each test specifying the interval at which the test should be skipped and the timeout interval. If the tests has these parameters specified, it should be scheduled using the EveryNthScheduler instead of the default scheduler.
There are still some quirks to work out but I think it is working out well so far. I'll have some graphs in a future post on how this reduced our test load.
Here's April 2015's monthly analysis of the pushes to our Mozilla development trees. You can load the data as an HTML page or as a json file.
Trends
The number of pushes decreased from those recorded in the previous month with a total of 8894. This is due to the fact that gaia-try is managed by taskcluster and thus these jobs don't appear in the buildbot scheduling databases anymore which this report tracks.
Highlights
8894 pushes
296 pushes/day (average)
Highest number of pushes/day: 528 pushes on Apr 1, 2015
17.87 pushes/hour (highest average)
General Remarks
Try has around 58% of all the pushes now that we no longer track gaia-try
The three integration repositories (fx-team, mozilla-inbound and b2g-inbound) account around 28% of all the pushes.
Records
August 2014 was the month with most pushes (13090 pushes)
August 2014 had the highest pushes/day average with 422 pushes/day
July 2014 had the highest average of "pushes-per-hour" with 23.51 pushes/hour
October 8, 2014 had the highest number of pushes in one day with 715 pushes
Note
I've changed the graphs to only track 2015 data.
Last month they were tracking 2014 data as well but it looked
crowded so I updated them. Here's a graph showing the number of pushes over the last few years for comparison.
ftp.mozilla.org has been around for a long time in the world of Mozilla, dating back to original source release in 1998. Originally it was a single server, but it’s grown into a cluster storing more than 60TB of data, and serving more than a gigabit/s in traffic. Many projects store their files there, and there must be a wide range of ways that people use the cluster.
This quarter there is a project in the Cloud Services team to move ftp.mozilla.org (and related systems) to the cloud, which Release Engineering is helping with. It would be very helpful to know what functionality people are relying on, so please complete this survey to let us know. Thanks!
We migrated most of our Mac OS X 10.8 (Mountain Lion) test machines to 10.10.2 (Yosemite) this quarter.
This project had two major constraints:
1) Use the existing hardware pool (~100 r5 mac minis)
2) Keep wait times sane1. (The machines are constantly running tests most of the day due to the distributed nature of the Mozilla community and this had to continue during the migration.)
So basically upgrade all the machines without letting people notice what you're doing!
Why didn't we just buy more minis and add them to the existing pool of test machines?
We run performance tests and thus need to have all the machines running the same hardware within a pool so performance comparisons are valid. If we buy new hardware, we need to replace the entire pool at once. Machines with different hardware specifications = useless performance test comparisons.
We tried to purchase some used machines with the same hardware specs as our existing machines. However, we couldn't find a source for them. As Apple stops production of old mini hardware each time they announce a new one, they are difficult and expensive to source.
Given that Yosemite was released last October, why we are only upgrading our test pool now? We wait until the population of users running a new platform2 surpass those the old one before switching.
Mountain Lion -> Yosemite is an easy upgrade on your laptop. It's not as simple when you're updating production machines that run tests at scale.
The first step was to pull a few machines out of production and verify the Puppet configuration was working. In Puppet, you can specify commands to only run certain operating system versions. So we implemented several commands to accommodate changes for Yosemite. For instance, changing the default scrollbar behaviour, new services that interfere with test runs needed to be disabled, debug tests required new Apple security permissions configured etc.
Once the Puppet configuration was stable, I updated our configs so the people could run tests on Try and allocated a few machines to this pool. We opened bugs for tests that failed on Yosemite but passed on other platforms. This was a very iterative process. Run tests on try. Look at failures, file bugs, fix test manifests. Once we had to the opt (functional) tests in a green state on try, we could start the migration.
Migration strategy
Disable selected Mountain Lion machines from the production pool
Reimage as Yosemite, update DNS and let them puppetize
Reconfig so the buildbot master enable new Yosemite builders and schedule jobs appropriately
Repeat this process in batches
Enable Yosemite opt and performance tests on trunk (gecko >= 39) (50 machines)
Enable Yosemite debug (25 more machines)
Enable Yosemite on mozilla-aurora (15 more machines)
We currently have 14 machines left on Mountain Lion for mozilla-beta and mozilla-release branches.
As a I mentioned earlier, the two constraints with this project were to use the existing hardware pool that constantly runs tests in production and keep the existing wait times sane. We encountered two major problems that impeded that goal:
Persistent and increasing numbers of DNS failures as we migrated more machines to Yosemite. The default Yosemite configuration broadcasts multicast messages via Bonjour. This is fine for a few Apple devices talking to each other in your house. This doesn't scale for 100 machines in a colo. I saw many DNS timeout messages in the system log. This manifested itself large numbers of performance tests failing because they couldn't resolve the name of the graphing server to upload their results. We disabled this multicast broadcast via Puppet and our tests turned green again.
It's a compliment when people say things like "I didn't realize that you updated a platform" because it means the upgrade did not cause large scale fires for all to see. So it was a nice to hear that from one of my colleagues this week.
Thanks to philor, RyanVM and jmaher for opening bugs with respect to failing tests and greening them up. Thanks to coop for many code reviews. Thanks dividehex for reimaging all the machines in batches and to arr for her valiant attempts to source new-to-us minis!
References 1Wait times represent the time from when a job is added to the scheduler database until it actually starts running. We usually try to keep this to under 15 minutes but this really varies on how many machines we have in the pool. 2We run tests for our products on a matrix of operating systems and operating system versions. The terminology for operating system x version in many release engineering shops is a platform. To add to this, the list of platform we support varies across branches. For instance, if we're going to deprecate a platform, we'll let this change ride the trains to release.
The Apple EULA severely restricts virtualization on Mac hardware.
