We are 5 days away from the release of Dawnmaker! It is a time of excitement, of stress of course, but also of regrets as we realize that there are so, so many things that we will not be able to add to our game. Let's introduce today's topic with a short video that is very à propos:
A game is never truly done. There's always the next thing you want to add, the little detail you want to change, the obvious problem you want to solve. But we cannot work on our game forever, because we simply need to sell it at some point and, hopefully, get some money to pay the bills and the foods. Such is the weight of reality on our dreams.
So we had to just make the cut somewhere, and decide on a release date. July 31 it is! Why? We wanted to release earlier, but there was a Steam Next Fest in early June, quickly followed by the Steam Summer Sale in early July, two events during which it is not advised to release a game. We've read that releasing on a Wednesday is a bit better for indies because there are usually less games coming out. So there we ended up! (That sounds easy but it took us a while to find a date that worked well for us… )
In just 5 days, Dawnmaker will be available for all to buy, to play, and to judge. That's a terribly exciting experience, but also a terribly scary one. Because we know that the game is not perfect. We know that it has weak points, that it is lacking in some places. But we have to release it anyway, we have to put it into your hands, and we have to accept that, yes, this is the game we're going to sell.
Believe me: it is truly heartbreaking to see all those things that could have been, all the ways this game could have been better, if only we had had more time, more money, more people… We are going to release a product that is not exactly what we had in mind, but a product that is what we have been able to create in the time we allowed ourselves.
In an attempt to amuse you, and maybe to grieve these features that will never be, let's go through some of the main elements that we wanted to add to Dawnmaker but couldn't.
Scientific research
The science part of the game has always, in our plans, been so much deeper than it currently is. In the game, science can be spent in some buildings to generate Eclairium. That's fairly basic. We had much bigger ambitions for that aspect of the game: we wanted science to be spent to research new technologies. Some scientific buildings were meant to have a scientific line, each step giving a one-off or a permanent bonus. For example, a research would have improved the production of your fields, another would have made harvesting better. Some would have replaced cards in your hand with a better version.
The reason why this never happened was that it required a lot of programming. We needed to change the way the core of the game worked, to add a big layer of complexity allowing to handle these types of effects. It also required some heavy UI work, which was partly done by Agathe when she worked with us, but that we never integrated. Sorry Agathe, it is very unlikely that this work of yours will ever be in the game.
Drafting cards
Deckbuilding is the poor child of Dawnmaker. When you mix two genres like we did, you usually end up favoring one over the other. We definitely did that with the city building part, at the expense of the deckbuilding part. But I have a hunch that we could have made the cards a lot more interesting for a cost that was not too high. Here's what I had in mind, but never had the time to try.
Some buildings in the game give you a card when you build them. That card is always the same, you know what it will be before choosing to buy the building. I wanted to change that, at least on some of the buildings, to instead make them offer you a choice between 3 different cards of the same type and level. So instead of an Exploration post always giving you an Exploration card, it would let you choose a new card from three random level 1, industry cards. Sometime you would get to pick an Exploration, sometimes you'd get an Optimization, and sometimes, rarely, you would find a card that you had never seen before.
From an economical point of view, this would also have allowed us to produce a lot more content for very little cost: since our cards do not have illustrations, adding a new card to the game would just be a matter of designing it. As the game currently stands, adding a new card means adding a new building, which means creating a new graphical asset for it, which is expensive! I sincerely wished I had thought about this much earlier in the development of Dawnmaker, but I did not, and here we are not having this in the game.
Starting characters
Much like in Slay the Spire, we wanted to have a little cast of characters that you could choose from when starting a new game. They would not have been as distinct as in Slay the Spire, but would allow player to start each game with a different deck and roster of buildings. We had plans for 3 different characters, each opening a different way of playing the game.
Nomad buildings
You might have played with the buildings that give you resources when you build something adjacent to them, and thought that they were weak? Well, that's because we made them planning for another kind of buildings: nomads. We wanted to have buildings that could be moved from one tile to another, triggering the adjacent build effects each time. We think it would have added a more puzzle-y element to the game.
Smog effects
When we added the cards to represent the Smog's behavior, we knew we had an opportunity for more than just Luminoil consumption. Basically, anything that a building could do, we could make the Smog do. We wanted to have the Smog give you Curse cards, half your Luminoil stock, destroy or deactivate some buildings, and so on.
I'm going to stop here because there is a lot more small things that I wished we could have added to Dawnmaker. But the game is what it is, and we're still very proud of all the work we've done over the last 2.5 years!
This piece was initially sent out to the readers of our newsletter. Wanna join in on the fun? Head out to Dawnmaker's presentation page and fill the form. You'll receive regular stories about how we're making this game and the latest news of its development!
If you contribute to the Knowledge Base in SUMO, please read this blog post carefully as we explain how others can request content from the SUMO team.
Historically, we didn’t have a structured workflow for content requests, relying on personal engagement or public groups to act reactively. With a larger content team, establishing a proper workflow is essential for task distribution and transparency within the team.
In general, the content intake workflow can be summarized in 4 steps:
Step 1: Submitting a content request
The process begins with submitting a content request through a Bugzilla form. Typically, feature/product owners make these requests, but anyone with ideas for improving support content can submit, including contributors. Documenting requirements helps us act appropriately.
This is a crucial step, and we require each field in the form to be filled out. Each piece of information helps us determine the necessary steps moving forward. All internal teams must use the Bugzilla form for SUMO content requests, whether for new articles or updates. Exceptions are for minor fixes, which can be submitted directly in the KB article. To learn more about what we consider as minor fixes, please see this.
Step 2: Determining content access restrictions
After submission, the workflow diverges based on the content access restriction chosen:
Non-confidential: All bugs and drafts within these requests are visible to anyone with a link and can receive comments and suggestions, benefiting from community contributions.
Confidential: These bugs are restricted and will be handled internally by staff members, due to sensitive information, such as upcoming features yet to be publicly announced, or information related to partnerships or other business strategies.
Step 3: Content creation
Once the necessary information is provided, the content team assigns the bug to a responsible person. This usually involves creating a draft in Google Docs before publishing it as a revision. The content team also creates in-product links if needed. Areas of responsibility for SUMO technical writers are:
Once the content draft is ready and approved by all parties, the person responsible for it can submit it as a new revision.
How contributors can help
Contributors remain essential to the article creation process. With this update, we’re aiming to make sure that the contribution workflow is integrated and aligned with our internal workflow.
For non-confidential content requests, contributors are encouraged to get involved. And here’s how you can help:
Identify a content request: Keep an eye on new content request bugs. When you find one you’re interested in, please directly comment on the bug to notify the content team that you want to help out with the request. If you’d like to get notifications on new content requests, consider watching the Knowledge Base Content component on Bugzilla. To do this, go to your Bugzilla profile → Edit Profile & Preferences → Component Watching. Choose support.mozilla.org on the product selection and select Knowledge Base Content for the Component field. And don’t forget to click on the Add button to save your changes.
Get assigned: Wait for the content team to assign the ticket before starting. Please do not work on the actual content creation before the content team assigns the ticket to you.
Content creation:
Review the ticket: Make sure to review the ticket thoroughly and understand the request. Also, ensure you can complete the work by the due date for publication. If anything changes, and you can’t finish the content on time, let the content team know as soon as possible.
Create a draft: Use Google Docs to start working on the draft. If it’s not possible, you can also share the content file as an attachment in Bugzilla for others to review.
Get Feedback:
Share the draft: Post the link to your draft in the Bugzilla ticket for review.
Open for comments: Ensure that the Google Docs settings allow for comments.
Work with the requester: Collaborate closely with the requester to cover all points in the article. If any information you need to complete the work is missing, don’t hesitate to reach out to the requester directly for additional details.
Final review: Once the draft is finalized and approved by all parties, including the requester, you can submit the content as a new revision on the actual Knowledge Base article. Once the KB revision is submitted, please also assign the ticket back to the technical writer responsible for the product.
Publication: The technical writer will review and publish the content.
Some days there’s something extra interesting to watch online — a sports event, election coverage, a certain show is leaving Netflix so you gotta binge — but you’ve got work to do. The Picture-in-Picture feature in Firefox makes multitasking with video content smooth and easy, no window shuffling necessary.
Picture-in-Picture allows a video to be played in a separate, small window, and still be viewable when you switch tabs or away from the Firefox browser.
To use it on videos longer than 45 seconds, hover your mouse over to see a small Picture-in-Picture button. Click the button to pop open a floating window so you can keep watching while working in other tabs.
You can also right-click on a video and select “Watch in Picture-in-Picture.” (This will work on shorter videos like the one below.)
Move the video around your screen and drag the corner to shrink or enlarge it. If you need to mute it, just tap the speaker icon on the right.
Check it out. Just don’t blame us if you end up with a gold for procrastination instead of getting that monthly report done.
Welcome back to our Meet The Team series! I recently had a very entertaining conversation with Sol Valverde, one of the creative minds behind Thunderbird’s user experience and interface design. During our chat, Sol explained how growing up around developers influenced her career path, and discusses the thought process behind designing and improving Thunderbird’s visuals.
Sol also shared a hilarious and heartwarming anecdote about her family’s reaction to her joining our team. It’s a story that underscores the importance of maintaining core Thunderbird features that long-time users rely on, while still modernizing the interface.
For the best and most complete experience, listen to our entire conversation above. Or, you can read select excerpts below.
Q: Can you start by sharing your origin story? How did you end up in UI/UX design?
A: As a kid I always used to draw a lot. I did want to become uh some sort of artistic area professional. However, I do come from a family of programmers. My dad and uncle are both developers. My uncle, he’s been a huge Thunderbird fan for 20 years. But when he found out I got the job he was terrified. He was like “oh my God that’s cool! And also please don’t change anything. It’s perfect the way it is. Don’t touch it!”
Q: What does your role entail?
A: I tend to take the first pass at evaluating how a user is going to interact with something. Like for example the first user experience. When I look at the screen, of course I want to make sure it’s attractive. But I ask things like “will the user understand what they need to do in this screen? Is it intuitive?”
A good experience is potentially one that you will forget. Because if you remember, it probably means that you struggled.
Sol Valverde
Q: How do you ensure that a design is intuitive for users?
A: I love the example of a door. If you have a door without a handle, you can assume it should be pushed. But how do you interact with a door if you don’t know? A lot of doors have “Push” or “Pull” signs. But then you kind of also get the extra interaction with the handle. Sometimes it’s a handle you can grab, but sometimes it’s just a bar that has to be pushed. The design lets you know intuitively what should be done, without needing to read anything. We want to guide the user without hiding anything from the user.
I grew up and learned by grabbing things, breaking things, interacting with them. And that kind of learning for me is crucial. So if the user is going to come into this room and and learn what I want them to learn, I have to make it easy for them to figure it out. I do a lot of research. If I’m working on K-9 Mail, for example, I not only look at other email apps, but also at various social media apps. How easy it to switch accounts? What do I dislike about those applications?
Q: Are there any mobile apps that stand out? Where the user experience is so straightforward there wasn’t any kind of learning curve?
A: The simpler ones tend to be the most intuitive ones. So for example, when you’re using an app to read comics or manga, you tap the book you want, and then you swipe back and forth to turn the pages. Like mimicking the physical actions of reading.
<figcaption class="wp-element-caption">Sol played a big role in improving Thunderbird’s Cards View. </figcaption>
Q: What has been one of the most rewarding projects you’ve worked on at Thunderbird so far?
A: Definitely the Cards View revamp. We redid the first big chunk of code code, but then realized we hadn’t accounted for high contrast and other accessibility needs. We had to address those because accessibility is a must. So, when Micah and I started reworking the design, we thought, “What if we make it ten times better than we originally planned?” Thankfully, Alex was crazy enough to let us do it.
Q: How important is community feedback in your design process?
A: It’s invaluable! The community has a lot of opinions which is great. We design and extrapolate based on our own experiences and those of people we know. We do our best to put ourselves in others’ shoes and predict how they’ll interact with the design. Some comments were straightforward, like “I wish for this or that because it serves me better” or “I just like how it looks.” For UI, as long as it looks cohesive, I’m happy. However, some users provided deeper insights and explained their use personal use cases and concerns. That kind of feedback is so eye-opening, because it addresses things we hadn’t considered. I’m really grateful that they bring those perspectives forward.
Q: OK, big picture question: What’s your overall vision for the user experience in Thunderbird?
A: My whole desire for Thunderbird is it’s something easy to use. It’s something friendly and inviting. However, it can be as complicated or as easy as you want it to be. Intuitive at first glance, but powerful when you need it to be!
The Rust team is happy to announce a new version of Rust, 1.80.0. Rust is a programming language empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, you can get 1.80.0 with:
If you'd like to help us out by testing future releases, you might consider updating locally to use the beta channel (rustup default beta) or the nightly channel (rustup default nightly). Please report any bugs you might come across!
What's in 1.80.0 stable
LazyCell and LazyLock
These "lazy" types delay the initialization of their data until first access. They are similar to the OnceCell and OnceLock types stabilized in 1.70, but with the initialization function included in the cell. This completes the stabilization of functionality adopted into the standard library from the popular lazy_static and once_cell crates.
LazyLock is the thread-safe option, making it suitable for places like static values. For example, both the spawn thread and the main scope will see the exact same duration below, since LAZY_TIME will be initialized once, by whichever ends up accessing the static first. Neither use has to know how to initialize it, unlike they would with OnceLock::get_or_init().
use std::sync::LazyLock;
use std::time::Instant;
static LAZY_TIME: LazyLock<Instant> = LazyLock::new(Instant::now);
fn main() {
let start = Instant::now();
std::thread::scope(|s| {
s.spawn(|| {
println!("Thread lazy time is {:?}", LAZY_TIME.duration_since(start));
});
println!("Main lazy time is {:?}", LAZY_TIME.duration_since(start));
});
}
LazyCell does the same thing without thread synchronization, so it doesn't implement Sync, which is needed for static, but it can still be used in thread_local! statics (with distinct initialization per thread). Either type can also be used in other data structures as well, depending on thread-safety needs, so lazy initialization is available everywhere!
Checked cfg names and values
In 1.79, rustc stabilized a --check-cfg flag, and now Cargo 1.80 is enabling those checks for all cfg names and values that it knows (in addition to the well known names and values from rustc). This includes feature names from Cargo.toml as well as new cargo::rustc-check-cfg output from build scripts.
Unexpected cfgs are reported by the warn-by-default unexpected_cfgs lint, which is meant to catch typos or other misconfiguration. For example, in a project with an optional rayon dependency, this code is configured for the wrong feature value:
warning: unexpected `cfg` condition value: `crayon`
--> src/main.rs:4:11
|
4 | #[cfg(feature = "crayon")]
| ^^^^^^^^^^--------
| |
| help: there is a expected value with a similar name: `"rayon"`
|
= note: expected values for `feature` are: `rayon`
= help: consider adding `crayon` as a feature in `Cargo.toml`
= note: see <https://doc.rust-lang.org/nightly/rustc/check-cfg/cargo-specifics.html> for more information about checking conditional configuration
= note: `#[warn(unexpected_cfgs)]` on by default
The same warning is reported regardless of whether the actual rayon feature is enabled or not.
The [lints] table in the Cargo.toml manifest can also be used to extend the list of known names and values for custom cfg. rustc automatically provides the syntax to use in the warning.
You can read more about this feature in a previous blog post announcing the availability of the feature on nightly.
Exclusive ranges in patterns
Rust ranged patterns can now use exclusive endpoints, written a..b or ..b similar to the Range and RangeTo expression types. For example, the following patterns can now use the same constants for the end of one pattern and the start of the next:
Previously, only inclusive (a..=b or ..=b) or open (a..) ranges were allowed in patterns, so code like this would require separate constants for inclusive endpoints like K - 1.
Exclusive ranges have been implemented as an unstable feature for a long time, but the blocking concern was that they might add confusion and increase the chance of off-by-one errors in patterns. To that end, exhaustiveness checking has been enhanced to better detect gaps in pattern matching, and new lints non_contiguous_range_endpoints and overlapping_range_endpoints will help detect cases where you might want to switch exclusive patterns to inclusive, or vice versa.
Following the news of our 25 honorees for The 2nd Annual Rise25 Awards, Mozilla is thrilled to announce that actress and presenter Siobhán McSweeney will be hosting this year’s ceremony which will celebrate these individuals for leading the next wave of AI. The Irish actress, best known for her BAFTA award-winning performance as Sister Michael in Channel 4’s (Netflix in the U.S.) series “Derry Girls” and most recently in Hulu’s “Extraordinary,” will take the helm during this year’s ceremony which will take place the evening of Tuesday, August 13 at the Convention Centre in Dublin, Ireland.
“I’m so excited to host these awards. AI is one of the biggest issues facing us, not only in my industry but across the board. To recognise and award individuals who are working for the benefit of society and not corporations is a great honor,” said McSweeney. She continued: “I’m so looking forward to meeting them. And having them explain what AI is.”
Rise25 is more than an award ceremony—it’s a platform to spark discussion, forge connections and inspire a wave of new ideas that will shape the future of AI. Siobhán’s contributions to television and theater, characterized by depth and charisma, make her an ideal voice to help us highlight these themes.
“The Rise25 awards are committed to bridging the gap between complex technological innovations and the very human stories at their core,” said Mark Surman, President of Mozilla. “Ms. McSweeney’s portrayal of Sister Michael in ’Derry Girls’ has left a lasting impression on audiences around the world (we’re big fans!). Her ability to deliver lines with sharp wit, while maintaining a warm presence, perfectly encapsulates the blend of insight and approachability we covet at our event.”
The awards show will also feature a special performance by Galway, Ireland-based Irish dancers The Gardiner Brothers. The American-born Irish dancers have won over 40 major Irish dancing titles between them and have performed to audiences all over the globe, including with the world famous Riverdance cast. They are known for their fast paced and rhythmic style of dance that they developed after training at the Hession School of Irish Dance in Galway, Ireland.
Bridget Todd, host of Mozilla’s Webby Award-winning “IRL” podcast, will be on hand to present the award categories at this year’s ceremony. Bridget is also the host of the iHeart Radio Podcast Award-winning podcast “There Are No Girls On The Internet,” and is a Shorty Award winner for “Best Podcast Miniseries” for DISINFORMED, a miniseries exploring how misinformation, and conspiracy theories around COVID, gender, and race hurt marginalized communities. Bridget’s writing and work on technology, race, gender and culture have been featured at The Atlantic, Newsweek, “The Daily Show” and more.
Mozilla’s 2nd Annual Rise25 Awards build upon the success of last year’s Rise25 Awards which were held in Berlin, Germany, bringing to life what a future trustworthy Internet could look like.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at @ThisWeekInRust on X(formerly Twitter) or @ThisWeekinRust on mastodon.social, or send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization. The following
RFCs would benefit from user testing before moving forward:
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing
label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature
need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on X (Formerly twitter) or Mastodon!
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on X (Formerly twitter) or Mastodon!
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
The problem to watch out for is that state privacy regulators tend to be diligent high achiever types who aren’t afraid of doing a bunch of extra work. But what we want here is for most of the work of the licensing system to be done on the surveillance company side. The people who are getting paid by the taxpayers should spend as little time on it as possible. So here’s a possible way to do it.
Pass a state law with a very general definition of surveillance, and say that anybody who surveils more than 20% of the population (to start with) needs to get a license. Appoint a surveillance licensing board.
Design a surveillance licensing application, a one-page PDF. Name of company, contact person, and so on. Last form field is describe your surveillance practices in detail (attach additional pages if needed)
When a company applies, put their application including the additional pages on the web, and have a public meeting.
The meeting will be full of concerned citizens, NGOs, businesses that use the surveillance in some way, and other random members of the public. (Yes, people who got kicked off of Facebook because of getting hacked will show up at the Facebook meeting to complain.)
Realistically some speakers at the meeting will come up with something that the surveillance company left out of their application, and some will mention harmful effects of surveillance practices. The board gives the company a temporary surveillance license and tells them to re-submit. While on a temporary license they can’t sign up any new users from this state.
Go to step 3. When the company cleans up their act, then the board can give them a longer term license. If they persist the board might deny them a license and that’s when a lawsuit could kick in. But most of the steps of the process have already worked.
No speech mentioned, it’s all about non-speech conduct, so very difficult for surveillance industry sockpuppet orgs to get a court to block.
Over on the social media sites there have been a bunch of very serious posts from very serious people explaining how surveillance advertising is here to stay and the best we can do is put some privacy-enhancing technologies on it. This sounds dismal and awful—ads according to the faufreluches so the big shots get ads for sweet cars and good jobs, retirees get precious metals scams, those with money get legit investments, those without get predatory finance, you know, all the same tricks and discrimination but with more math to make it harder to understand. So instead I’m going to do some Internet optimism today. What happens if instead of reimplementing surveillance advertising, we just get rid of it?
Step one: people start buying better stuff. If you figure out how to turn the surveillance advertising off, you start buying goods and services that you are more satisfied with (Lin et. al) and buying less overpriced crap (Mustri et al). The main reason I’m pretty confident about this effect is because of some research that hasn’t been published. If people who use ad blockers and privacy tools were making worse purchases, then someone in the surveillance business would have published research saying so.
Step two: marketers look for alternatives. If I can somehow avoid being exposed to the surveillance ads, that doesn’t mean that people still aren’t going to try to sell me stuff. But instead of surveillance ads, which let them target the most valuable possible audience for the lowest possible ad rates they have to fall back to the next best options, which might be
spending more money on better ad-supported content
reviewer and influencer programs
content marketing
increase product quality
lower price
All of those options have less attractive profits or predictability than the surveillance ads, but by removing the surveillance ad option, as a shopper you get more money to flow to more win-win options.
Step three: what happened to the ad-supported content? A lot of ad-supported content does get money from surveillance ads. It could turn out that the legit ad-supported sites end up better off, just by supply and demand. The number of available crap ad spots—that are only saleable because of surveillance—will go down. And after surveillance advertising the customers will be sitting on more money, and can put some of it into subscriptions and crowdfunding. And a bigger percentage of the subscription or crowdfunding money gets to the content creator.
Of course, the market isn’t going to change because one person is harder to reach with surveillance ads. Ad reform is a collective problem, and needs tool building, education, and lobbying work.
We might be able to get some good data about this soon, thanks to the EDPB decision on Facebook ad tracking. It looks like some users are going to be able to use the exact same social site with random ads instead of personalized ones. When the users who picked Facebook’s non-personalized option turn out to own better stuff that they’re more satisfied with, that will help build toward a surveillance advertising ban. It’s a lot easier to justify a ban when it’s not about balancing harms and benefits, but more about stacking consumer benefits on top of the existing privacy and national security benefits.
Academic Publishing is a Lucrative ScamI think the reason more academics haven’t already migrated to Diamond Open Access journals is that there are relatively few such journals. The reason for that is that although there are lots of people talking about Diamond Open Access there are many fewer actually taking steps to implement it. The initiative mentioned in the Guardian article is therefore very welcome. Although I think in the long run this transition is inevitable, it won’t happen by itself. (Links to Academic journals are a lucrative scam – and we’re determined to change that)
I am a tab maximalist. On any given day, you can find me with 50+ tabs open across multiple windows on Firefox. Having this many tabs open can seem chaotic, but rest assured there is a method to the madness.
As a global product marketing manager at Mozilla, a large part of my job is to think critically about various inputs, synthesize and pass information from one team to another. Unsurprisingly, one of my guilty pleasures is being the first to provide a resource when in group conversation (e.g. a link to an insight or framework). These are not just any links. These are links to tabs that have been open for weeks… months … that I can recite like the alphabet.
Now, I may not keep 7,000 tabs open, but I do know five features that can help you manage yours… however many your heart desires.
1. Pinned Tabs
Pinned Tabs are my go-to for keeping essential tabs easily accessible. By pinning tabs, they stay in a fixed position on the left side of the tab bar, saving space and preventing accidental closure. I pin my active work and resources like documents in development, recent insights or my favorite playlist. Unlike bookmarks, which are great for long-term link storage, I use pinned tabs for resources I need to access frequently throughout the day but don’t need to hold onto for longer than a month or two. They also offer reduced page load times since they are technically still open in the tab bar and less likely to be unloaded when your memory is low.
To try it out, just right click on the tab you want to pin, and choose “Pin Tab” from the menu.
2. Search tabs
Having several pinned tabs can also become overwhelming. That’s when the search tabs feature becomes a lifesaver. When I need to find a specific tab among the dozens I have open, I can search for any open tab by typing a keyword into the address bar. This feature saves me from endlessly navigating tabs and quickly locating the exact information I need, ensuring I stay efficient and productive.
Click the “List all tabs” button in the tab bar, then choose “Search Tabs” from the menu.
3. Pocket integration
If you are a tab maximalist, you probably need a place to get away from the noise. Pocket is a great escape, like your own personal library. Luckily, Pocket is integrated directly into Firefox, allowing me to save articles, videos, and web pages for later. When I need to take a beat from work, this is the perfect place to catch up on my favorite topics – which currently includes House of Dragons fan theory and recaps. This doesn’t fit easily into my workday though, so it is great to revisit later when I have the time to dive into the rabbit hole.
Hit the “Save to Pocket” button in the toolbar.
4. Close duplicate tabs
Close duplicate tabs is exactly as it sounds, a handy feature that can detect and close duplicate tabs with a simple right click. As of Firefox 127, this feature is directly integrated into the browser for greater ease of use. With this feature, I avoid the clutter and confusion of having multiple tabs open for the same webpage. It’s a small but powerful tool that keeps my browser organized and streamlined. It is no wonder why this was a top requested feature from our community. For those moments when my tab habits become unwieldy, this feature is a real lifesaver.
To try it out, just right click on the tab you want to pin, and choose “Close Duplicate Tabs.”
5. Multi-Account Containers
If you have interests you want to keep private, Multi-Account Containers are for you. They allow you to separate different browsing activities into different containers, enhancing privacy and organization. Click here for a quick tutorial on using Multi-Account Containers.
For a tab maximalist, this is a game-changer. With Multi-Account Containers, you can keep your tabs organized by context, making it easier to find what you need without the clutter of unrelated tabs.
With these features, I hope you explore your greatest curiosities and become the most efficient version of yourself. Never lose a link again. Be a maximalist with Firefox.
There are endless ways to make Firefox your own, whether you’re a tab maximalist, a minimalist or however you choose to navigate the internet. We want to know how you customize Firefox. Let us know and tag us on X or Instagram at @Firefox.
Alexandre massively improved performance through the whole browser toolbox (-50% on Webconsole reload, -20% on heavy console logging, -15% on Debugger step-in) by throttling some events (Bug 1824726)
The DevTools team is happy to announce that 100% of tests pass on https://puppeteer.github.io/ispuppeteerwebdriverbidiready/. This is the result of a long effort and collaboration with our peers from the Puppeteer team, and thanks to this we hope to see more Puppeteer users running tests in Firefox.
Dale is working on a dedicated search button on the address bar, allowing you to change search engines or browse tabs easily. ( Bug 1903146, Bug 1903145)
To test it out, set the pref browser.urlbar.scotchBonnet.enableOverride to true
As part of follow ups to the Manifest V3 improvements:
Investigated and fixed issues related to the event page lifetime and event page ability to be respawned by persisted event listeners, and improve Manifest V3 background script reliability (Bug 1905505, Bug 1905153, Bug 1830144)
Fixed a bug related to the extension button’s “attention dot”, which was making it always shown for Manifest V3 extensions with an activeTab permission (Bug 1851083
Fixed theme API internal issue that could make the add-on database to grow unnecessarily (Bug 1830136)
Fixed zooming on the extension devtools panels (Bug 1583716)
Thanks to Gregory Pappas for contributing this fix!
Fixed extension sidebar bug leading extension sidebar to always be open automatically on add-on updates and reloads (Bug 1892667)
WebExtension APIs
Fixed a downloads API regression that was preventing files containing % character from being saved successfully (Bug 1898498)
From Firefox 129, declarativeNetRequest API rules will be able to intercept and modify web requests originate from web pages loaded from a file: URI (Bug 1887869)
Addon Manager & about:addons
Checkbox that allows users to grant access to private browsing windows as part of the install flow has been moved to the first install dialog in Firefox 129 (Bug 1842832).
Valentin Gosu fixed a NetworkError that could happen for fetch calls when Responsive Design Mode was enabled (#1885308)
Brad Werth fixed a Browser crash that was occurring when displaying the highlighter for flexbox items (#1901233)
Arai fixed Debugger pretty-printing when there was escape sequence inside template literals (#1905653)
Alexandre is still working on improving the JS tracer. The max depth can now be set through a pref (#1903791), and when recording to the profiler, the stack chart panel is selected instead of the call tree (#1903792)
Julian made network blocking from DevTools actually block the request, not only the response (#1756770)
Nicolas fixed an issue in the Rules view that could break the style of the page when writing property values with quotes (#1904752)
Alexandre fixed a nasty bug that could prevent DevTools to open (#1903980)
Nicolas made some interactive elements in the Inspector keyboard focusable:
Nicolas added information for registered properties (aka @property) in the Computed panel:
Show initial value of registered properties (#1900069)
Show invalid at computed-value time declarations (#1900070)
Hubert is almost done migrating the Debugger to CodeMirror 6. All major features are now supported and we’re only looking at smaller bugs and test failures before enabling it on Nightly (#1904488)
WebDriver BiDi
External:
Thanks to James Hendry for removing the deprecated “desiredCapabilities” and “requiredCapabilities” from geckodriver (#1823907)
Thanks to :haik and to everyone involved on Bug 1893921 for solving a sandboxing issue with the latest macos arm workers provided for Github actions. This was preventing several projects using Github actions to run their CI on Firefox.
Updates:
Sasha and Henrik implemented the network.setCacheBehavior command, which allows to disable the network cache either globally or for a set of top-level browsing contexts. This is particularly useful to ensure consistent network behavior during repeated tests (#1901032 and #1906100)
Sasha added support for the “originalOpener” field in BrowsingContextInfo, which allows clients to find the opener of a given browsing context, even if it was opened using “rel=noopener”. (#1898004)
Julian added support for all arguments to the “network.provideResponse” command, for requests blocked in the “beforeRequestSent” phase. Clients can now build a custom response to any request by providing its body, headers, cookies, status code and status phrase. This way users can easily mock backend responses without having to change their server. (#1853882)
Sasha added support for network events using data URLs. At the moment we only emit events for data URLs requests used to load a document, but we will follow up to add support for all requests to data URLs. (#1805176)
Henrik implemented the handler field of the browsingContext.userPromptOpened event which will indicate the configured prompt handler for the opened prompt (eg “accept”, “dismiss” etc…). (#1904822)
Henrik added support for “beforeunload” prompts, which can now be handled as any other prompt in WebDriver BiDi sessions (they are still automatically dismissed in WebDriver classic sessions). (#1824220)
Henrik added support for the “promptUnload” argument to the browsingContext.close command, which allows to skip beforeunload prompts. (#1862380)
Henrik updated the default value of the “remote.active-protocols” preference to “1”, which means that from now on, CDP (Chrome DevTools Protocol) is no longer enabled by default. If clients still want to enable it, they can either set this preference to “2” (CDP only) or “3” (WebDriver BiDi + CDP). This is a temporary step before CDP is fully disabled and removed from Firefox around the end of the year. (#1882089)
Bug fixes (read-only):
Julian fixed a bug with network.continueRequest where you could not provide multiple values for a single header name (#1904379)
Julian fixed an issue with authentication flows where we would emit too many network.responseCompleted events. This is still being discussed on the spec side and might change in the future, but for now having a single event to mark the end of the authentication is easier to handle for WebDriver BiDi clients. (#1906106)
Henrik fixed a bug in browsingContext.navigate where the command would resolve too early if a script was performing a history navigation via a “beforeunload” event listener. (#1879163)
Sasha updated browsingContext.userPromptOpened to always contain the “defaultValue” for prompts of type “prompt”. (#1859814)
Henrik updated the browser.close command to silently discard all beforeunload prompts when closing the browser. (#1873196)
We just closed the metabug for creating the single-file archive! This is because we now:
Create a single-file archive (optionally encrypted)
The single-file archive is a specially prepared HTML page that provides instructions on how to recover from it when viewed in Firefox, and download links for Firefox when viewed in other browsers.
Moves the single-file archive into a user-configured directory
Generates the backup in the background, relatively quickly. Right now, it’s created maximum once an hour when there’s at least 5 minutes of user idle time.
The team is focusing on getting the UI for managing and configuring backups completed, as well as doing cleanup, measurement and maintenance bugs
Search and Navigation
Search
Moritz fixed a bug to not allow for empty search using search bar one-off buttons. Bug 1904014,
Moritz is helping with post search-config-v2 clean up and removed icons from extensions that’s no longer used, and removed SearchEngine.searchForm Bug 1895873, Bug 1903247
If you’re a regular follower of the Thunderbird blog, you might have wondered “what happened with the June office hours?” And while our teams were all pretty busy preparing for Thunderbird 128, we also have changed the Office Hours format. Instead of recording live, which sometimes made scheduling difficult, we’ll be prerecording most Office Hours and releasing a blog with the video and slides, just like this one!
One week before we record, we’ll put out a call for questions on socialmedia and on the relevant TopicBox mailing lists. And every few months, we’ll have open, live ‘ask us anything’ office hours. We are definitely keeping the community in the Community Office Hours, even with the new format.
June Office Hours: Thunderbird Support (Part 1)
In this first of two Office Hours, the Community Team sat down to talk with User Support Specialist Roland Tanglao. Roland has been a long-time Mozilla Support (SUMO) regular, as well as a member of the Thunderbird community. A large part of Roland’s current work is on the Thunderbird side of SUMO, writing and updating Knowledge Base (KB) articles and responding to user questions in the forums.
Roland takes us through the who, what, and how of writing, updating, and translating Thunderbird KB articles. If you’ve ever wanted to write or translate a KB article, or wanted to suggest updates to ones which are out of date, Roland shows you how and where to get started.
Documentation is great way to become an open source contributor, or to broaden your existing involvement.
Highlights of Roland’s discussion include:
The structure and markup language of the SUMO Wiki
How to find KB issues that need help
Where to meet and chat with other volunteers online
A demonstration of the KB revision workflow
Our KB sandbox where you can safely try things out
Watch, Read, and Get Involved
This chat helps demystify how we and the global community create, update, and localize KB articles. We hope it and the included deck inspire you to share your knowledge, eye for detail, or multilingual skills. It’s a great way to get involved with Thunderbird – whether you’re a new or experienced user!
Greater openness, privacy, fair competition, and meaningful choice online have never been more paramount. With the new European Commission mandate kicking in, we put forward a series of policy recommendations to achieve these goals.
Mozilla envisions a future where the Internet is a truly global public resource that is open and accessible to all. Our commitment to this vision stems from our foundational belief that the Internet was built by people for people and that its future should not be dictated by a few powerful organizations.
When technology is developed solely for profit, it risks causing real harm to its users. True choice and control for individuals online can only be achieved through open, fair, and competitive markets that foster innovation and diversity of services and providers. However, today’s web is far from this ideal state.
Over the coming years, we must radically shift the direction of the web—and, by extension, the internet—towards greater openness, privacy, fair competition, and choice.
The European Union has adopted milestone pieces of tech legislation that strive to achieve these goals and have set the tone for global regulatory trends. For laws like the Digital Services Act (DSA), the Digital Markets Act (DMA), the GDPR, and the AI Act to realise their full potential, we strongly support reinforcing cooperation, shared resources, and strategic alignment among regulators and enforcement authorities.
In parallel, as the new European Commission mandate kicks in, our policy vision for the next five years (2024-2029) is anchored in our guiding principles for a Healthy Internet. With these principles in mind, we believe that the following priorities should be the ‘north star’ for EU regulators and policymakers to realise the radical shift today’s web needs.