I don't know of any major cloud vendors that offer the Mac as a platform. Those that claim they do are actually renting racks of Macs on a dedicated per host basis. This does not have the inherent scaling and associated cost saving of cloud computing. In addition, the APIs to manage the machines at scale aren't there.
We manage ~350 Mac minis. We have more experience scaling Apple hardware than many vendors. Not many places run CI at Mozilla scale :-) Hopefully this will change and we'll be able to scale testing on Mac products like we do for Android and Linux in a cloud.
Here's February's 2015 monthly analysis of the pushes to our Mozilla development trees. You can load the data as an HTML page or as a json file.
Trends Although February is a shorter month, the number of pushes were close to those recorded in the previous month. We had a higher average number of daily pushes (358) than in January (348).
Highlights 10015 pushes 358 pushes/day (average) Highest number of pushes/day: 574 pushes on Feb 25, 2015 23.18 pushes/hour (highest)
General Remarks Try had around 46% of all the pushes The three integration repositories (fx-team, mozilla-inbound and b2g-inbound) account around 22% of all the pushes
Records August 2014 was the month with most pushes (13090 pushes) August 2014 has the highest pushes/day average with 422 pushes/day July 2014 has the highest average of "pushes-per-hour" with 23.51 pushes/hour October 8, 2014 had the highest number of pushes in one day with 715 pushes
The release engineering special issue of IEEE software was published yesterday. (Download pdf here). This issue focuses on the current state of release engineering, from both an industry and research perspective. Lots of exciting work happening in this field!
I'm interviewed in the roundtable article on the future of release engineering, along with Chuck Rossi of Facebook and Boris Debic of Google. Interesting discussions on the current state of release engineering at organizations that scale large number of builds and tests, and release frequently. As well, the challenges with mobile releases versus web deployments are discussed. And finally, a discussion of how to find good release engineers, and what the future may hold.
Thanks to the other guest editors on this issue - Stephany Bellomo, Tamara Marshall-Klein, Bram Adams, Foutse Khomh and Christian Bird - for all their hard work that make this happen!
As an aside, when I opened the issue, the image on the front cover made me laugh. It's reminiscent of the cover on a mid-century science fiction anthology. I showed Mr. Releng and he said "Robot birds? That is EXACTLY how I pictured working in releng." Maybe it's meant to represent that we let software fly free. In any case, I must go back to tending the flock of robotic avian overlords.
FileMerge is a nice diff and merge tool for OS X, and I use it a lot for larger code reviews where lots of context is helpful. It also supports intra-line diff, which comes in pretty handy.
However in recent releases, at least in v2.8 which comes as part of XCode 6.1, it assumes you want to be merging and shows that bottom pane. Adjusting it away doesn’t persist to the next time you use it, *gnash gnash gnash*.
The solution is to open a terminal and offer this incantation:
defaults write com.apple.FileMerge MergeHeight 0
Unfortunately, if you use the merge pane then you’ll have to do that again. Dear Apple, pls fix!
Here's January 2015's monthly analysis of the pushes to our Mozilla development trees. You can load the data as an HTML page or as a json file.
Trends
We're back to regular volume after the holidays. Also, it's really cold outside in some parts of the of the Mozilla world. Maybe committing code > going outside.
Highlights
10798 pushes
348 pushes/day (average)
Highest number of pushes/day: 562 pushes on Jan 28, 2015
18.65 pushes/hour (highest)
General Remarks
Try had around around 42% of all the pushes
The three integration repositories (fx-team, mozilla-inbound and b2g-inbound) account around 24% of all of the pushes
Records
August 2014 was the month with most pushes (13,090 pushes)
August 2014 has the highest pushes/day average with 422 pushes/day
July 2014 has the highest average of "pushes-per-hour" with 23.51 pushes/hour
October 8, 2014 had the highest number of pushes in one day with 715 pushes
migrating your build or test pipeline to the cloud
switching to a new build system
migrating to a new version control system
optimized your configuration management system or switched to a new one
implemented continuous integration for mobile devices
reduced end to end build times
or anything else build, release, configuration and test related
we'd love to hear from you. Please consider submitting a talk!
In addition, if you have colleagues that work in this space that might have interesting topics to discuss at this workshop, please forward this information. I'm happy to talk to people about the submission process or possible topics if there are questions.
Sono nel comitato che organizza la conferenza Releng 2015 che si terrà il 19 Maggio 2015 a Firenze. La scadenza per l’invio dei paper è il 23 Gennaio 2015.
migrazione del sistema di build o dei test nel cloud
aggiornamento del processo di build
migrazione ad un nuovo sistema di version control
ottimizzazione o aggiornamento del configuration management system
implementazione di un sistema di continuos integration per dispositivi mobili
riduzione dei tempi di build
qualsiasi cambiamento che abbia migliorato il sistema di build/test/release
e volete discutere della vostra esperienza, inviateci una proposta di talk!
Per favore inoltrate questa richiesta ai vostri colleghi e alle persone interessate a questi argomenti. Nel caso ci fossero domande sul processo di invio o sui temi di discussione, non esitate a contattarmi.
(Thanks Massimo for helping with the Italian translation).
Mozilla’s Release Engineering team has been through several major iterations of our “release automation”, which is how we produce the bits for Firefox betas and releases. With each incarnation, the automation has become more reliable, supported more functionality, and end-to-end time has reduced. If you go back a few years to Firefox 2.0 it took several days to prepare 40 or so locales and three platforms for a release; now it’s less than half a day for 90 locales and four platforms. The last major rewrite was some time ago so it’s time to embark on a big revamp – this time we want to reduce the end-to-end time significantly.