Promoting Openness & Accountability in AI: Update Europe’s Open Source Strategy in order to leverage the value and benefits open approaches can bring in the AI space and to create the conditions that can fuel and foster Europe’s economic growth. Involve civil society, researchers, academia, and smaller AI developers in the AI Act implementation to prevent big AI companies from dominating the process. Address cloud market concentration, ensure robust liability frameworks, and guarantee meaningful researcher access to scrutinize AI models for greater accountability and transparency.
Safeguarding Privacy & Restoring Trust Online: Safeguard Europe’s existing high privacy standards (e.g. GDPR). Address aggressive tracking techniques and ensure the technical expression of user choices through the use of browser-based signals is respected. Incentivize privacy-enhancing technologies (PETs) and mandate greater transparency in the online advertising value chain to enhance accountability and data protection.
Increasing Fairness & Choice for Consumers: Ensure robust enforcement of the DSA and DMA by empowering regulatory bodies and assessing compliance proposals for true contestability and fairness. Update EU consumer protection rules to address harmful design practices both at interface and system architecture levels. Introduce anti-circumvention clauses for effective compliance with rules while also ensuring consumers are given meaningful choices and control over personalization features.
You can read more about our detailed recommendations here.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at @ThisWeekInRust on X(formerly Twitter) or @ThisWeekinRust on mastodon.social, or send us a pull request.
Want to get involved? We love contributions.
This week's crate is cargo-wizard, a cargo subcommand that applies profile and config templates to your Cargo project to configure it for maximum performance, fast compile times or minimal binary size.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization. The following
RFCs would benefit from user testing before moving forward:
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing
label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature
need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on X (Formerly twitter) or Mastodon!
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on X (Formerly twitter) or Mastodon!
Fairly quite week with the only pure regressions being small and coming from correctness fixes. The biggest single change came from turning off the -Zenforce-type-length-limit check which had positive impacts across many different benchmarks since the compiler is doing strictly less work.
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
I have a dream. A dream that Cargo has its own release cadence, so it is free from the strict stability curse and can then ship major version releases.
It’s Matt here from the SpiderMonkey team, with another newsletter for you. I hope you’re enjoying summer/winter. The last heatwave where I am broke on Thursday evening, with a dramatic drop in temperatures driven by the arrival of a thunderstorm. Unfortunately for me, it seems to be back for round two this week.
In SpiderMonkey land we’ve been hard at work on a number of things, but you’ll see from this abbreviated blog that we do tend to slow down a bit in the middle of the year as vacations build up.
In June of this year Mozilla, in collaboration with Aalto University hosted the 102nd meeting of TC39 in Helsinki, Finland. I was actually able to attend this meeting in person, which was really interesting to me. On the one hand, seeing how JavaScript is standardized from such an intimate viewpoint was extremely eye-opening. On the other hand, Helsinki was also just wonderful.
🚉 SpiderMonkey Platform Improvements
Work is underway to smooth the sharing of string contents across Gecko and SpiderMonkey, tracked under Bug 1892253 - Use a shared string buffer type for JS and DOM strings. The intention of this work is to reduce the overhead and copying required when strings cross from SpiderMonkey into Gecko and back.
🔦 Contributor Spotlight
This Newsletter’s Contributor Spotlight focuses on Debadree Chatterjee! In his own words,
A fully stack js dev mostly working with react and nodejs with a newfound interest in learning about JS runtimes and JIT compilers, Initially exposed to workings of jit compilers when studying nodejs internals and from there still going down the rabbit hole of exploring js engines :-)
He is on an ongoing quest to implement Explicit Resource Management, and has made great progress. Thank you so much for all your work Debadree, and I hope to keep hearing from you as a contributor over time!
🧑🏾🏫 Mentored Bugs
Are you curious about what it would be like to contribute to SpiderMonkey, but not sure what kind of work is hanging around? This section, new for this newsletter, highlights a few of our bugs which have mentors assigned that we think would be interesting for newish contributors to tackle. Not all our Mentored bugs are in equally good shape to have new contributors jump on, but the following are pretty safe bets
Iain landed Bug 1895957 - Use emitCalleeGuard in GetPropIRGenerator::tryAttachScriptedProxy , which handles proxies where the handler uses function literals by checking the Script (our representation of code, which is shared here) rather than Functions, which will not be shared. This was a 5% improvement on the Speedometer 3 ChartJS test.
We recently shared a number of updates with our community of users, and now we want to share them here:
At Mozilla, we work hard to make Firefox the best browser for you. That’s why we’re always focused on building a browser that empowers you to choose your own path, that gives you the freedom to explore without worry or compromises. We’re excited to share more about the updates and improvements we have in store for you over the next year.
Bringing you the features you’ve been asking for
We’ve been listening to your feedback, and we’re prioritizing the features you want most.
Tab Grouping, Vertical Tabs, and our handy Sidebar will help you stay organized no matter how many tabs you have open — whether it’s 7 or 7,500.
Plus, our new Profile Management system will help keep your school, work, and personal browsing separate but easily accessible.
Customizable new tab wallpapers that will let you choose from a diverse range of photography, colors, and abstract images that suits you most.
Intuitive privacy settings that deliver all the power of our world-class anti-tracking technologies in a simplified, easy-to-understand way.
Morestreamlined menus that reduce visual clutter and prioritize top user actions so you can get to the important things quicker.
Continuous work on speed, performance and compatibility
Speed is everything when you’re online, so we’re continuing to work hard to make Firefox as fast and efficient as possible. You can expect even faster, smoother browsing on Firefox,thanks to quicker page loads and startup times – all while saving more of your phone’s battery life. We’ve already improved responsiveness by 20 percent as measured by Speedometer 3, a collaboration we’ve spearheaded with other leading tech companies. And in that collaborative spirit, we’re also working with the Interop project to make it easy for people to build sites that work great across all browsers. We value your support in our efforts to improve cross-browser compatibility which is why we’ve added new features to easily report when websites aren’t working quite right; this feedback is critical as we look to address even small functionality issues that affect your day-to-day online experience.
Making the most of your time online — without sacrifice
Ensuring your privacy is core to everything we do at Firefox. Unlike other companies, who ask you to exchange your data in order to do even basic, everyday things online — you don’t have to give up your personal information to get a faster, more efficient browser experience with Firefox. Reading a news story in a different language or signing a form for school or work shouldn’t require you to give up your privacy. So, we’ve worked hard to make things like translation and PDF editing in Firefox happen locally on your device, so you don’t have to ship off your personal data to a server farm for a company to use it how they see fit — to keep tabs on you, sell your information to the highest bidder, or train their AI. With Firefox, you have a lot of choice — but you don’t have to choose between utility and privacy. Your data is secure, and most importantly, just yours.
We are approaching the use of AI in Firefox — which many, many of you have been asking about — in the same way. We’re focused on giving you AI features that solve tangible problems, respect your privacy, and give you real choice.
We’re looking at how we can use local, on-device AI models — i.e., more private — to enhance your browsing experience further. One feature we’re starting with next quarter is AI-generated alt-text for images inserted into PDFs, which makes it more accessible to visually impaired users and people with learning disabilities.
Join us on this journey
Our progress is driven by a vibrant community of users and developers like you. We encourage you to contribute to our open-source projects and to engage with us on Mozilla Connect or Discourse, and check out our recent AMA on Reddit. Your participation is crucial in shaping what Firefox becomes next.
A while ago I already looked into Avast Secure Browser. Back then it didn’t end well for Avast: I found critical vulnerabilities allowing arbitrary websites to infect user’s computer. Worse yet: much of it was due to neglect of secure coding practices, existing security mechanisms were disabled for no good reason. I didn’t finish that investigation because I discovered that the browser was essentially spyware, collecting your browsing history and selling it via Avast’s Jumpshot subsidiary.
But that was almost five years ago. After an initial phase of denial, Avast decided to apologize and to wind down Jumpshot. It was certainly a mere coincidence that Avast was subsequently sold to NortonLifeLock, called Gen Digital today. Yes, Avast is truly reformed and paying for their crimes in Europe and the US. According to the European decision, Avast is still arguing despite better knowledge that their data collection was fully anonymized and completely privacy-conformant but… well, old habits are hard to get rid of.
Either way, it’s time to take a look at Avast Secure Browser again. Because… all right, because of the name. That was a truly ingenious idea to name their browser like that, nerd sniping security professionals into giving them free security audits. By now they certainly would have addressed the issues raised in my original article and made everything much more secure, right?
Note: This article does not present any actual security vulnerabilities. Instead, this is a high-level overview of design decisions that put users at risk, artificially inflating the attack surface and putting lots of trust into the many, many companies involved with the Avast webspaces. TL;DR: I wouldn’t run Avast Secure Browser on any real operating system, only inside a virtual machine containing no data whatsoever.
Contents
Summary of the findings
The issues raised in my original article about the pre-installed browser extensions are still partially present. Two extensions are relaxing the default protection provided by Content-Security-Policy even though it could have been easily avoided. One extension is requesting massive privileges, even though it doesn’t actually need them. At least they switched from jQuery to React, but they still somehow managed to end up with HTML injection vulnerabilities.
In addition, two extensions will accept messages from any Avast website – or servers pretending to be Avast websites, since HTTPS-encrypted connections aren’t being enforced. In the case of the Privacy Guard (sic!) extension, this messaging exposes users’ entire browsing information to websites willing to listen. Yes, Avast used to collect and sell that information in the past, and this issue could in principle allow them to do it again, this time in a less detectable way.
The Messaging extension is responsible for the rather invasive “onboarding” functionality of the browser, allowing an Avast web server to determine almost arbitrary rules to nag the user – or to redirect visited websites. Worse yet, access to internal browser APIs has been exposed to a number of Avast domains. Even if Avast (and all the other numerous companies involved in running these domains) are to be trusted, there is little reason to believe that such a huge attack surface can possibly be secure. So it has to be expected that other websites will also be able to abuse access to these APIs.
What is Avast Secure Browser?
Avast Secure Browser is something you get automatically if you don’t take care while installing your Avast antivirus product. Or AVG antivirus. Or Avira. Or Norton. Or CCleaner. All these brands belong to Gen Digital now, and all of them will push Avast Secure Browser under different names.
According to their web page, there are good reasons to promote this browser:
So one of the reasons is: this browser is 100% free. And it really is, as in: “you are the product.” I took the liberty of making a screenshot of the browser and marking the advertising space:
Yes, maybe this isn’t entirely fair. I’m still indecisive as to whether the search bar should also be marked. The default search engine is Bing and the browser will nudge you towards keeping it selected. Not because Microsoft’s search engine is so secure and private of course but because they are paying for it.
But these are quality ads and actually useful! Like that ad for a shop selling food supplements, so that you can lead a healthy life. A quick search reveals that one of the three food supplements shown in the ad is likely useless with the suspicion of being harmful. Another brings up lots of articles by interested parties claiming great scientifically proven benefits but no actual scientific research on the topic. Finally the third one could probably help a lot – if there were any way of getting it into your body in sufficient concentration, which seems completely impossible with oral intake.
Now that we got “free” covered, we can focus on the security and privacy aspects in the subsequent sections.
My previous article mentioned Avast Secure Browser adding eleven extensions to the ones already built into Google Chrome. This number hasn’t changed: I still count eleven extensions, even though their purposes might have changed. At least that’s eleven extensions for me, differently branded versions of this browser seem to have a different combination of extensions. Only two of these extensions (Coupons and Video Downloader) are normally visible in the list of extensions and can be easily disabled. Three more extensions (Avast Bank Mode, Avast SecureLine VPN, Privacy Guard) become visible when Developer Mode is switched on.
And then there are five extensions that aren’t visible at all and cannot be disabled by regular means: Anti-Fingerprinting, Messaging, Side Panel, AI Chat, Phishing Protection. Finally, at least the New Tab extension is hardwired into the browser and is impossible to disable.
Now none of this is a concern if these extensions are designed carefully with security and privacy in mind. Are they?
The permissions requested by this extension still grant it almost arbitrary access to all websites. But at least the only unused privilege on this list is management which gives it the ability to disable or uninstall other extensions.
As to CSP, there is still 'unsafe-eval' which allowed this extension to be compromised last time. But now it’s there for a reason: Video Downloader “needs” to run some JavaScript code it receives from YouTube in order to extract some video metadata.
I did not test what this code is or what it does, but this grants at the very least the YouTube website the ability to compromise this extension and, via it, the integrity of the entire browser. But that’s YouTube, it won’t possibly turn evil, right?
For reference: it is not necessary to use 'unsafe-eval' to run some untrusted code. It’s always possible to create an <iframe> element and use the sandbox attribute to execute JavaScript code in it without affecting the rest of the extension.
But there are more extensions. There is the Avast Bank Mode extension for example, and its extension manifest says:
Yes, requesting every possible permission and allowing execution of dynamic scripts at the same time, the exact combination that wreaked havoc last time. Why this needs 'unsafe-eval'? Because it uses some ancient webpack version that relies on calling eval() in order to “load” JavaScript modules dynamically. Clearly, relaxing security mechanisms was easier than using a better module bundler (like the one used by other Avast extensions).
The (lack of) ad blocking privacy
The Privacy Guard extension is responsible for blocking ads and trackers. It is meant by the sentence “block ads and boost your online privacy” in the website screenshot above. It is also one of the two extensions containing the following entry in its manifest:
What this means: any other extension installed is allowed to send messages to the Privacy Guard extension. That isn’t restricted to Avast extensions, any other extension you installed from Avast’s or Google’s add-on store is allowed to do this as well.
The same is true for any website under the domains avast.com, securebrowser.com, avastbrowser.com, avgbrowser.com or ccleanerbrowser.com. Note that the rules here don’t enforce https:// scheme, unencrypted HTTP connections will be allowed as well. And while avast.com domain seems to be protected by HTTP Strict Transport Security, the other domains are not.
Why this matters: when your browser requests example.securebrowser.com website over an unencrypted HTTP connection, it cannot be guaranteed that your browser is actually talking to an Avast web server. In fact, any response is guaranteed to come from a malicious web server because to such website exists.
One way you might get a response from such a malicious web server is connecting to a public WiFi. In principle, anyone connected to the same WiFi could redirect unencrypted web requests to their own malicious web server, inject an invisible request to example.securebrowser.com in a frame (which would also be handled by their malicious server) and gain the ability to message Privacy Guard extension. While not common, this kind of attack did happen in the wild.
The first part are the Privacy Guard settings, your whitelisted domains, everything. There are also the three hardcoded lists containing blocking exceptions – funny how Avast doesn’t seem to mention these anywhere in the user interface or documentation. I mean, it looks like in the default “Balanced Mode” their ad blocker won’t block any ads on Amazon or eBay among other things. Maybe Avast should be more transparent about that, or people might get the impression that this has something to do with those sponsored bookmarks.
And then there is information about all your browsing tabs which I shortened to only one tab here. It’s pretty much all information produced by the tabs API, enriched with some information on blocked ads. Privacy Guard will not merely send out the current state of your browsing session, it will also send out updates whenever something changes. To any browser extension, to any Avast website and to any web server posing as an Avast website.
Does Avast abuse this access to collect users’ browsing data again? It’s certainly possible. As long as they only do it for a selected subset of users, this would be very hard to detect however. It doesn’t help that Avast Secure Browser tracks virtual machine usage among other things, so it’s perfectly plausible that this kind of behavior won’t be enabled for people running one. It may also only be enabled for people who opened the browser a given number of times after installing it, since this is being tracked as well.
Can other browser extensions abuse this to collect users’ browsing data? Absolutely. An extension can declare minimal privileges, yet it will still be able to collect the entire browsing history thanks to Privacy Guard.
Can a malicious web server abuse this to collect users’ browsing data beyond a single snapshot of currently open tabs? That’s more complicated since this malicious web server would need its web page to stay open permanently somehow. While Avast has the capabilities to do that (more on that below), an arbitrary web server normally doesn’t and has to resort to social engineering.
The messaging interface doesn’t merely allow reading data, the data can also be modified almost arbitrarily as well. For example, it’s possible to enable ad blocking without any user interaction. Not that it changes much, the data collection is running whether ad blocking is enabled or not.
This messaging interface can also be used to add exceptions for arbitrary domains. And while Privacy Guard options page is built using React.js which is normally safe against HTML injections, in one component they chose to use a feature with the apt name dangerouslySetInnerHTML. And that component is used among other things for displaying, you guessed it: domain exceptions.
This is not a Cross-Site Scripting vulnerability, thanks to CSP protection not being relaxed here. But it allows injecting HTML content, for example CSS code to mess with Privacy Guard’s options page. This way an attacker could ensure that exceptions added cannot be removed any more. Or they could just make Privacy Guard options unusable altogether.
The onboarding experience
The other extension that can be messaged by any extension or Avast web server is called Messaging. Interestingly, Avast went as far as disabling Developer Tools for it, making it much harder to inspect its functionality. I don’t know why they did it, maybe they were afraid people would freak out when they saw the output it produces while they are browsing?
You wonder what is going on? This extension processes some rules that it downloaded from https://config.avast.securebrowser.com/engagement?content_type=messaging,messaging_prefs&browser_version=126.0.25496.127 (with some more tracking parameters added). Yes, there is a lot of info here, so let me pick out one entry and explain it:
{"post_id":108341,"post_title":"[190] Switch to Bing provider – PROD; google","engagement_trigger_all":[{"parameters":[{"operator":"s_regex","value":"^secure:\\/\\/newtab","parameter":{"post_id":11974,"name":"url_in_tab","post_title":"url_in_tab","type":"string"}}]},{"parameters":[{"operator":"s_regex","value":"google\\.com","parameter":{"post_id":25654,"name":"setting_search_default","post_title":"setting_search_default (search provider)","type":"string"}}]}],"engagement_trigger_any":[{"parameters":[{"operator":"equals","value":"0","parameter":{"post_id":19236,"name":"internal.triggerCount","post_title":"internal.triggerCount","type":"number"}}]},{"parameters":[{"operator":"n_gte","value":"2592000","parameter":{"post_id":31317,"name":"functions.interval.internal.triggered_timestamp","post_title":"interval.internal.triggered_timestamp","type":"number"}}]}],"engagement_trigger_none":[],…}
The engagement_trigger_all entry lists conditions that have all be true: you have to be on the New Tab page, and your search provider has to be Google. The engagement_trigger_any entry lists conditions where any one is sufficient: this particular rule should not have been triggered before, or it should have been triggered more than 2592000 seconds (30 days) ago. Finally, engagement_trigger_none lists conditions that should prevent this rule from applying. And if these conditions are met, the Messaging extension will inject a frame into the current tab to nag you about switching from Google to Bing:
Another rule will nag you every 30 days about enabling the Coupons extension, also a cash cow for Avast. There will be a nag to buy the PRO version for users opening a Private Browsing window. And there is more, depending on the parameters sent when downloading these rules probably much more.
An interesting aspect here is that these rules don’t need to limit themselves to information provided to them. They can also call any function of private Avast APIs under the chrome.avast, chrome.avast.licensing and chrome.avast.onboarding namespaces. Some API functions which seem to be called in this way are pretty basic like isPrivateWindow() or isConnectedToUnsafeWifi(), while gatherInfo() for example will produce a whole lot of information on bookmarks, other browsers and Windows shortcuts.
Also, displaying the message in a frame is only one possible “placement” here. The Messaging extension currently provides eight different user interface choices, including straight out redirecting the current page to an address provided in the rule. But don’t worry: Avast is unlikely to start redirecting your Google searches to Bing, this would raise too many suspicions.
Super-powered websites
Why is the Messaging extension allowing some Avast server to run browser APIs merely a side-note in my article? Thing is: this extension doesn’t really give this server anything that it couldn’t do all by itself. When it comes to Avast Secure Browser, Avast websites have massive privileges out of the box.
The browser grants these privileges to any web page under the avast.com, avg.com, avastbrowser.com, avgbrowser.com, ccleanerbrowser.com and securebrowser.com domains. At least here HTTPS connections are enforced, so that posing as an Avast website won’t be possible. But these websites automatically get access to:
chrome.management API: complete access to extensions except for the ability to install them
chrome.webstorePrivate API: a private browser API that allows installing extensions.
A selection of private Avast APIs:
chrome.avast
chrome.avast.licensing
chrome.avast.ntp
chrome.avast.onboarding
chrome.avast.ribbon
chrome.avast.safebrowsing
chrome.avast.safesearch
chrome.avast.stats
chrome.avast.themes
Now figuring out what all these private Avast APIs do in detail, what their abuse potential is and whether any of their crashes are exploitable requires more time than I had to spend on this project. I can see that chrome.avast.ntp API allows manipulating the tiles displayed on the new tab page in arbitrary ways, including reverting all your changes so that you only see those sponsored links. chrome.avast.onboarding API seems to allow manipulating the “engagement” data mentioned above, so that arbitrary content will be injected into tabs matching any given criteria. Various UI elements can be triggered at will. I’ll leave figuring out what else these can do to the readers. If you do this, please let me know whether chrome.avast.browserCall() can merely be used to communicate with Avast’s Security & Privacy Center or exposes Chromium’s internal messaging.
But wait, this is Avast we are talking about! We all know that Avast is trustworthy. After all, they promised to the Federal Trade Commission that they won’t do anything bad any more. And as I said above, impersonating an Avast server won’t be possible thanks to HTTPS being enforced. Case closed, no issue here?
Not quite, there are far more parties involved here. Looking only at www.avast.com, there is for example OneTrust who are responsible for the cookie banners. Google, Adobe, hotjar, qualtrics and mpulse are doing analytics (a.k.a. user tracking). A Trustpilot widget is also present. There is some number of web hosting providers involved (definitely Amazon, likely others as well) and at least two content delivery networks (Akamai and Cloudflare).
And that’s only one host. Looking further, there is a number of different websites hosted under these domains. Some are used in production, others are experiments, yet more appear to be abandoned in various states of brokenness. Some of these web services seem to be run by Avast while others are clearly run by third parties. There is for some reason a broken web shop run by a German e-commerce company, same that used to power Avira’s web shop before Gen Digital bought them.
If one were to count it all together, I would expect that a high two digit number of companies can put content on the domains mentioned above. I wouldn’t be surprised however if that number even went into three digits. Every single one of these companies can potentially abuse internal APIs of the Avast Secure Browser, either because they decide to make some quick buck, are coerced into cooperation by their government or their networks simply get compromised.
And not just that. It isn’t necessary to permanently compromise one of these web services. A simple and very common Cross-Site Scripting vulnerability in any one of these web services would grant any website on the internet access to these APIs. Did Avast verify the security and integrity of each third-party service they decided to put under these domains? I very much doubt so.
It would appear that the official reason for providing these privileges to so many websites was aiding the onboarding experience mentioned above. Now one might wonder whether such a flexible and extensive onboarding process is really necessary. But regardless of that, the reasonable way of doing this is limiting the attack surface. If you need to grant privileges to web pages, you grant them to a single host name. You make sure that this single host name doesn’t run any more web services than it absolutely needs, and that these web services get a proper security review. And you add as many protection layers as possible, e.g. the Content-Security-Policy mechanism which is severely underused on Avast websites.
At this point, the Appellate Authority considers it necessary to recall that the Charged Company provides software designed to protect the privacy of its users. As a professional in the information and cyber field, the Charged Company is thereby also expected to be extremely knowledgeable in the field of data protection.
Apple Safari includes an advertising measurement feature, but fortunately you can turn it off. I don’t regularly use this browser but can get a hold of a copy to check it, so I’ll update this if the instructions change.
On Apple iOS
Open Settings, select Safari, then scroll down to Advanced.
Turn off Privacy Preserving Ad Measurement
While you have Settings open, you might as well check two other iOS tracking features.
In Settings, go to Privacy & Security, then Tracking, and make sure “Allow Apps to Request to Track” is turned off.
Also in Settings under Privacy & Security, find “Apple Advertising” and make sure that “Personalized Ads” is turned off. (You will probably have to scroll down—Apple makes this one a little trickier to find.)
On Mac OS
From the Safari menu, choose Settings, then select the Advanced tab.
Uncheck Allow privacy-preserving measurement of ad effectiveness
why turn this off?
The deeper they hide stuff like this, the more it shows they understand that it’s not in your best interest to have it on. The Apple billboards are all about protecting you from tracking. I haven’t seen one yet that was more like Connect and share with brands you love! (please me know if you see any Apple billboards like this)
Information has value in a market. When your browser passes information about you—even in a form that is supposed to prevent individual tracking—you’re rewarding risky and problematic advertising practices along with the legit ones. Some advertising has value, but putting legit sites and malvertising on an equal basis for data collection is not helping.
With a Little Help, Western Bluebirds Are Nesting in AlamedaRemember, we humans cut down dead trees for safety, but that is bad for birds that are cavity nesters. Would you like to do something to improve nesting habitat? Consider installing nest boxes around your home, school, or community center.
Every advertising event is full of thought leader insights about privacy-enhancing technologies (PETs) for ad personalization and reporting systems. Somehow Big Tech, adtech, and martech are all fired up about projects for reimplementing personalized/surveillance advertising, but this time with a bunch of complicated math added in a way that makes it hard to identify or track an individual.
In the real world, though, individualized tracking is not the top advertising privacy problem, and it might not even be in the top five. Arielle Garcia, director of intelligence for Check My Ads, said, Privacy-enhancing tech doesn’t make creepy and disruptive ads less creepy or disruptive in the eyes of the average user. And the user research backs that up. Jereth et al. find that perceived privacy violations for a browser-based system that does not target people individually are similar to the perceived violations for conventional third-party cookies. Co-author Klaus M. Miller presented the research at FTC PrivacyCon (PDF):
So keeping your data safer on your device seems to help in terms of consumer perceptions, but it doesn’t make any difference whether the firm is targeting the consumer at the individual or group level in the perceived privacy perceptions.
This might not make sense if you compare just the information passed through PETs to what is possible to do with a third-party cookie. It’s fewer total bits of information, so the users should be getting more privacy and like it better, right? Not so fast. The real problems that people complain about when they raise privacy concerns are more about information asymmetry.
People tend not to want to participate in markets in ways that give their counterparties too much information. Imagine going on vacation and visiting an old-fashioned rug market—and showing every rug merchant your budget, shopping list, and departure date. Information imbalances are not how sustainable markets work. And that’s just legit markets. The situation is even worse on today’s scam culture Internet, where the old fake it til you make it has been replaced with make it, then fake it even harder. The pervasive risks of scam culture are mostly group-level personalization risks and not the consequences of being individually identified.
Some PETs just measure ad performance and don’t personalize. But when the same measurement system covers both harmful and win-win ad placements, it creates incentives for advertisers to chase the best possible metrics while creating the least possible value for the user. In a sustainable system, the user, or some party that the user trusts to provide an ad-supported resource, would be a data gatekeeper to keep data from leaking into the negative-sum corners of the Internet. People choose to provide their information to parties they trust—they don’t broadcast info about themselves to trusted and untrusted parties on the same terms.
how things got this far
PETs started to go mainstream in the advertising scene back in 2019 when Google announced the Privacy Sandbox project. (Apple was first with wide release of a PET ad system, Private Click Measurement in 2021.) At the time, some people picked up on PETs as an alternative to platform dystopia, a way for independent retailers and publishers on the web to make a compromise and continue to do business without a hard dependency on fixing the Internet’s deeper monopolization, discrimination, and fraud problems. But in the about five years that people have been been arguing about web ad PETs, most recently over Google’s ongoing effort to make their PETs acceptable to the Competition and Markets Authority (CMA) in the UK, a big PET win is looking less and less likely. After all the work that has gone into PETs, not only do big risks remain, but—and this is super awkward—the companies working on PETs are still the same Big Tech companies that PETs were supposed to…protect us from?
Meanwhile, in the years since the PET trend began, mainstream privacy laws have gone off in a different direction, and focused not on obfuscation and math, but on data minimization and on enabling people to find out how companies use data. Data subject access rights, or “right to know,” are a key component of modern privacy laws and make it possible for web users and for organizations working on their behalf to detect patterns of illegal discrimination. In a 2019 settlement, Facebook agreed to stop using age, gender and ZIP code for housing, employment and credit ads. Reporters were later able to track the company’s progress. Privacy researchers and advocates continue to benefit from “right to know” processes today. A PET environment, however, limits access to data, making algorithmic discrimination hard to detect.
Much recent privacy news would have been as bad or worse in a PET environment. Grindr users aren’t suing over privacy because they were individually identified, they are suing because they were identified by HIV status, a fact common to a large group of people. Reviews of Google’s Privacy Sandbox, have, for quite a while, anticipated regulator concerns over algorithmic discrimination and transparency. The W3C TAG, in a review of a Privacy Sandbox” sub-project, wrote, “The Topics API as proposed puts the browser in a position of sharing information about the user, derived from their browsing history, with any site that can call the API. This is done in such a way that the user has no fine-grained control over what is revealed, and in what context, or to which parties. It also seems likely that a user would struggle to understand what is even happening; data is gathered and sent behind the scenes, quite opaquely.” Under privacy laws, users have the right to access not just their raw data, but the inferences made from it—a capability that will be difficult to retrofit into PETs. Google posted a FAQ stating,
Chrome can and will take steps to avoid topics that might be sensitive (i.e. race, sexual orientation, religion, etc.). However, it is still possible that websites calling the API may combine or correlate topics with other signals to infer sensitive information, outside of intended use. Chrome will continue to investigate methods for reducing this risk.
No results have been posted from this investigation so far. Someone will probably get a Best Paper award at a conference for solving this…eventually. Until that happens, PETs will struggle to meet basic transparency requirements in more and more jurisdictions. The data obfuscation problems introduced by PETs will also create compliance challenges in the area of competition policy. In a recent Google report (PDF) to the CMA, the company acknowledges that compliance with the Digital Services Act (DSA) by “Privacy Sandbox” publishers and advertisers remains an unsolved problem.
alternatives
So what do we do instead? PETs may continue to be valuable in fields like software telemetry, where the end result is all users receiving the same bug fixes, not different treatment of different users. But ads are a harder problem. First of all, PETs are not a shortcut to solving some important platform trust issues.
I see that your industry sold my parents a retirement scam, put malware in my search results, and showed fake repair shops on a map of my neighborhood…but I totally trust your answer to this complicated math problem. — no one ever
The hard part about running any Internet service is the moderation (including ad review if it’s an ad-supported service). At some point Big Tech management needs to get over its dogmatic union-busting and sign fair contracts with the moderators and all the other people who do the high-skill human side of their operations. You can’t fix a reputation problem with math.
As far as how to make the ads work, it’s possible to get rid of third-party cookies and other problematic identifiers like mobile ad IDs without also taking on an open-ended research project. Instead of starting from what data flows are acceptable to today’s platforms/adtech/martech and trying to stick enough math on them to make them acceptable to users, start with how people choose to participate in markets and automate it. The Lindy Effect is a real thing in marketing. Ideas get tested out all the time, but the practices that tend to persist are the ones that have endured many generations of marketers, companies, and technologies. So the history of marketing practices that people have been willing to accept in the past is probably the best guide here. Realistically, markets will always have high and low reputation sellers, and the advertising most likely to persist will be whatever can pay for itself in (ad-supported resources + economic signal) > (cost in attention + resources + risk).
Finding something successful and sustainable and adapting it to the web is good for more total ad revenue over time—even if in any one transaction you get to capture less of it. A browser is a user agent, which means it does what users would do for themselves if they had time. People like to buy stuff, and prefer to buy better stuff. How can browsers help?
Used.Today, though I make more money than ever before in my life, have more disposable income and am statistically in the top one-percent of American income-earners, there’s scarcely a brand or a product that tells me anything I feel I need to know about themselves.
Revenue-Share Orgy: Why Ad Agencies Are in Bed with EveryoneWe’re not going to fix our industry’s anemic ad-driven sales growth without rekindling the critical thinking, transparency, trust, and communication that originally built our business.
Glyph Lefkowitz: Against Innovation TokensWhen programmers make a technology selection, we are often considering how difficult it will make the programming. Innovative technology selections are, by definition, less mature. That lack of maturity — particularly in the open source world — often means that the project is in a part of its lifecycle where it is concerned with development affordances more than operational ones. Therefore, the stereotypical innovative project, even one which might legitimately be a big improvement to development velocity, will create more operational overhead.
Today, Fakespot, a free browser extension and website that protects consumers from unreliable reviews and sellers, announced the Amazon product categories with the most reliable and unreliable reviews, just in time for the big summer sales and back-to-school shopping season.
“We’re all about helping you shop smarter, especially during this month’s summer sales and the upcoming back-to-school season,” said Saoud Khalifah, co-founder and director of Fakespot. “Our latest report shows just how crucial it is to check those reviews, especially in categories flooded with unreliable reviews. By spotlighting both the best and worst categories, we give you the tools to shop with confidence.”
Since 2016, Fakespot has empowered millions of shoppers to make well-informed purchases using advanced AI technology. Its AI engine analyzes reviews, filters out unreliable ones and gives shoppers a true understanding of the quality of a product and the seller, so they can feel confident about their decisions. As a free browser extension available on most web browsers, Fakespot analyzes reviews from top e-commerce sites like Amazon, Best Buy, Sephora and Walmart, providing the most reliable product information before you buy. Bonus: The extension also provides seller ratings on Shopify-powered web stores.
When it comes to online shopping, knowing which products are trustworthy can save time and money. We are sharing our latest findings just in time for the shopping season. Our latest analysis has revealed some surprising and noteworthy stats (June 1, 2023 through May 31, 2024). Here are the most reliable and least reliable popular product categories:
Shop with confidence: Top 5 categories you can trust
Shop confidently with these top-rated products. These categories earned Fakespot Grades of B or better for reliability.
Apple products: With an impressive 84% of reviews being genuine, Apple products stand out as a top choice for reliability. Only a tiny 5% of reviews are marked as unreliable.
Video game chairs: Gamers, rejoice! 84% of reviews for video game chairs are trustworthy, making this a solid category for your next purchase.
Books: Book lovers can breathe easy, as 81% of book reviews are authentic. Even with a whopping 2,907 products reviewed, books maintain a high standard of reliability.
Computers: Tech enthusiasts, take note. Computers come in with 79% genuine reviews, ensuring you get the real scoop before buying.
Home Office Desks: Perfect for remote work and homework, with 68% of reviews being legit.
Shop carefully: Top 5 categories to watch out for
Shop carefully and think twice before purchasing from these categories. These product categories have a Fakespot Review Grade of D or lower.
Slides: A staggering 75% of reviews for slides are unreliable, making it the least reliable category in our study.
Pajamas: Cozy up with caution, as 62% of pajama reviews aren’t genuine.
Basketball: Sports gear shoppers should be wary, with 61% of basketball-related product reviews being unreliable.
Stick vacuums and electric brooms: Housekeeping might need a bit more homework, with 57% unreliable reviews in this category.
Fashion hoodies and sweatshirts: Fashion fans, beware. Over half (57%) of reviews in this category are not reliable, despite the large number of products reviewed (6,078).
Millions of Fakespot users depend on Fakespot’s Review Grade to help determine the reliability of the product reviews and seller. It follows the standard grading system of “A”, “B”, “C”, “D”, or “F” and represents the following:
Fakespot Review Grade A and B: These grades represent reliable reviews.
Fakespot Review Grade C: This grade should be approached with caution, as it includes a mix of reliable and unreliable reviews.
Fakespot Review Grade D and F: These grades are considered unreliable.
We know just how crucial reliable reviews are in making informed purchasing decisions. Fakespot’s study sheds light on which categories are more prone to review manipulation, helping consumers make smarter, more informed choices.
So, whether it’s deal days or early back-to-school shopping, be sure to download Fakespot whenever you shop online.