Currently, when a code change lands in the repository (eg mozilla-beta) a large set of compile and test jobs are started. It takes about 5 hours for the slowest platform to complete an optimized build and run the tests, in part because we’re using Profile-Guided Optimization (PGO) and need to link XUL twice. Assuming the tests have passed, or been recognized as an intermittent failure, a Release Manager will kick off the release automation. It will tag the gecko and localization repositories, and a second round of compilation will start, using the official branding and other release-specific settings. Accounting for all the other release work (localized builds, source tarballs, updates, and so on) the automation takes 10 or more hours to complete.
The first goal of the revamp is to avoid the second round of compilation, with all the loss of time and test coverage it brings. Instead, we’re looking at ‘promoting’ the builds we’ve already done (in the sense of rank, not marketing). By making some other improvements along the way, eg fast generation of partial updates using funsize, we may be able to save as much as 50% from the current wall time. So we’ll be able to ship fixes to beta users more often than twice a week, get feedback earlier in the cycle, and be more confident about shipping a new release. It’ll help us to ship security fixes faster too.
We’re calling this ‘Build Promotion’ for short, and you can follow progress in Bug 1118794 and dependencies.
Here's December 2014's monthly analysis of the pushes to our Mozilla development trees. You can load the data as an HTML page or as a json file.
Trends
There was a low number of pushes this month. I expect this is due to the Mozilla all-hands in Portland in early December where we were encouraged to meet up with other teams instead of coding :-) and the holidays at the end of the month for many countries.
As as side node, in 2014 we had a total number of 124423 pushes, compared to 79233 in 2013 which represents a growth rate of 57% this year.
Highlights
7836 pushes
253 pushes/day (average)
Highest number of pushes/day: 706 pushes on Dec 17, 2014
15.25 pushes/hour (highest)
General Remarks
Try had around around 46% of all the pushes
The three integration repositories (fx-team, mozilla-inbound and b2g-inbound) account around 23% of all of the pushes
Records
August 2014 was the month with most pushes (13,090 pushes)
August 2014 has the highest pushes/day average with 422 pushes/day
July 2014 has the highest average of "pushes-per-hour" with 23.51 pushes/hour
October 8, 2014 had the highest number of pushes in one day with 715 pushes
ZNC is great for having a persistent IRC connection, but it’s not so great when the IRC server or network has a blip. Then you can end up failing to rejoin with
The way to fix this is to limit the number of channels ZNC can connect to simultaneously. In the Web UI, you change ‘Max Joins’ preference to something like 5. In the config file use ‘MaxJoins = 5’ in a <User foo> block.
We’ve removed the rsync modules mozilla-current and mozilla-releases today, after calling for comment a few months ago and hearing no objections. Those modules were previously used to deliver Firefox and other Mozilla products to end users via a network of volunteer mirrors but we now use content delivery networks (CDN). If there’s a use case we haven’t considered then please get in touch in the comments or on the bug.
Mozilla Release Engineering provides some simple trending of the Buildbot continuous integration system, which can be useful to check how many jobs are currently running versus pending. There are graphs of the last 24 hours broken out in various ways – for example compilation separate from tests, compilation on try and everything else. This data also feeds into the pending queue on trychooser.
Until recently the mapping of job name to machine pool was out of date, due to our rapid growth for b2g and into Amazon’s AWS, so the graphs were more misleading than useful. This has now been corrected and I’m working on making sure it stays up to date automatically.
Update: Since July 18 the system stays up to date automatically, in just about all cases.
So in Part 1 and 2, we saw how Buildbot tegra and panda masters can assign jobs to Buildbot slaves, and that these slaves run on foopies, and that these foopies then connect to the SUT Agent on the device, to deploy and perform the tests, and pull back results.
However, over time, since these devices can fail, how do we make sure they are running ok, and handle the case that they go awol?
The answer has two parts:
watch_devices.sh
mozpool
What is watch_devices.sh?
You remember that in Part 2, we said you need to create a directory under /builds on the foopy for any device that foopy should be taking care of.
This script will look for device directories under /tools to see which devices are associated to this foopy. For each of these, it will check there is a buildbot slave running for that device. It handles the case of automatically starting buildbot slaves as necessary, if they are not running, but also checks the health of the device, by using the verification tools of SUT tools (discussed in Part 2). If it finds a problem with a device, it will also shutdown the buildbot slave, so that it does not get new jobs. In short, it keeps the state of the buildbot slave consistent with what it believes the availability of the device to be. If the device is faulty, it brings down the buildbot slave for that device. If it is a healthy device, passing the verification tests, it will start up the buildbot slave if it is not running.
Therefore if you need to disable a device, by marking it as disabled in slavealloc, watch_devices.sh running from a cron tab on the foopy, will bring down the buildbot slave of the device.
Where are the log files of watch_devices.sh?
They are on the foopy:
/builds/watcher.log (global)
/builds/<device>/watcher.log (per device)
If during a buildbot test we determine that a device is not behaving properly, how do we pull it out of use?
If a serious problem is found with a device during a buildbot job, the buildbot job will create an error.flg file under the device directory on the foopy. This signals to watch_devices.sh that when that job has completed, it should kill the buildbot slave, since the device is faulty. It should not respawn a buildbot slave while that error.flg file remains. Once per hour, it will delete the error.flg file, to force another verification test of the device.
But wait, I heard that mozpool verifies devices and keeps them alive?
Yes and no. Mozpool is a tool (written by Dustin) to take care of the life-cycle management of panda boards. It does not manage tegras. Remember: tegras cannot be automatically reimaged – you need fingers to press buttons on the devices, and physically connect a laptop to them. Pandas can. This is why mozpool only takes care of pandas.
Mozpool is the highest-level interface, where users request a device in a certain condition, and Mozpool finds a suitable device.
Lifeguard is the middle level. It manages the state of devices, and knows how to cajole and coddle them to achieve reliable behavior.
Black Mobile Magic is the lowest level. It deals with devices directly, including controlling their power and PXE booting them. Be careful using this level!
So the principles behind mozpool, is that all the logic you have around getting a panda board, making sure it is clean and ready to use, contains the right OS image you want to run it with, etc – can be handled outside of the buildbot jobs. You would just query mozpool, tell it you’d like a device, specify the operating system image you want, and it will get you one.
In the background it is monitoring the devices and checking they are ok, only handing you a “good” device, and cleaning up when you finish with it.
So watch_devices and mozpool are both routinely running verification tests against the pandas?
No. This used to be the case, but now the verification test of watch_devices.sh for pandas simply queries mozpool to get the status of the device. It no longer directly runs verification tests against the panda, to avoid that we have two systems doing the same. It trusts mozpool to tell it the correct state.
So if I dynamically get a device from mozpool when I ask for one, does that mean my buildbot slave might get different devices at different times, depending on which devices are currently available and working at the time of the request?
No. Since the name of the buildbot slave is the same as the name of the device, the buildbot slave is bound to the one device only. This means it cannot take advantage of the “give me a panda with this image, i don’t care which one” model.
Summary part 3
So we’ve learned:
there is a cron job running on the foopies, that looks for the device directories under /builds, and spawns/kills buildbot slaves as appropriate, so that the state of the buildbot slave matches the availability of the device
mozpool is a tool for automatically reimaging pandas
not all features of mozpool are available due to our buildbot setup (such as being able to get an arbitrary panda dynamically at runtime for a given buildbot slave)
So how does buildbot interact with a device, to perform testing?
By design, Buildbot masters require a Buildbot slave to perform any job. For example, if we have a Windows slave for creating Windows builds, we would expect to run a Buildbot slave on the Windows machine, and this would then be assigned tasks from the Buildbot master, which it would perform, and feed results back to the Buildbot master.
In the mobile device world, this is a problem:
Running a slave process on the device would consume precious limited resources
Buildbot does not run on phones, or mobile boards
Thus was born …. the foopy.
What the hell is a foopy?
A foopy is a machine, running Centos 6.2, that is devoted to the task of interfacing with pandas or tegras, and running buildbot slaves on their behalf.
My first mistake was thinking that a “foopy” is special piece of hardware. This is not the case. It is nothing more than a regular Centos 6.2 machine – just a regular server, that does not have any special physical connection to the mobile device boards – it is simply a machine that has been set aside for this purpose, that has network access to the devices, just like other machines in the same network.
For each device that a foopy is responsible for, it runs a dedicated buildbot slave. Typically each foopy serves between 10 and 15 devices. That means it will have around 10-15 buildbot slaves running on it, in parallel (assuming all devices are running ok).
When a Buildbot master assigns a job to a Buildbot slave running on the foopy, it will run the job inside its slave, but parts of the job will involve communicating with the device, pushing binaries onto it, running tests, and gathering results. As far as the Buildbot master is concerned, the slave is the foopy, and the foopy is doing all the work. It doesn’t need to know that the foopy is executing code on a tegra or panda. As far as the device is concerned, it is receiving tasks over the SUT Agent listener network interface, and performing those tasks.
So does the foopy always connect to the same devices?
Yes. Each foopy has a static list of devices for it to manage jobs for.
How do you see which devices a foopy manages?
If you ssh onto the foopy, you will see the devices it manages as subdirectories under /builds:
Manually. Each directory contains artefacts related to that panda or tegra, such as log files for verify checks, error flags if it is broken, disable flags if it has been disabled, etc. More about this later. Just know at this point that if you want that foopy to look after that device, you better create a directory for it.
So the directory existence on the foopy is useful to know which devices the foopy is responsible for, but how do you know which foopy manages an arbitrary device, without logging on to all foopies?
In the tools repository, the file buildfarm/mobile/devices.jsonalso defines the mapping between foopy and device. Here is a sample:
So what if the devices.json lists different foopy -> devices mappings than the foopy filesystems list? Isn’t there a danger this data gets out of sync?
Yes, there is nothing checking that these two data sources are equivalent. For example, if /builds/tegra-0123 was created on foopy39, but devices.json said tegra-0123 was assigned to foopy65, nothing would report this difference, and we would have non-deterministic behaviour.
Why is the foopy data not in slavealloc?
Currently the fields for the slaves are static across different slave types – so if we added a field for “foopy” for the foopies, it would also appear for all other slave types, which don’t have a foopy association.
What is that funny other data in the devices.json file?
The “pdu” and “pduid” are the coordinates required to determine the physical power supply of the tegra. These are the values that you call the PDU API with to enable/disable power for that particular tegra.
The “relayhost” and “relayid” are the equivalent values for the panda power supplies.
Where does this data come from?
This data is maintained in IT’s inventory database. We duplicate this information in this file.
So is a PDU and a relay board essentially the same thing, just one is for pandas, and the other for tegras?
Yes.
What about if we want to write comments in this file? json doesn’t support comments, right?
For example, you want to put a comment to explain why a tegra is not assigned to a PDU. For this, since json currently does not support comments, we add a _comment field, e.g.:
Is there any sync process between inventory and devices.json to guarantee integrity of the relayboard and PDU data?
No. We do not sync the data, so there is a risk our data can get out-of-sync. This could be solved by having an auto-sync to the devices.json file, or using inventory as the data source, rather than the devices.json file.
So how do we interface with the PDUs / relay boards to hard reboot devices?
Is there anything else useful in this “sut tools” folder?
Yes, lots. This provides scripts for doing all sorts, like deploying artefacts on tegras and pandas, rebooting, running smoke tests and verifying the devices, cleaning up devices, accessing device logs, etc.