On behalf of the entire team, the Thunderbird Council, and our global community of contributors, I’m excited to announce the initial release of Thunderbird 128 “Nebula.” This annual Extended Support Release (ESR) builds on the solid foundation established by Supernova last year.
Nebula ushers in significant improvements to Thunderbird’s code, stability, overall user experience, and the speed at which we can deliver new features to you.
Here’s a small sample of what you can look forward to in this initial release.
Thunderbird 128: A Rust Revolution
We’ve devoted significant development time integrating Rust — a modern programming language originally created by Mozilla Research — into Thunderbird. Even though this is a seemingly invisible change, it is a major leap forward because it enhances our code quality and performance. This overhaul will allow us to share features between the desktop and future mobile versions of Thunderbird, and speed up our development process. It’s a win for our developers and a win for you.
Redesigned Cards View
The Cards View, which debuted in 115 Supernova, has been tuned and refined for an even better experience. The new layout is more attractive and makes it easier to scan your email threads and glean information at a glance. Plus, the height of email cards adjusts automatically based on your settings, ensuring everything looks just right.
Enhanced Folder Pane
The Folder Pane has received several improvements, including faster rendering and searching of unified folders, better recall of message thread states, and multi-folder selection. We hope these changes make managing your folders faster and more intuitive.
Accent Colors
Thunderbird now offers improved theme compatibility, which is especially beneficial for our Linux users on Ubuntu and Mint. Your Thunderbird should blend seamlessly with your desktop environment, matching the system’s accent colors perfectly.
More Refinements & Updates
Account Color Customization: By popular demand, you can now customize the color of your account icons. These colors also appear in the “From” selection when composing emails, adding a light personal touch to your email experience.
Streamlined Menu Navigation: We’ve simplified menu navigation with better visual cues and reduced cognitive load. These enhancements make using Thunderbird more efficient and enjoyable.
Native Windows Notifications: Thunderbird’s native Windows notifications are now fully functional. Clicking a notification will dismiss it, bring Thunderbird to the foreground, and select the relevant message. Notifications also disappear when Thunderbird is closed, ensuring a seamless experience.
Improved Context Menu: The context menu has been reorganized for a smoother experience, with primary actions now displayed as icons for quick access.
Upcoming Exchange and Mozilla Sync Features
We plan to launch the first phase of built-in support for Exchange, as well as Mozilla Sync, in a future Nebula point release (e.g. Thunderbird 128.X). Although these features are very close to being finished, technical obstacles prevented them from being ready today. Alex will keep you updated in his monthly Thunderbird Monthly Dev Digests.
For advanced users who want to help test our initial implementation of Exchange (currently limited to Mail), it is now available in our Daily and Beta builds. This Wiki page has more information as well as instructions for enabling it. While we definitely welcome your testing and feedback, please keep in mind this feature is currently experimental, and you may run into unexpected behavior or errors.
Looking Forward
In space, a supernova creates the building blocks of creation. In a nebula, those elements nurture new possibilities. Thunderbird 128 Nebula brings together and builds on the best of Supernova! Expect more updates and useful new features in the coming months.
Thank you for being a part of the growing Thunderbird community and sharing this adventure with us. Your feedback and support motivate us to chase constant improvements and deliver the best email experience possible.
Thunderbird 128 Availability For Windows, Linux, and macOS
Even with QA and beta testing, any major software release may have issues exposed after significant public testing. That’s why we’ll wait to enable automatic updates until we’re confident no such issues exist. At present – Thunderbird version 128.0 is only offered as direct download from thunderbird.net and not as an upgrade from Thunderbird version 115 or earlier. A future release will provide updates from earlier versions.
This post has been automatically translated from English to other languages by DeepL. Please forgive any grammatical or spelling errors.
<figcaption class="wp-element-caption">Udbhav Tiwari, Mozilla’s Director of Global Product Policy, testifies at a Senate committee hearing on the importance of federal privacy legislation in the development of AI.</figcaption>
Today, U.S. Senator Maria Cantwell (D-Wash.), Chair of the Senate Committee on Commerce, Science and Transportation, convened a full committee hearing titled “The Need to Protect Americans’ Privacy and the AI Accelerant.” The hearing explored how AI has intensified the need for a federal comprehensive privacy law that protects individual privacy and sets clear guidelines for businesses as they develop and deploy AI systems.
Mozilla’s Director of Global Product Policy, Udbhav Tiwari, served as a key witness at the public hearing, highlighting privacy’s role as a critical component of AI policy.
“At Mozilla, we believe that comprehensive privacy legislation is foundational to any sound AI framework,” Tiwari said. “Without such legislation, we risk a ‘race to the bottom’ where companies compete by exploiting personal data rather than safeguarding it. Maintaining U.S. leadership in AI requires America to lead on privacy and user rights.” Tiwari added that data minimization should be at the core of these policies.
As a champion of the open internet, Mozilla has been committed to advancing trustworthy AI for half a decade. “We are dedicated to advancing privacy-preserving AI and advocating for policies that promote innovation while safeguarding individual rights,” Tiwari said.
Is it July already? That means it’s time for another report on the progress of creating Thunderbird for Android.
Unfortunately, June has been one of these months without any flashy new features that would make for a nice screenshot to show off in a blog post. To not leave you hanging without any visuals, please enjoy this picture of Thunderbird team member Chris Aquino’s roommate Mister Betsy:
This year Thunderbird has hired a lot of new people. I’m very happy to report that this also included a manager who will coordinate all of our mobile efforts. Some of you may already know him. Philipp Kewisch has been working on the calendar integrated into Thunderbird for desktop and has been with the project in one capacity or another for a very long time. We’re very excited to have him (back).
Building two apps
In June we continued to work on making the necessary changes to be able to build two apps – K-9 Mail and Thunderbird for Android.
Volunteers working on translating the app have probably already noticed that we changed a lot of user-visible texts that included the app name. In cases where the app name wasn’t strictly necessary, we removed it. In other cases we added a placeholder, so the name of the app can be inserted dynamically.
We also worked on internal changes to make it easier to build multiple apps. However, there’s still quite a bit of work left. So don’t expect a fully working Thunderbird-branded version of the app to be available next week.
Material 3
We’re still in the middle of migrating the user interface to Material 3. So far there hasn’t been any fine-tuning. What you currently see in beta versions of K-9 Mail is likely to change in the future. So we’re not looking for feedback on the design just yet.
Targeting Android 14
In May the changes to target Android 14 were included in a beta release. After a few weeks of testing and not receiving any reports of problems, we included these changes in K-9 Mail 6.804, a maintenance release of the stable branch.
As a reminder, these changes are necessary so the app is not run in a compatibility mode on Android 14. It means the app supports the latest Android restrictions (e.g. when it comes to running in the background) and security features. Google Play enforces this by not allowing apps to publish updates without targeting Android 14 after the August 31 deadline.
More translations
Thanks to the work of volunteer translators we were able to add support for the following languages to beta releases:
I’ve always loved journalism. When I was in high school a chemistry teacher once gently reprimanded me for reading a copy of The New York Times during class. When I told them I was more interested in the midterm elections than balancing equations, they said, “You’ll never get a job reading newspapers.”
Fast forward to today and that’s… basically what I do as a recommendations editor for Mozilla. It’s my job to think hard about what makes great content and how we should deliver it to users across all our products, including Firefox. I’m particularly passionate about amplifying incredible, impactful journalism, because I’ve also been a working journalist (and not, alas, a chemist). Before joining Mozilla, I was a senior editor at The Weekmagazine and a reporter for American City Business Journals, but Firefox has always been an indispensable part of my life as a reporter and editor. Here’s why.
Pocket has been part of my workflow for so long, I don’t really know what I’d do without it. I’ve used it to research countless articles over the years. The Firefox extension makes it outrageously easy to save just about anything you see on the internet to your personal library. And if you’re a tags sicko, you can really go to town. Whenever you save an article, just give it a tag. I created my own tagging system for story ideas, research for articles in progress, great work from other writers I admire, and recipes, because you know, reporters also have to eat.
<figcaption class="wp-element-caption">When you see an interesting page or video, click the Save to Pocket button to save it instantly.</figcaption>
Tab management
If it’s your job to be extremely online, you probably have strong opinions about tabs and tab management. I love Pinned Tabs for keeping tabs (sorry) on the ones that really matter. Also, you can’t close them accidentally when it’s time to declare tab bankruptcy (the OneTab extension is great for wiping the slate clean). Firefox’s Browser Sync also makes it easy to send tabs from one device to another, so you don’t lose your place on whatever you’re working on when it’s time to switch from desktop to smartphone or tablet.
Pocket and OneTab aren’t the only extensions worth calling out. Firefox has a huge library of add-ons. I’m partial to productivity extensions. A thing I love about journalists is that we’re interested in everything, unfortunately that also makes us highly distractible. I use a Pomodoro timer built into my browser for breaking up my work into manageable chunks and staying on task. Nobody likes the sound of a deadline whooshing past.
I think all reporters know the value of confidentiality and transparency. I’ve always liked that Firefox takes privacy seriously and isn’t hoovering up my browsing data to sell to the highest bidder and works overtime to protect users from predatory tracking practices by bad actors. This next thing isn’t a feature so much, but at a time when newspaper firms are being gobbled up and gutted by unscrupulous hedge funds and when other platforms are pivoting away from promoting journalism, it’s nice to know that Mozilla doesn’t work like the rest of big tech. We don’t work for shareholders, we work for users. Firefox is first and foremost a really, really good browser, but I also sleep better at night knowing that we’re trying to build a healthier internet, and journalism can’t thrive without that.
There are endless ways to make Firefox your own, whether you’re a journalist, a creative, a gamer, a minimalist, a shopper or however you choose to navigate the internet. We want to know how you customize Firefox. Let us know and tag us on X or Instagram at @Firefox.
It’s understandable that Mozilla wants to break their dependency on Google search ads, but right now they seem to be doing it by, yes, yet again putting advertising features in the browser. This time they’re doing it in a way that introduces new, hard-to-understand risks. Google gets all the ink for their ad features in the browser project, but Firefox has given us some to-do items, too. I’ll keep this post up to date if the instructions change.
Create an entry: dom.private-attribution.submission.enabled with a value of false.
That blog post also has info for disabling this by default in user.js which I have not tested.
Just putting privacy in the name of a feature doesn’t make it less creepy. Considering today’s branding trends it might even go the other way. Your privacy is important to us is the new your call is important to us. If you dig into the literature behind PPA, you will find some mathematical claims about how it prevents tracking of individuals. This is interesting math if you like that kind of thing. But in practice the real-world privacy risks are generally based on group discrimination, so it’s not really accurate to call a system privacy-preserving just because it limits individual tracking. Even if the math is neato.
Use the search field to find the entry for aboutConfig and enable it
Go to about:config
Search for dom.private-attribution.submission.enabled and set it to false
(I have not tested this—if you have better instructions please let me know.)
Sponsored stuff on the new tab page
These have been around for a while and do not seem to be a big deal, but just in case you’re creeped out by the whole PPA thing and on a roll with clicking around in settings…
Click the menu button (≡) and select Settings (if you’re not already in Settings from the previous tip)
In the Home panel, you have two options.
Change the New Windows and Tabs settings to Blank Page (fastest) or Custom URLs
Uncheck any or all of these boxes: Recommended by PocketSponsored shortcutsSponsored Stories
These do seem harmless but if you’re in doubt because of the whole turn on Meta tracking without asking thing I can understand turning them off too.
Turn on Global Privacy Control
I’m going to end with some good news and ask, please don’t get mad at Firefox in general just because of one more fad-chasing move by management. I have been using this thing since it was Netscape Navigator, and even worked there for a while, and I have always been able to muddle through. Here is a place where Firefox is ahead of the other browsers.
Go to about:config (and accept any warning dialogs if you get them).
Search for globalprivacycontrol.
Change the setting to true.
You can check that it works by going to globalprivacycontrol.org. Look for GPC signal detected at the top of the screen.
Ad blocker check
Mozilla seems to be doing better at keeping the scam ad blockers out of their extensions directory than Google—but that might just be that fewer malware developers are targeting Firefox now. But it is a good idea to check that your ad blocker is protecting you—privacy is now the number one reason why people install ad blockers. You can check your browser setup at EFF’s Cover Your Tracks site.
Work in progress
This is a work in progress, will update as needed. If you’re looking for info on the Mr Robot TV show plugin I think this is totally gone by now and you should not have to do anything.
PET projects or real privacy? Some background info on privacy-enhancing ad personalization, which, to me, looks like an interesting technical dead end.
explainers/ppa-experiment at main · mozilla/explainers This is Mozilla’s POV about why they’re doing this. (They’re mixing up privacy protection and protection from individual addressability, which is a trend now, and an annoying one. As a privacy nerd, now I know how music nerds feel when people go on and on about Nickelback.)
Bonus links
The Golden Calf Of Addressability: Reevaluating The Foundations Of Digital AdvertisingAdvancements in AI have given us the tools to gather probabilistic insights by examining broader audience trends and modeling future behavior, rather than chasing the deterministic cookie trail to nowhere. (You still have to be careful—even if tracking is not deterministic it can still faciliate discrimination, matching scammers to victims, and other harms.)
As we wrap up the second quarter of 2024, it’s time to reflect on our accomplishments and the ongoing efforts within our community. It’s been a busy Q2. And many of you have made some of that work possible by really jumping in to help. It’s time to celebrate and look back on our accomplishments before we gather more strength again to continue our fights for the healthy internet.
Thanks to those who take care of the locale-specific forums in SUMO. Next for taking care of Italian, poljos and Ansam for taking care of cs, Gerardo for taking care of Spanish, Balázs Meskó for taking care of Hungarian, Selim for taking care of Turkish, and Wim for taking care of the newly opened NL forum. You’ve been wonderful, and your contribution is highly appreciated.
If you know anyone that we should feature here, please contact Kiki and we’ll make sure to add them in our next edition.
Wiki page for Firefox release just got a new face since version 126. Check it out and let Kiki know if you have feedback on how to improve it!
There’s a lot going on with content in SUMO. Make sure you’re updated with what we’re up to.
There was an incident which caused X/Twitter to break on Firefox with Enhanced Tracking Protection set to strict mode (recap of the incident is in Firefox 126 wikipage), but we quickly react by posting a status update of the incident.
We released the first edition of the Contributor spotlight content last month featuring Wensheng Xie. Stay tuned for the next edition!
Platform updates
We released a bunch of stuff with Kitsune 1.0.3 on May 15, 2024. There’s a recap of this release here, which includes group messaging capability, in-product indicator on a KB, and Google Analytics migration. You can also check out the full release note on GitHub.
On May 30, 2024, we released an exciting change in Kitsune, which is KB metadata information. We also released an improvement to the article metadata with the release of Kitsune 1.0.6 on June 5, 2024. You may see this contributor thread to read the recap of this release.
Stay updated
Join our discussions in the contributor forum to see what’s happening in the latest release on Desktop and mobile.
Watch the monthly community call if you haven’t. Learn more about what’s new in April, May, and June! Reminder:Don’t hesitate to join the call in person if you can. We try our best to provide a safe space for everyone to contribute. You’re more than welcome to lurk in the call if you don’t feel comfortable turning on your video or speaking up. If you feel shy to ask questions during the meeting, feel free to add your questions on the contributor forum in advance, or put them in our Matrix channel, so we can answer them during the meeting.
If you’re an NDA’ed contributor, you can watch the recording of our bi-weekly Release Meeting from AirMozilla to catch up with the latest product releases. You can also subscribe to the AirMozilla folder by clicking on the Subscribe button at the top right corner of the page to get notifications each time we add a new recording.
Consider subscribing to Firefox Daily Digest to get daily updates (Mon-Fri) about Firefox from across the internet.
Check out SUMO Engineering Board to see what the platform team is cooking in the engine room. Also, check out this page to see our latest release notes
Community stats
I still haven’t got my hands on GA4 data, so stay tuned for KB and localization stats!
KB
KB pageviews (*)
* KB pageviews number is a total of KB pageviews for /en-US/ only
* Locale pageviews is an overall pageview from the given locale (KB and other pages)
** Localization progress is the percentage of localized article from all KB articles per locale
Top 5 localization contributors in the last 90 days:
With the release of Firefox 128 comes additional Manifest V3 improvements as the engineering team continues to make cross-browser compatibility work a key focus, especially related to content scripts and the scripting API.
In Firefox 128, support is now available for the MAIN execution world for content scripts declared in the manifest.json file and scripting.executeScript, which allows extensions to inject a script in the web page execution environment. However, unlike using window.eval from an isolated content script, the script injected into the MAIN world is not blocked by a strict webpage CSP. Please be aware that content scripts executed in the MAIN world do not have access to any WebExtension APIs.
Developers should also take note that the non-standard Web API events overflow and underflow have been deprecated. Use of these events should be removed from extension documents before the release of Firefox 131. Extension developers can set the “layout.overflow-underflow.content.enabled_in_addons” about:config preference to falsein Firefox Nightly to determine whether their extensions will break in the future.
And to make migration less burdensome for developers, we intentionally back ported MV3 APIs to MV2. This means extensions developers will be able to more easily transition their extensions to MV3 gradually. For example, in Firefox 128, despite the fact that the MAIN world and the match_origin_as_fallback features are only supported for MV3 in Chrome, we will still support them on Firefox for MV2.
Lastly, with the launch of the Android permissions UI in Firefox 128, we are able to facilitate the control of the optional permissions and supporting host permissions that landed last month in Firefox 127. This means we are now able to fully support MV3 on Firefox for Android.
For a list of all changes relevant for add-on developers available in Firefox 128, please see our release notes. For more information on adopting MV3 in general, check out our migration guide. If you have questions or comments on our Manifest V3 updates we would love to hear from you in the comments section below or if you prefer, drop us an email.
Hello, SUMO Community! As we kick off the second half of 2024, we’re thrilled to share the progress the CX Content Team has made this year in our Cognitive Load Reduction Initiatives. Our goal? To make SUMO articles more accessible, user-friendly, and visually appealing. Here’s a look at what we’ve accomplished so far and a sneak peek at what’s coming next.