Summary part 2
So we’ve learned:
Tegras and Pandas do not run buildbot slaves, we have dedicated machines to run buildbot slaves on their behalf, called foopies
Foopies are regular Centos 6.2 machines, with one buildbot slave running per device that they manage
Foopies manage typically 10-15 devices
The mappings of foopy -> devices is stored in the devices.json file in the tools project
This file is maintained by hand, but contains data that came from IT inventory database for PDU / relay boards
PDUs and relay boards are the devices that control the power supply to the tegras / pandas respectively
We can power cycle devices by using the reboot.py script in the sut_tools directory of the tools repository
There are other useful tools in “sut tools” folder for device tasks
We don’t build on tegras and pandas (we only test!)
Second key point:
Fennec is the only product we test on tegras and pandas (we don’t test B2G on real devices)
So why do we test Fennec on tegras, pandas and emulators?
To answer this, first remember the wide variety of builds and tests we perform:
Screenshot from tbpl
The answer is:
We use tegras to test: Android 2.2 (Froyo)
We use pandas to test: Android 4.0 (Ice Cream Sandwich)
We use emulators to test: Android 2.3 (Gingerbread) and Android 4.2 (Jelly Bean)
Notice:
We don’t test on 3.x (Honeycomb)
We don’t test on 4.4 (KitKat)
The versions we test on emulators are not sequencial (i.e. we test 2.3 and 4.2 on emulators – with 4.0 tested on pandas – in the middle of these two versions)
What are the main differences between our tegras and pandas?
For this reason, it was decided to create a generic interface, which would be implemented on all supported platforms. The SUT Agent was born.
Please note: nowadays, Fennec it only available for Android 2.2+. It is not available for iOS (iPhone, iPad, iPod Touch), Windows Phone, Windows RT, Bada, Symbian, Blackberry OS, webOS or other operating systems for mobile.
Therefore, the original reason for creating a standard interface to all devices (the SUT Agent) no longer exists. It would also be possible to use a different mechanism (telnet, ssh, adb, …) to communicate with the device. However, this is not what we do.
So what is the SUT Agent, and what can it do?
The SUT Agent is a listener running on the tegra or panda, that can receive calls over its network interface, to tell it to perform tasks. You can think of it as something like an ssh daemon, in the sense that you can connect to it from a different machine, and issue commands.
How do you connect to it?
You simply telnet to the tegra or foopy, on port 20700 or 20701.
Why two ports? Are the different?
Only marginally. The original idea was that users would connect on port 20701, and that automated systems would connect on port 20700. For this reason, if you connect on port 20700, you don’t get a prompt. If you connect on port 20701, you do. However, everything else is the same. You can issue commands to both listeners.
What commands does it support?
The most important command is “help”. It displays this output, showing all available commands:
pmoore@fred:~/git/tools/sut_tools master $ telnet panda-0149 20701
Trying 10.12.128.132...
Connected to panda-0149.p1.releng.scl1.mozilla.com.
Escape character is '^]'.
$>help
run [cmdline] - start program no wait
exec [env pairs] [cmdline] - start program no wait optionally pass env
key=value pairs (comma separated)
execcwd <dir> [env pairs] [cmdline] - start program from specified directory
execsu [env pairs] [cmdline] - start program as privileged user
execcwdsu <dir> [env pairs] [cmdline] - start program from specified directory as privileged user
execext [su] [cwd=<dir>] [t=<timeout>] [env pairs] [cmdline] - start program with extended options
kill [program name] - kill program no path
killall - kill all processes started
ps - list of running processes
info - list of device info
[os] - os version for device
[id] - unique identifier for device
[uptime] - uptime for device
[uptimemillis] - uptime for device in milliseconds
[sutuptimemillis] - uptime for SUT in milliseconds
[systime] - current system time
[screen] - width, height and bits per pixel for device
[memory] - physical, free, available, storage memory
for device
[processes] - list of running processes see 'ps'
alrt [on/off] - start or stop sysalert behavior
disk [arg] - prints disk space info
cp file1 file2 - copy file1 to file2
time file - timestamp for file
hash file - generate hash for file
cd directory - change cwd
cat file - cat file
cwd - display cwd
mv file1 file2 - move file1 to file2
push filename - push file to device
rm file - delete file
rmdr directory - delete directory even if not empty
mkdr directory - create directory
dirw directory - tests whether the directory is writable
isdir directory - test whether the directory exists
chmod directory|file - change permissions of directory and contents (or file) to 777
stat processid - stat process
dead processid - print whether the process is alive or hung
mems - dump memory stats
ls - print directory
tmpd - print temp directory
ping [hostname/ipaddr] - ping a network device
unzp zipfile destdir - unzip the zipfile into the destination dir
zip zipfile src - zip the source file/dir into zipfile
rebt - reboot device
inst /path/filename.apk - install the referenced apk file
uninst packagename - uninstall the referenced package and reboot
uninstall packagename - uninstall the referenced package without a reboot
updt pkgname pkgfile - unpdate the referenced package
clok - the current device time expressed as the number of millisecs since epoch
settime date time - sets the device date and time
(YYYY/MM/DD HH:MM:SS)
tzset timezone - sets the device timezone format is
GMTxhh:mm x = +/- or a recognized Olsen string
tzget - returns the current timezone set on the device
rebt - reboot device
adb ip|usb - set adb to use tcp/ip on port 5555 or usb
activity - print package name of top (foreground) activity
quit - disconnect SUTAgent
exit - close SUTAgent
ver - SUTAgent version
help - you're reading it
$>quit
quit
$>Connection closed by foreign host.
Typically we use the SUT Agent to query the device, push Fennec and tests onto it, run tests, perform file system commands, execute system calls, and retrieve results and data from the device.
What is the difference between quit and exit commands?
I’m glad you asked. “quit” will terminate the session. “exit” will shut down the sut agent. You really don’t want to do this. Be very careful.
Is the SUT Agent a daemon? If it dies, will it respawn?
No, it isn’t, but yes, it will!
The SUT Agent can die, and sometimes does. However, it has a daddy, who watches over it. The Watcher is a daemon, also running on the pandas and tegras, that monitors the SUT Agent. If the SUT Agent dies, the Watcher will spawn a new SUT Agent.
Probably it would be possible to have the SUT Agent as an auto-respawning daemon – I’m not sure why it isn’t this way.
Who created the Watcher?
Legend has it, that the Watcher was created by Bob Moss.
Where is the source code for the SUT Agent and the Watcher?
Does the Watcher and SUT Agent get automatically deployed when there are new changes?
No. If there are changes, they need to be manually built (no continuous integration) and manually deployed to all tegras, and a new image needs to be created for pandas in mozpool (will be explained later).
Fortunately, there are very rarely changes to either component.
Summary part 1
So we’ve learned:
Tegras and Pandas are used for testing Fennec for Android
They run different versions of the Android OS (2.2 vs 4.0)
We don’t build anything on them
Tegras are older/inferior/less reliable than pandas
We can’t reimage tegras programmatically, but pandas we can
There is a SUT Agent that runs on both the tegras and the pandas, and provides a mechanism to interact with it
There is a Watcher that keeps the SUT Agent alive
Whenever a new version of SUT Agent or Watcher is required, this needs to be manually built and rolled out to devices










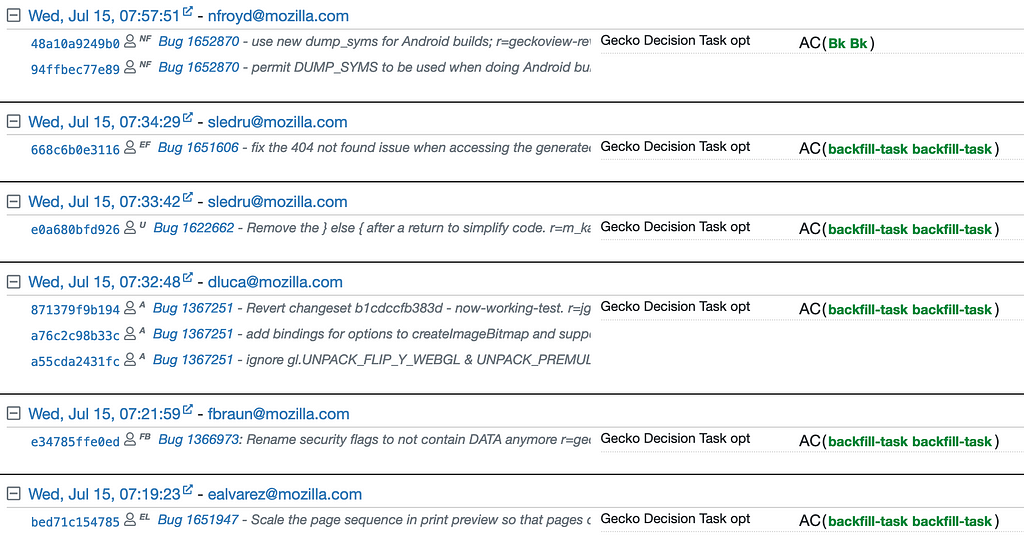

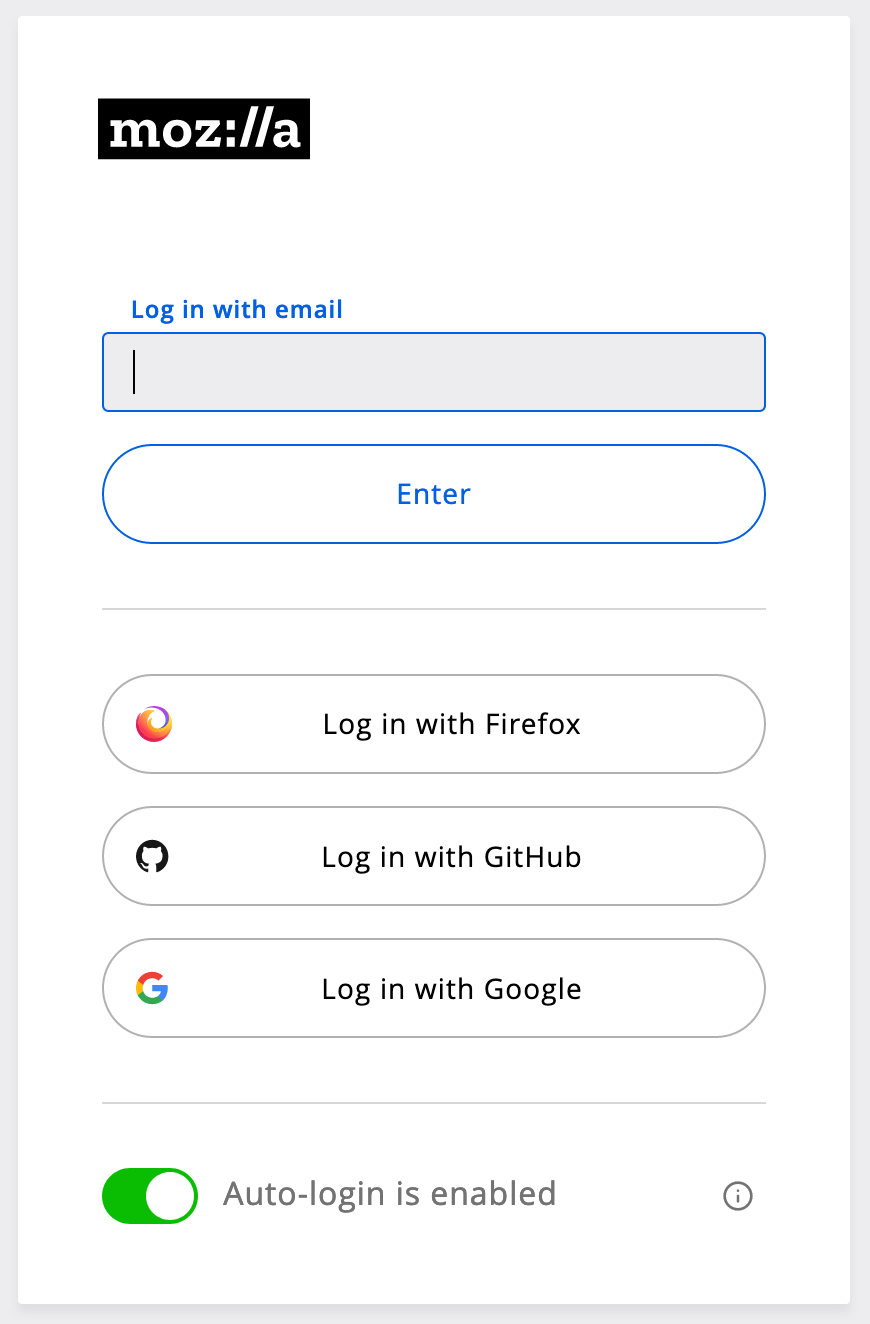
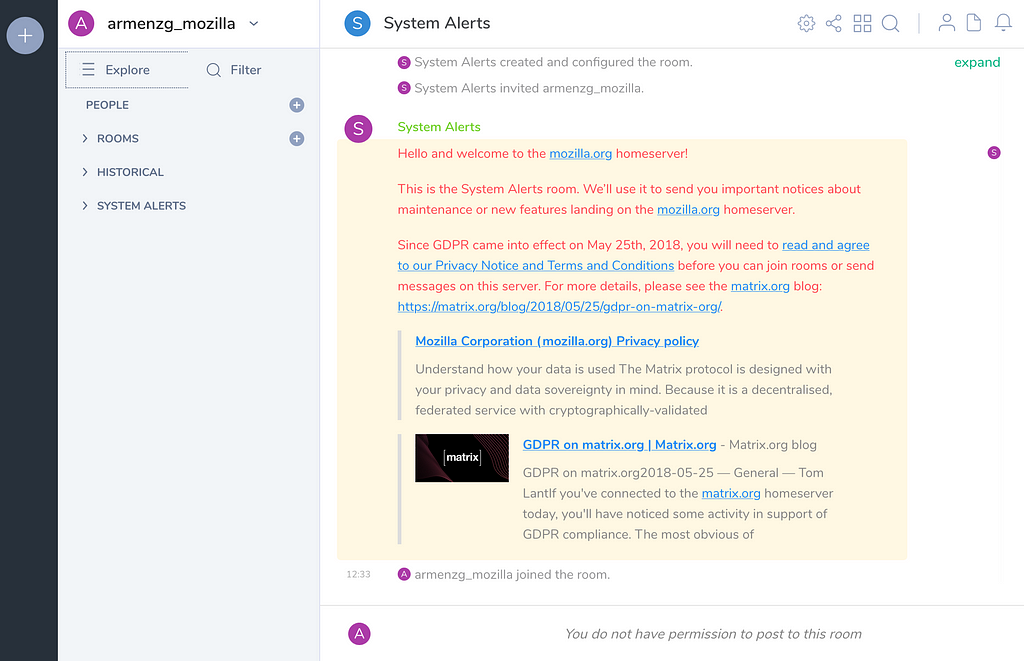
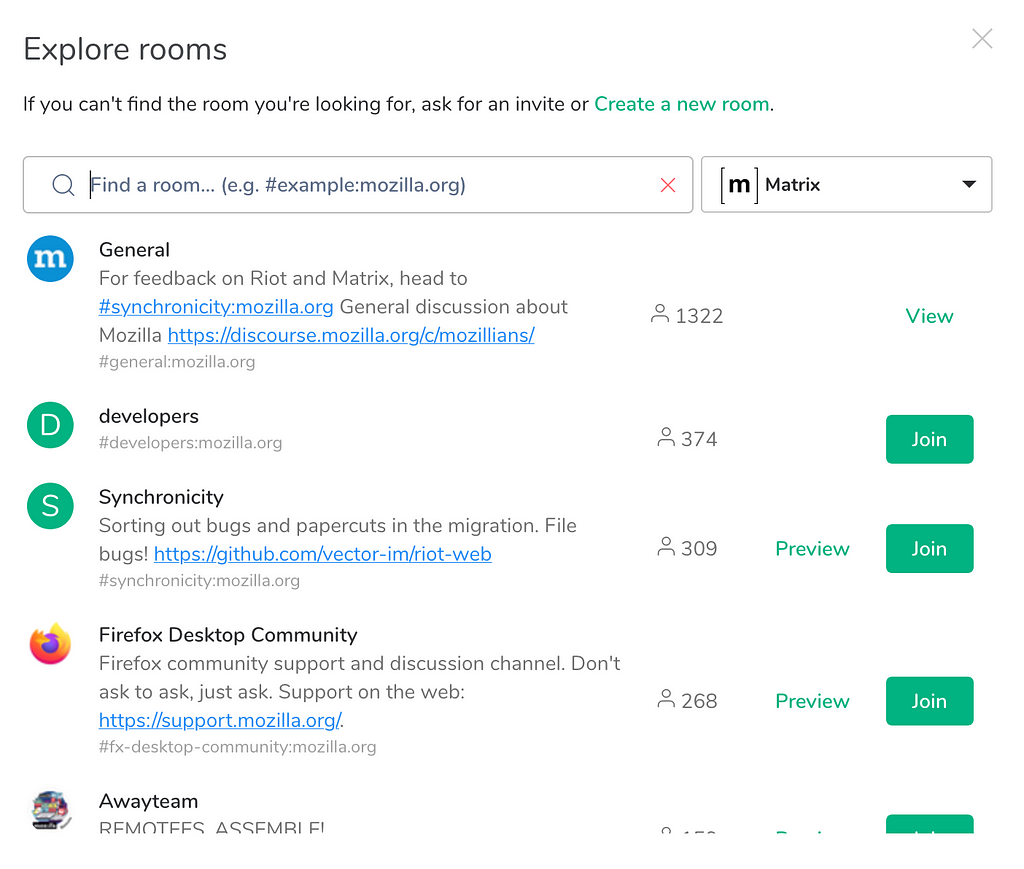
 Solution 1
Solution 1 Solution 2
Solution 2 Solution 3
Solution 3 Solution 3a: What’s inside the decision task
Solution 3a: What’s inside the decision task Solution 3b: Inside the decision task
Solution 3b: Inside the decision task Hacking taskgraph is usually dealing with that part of the data flow
Hacking taskgraph is usually dealing with that part of the data flow You may not need it, but that’s how optimization happens!