Phase 1: Optimizing image use
Simplified user interface (SUI) screenshots: We have updated existing screenshots with simplified versions that focus on crucial visual elements. This reduces complexity and makes it easier for users to understand.
Inline screenshots and icons: We have added inline screenshots and icons to enhance our articles by visually demonstrating interface elements, making instructions clearer, and improving user comprehension.
Sequential step markers: We have opened the possibility of using numbered annotations on product screenshots to consolidate various actions into a single image. This reduces the number of screenshots needed and makes articles clearer and more concise.
Phase 2: Rich media and content reorganization
Integrating animated GIFs: We plan to incorporate GIFs into key articles where they can be most effective. These GIFs will visually illustrate processes that would otherwise require multiple static images, enhancing user comprehension and engagement.
Merging and reorganizing content: We plan to redesign key articles to support multiple platforms, consolidating information into one comprehensive article. Platform-specific details will be organized using tabs or collapsible sections. We will also reorganize and merge similar articles to enhance clarity and ease of use.
We look forward to continuing this journey in the second half of 2024, making SUMO an even more valuable resource for our users. Thank you to all our contributors for your hard work and dedication to these initiatives. Together, we’re making a huge impact on the Firefox support experience.
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at @ThisWeekInRust on X(formerly Twitter) or @ThisWeekinRust on mastodon.social, or send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization. The following
RFCs would benefit from user testing before moving forward:
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing
label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature
need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on X (Formerly twitter) or Mastodon!
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on X (Formerly twitter) or Mastodon!
More regressions than improvements this week, caused by a combination of fixes,
refactorings, third-party dependency updates and in general the compiler doing
slightly more work.
Changes to Rust follow the Rust RFC (request for comments) process. These
are the RFCs that were approved for implementation this week:
* No RFCs were approved this week.
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
Something I recently ran into: How do you build a site locally and host the resulting built version of the site on GitHub Pages? Here’s one way to do it. First, have a make all target that builds the public files from the source pages (for example, pass CommonMark filenames to Pandoc to get HTML.) Then make deploy does several things:
Make a fresh build directory and copy the source files, the Makefile, and the .git directory into it.
Run make gh-pages inside the build directory. That target depends on the all target, so this builds the site inside the directory.
Next, make gh-pages inside the build directory commits the public files on the gh-pages branch, then force pushes to GitHub.
Back in make deploy, delete the build directory. That includes the .git directory inside, so no history of built files gets preserved.
# We make this site with "make" locally and deploy generated pages to GitHub in # a branch. First, delete the build directory and the gh-pages branch. Then # copy the site files into the build directory and make the gh-pages target deploy : all (git branch -D gh-pages || true) &> /dev/null rm -rf build && mkdir -p build cp -a Makefile .git $(SOURCES) build make -C build gh-pages rm -rf build # This target only runs inside the build directory and does a commit and push # on the gh-pages branch. If you look at this project on GitHub you should see # the original .md files on the main branch and the generated HTML files on the # gh-pages branch. gh-pages : all basename `pwd` | grep -q build || exit 1 rm -f .git/hooks/pre-push git checkout -b gh-pages git rm -f $(SOURCES) git add -f $(PUBLICFILES) git commit -m "this is a temporary branch, do not commit here." git push -f origin gh-pages:gh-pages
This is from a Makefile for a very basic .org site. The -C option to make is to change to the given directory before reading the Makefile. (That site has versioning for the source files on GitHub too, but it doesn’t have to be.)
planning for SCALE 2025 is about some ideas for a conference talk on making a site using a Makefile and a bunch of various stuff instead of a static site generator.
Bonus links
hangout_services/thunk.jsIt turns out Google Chrome (via Chromium) includes a default extension which makes extra services available to code running on the *.google.com domains
A high-level view of all of this feed reader stuff (good info about a useful QA service for making your RSS tool better behaved. The script that builds the links for this bonus links section just got fixed up some.)
Download the Atkinson Hyperlegible Font | Braille InstituteAtkinson Hyperlegible font is named after Braille Institute founder, J. Robert Atkinson. What makes it different from traditional typography design is that it focuses on letterform distinction to increase character recognition, ultimately improving readability. (If I use a hyperlegible typeface, I can make my prose more confusing, right?)
The Itanic Saga (personally I had no idea that a story about Intel Itanium would start in 1923)
Amazon Is Investigating Perplexity Over Claims of Scraping AbuseAmazon’s cloud division has launched an investigation into Perplexity AI. At issue is whether the AI search startup is violating Amazon Web Services rules by scraping websites that attempted to prevent it from doing so, WIRED has learned.
There may be differing opinions about the health benefits of vitamin supplements, but there’s no debate among medical experts that eating sawdust is bad for you. Yet sawdust is exactly what Saoud Khalifah found in vitamin supplements he ordered online from a globally popular shopping site. How could this have happened, he wondered? Khalifah started digging and discovered an overwhelming number of unreliable product reviews on many of the world’s biggest eCommerce sites.
That revelation back in 2016 inspired Khalifah to assemble a team and develop Fakespot — an extension that utilizes generative artificial intelligence (GenAI) to analyze the reliability of product reviews. Fakespot can analyze reviews on Amazon, Best Buy, Walmart, Sephora, eBay and Shopify-powered sites, with coverage for more shopping platforms in the pipeline. Sensing an opportunity for great collaboration, the Fakespot team joined Mozilla last year to further advance its mission to arm users with information about product reviews and pursue other GenAI projects.
Rob Gross, Fakespot Senior Manager, explains that part of what makes Fakespot so effective are the seven years experience their team has accrued deploying “state-of-the-art AI and constantly improving our platform to find emerging problematic patterns and stop them before they spread.”
<figcaption class="wp-element-caption">Fakespot Review Grades indicate how reliable the reviews are, not the product.</figcaption>
When unreliable product reviews started to emerge en masse online about a decade ago, they were the written work of actual people employed at “fake review farms” and still are today. But now the “fake review farms” and others have the power of GenAI to help them mass produce reviews, which compounds the complexity and scale of this phenomenon. However the root problem remains the same. “The issue with GenAI-derived reviews have the same issues as human-generated ones,” explains Gross. “They have patterns that Fakespot can detect and we are constantly working to update our engines to detect new and emerging forms of potential consumer deception.
Give yourself a fighting chance against a rising tide of unreliable reviews and try Fakespot. It’s intuitive, easy to use, and improves all the time.
Recently, we shared our 2024 priorities for Firefox on Mozilla Connect, our dedicated space for engaging our community. It’s where we exchange ideas, gather feedback and spark discussions to shape future product releases. Eager to reach more of the community, the Firefox team hosted a two hour Ask Me Anything on Reddit.
The AMA had a great turnout of Firefox supporters keen to discuss topics like videos for new releases, performance enhancements and feature suggestions like automatic tab discarding. Here are some highlights:
User interface and productivity enhancements
Our community is enthusiastic about several upcoming features designed to improve productivity and customization. Our Tab Groups team is hard at work creating a better experience for people who need to manage many tabs. Additionally, we are also exploring modernizing a place where you’ll have access to better tools for viewing your browser history and bookmarks and providing a better interface for organizing tabs and windows across devices.
Performance and compatibility improvements
Speed and efficiency remain top priorities. For Android users, enhancements focus on improving performance, battery life and adding new features. Site isolation (Fission) is also in progress for Android to boost security.
Media and accessibility features
To enhance media playback, we’re exploring a contributor patch — a piece of code submitted by an external developer — for Picture-in-Picture (PiP) autoplay, a feature that allows video content to play in a small, resizable window that stays on top of other windows, which will automatically open a Picture-in-Picture window when navigating away from a media tab. On the accessibility front, we’re expanding our translation feature to include more languages, with new packages and support for Chinese, Japanese, and Korean in our pipeline.
We want to hear from you
This was our first AMA in a while, and we’re interested in what you think. Did you find the AMA helpful? Was there anything we missed? How often should we host these sessions? Let us know by filling out this survey. If you missed the AMA, you can still check it out here.
These insights and feedback from our community are instrumental in guiding our efforts to make Firefox the best browser experience possible. Stay tuned for more on our next AMA as well as updated. Join us on Mozilla Connect to keep the conversation going!
WebDriver is a remote control interface that enables introspection and control of user agents.As such itcanhelp developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we’ve done as part of the Firefox 128 release cycle.
Contributions
Firefox – including our WebDriver implementation – is developed as an open source project, and everyone is welcome to contribute. There were no external contributions during the Firefox 128 release cycle, but I’m sure we will have more in the next cycles. If you ever wanted to contribute to an open source project used by millions of users, or are interested in some experience in software development, we have many beginner-friendly available over at https://codetribute.mozilla.org/.
General
Support for the extended “unhandledPromptBehavior” capability
We now support the extended “unhandledPromptBehavior” capability which can either be a string (for WebDriver Classic) or a JSON object (for WebDriver BiDi). The JSON object can be used to configure a different behavior depending on the prompt type, which is useful for instance to handle “beforeunload” prompts.
Support for several arguments for the `network.continueRequest` command
In previous releases, we introduced commands to intercept and resume requests, such as network.addIntercept and network.continueRequest. With Firefox 128 we now support most of the optional parameters for network.continueRequest, which means you can now modify requests blocked in the beforeRequestSent phase. The available parameters are body, cookies, headers and method. The modification will happen before the request is sent to the server, so this can be used for instance to add some test-specific headers to certain requests.
Take a look at the specification to learn more about the types for the new parameters. There is still one parameter to implement for network.continueRequest which is url and will allow to redirect a request to another URL, hopefully coming soon.
Also note that before Firefox 128, the requests blocked in the beforeRequestSent phase could still intermittently be blocked a bit late and reach the server. This should now be fixed, and requests blocked in this phase should not reach the network until resumed.
Support for the `userContext` argument in the `permissions.setPermission` command
We now support the userContext argument for permissions.setPermission, which allows to isolate a specific permission update to a single user context (Firefox Container). userContext is expected to be a string corresponding to the id of a user context.
This is the second in a series of blog posts describing new web platform features Igalia has implemented in Gecko, as part of an effort to improve browser interoperability.
I’ll talk about the task of implementing ‘content-visibility’, to which several Igalians have contributed since early 2022, and I’ll focus on two main roadblocks I had to overcome.
The ‘content-visibility’ property
In the past, Igalia worked on CSS containment, a feature allowing authors to isolate a subtree from the rest of the document to improve rendering performance.
This is done using the ‘contain’ property, which accepts four kinds of containment: size, layout, style and paint.
‘content-visibility’ is a new property allowing authors to “hide” some content from the page, and save the browser unnecessary work by applying containment.
The most interesting one is probably content-visibility: auto, which hides content that is not relevant to the user.
This is essentially native “virtual scrolling”, allowing you to build virtualized or “recycled” lists without breaking accessibility and find-in-page.
To explain this, consider the typical example of a page with a series of posts, as shown below.
By default, each post would have the four types of containment applied, plus it won’t be painted, won’t respond to hit-testing, and would use the dimensions specified in the ‘contain-intrinsic-size’ property.
It’s only once a post becomes relevant to the user (e.g. when scrolled close enough to the viewport, or when focus is moved into the post) that the actual effort to properly render the content, and calculate its actual size, is performed:
If a post later loses its relevance (e.g. when scrolled away, or when focus is lost) then it would use the dimensions specified by ‘contain-intrinsic-size’ again, discarding the content size that was obtained after layout.
One can also avoid that and use the last remembered size instead:
Finally, there is also a content-visibility: hidden value, which is the same as content-visibility: auto but never reveals the content, enhancing other methods to hide content such as display: none or visibility: hidden.
As is often the case, the feature looks straightforward to implement, but issues appear when you get into the details.
In bug 1807253, my colleague Oriol Brufau raised an interoperability bug with a very simple test case, reproduced below for convenience.
Chromium would report 0 and 42, whereas Firefox would sometimes report 0 twice, meaning that the post did not become relevant after a rendering update:
It turned out that an early version of the specification relied too heavily on an modified version of IntersectionObserver to synchronously detect when an element is close to the viewport, as this was how it was implemented in Chromium.
However, the initial implementation in Firefox relied on a standard IntersectionObserver (with asynchronous notifications of observers) and so failed to produce the behavior described in the specification.
This issue was showing up in several WPT failures.
To solve that problem, the moment when we determine an element’s proximity to the viewport was moved into the HTML5 specification, at the step when the rendering is updated, more precisely when the ResizeObserver notifications are broadcast.
My colleague Alexander Surkov had started rewriting Firefox’s implementation to align with this new behavior in early 2023, and I took over his work in November.
Since this touches the “update the rendering” step which is executed on every page, it was quite likely to break things…
and indeed many regressions were caused by my patch, for example:
One regression was about white flickering of pages on every reload/navigation.
One more regression was about content-visibility: auto nodes not being rendered at all.
Some test cases were also found where the “update the rendering step” would repeat indefinitely, causing performance regressions.
Last but not least, crashes were reported.
Some of these issues were due to the fact that support for the last remembered size in Firefox relied on an internal ResizeObserver.
However, the CSS Box Sizing spec only says that the last remembered size is updated when ResizeObserver events are delivered, not that such an internal ResizeObserver object is actually needed.
I removed this internal observer and ensured the last remembered size is computed directly in the “update the rendering” phase, making the whole thing simpler and more robust.
Dynamic changes to CSS ‘contain’ and ‘content-visibility’
Before sending the intent-to-ship, we reviewed remaining issues and stumbled on bug 1765615, which had been opened during the initial 2022 work.
Mozilla indicated this performance bug was important enough to consider an optimization, so I started tackling the issue.
When we dynamically modify the ‘contain’ or ‘content-visibility’ properties, or when the relevance of a content-visibility: auto element changes, browsers must make sure that the rendering is properly updated.
It turned out that there were almost no tests for that, and unsurprisingly, Chromium and WebKit had various invalidation bugs.
Firefox was always forcing a rebuild of the tree used for rendering, which avoided such bugs but is not optimal.
I wrote a couple of web platform tests for ‘contain’ and ‘content-visibility’2, and made sure that Firefox does the minimal invalidation effort needed, being careful not to cause any regressions.
As a result, except for style containment changes, we’re now able to avoid the cost a rebuild of the tree used for rendering!
Conclusion
Almost two years after the initial work on ‘content-visibility’, I was able to send the intent-to-ship, and the feature finally became available in Firefox 125.
Finishing the implementation work on this feature was challenging, but quite interesting to me.
I believe ‘content-visibility’ is a good example of why implementing a feature in different browsers is important to ensure that both the specification and tests are good enough.
The lack of details in the spec regarding when we determine viewport proximity, and the absence for WPT tests for invalidation, definitely made the Firefox work take longer than expected.
But finishing that implementation work was also useful for improving the spec, tests, and other implementations 3.
I’ll conclude this series of blog posts with fetch priority, which also has its own interesting story…
In both cases, “implies” means the used value of ‘contain’ is modified accordingly. ↩
One of the thing I had to handle with care was the update of the accessibility tree, since content that is not relevant to the user must not be exposed. Unfortunately it’s not possible to write WPT tests for accessibility yet so for now I had to write internal Firefox-specific non-regression tests. ↩
The Pruneyard is “an iconic destination and experience designed to make the everyday extraordinary.” It’s also, according to the US Supreme Court, a business establishment that is open to the public to come and go as they please. The views expressed by members of the public in passing out pamphlets or seeking signatures for a petition thus will not likely be identified with those of the owner.Pruneyard Shopping Center v. Robins, in which a student group ended up being allowed to distribute their leaflets in some areas of the mall, is a Supreme Court case that keeps coming up in discussions about what kinds of regulation are appropriate for the “Big Tech” companies.
Is a Big Tech platform more like a mall, or more like a newspaper? Making the best case for the newspaper option, Mike Masnick at Techdirt asserts that the Big Tech companies have broad First Amendment rights that extend to cover many design and business model decisions. This point of view is pretty far outside the mainstream—if the First Amendment really extended that far into protecting business models, then the Fair Credit Reporting Act would be unconstitutional, and lenders and fintech companies would have the right to spread any kind of negative information about anyone (up to the generous limits of libel law). On the extreme end of the other side, of course, we hear from far right and far left politicians who want to shut down even classic First Amendment media such as newspapers and newspaper-like web sites.
In the middle, though, the tricky part is to figure out is which online platforms are more like a mall, where permitting the people who use it to exercise their own personal rights is not an unconstitutional infringement of the platform owner’s rights, as covered in the Pruneyard decision…
Here the requirement that appellants permit appellees to exercise state-protected rights of free expression and petition on shopping center property clearly does not amount to an unconstitutional infringement of appellants’ property rights under the Taking Clause. There is nothing to suggest that preventing appellants from prohibiting this sort of activity will unreasonably impair the value or use of their property as a shopping center. The PruneYard is a large commercial complex that covers several city blocks, contains numerous separate business establishments, and is open to the public at large. The decision of the California Supreme Court makes it clear that the PruneYard may restrict expressive activity by adopting time, place, and manner regulations that will minimize any interference with its commercial functions.
…and when is a site more like a newspaper? It makes sense in principle to treat a privately owned platform as a mall in situations where it works like a mall, and people want or need to do the kinds of things they do in a mall, but how do you draw the line?
A state law writing assigment, direct from the Supreme Court
The mall or newspaper question has been in the news lately because of the Supreme Court’s decision in Moody v. Netchoice, which is largely a writing assignment for state legislators. (full decision PDF) The task that the Court has set for legislators is to come up with laws that can somehow take a whack at Big Tech’s multifarious villainy—mental health harms, child exploitation, national security threats, fraud, and all the rest—and to draft those laws in a way that clearly treats an online version of the Pruneyard Shopping Center, a place where the rights of the users outweigh the rights of the platform owner, differently from a site that works like a newspaper.
But instead of getting too far into the weeds on the mall or newspaper question, what about other options? Big Tech has qualities more similar to other businesses that are covered by other kinds of laws.
Regulation is justified by the scale and impact of the gambling and credit reporting industries. Even though a hypothetical Techdirt for slot machine designers or Techdirt for credit bureaus could stretch out a First Amendment argument to cover those two cases, in reality they’re regulated. State legislatures need to identify and regulate a Big Tech business practice in a way that will also hold up in court. Fortunately, there is one that’s far enough away from speech to clearly avoid First Amendment issues: surveillance, or cross-context tracking.
Cross-context tracking includes using pixels, SDKs, or “conversion tracking” APIs as a way for any business to send information about any person to the Big Tech company. (More about conversion tracking, from Consumer Reports). Cross-context tracking also takes place within Big Tech companies, when, for example, the same company owns both a video sharing platform and a web browser, and uses data collected by the browser to personalize ads on the video sharing platform.
Cross-context tracking affects hundreds of billions of dollars in advertising and content, as well as people’s opportunities in housing, employment, and other areas. So we should be able to avoid asking mall or newspaper? as much as possible and work toward building a consensus: a company that collects or accepts tracking data about people’s actions in one context in order to inform decisions that affect them in another context is holding itself out as a networked meeting place for other people’s transactions, and in need of licensing. The tracking is in no way expressive by the Big Tech company. It’s an inbound flow of data, not outbound, and the company has no knowledge or control of what the tracking events will be.
Just as states regulate and inspect any business with a gambling or liquor license, a state licensing agency for cross-context tracking would be able to handle citizen complaints about Big Tech platforms. Even if you believe that cross-context behavioral advertising is a net economic win, the people subject to it face more than enough risks to justify a state-level licensing system. For the state whose legislature can get cross-context tracking licenses into law, it’s a win-win:
Costs to the state government could be minimized. A company would be required to disclose its own cross-context tracking in its license application, state regulators wouldn’t have to go try to figure it out. And objections to licenses could be raised through public comment forms and meetings.
A site could cleanly avoid regulation by staying out of the cross-context tracking business and not applying for a license.
Can promote fair competition because the tracking that requires a license would be across contexts, not owners. A Big Tech company that gained a new context, such as a site or app, by acquisition would need to update its license.
A licensing bill covering cross-context tracking could get support from a variety of interests, including people who already believe in the harms of cross-context tracking and want fewer, better-run companies doing it, and people who are neutral or even slightly positive about the tracking part but want to use future public meetings about tracking license renewals as a way to get Big Tech to improve their behavior toward their state’s citizens and businesses. Small business owners could show up at a license renewal meeting and have real impact, not just get rounded up to advocate for Big Tech and against privacy one day a year while their support tickets go to oblivion the rest of the time. And maybe, as Big Tech platforms increasingly resemble the spawn of the arbitrary top-down decision-making of a credit report and the psychological manipulation of a slot machine, the answer to the mall or newspaper question is neither.
The NetChoice Decision Shows the First Amendment Is Out of Control by Tim WuJudges have transmuted a constitutional provision meant to protect unpopular opinion into an all-purpose tool of legislative nullification that now mostly protects corporate interests. Nearly any law that has to do with the movement of information can be attacked in the name of the First Amendment.
Supreme Court protects the future of content moderationThe decision elaborates that the compilation and curation of “others’ speech into an expressive product of its own” is entitled to First Amendment protection and that the government cannot get its way just by asserting an interest in better balancing the marketplace of ideas.
BRIEF OF LAW AND HISTORY SCHOLARS AS AMICI CURIAE IN SUPPORT OF RESPONDENTS IN NO. 22-555Facebook, Twitter Instagram, and TikTok are not newspapers. They are not space-limited publications dependent on editorial discretion in choosing what topics or issues to highlight. Rather, they are platforms for widespread public expression and discourse. They are their own beast, but they are far closer to a public shopping center or a railroad than to the Manchester Union The proposed NetChoice trigger of “editorial judgment” is misplaced.
Meta’s ‘pay or consent’ model fails EU competition rules, Commission finds (From here in the USA this looks like a brilliant piece of legal work: allowing European publishers to continue using “pay or consent” while putting this model off-limits to Meta. Remember, think about European tech policy in context. Big Tech isn’t in trouble in Europe because companies are failing to comply with whatever the EU laws are today. They’re in trouble because they’re more of a part of the problem than a part of the solution on the big issues.)
Bonus links
My reply to the people who want to designate my neighborhood a “historic district”Having a house in a city with a lot of homeless people, and one where essential workers can’t afford to live, will also depress property values. It’s not as obvious. It’s not as acute. But it’s a much bigger problem and one that’s harder to deal with.
Mastodon is actively courting journalists (The underrated asset of Twitter was that they owned the “byline namespace” for mass and trade media. The pro-Putin direction over there is creating an opportunity for a new journalist directory, and I hope not a single point of failure this time.)
For those who don't know, I have provided countless
contributions to the Mozilla project. This is to an extent, that I
have been added to our credits page (type about:credits into Firefox!)
more than ten years ago. In February 2014, Mozilla constructed a real monument
as praise for the …
Hello and welcome to another issue of This Week in Rust!
Rust is a programming language empowering everyone to build reliable and efficient software.
This is a weekly summary of its progress and community.
Want something mentioned? Tag us at @ThisWeekInRust on X(formerly Twitter) or @ThisWeekinRust on mastodon.social, or send us a pull request.
Want to get involved? We love contributions.
An important step for RFC implementation is for people to experiment with the
implementation and give feedback, especially before stabilization. The following
RFCs would benefit from user testing before moving forward:
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing
label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature
need testing.
Always wanted to contribute to open-source projects but did not know where to start?
Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
If you are a Rust project owner and are looking for contributors, please submit tasks here or through a PR to TWiR or by reaching out on X (Formerly twitter) or Mastodon!
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
No Calls for papers or presentations were submitted this week.
If you are an event organizer hoping to expand the reach of your event, please submit a link to the website through a PR to TWiR or by reaching out on X (Formerly twitter) or Mastodon!
We saw a large set of primary benchmarks regress, mostly due to PR #120924 (lint_reasons and #[expect]) and PR #120639 (new effects
desugaring). Separate from those, there are a couple rollup PRs (#127076, #127096) with some regressions that were limited to relatively few benchmarks; pnkfelix was unable to isolate a injecting PR that can be identified as a root cause (outside assistance welcome!).
If you are running a Rust event please add it to the calendar to get
it mentioned here. Please remember to add a link to the event too.
Email the Rust Community Team for access.
<figcaption class="wp-element-caption">Participants of the Dataset Convening in Amsterdam.</figcaption>
Mozilla and EleutherAI brought together experts to discuss a critical question: How do we create openly licensed and open-access LLM training datasets and how do we tackle the challenges faced by their builders?
On June 11, on the eve of MozFest House in Amsterdam, Mozilla and EleutherAI convened an exclusive group of 30 leading scholars and practitioners from prominent open-source AI startups, nonprofit AI labs and civil society organizations to discuss emerging practices for a new focus within the open LLM community: creating open-access and openly licensed LLM training datasets.
This work is timely. Although sharing training datasets was once common practice among many AI actors, increased competitive pressures and legal risks have made it almost unheard of nowadays for pre-training datasets to be shared or even described by their developers. However, just as open-source software has made the internet safer and more robust, we at Mozilla and EleutherAI believe open-access data is a public good that can empower developers worldwide to build upon each other’s work. It fosters competition, innovation and transparency, providing clarity around legal standing and an ability to stand up to scrutiny.
Leading AI companies want us to believe that training performant LLMs without copyrighted material is impossible. We refuse to believe this. An emerging ecosystem of open LLM developers have created LLM training datasets —such as Common Corpus, YouTube-Commons, Fine Web, Dolma, Aya, Red Pajama and many more—that could provide blueprints for more transparent and responsible AI progress. We were excited to invite many of them to join us in Amsterdam for a series of discussions about the challenges and opportunities of building an alternative to the current status quo that is open, legally compliant and just. During the event, we drew on the learnings from assembling “Common Pile” (the soon-to-be-released dataset by EleutherAI composed only of openly licensed and public domain data) which incorporates many learnings from its hugely successful predecessor, “The Pile.” At the event, EleutherAI released a technical briefing and an invitation to public consultation on Common Pile.
<figcaption class="wp-element-caption">Participants engaged in a discussion at “The Dataset Convening,” hosted by Mozilla and EleutherAI on June 11, 2024 to explore creating open-access and openly licensed LLM training datasets.</figcaption>
Our goal with the convening was to bring in the experiences of open dataset builders to develop normative and technical recommendations and best practices around openly licensed and open-access datasets. Below are some highlights of our discussion:
Openness alone does not guarantee legal compliance or ethical outcomes, we asked which decision points can contribute to datasets being more just and sustainable in terms of public good and data rights.
We discussed what “good” looks like, what we want to avoid, what is realistic and what is already being implemented in the realm of sourcing, curating, governing and releasing open training datasets.
Issues such as the cumbersome nature of sourcing public domain and openly licensed data (e.g. extracting text from PDFs), manual verification of metadata, legal status of data across jurisdictions, retractability of consent, preference signaling, reproducibility and data curation and filtering were recurring themes in almost every discussion.
To enable more builders to develop open datasets and unblock the ecosystem, we need financial sustainability and smart infrastructural investments that can unblock the ecosystem.
The challenges faced by open datasets today bear a resemblance to those encountered in the early days of open source software (data quality, standardization and sustainability). Back then, it was the common artifacts that united the community and provided some shared understanding and language. We saw the Dataset Convening as an opportunity to start exactly there and create shared reference points that, even if not perfect, will guide us in a common direction.
The final insight round underscored that we have much to learn from each other: we are still in the early days of solving this immense challenge, and this nascent community needs to collaborate and think in radical and bold ways.
<figcaption class="wp-element-caption">Participants at the Mozilla and EleutherAI event collaborating on best practices for creating open-access and openly licensed LLM training datasets.
</figcaption>
We are immensely grateful to the participants in the Dataset Convening (including some remote contributors):
Stefan Baack — Researcher and Data Analyst, Insights, Mozilla
Mitchell Baker — Chairwoman, Mozilla Foundation
Ayah Bdeir — Senior Advisor, Mozilla
Julie Belião — Senior Director of Product Innovation, Mozilla.ai
Greg Leppert — Director of Product and Research, the Library Innovation Lab, Harvard
EM Lewis-Jong — Director, Common Voice, Mozilla
Shayne Longpre — Project Lead, Data Provenance Initiative
Angela Lungati — Executive Director, Ushahidi
Sebastian Majstorovic — Open Data Specialist, EleutherAI
Cullen Miller — Vice President of Policy, Spawning
Victor Miller — Senior Product Manager, LLM360
Kasia Odrozek — Director, Insights, Mozilla
Guilherme Penedo — Machine Learning Research Engineer, HuggingFace
Neha Ravella — Research Project Manager, Insights Mozilla
Michael Running Wolf — Co-Founder and Lead Architect, First Languages AI Reality, Mila
Max Ryabinin — Distinguished Research Scientist, Together AI
Kat Siminyu — Researcher, The Distributed AI Research Institute
Aviya Skowron — Head of Policy and Ethics, EleutherAI
Andrew Strait — Associate Director, Ada Lovelace Institute
Mark Surman — President, Mozilla Foundation
Anna Tumadóttir — CEO, Creative Commons
Marteen Van Segbroeck — Head of Applied Science, Gretel
Leandro von Werra — Chief Loss Officer, HuggingFace
Maurice Weber — AI Researcher, Together AI
Lee White — Senior Full Stack Developer, Ushahidi
Thomas Wolf — Chief Science Officer and Co-Founder, HuggingFace
In the coming weeks, we will be working with the participants to develop common artifacts that will be released to the community, along with an accompanying paper. These resources will help researchers and practitioners navigate the definitional and executional complexities of advancing open-access and openly licensed datasets and strengthen the sense of community.
The event was part of the Mozilla Convening Series, where we bring together leading innovators in open source AI to tackle thorny issues and help move the community and movement forward. Our first convening was the Columbia Convening where we invited 40 leading scholars and practitioners to develop a framework for defining what openness means in AI. We are committed to continuing the efforts to support communities invested in openness around AI and look forward to helping grow and strengthen this movement.
I can’t believe it’s already the end of June. ESR is only a few days away, and things are moving faster than ever.
Preparing For ESR
This is going to be a slightly shorter update since the majority of our effort revolved around testing and polishing 128 beta, which will turn into ESR on July 10th.
We fixed a total of 127 bugs and a few more things are getting tackled.
Account Colors In Compose
You can now see the custom colors you chose for your accounts in the compose windows. This was an 18 year-old request that we were finally able to fulfill thanks to the incredible work that many core developers put in place during the past 2 years.
By implementing a much more reliable and modular code base, with a clearer separation between data and UI, we’re finally able to ship these long standing requested features much faster. There’s still a lot to do, but working on our code base is getting better and better.
Mozilla Sync
The client code is finished, everything is in place and we’re testing syncing server data against a temporary staging server.
We’re still working on spawning our own production server, which turned out more challenging than expected. This means that potentially we won’t enable Sync by default for the first ESR release and instead keep it hidden temporarily, with the objective of enabling it in a future point release (maybe 128.1 or 128.2) depending on when the production server will be ready.
We will keep you posted every step of the way.
Thunderbird Beta 128
If you haven’t downloaded 128 beta, please do so and help us test and report bugs if you spot them. You can download Thunderbird 128 Beta here, and if you find any issue, please open a bug report against this Meta Bug we’re using to track any potential regression specific to 128. Thank you!
See ya next month.
Alessandro Castellani(he, him) Director, Desktop and Mobile Apps
If you’re interested in joining the technical discussion around Thunderbird development, consider joining one or several of our mailing list groups here.
At Mozilla, we know we can’t create a better future alone, that is why each year we will be highlighting the work of 25 digital leaders using technology to amplify voices, effect change, and build new technologies globally through our Rise 25 Awards. These storytellers, innovators, activists, advocates. builders and artists are helping make the internet more diverse, ethical, responsible and inclusive.
This week, we chatted with Kay Lopez, a content creator dedicated to empowering Latinas by celebrating their heritage and accomplishments. We talk with Kay about the launch of her platform, Latinas Poderosas, what inspires her work as a creator, navigating social media exhaustion and more.
You mentioned in your video that when going to school, you felt you didn’t learn enough about your own culture. What things did you learn along the way that surprised you?
So growing up in Texas, I feel like a lot of the education was very much focused on obviously American culture, right? The conversation was about pilgrims, Native Americans, colonies, the creation of colonies. The colonization of the United States was very much painted as it was a fun time, a great time, a perfect America, and I fed into it. I believed that was accurate history that I was being taught in school. But when I started to really dig in and watch documentaries on my own, I discovered the number of individuals that helped build America and their own stories. Whether they were inventors, or whether they had impacted the art scene, what we eat today, especially with the dishes — the grains, everything that we consume where it comes from — I just started to feel like that was in the shadows and when I started to learn more on my own about people that came to America and built America, I started to get even more inspired to want to learn more, and really started to share that history on my platform. So the creation of Latinos Poderosas was a lot for myself initially so I could learn about what it meant to be a first-generation American, and learn more about my culture and celebrate what my culture has brought to the U.S. from the perspective of a first-generation, and then along the way, I just felt like every time that I shared another piece of information and history, people started to follow or engage, or share, or get really, really excited. There’s something about learning a tad bit of history that you never knew. You get really prideful of your culture, and you start to share it, and you feel like you’re more connected to it. And you’re prideful. That was kind of my journey of self-discovery and learning, going beyond what I was taught in school and making the time and energy to go out and watch documentaries, go out to libraries, go to check-out books about everything about how the U.S. became to be what it is today.
Where do you hope to see Latinas Poderosas grow in the next few years?
Where I see it going, just going off of what I see on social media and the trends that I’m seeing, I see Latinas Poderosas becoming this like hub for hosting and holding a lot of like history and a platform where people can come and find things like businesses that are Latina-owned, recent moments in history that are being accomplished. I want it to become a hub. And what I’m seeing on social media is this younger generation is so proud to showcase their culture online, and that’s very different from the way that I grew up back in Texas. It was very much like you put your culture behind you, and you just kind of present yourself as an American, and now I’m seeing the reverse of people being very much like, “No, this is what I eat. This is what we eat in our culture. I’m very proud of it. This is the music that we listen to. This is some of the outfits that we wear.” So I see this moment online where people are going to be more proud to kind of share who they are fully and also showcasing their culture. So I hope Latinas Poderosas can be this hub that hosts a lot of that information, and a lot of those moments that people can just refer to whenever they feel like they’re in this moment of trying to figure out their identity of who they are.
I feel like a lot of the conversations that I personally have heard, and from my personal experience, a lot of people when they’re growing up, and they’re in their pre-teens and teens, they’re kind of confused trying to figure out who they are as an individual. And then when they hit their 20s, you wonder, “who really am I?” And it goes back into thinking of who are you? Culturally, your roots. How do you identify and navigate this world? So I hope that when people are at that stage of their lives, when they’re trying to figure out how they can celebrate themselves and who they are fully, they can have a platform, an online space where they can be like, “OK, here’s where I can learn about myself. Here’s where I can learn about and support businesses from my community.” Maybe they don’t want to create their own platform, maybe they don’t want to create their own brand, but they’re like, “how can I support?” So I hope it becomes that type of online space where people can just find it whenever they’re in that moment of wondering who they are, how they can celebrate themselves and learn more about who they are and where they come from.
We’re definitely in a world today where it’s a lot more accepted to embrace your culture, especially in schools.
And now you see people wearing like the traditional patterns or clothing. And it’s very in your face now, and you’re like, “Hey, where was this type of energy when I was in middle school or high school, and you were teasing me?”
<figcaption class="wp-element-caption">Kay Lopez at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
Who are some of the other creators you draw inspiration from to continue your work today?