You may not need it, but that’s how optimization happens!









































































































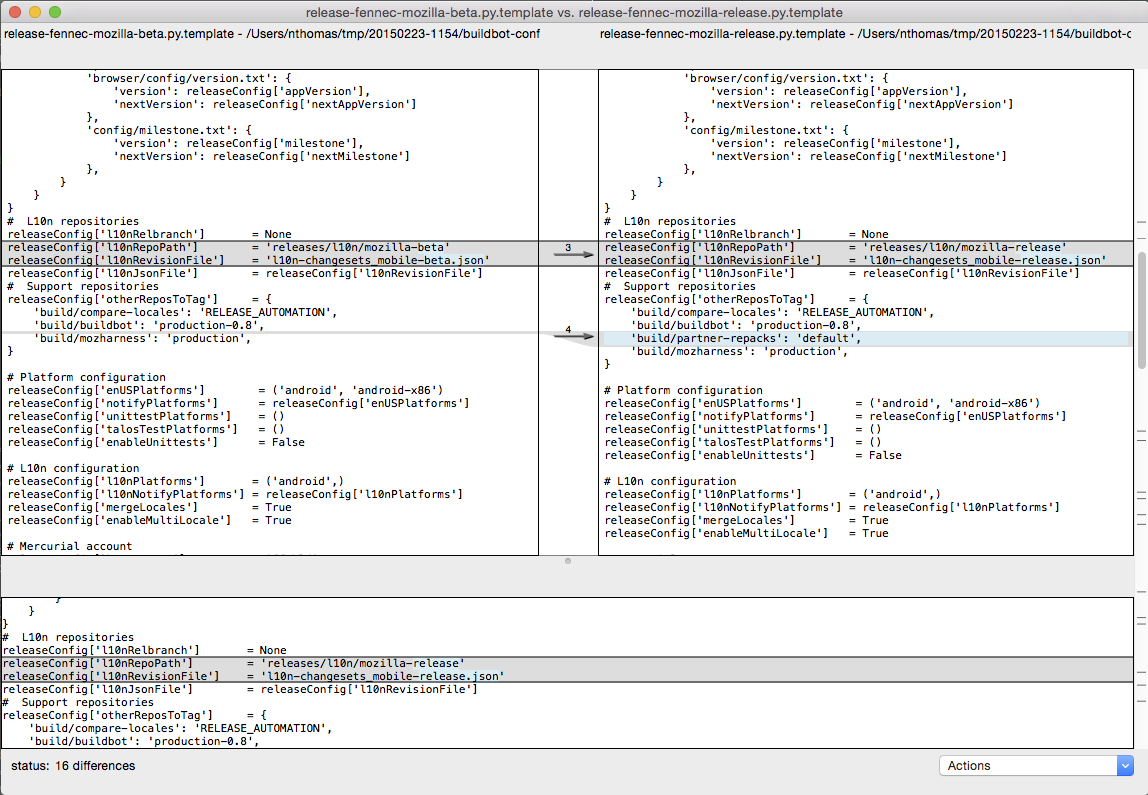








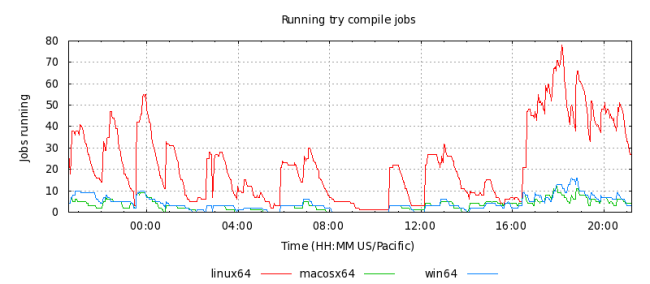 Until recently the mapping of job name to machine pool was out of date, due to our rapid growth for b2g and into Amazon’s AWS, so the graphs were more misleading than useful. This has now been corrected and I’m working on making sure it stays up to date automatically.
Until recently the mapping of job name to machine pool was out of date, due to our rapid growth for b2g and into Amazon’s AWS, so the graphs were more misleading than useful. This has now been corrected and I’m working on making sure it stays up to date automatically.




{kind=link}
{kind=link}