I wouldn’t call out anyone specifically, I would just say again that it’s anyone who’s in the space of culture. I look at anyone who’s trying to amplify the voice of their communities to really showcase and educate, who are really trying to drive positive conversation. I think that’s the number one thing for me. There is a lot of trolling, negative conversations that can affect people’s mental health and very aggressive conversations when it comes to culture, and those are the conversations I tend to shy away from. Only because I really want to focus on how we can move forward progressively as communities of color within the United States. How can we just kind of focus on amplifying the positive and trying to break some noise and create positive impact? Long answer, but it’s just to say it’s really anyone who is trying to make a positive space online while amplifying culture.
What do you think is the biggest challenge we as a whole face in the world this year, on and offline? How do we combat it?
I would say it’s mental health. Social media exhaustion, I hear it so much. I’ve been in the social media space for 12 years. I started on MySpace, creating content for brands, so I’ve been in this space for a very long time. It can become a very overwhelming space with a lot of information. I do believe, despite me being in social media and working for brands on their social and having my own platform, that mental breaks are OK and they should happen. You should be able to walk away from social media. You should be able to walk away from your phone and be like, “Hey, I just need to connect with the real world for a little bit and then come back.” Because the way that it’s affecting people can be very negative. Like having someone step away from their phone or not having a phone on them causes panic in a lot of people, so being able to be OK with disconnecting, I would say, is something that should be a priority for your mental state when it comes to being online and knowing how to set your boundaries for your mental health.
What is one action that you think everyone should take to make the world and our lives a little better?
I feel like the quick answer is just be yourself. Embrace who you are and live proudly every day with that mindset. I think it just makes you a happier person as a whole, but then it also welcomes others to learn.
We started Rise25 to celebrate Mozilla’s 25th anniversary, what do you hope people are celebrating in the next 25 years?
That’s such a heavy question. Truthfully, something that I think about all the time is world peace. That we have solved the environmental issues that we are facing. That as a human species, we’re just in a better, healthier environment. And that history doesn’t repeat itself.
What gives you hope about the future of our world?
What gives me hope, I think, is just seeing what’s being created, whether that’s like advances in medicine, seeing people share history, just all of us working towards a better environment, working towards a better world. It just makes me hope that we are in a more positive existence and a better, safer environment. Despite the negative that is happening in today’s world, I do see that there are those who are really working towards a better tomorrow and I hope that we can see that in the next coming years.
It’s all coming together. The PC power user is back. In the early days of small business microcomputers, the person with a subscription to Byte, and some knowledge of topics like batch files and how to get support for a printer driver, was able to bring up the value of the office computer up from, say, a 2 on a scale of 1 to 10 to maybe a 4 or 5. The desktop PC options kept getting better, though, so by the time Microsoft got to Windows XP in the early 2000s, the small office PC was more like a 6 or 7 without tweaking, and power user skills made less of a difference. No more DIP switch settings to learn! When you plug in a printer it works out of the box! You can get updates over the Internet! And the small business Internet scene, for a while, was solidly in create more value than you capture territory. All that added up to much less value returned from the time invested to become a power user.
But now the balance is shifting again. Now the small office or home office PC is more of a point of sale device, loaded with surveillance software, compliance risks, and SaaS upsells. The peripherals work, in a sense, but they don’t work so much for you as for some far-away product manager who needs to nail their OKRs to get promoted and afford a down payment on a house.economics experiment I’d like to try: make middle-class housing affordable on an honest IT salary to test my hyothesis that enshittification would go down And the small-business-facing Internet is a more or less wretched hive of scum and villainy, from fairly mild shelfware without the shelf schemes, all the way to actively heinous stuff like sending your marketing budget to terrorists.
But the underlying PC hardware is still getting way better. And Internet service is getting faster with lower latency, and the best of the software you can easily get is still getting way better. Which means a bigger gap between baseline and advanced configuration, so a bigger win from learning power user stuff. Yes, I’m a Linux nerd, but you can probably get your computer into an acceptable state without switching OSs. (I got a Microsoft Windows laptop for work, and the two OSs have gotten a lot more similar. On Linux a video conference is more likely to just work, and on Windows, stuff is more likely to break because somebody got bored with it.) So if in the 1980s you could bring an office PC up from a 2 to a 5, and in the 2000s you might not get much noticeable change, now you can bring your PC from negative territory up to a 7 or 8. Looks like a big win, even if you don’t count the payoff from scam protection.
Related
Why We Need to Address Scam Culture by Tressie McMillan Cottom (The growth hacking mindset in IT product management is a small part of a bigger problem. Business practices that used to be unthinkable for reputation reasons have now gone mainstream. Personally, I’m not sure why. It might just be that business culture is more global and today’s Big Tech decision-makers are more likely to compare themselves to a peer group that includes more international resource extraction oligarchs and fewer execs at mid-sized legit companies.)
Is Everything BS?So the most important thing you can do with a sale is not purely the economic bit, and it’s not purely the behavioral bit. It’s both. Good interview with Rory Sutherland
Google’s Privacy Sandbox: More Like Privacy Litter Box (At last, an adtech piece about Google’s in-browser advertising system that doesn’t do the whole feedback sandwich thing with praising Google’s privacy efforts first, then actually saying what the author means to say, then buttering up Google again at the end. A must-read for anyone who has to edit anything about web ads.)
Mozilla is an advertising company now (they have gone back and forth with ad features in Firefox for quite a few iterations. Possible good news here, though. Probably a good sign that the PETs adtech hype peak has been crested.)
What everyone gets wrong about the 2015 Ashley Madison scandalPeople have been trying to have affairs with strangers for thousands of years. Ashley Madison was never really about that. Avid Life Media, its parent company, wasn’t in the business of sex, it was in the business of bots. Its site became a prototype for what social media platforms such as Facebook are becoming: places so packed with AI-generated nonsense that they feel like spam cages, or information prisons where the only messages that get through are auto-generated ads.
Applying The ‘Would Your Mother Approve?’ Rule To Online Ad TrackingBarnes is one of the attorneys leading an ongoing class-action suit alleging that Meta’s tracking pixel is a violation of HIPPA because it’s able to collect sensitive protected health information without a patient’s knowledge and can transmit that data directly to Facebook and Instagram. He says, But I will say that any legislator who votes to say that only an attorney general can bring an action to defend a consumer’s privacy rights is making a 100% un-American vote. People have the right to a jury trial lawyer of their own choosing and the ability to access the courts on their own without asking permission from a government official. (Class-action privacy cases are a promising direction for taking on a lot of this stuff IMHO.)
I finally understand why
Rambaldi
may have hidden so many inventions.
Forecast
When you invent something, you should forecast the impact of your invention in the current cultural (social, political, economic, belief systems) context, and if it
poses non trivial existential risk
or is likely to cause more harm than good
Shoulds
Then you should stop, and:
encrypt your work for a potentially better future context
or destroy your notes, ideally in a way that minimizes risk of detection of their deliberate destruction
and avoid any or any detectable use of your invention, because even the mere use of it may provide enough information for someone else to reinvent it who may not be as responsible.
In Addition
Insights and new knowledge are included in this meaning of “invention” and the guidance above.
Forecasting should consider both whether your invention could directly cause risk or more harm, or if it could be incorporated as a building block with other (perhaps yet to be invented) technologies to create risk or more harm.
Instead
Instead of continuing work on such inventions, shift your focus to:
work on other inventions
and document & understand how & why that current cultural context would contribute to existential risk or more harm than good
and work to improve, evolve that cultural context to reduce or eliminate its contribution to existential risk, and or its aspects that would (or already do) cause more harm than good
Da Vinci
The
Should (1)
provides a plausible explanation for why
Da Vinci
“encrypted” his writings in
mirror script,
deliberately making it difficult for others to read (and thus remember or reproduce).
Per
Should (2)
he also wrote in paper mediums of the time that were all destroyable,
and he may have been successful in destroying without detection,
since no one has found any evidence thereof, although such a lack of evidence is purely circumstantial and he may just as likely never destroyed any invention notes.
Methods & Precautions
Learning from Da Vinci’s example within the context of the
Shoulds, we can infer additional methods and precautions to take when developing inventions:
do not write initial invention notes where others (people or bots) may read them (e.g. most online services) because their ability to transcribe or make copies prevents
Should (2).
Instead use something like paper notes which can presumably be shredded or burned if necessary, or keep your notes in your head.
do not use bound notebooks for initial invention notes because tearing out a page to destroy may be detectable by the bound remains left behind.
instead use individual sheets of paper organized into folders. perhaps eventually bind your papers into a notebook. Which apparently
Da Vinci did!
“These notebooks – originally loose papers of different types and sizes…”
consider developing a simple unique cipher you can actively use when writing which will at least inconvenience, reduce, or slow the readability of your notes. even better if you can develop a
steganographic
cipher, where an obvious reading of your invention writings provides a plausible but alternative meaning, thus hiding your actual invention writings in plain sight.
Dream
Many of these insights came to me in a dream this morning, so clearly that I immediately wrote them down upon waking up, and continued writing extrapolations from the initial insights.
Additional Reading
After writing down the above while it (and subsequent thoughts & deductions) were fresh in mind, and typing it up, I did a web search for “responsible inventing” for prior similar, related, or possibly of interest works and found:
While this post encourages forecasting and other methods for avoiding unintended harmful impacts of inventions, I want to close by placing those precautions within an active positive context.
I believe it is the ultimate responsibility of an inventor to contribute, encourage, and actively create a positive vision of the future through their inventions. As
Alan Kay said:
“The best way to predict the future is to invent it.”
Comments
Comments curated from
replies on personal sites
and
federated replies
that include thoughts, questions, and related reading
that contribute to the primary topic of the article.
If some invention can pose a risk, should it be treated as a vulnerability?
Destroying/delaying an invention, in this case, could lead to it being re-invented and exploited in a different, less responsible, place.
Obviously, it doesn't mean that invention should be unleashed. But if it poses a risk, wouldn't it be more responsible to work on finding a way to minimize it, and, ideally, not alone?
There is probably no one good answer, and each case will be different.
I am unsure if it is always practical or possible, for an inventor to understand all the characteristics of their inventions and their impact beyond a very slim set of hops.
If things go well, I believe inventors can "believe their own hype", because they are human.
Questions:
Is it a free pass if you make something awful and can't take it back?
Would that make Ignorance a virtue?
This opens up many more problems, for both creators, and broader society.
Servo has had some exciting changes land in our nightly builds over the last month:
as of 2024-05-31, we now support ‘white-space-collapse: break-spaces’ (@mrobinson, @atbrakhi, #32388)
as of 2024-06-11, we now support <col span> in <colgroup> (@Loirooriol, #32467)
as of 2024-06-14, we now support the decode method on HTMLImageElement (@Taym95, #31269)
as of 2024-06-18, we now have initial support for ResizeObserver (@gterzian, #31108)
to enable this experimental feature, run servoshell with --pref dom.resize_observer.enabled
as of 2024-06-21, we now render text in input fields (@mrobinson, #32365)
note that editing is still very limited, and the caret and selection are not yet rendered
<figcaption>On platforms with color emoji support, we now correctly follow Unicode’s rules for when to use color emoji. This table also uses <col span> in a <colgroup>.</figcaption>
WebGPU can now run on OpenGL ES on Windows and Linux (@hieudo-dev, #32452), no longer records errors after losing a device (@sagudev, #32347), and you can now select a WebGPU backend with --pref dom.webgpu.wgpu_backend=.
servoshell can now go fullscreen without showing the location bar (@Nylme, #32425), and no longer leaves the status bar behind when navigating (@webbeef, #32518).
We’ve also started building servoshell on OpenHarmony in CI (@jschwe, #32507), started merging our Android build into servoshell (@jschwe, #32533), and refactored servoshell’s desktop-only code (@jschwe, #32457).
Fonts and emoji
Unicode emoji often come in two variants: an emoji presentation (color or graphic) and a text presentation (monochrome).
You can select one or the other by appending the variation selectorsU+FE0F or U+FE0E respectively, and the default presentation is controlled by the Emoji_Presentation property.
Most emoji default to emoji presentation, but not all of them, and bugs in handling that property are often why characters like ™ and ↔ get displayed as emoji when they shouldn’t.
We’ve reworked our font fallback algorithm to enable emoji in text presentation on Windows (@mrobinson, #32286) and correctly handle emoji variation selectors and Emoji_Presentation (@mrobinson, @atbrakhi, @mukilan, #32493).
<figcaption>You can now use Firefox devtools to evaluate JavaScript in Servo, but messages from the Console API are not yet visible.</figcaption>
Servo now has an AI contributions policy (@mrobinson, @delan, #32287).
In short, for the time being, anything you contribute to the Servo project must not contain content generated by large language models or other probabilistic tools.
We’ve fixed a panic in multiprocess mode (@mukilan, #32571) and several busted builds, including cross-compiling on macOS (@jschwe, #32504), building on NixOS (@mukilan, #32567), and building for Android on Fedora (@jschwe, #32532).
Donations
Thanks again for your generous support!
We are now receiving 2229 USD/month (+36.7% over May) in recurring donations.
We are still receiving donations from 15 people on LFX, and we’re working on transferring the balance to our new fund, but we will stop accepting donations there soon — please move your recurring donations to GitHub or Open Collective.
2229 USD/month
10000
As always, use of these funds will be decided transparently in the Technical Steering Committee.
For more details, head to our Sponsorship page.
Conferences and blogs
Fixing Servo’s Event Loop — Gregory Terzian blogged about using TLA+ to guide and verify our work on implementing the HTML event loop in Servo
Now that AI can beat a Turing test by bullshitting, what’s the next test? In Prediction Market Trading as an LLM Benchmark, Jesse Richardson suggests that setting up an LLM to trade on a prediction market (e.g. Polymarket, which is the platform I’ll talk about here) could be a particularly strong benchmark with a number of desirable properties.Scott Alexander also suggests prediction markets as a useful challenge for bots.
Seems like a good idea. The best part about prediction markets as a benchmark is scaling. One skilled prediction market trader can end up on the winning side of trades with a large number of low-skill traders, human or bot. LLM benchmarks that depend on evaluating generated text are much harder to scale, and it’s usually easier to bullshit than to detect bullshit. To make a market-based pass/fail test, give the bot a stake and charge it interest on its stake and rent for the computing resources it uses. A bot passes the test if it can stay solvent for the agreed-upon time in a market with human traders. Even if bots can’t pass the test, they might still have their uses, since they can help add liquidity to corporate prediction markets and incentivization markets. (More: boring bots ftw)
In practice this market test would not be a pure prediction benchmark, but would have some text generation aspects, too. A bot would get a substantial advantage by explaining its trades afterwards—talking up its positions, and telling other traders why they should pay more than the bot did. But the bot’s ability to explain its actions in a persuasive way does not have to be tested just by looking. It can be evaluated indirectly by looking at how well the bot can persuade other traders.
The big problem with building an open ecosystem for AI is the cost of benchmarking. Even when it is possible to train a model at low cost, evaluating that model depends on either hiring large numbers of human reviewers, or paying for access to a larger model. In order to get to the own your own AI stage, the benchmarking budget problem needs to be addressed early on. Integrating an incentivization market with existing open-source collaboration infrastructure (Pinfactory connects to a GitHub project pretty easily, just saying) could be a good start.
Bonus links
Ever notice that the AI skeptic articles are so much better written than the AI fan articles? It seems like the only way to change that would be for the AI firms to start doing the whole pay the writers thing. Somehow the AI scene needs to, for its own good, figure out how to stop squeezing legit text out of training sets and avoid letting deceptive text in. But paying people for public information goods is hard. AI firms will have to look at options such as putting up the seed money for a dominant assurance contract on a to-be-written work on the condition that it will be licensable for training. In the meantime, here’s a recent list of AI-related links that have been making the rounds.
Perplexity’s grand theft AI[B]y providing an answer, rather than pointing people to click through to a primary source, these so-called “answer engines” starve the primary source of ad revenue — keeping that revenue for themselves.
L AI ZY.What was happening in the world of AI was that people thought they could ask it a question–what’s the next big fashion trend–and get an answer. They didn’t realize the amount of work that had to be done to allow a computer to derive an answer.
There’s Something Deeply Wrong With PerplexityEven readers are becoming wary of the trend, with a new report by the Reuters Institute for the Study of Journalism finding that a majority of news consumers are suspicious of AI-generated news content. (I am seeing a lot more user questions about how to block or avoid AI output then questions about how to get it. Maybe the people trying to get it are asking in other places?)
The public web and consentOn the LLM front, I’m not particularly bothered by my writing being used to help train GPT, Claude, or Apple Intelligence. While I appreciate others feel differently, I just don’t see these tools as replacing me in any real way. On the other hand, tools like Arc Search, Perplexity, and Google’s AI answers are trying to replace me and present my work as their own. That’s plagiarism and copyright infringement…
How to stop Perplexity and save the web from bad AILike Clearview, Perplexity’s core innovation is ethical rather than technical. In the recent past, it would have been considered bad form to steal and repurpose journalism at scale. Perplexity is making a bet that the advent of generative AI has somehow changed the moral calculus to its benefit.
I Paid $365.63 to Replace 404 Media With AI (This is a fun one, although scary when you consider the low standards of certain web ad companies. I really hope they do a follow-up about whether Mohamed Sawah has more work than he can handle now. Or maybe in the future when he’s some kind of Internet tycoon this story will be the place to look for answers to some trivia questions about sites he worked on.)
The good news is: I haven’t forgotten about transient bit-flips and solar interference has been brewing in the back of my mind since the original blog post.
The sun itself has helped to bring this back to the forefront for me since we are approaching the solar maximum. Once about every 11 years or so, the sun tends to get very active in generating sun-spots and that comes with an increase in solar flares and coronal mass ejection events. Pair that with the new sunspot friends I have made which have been spewing charged particles our way (such as my new best sunspot friend AR3664, who has been especially active lately), have all helped to give me an increased amount of solar activity that will make searching for the needles in the haystack that much easier.
Currently I have been looking at correlations between the incidence of transient bit-flips in the data and the Kp and Ap indices. These are relative measures of the Sun’s effect on the Earth’s magnetic field. I’ve also taken advantage of having an actual astrophysicist working on data-science within my wider org that I hope I haven’t been pestering too much with my questions (thank you Dr. Jeff Silverman).
Right now is the best time to collect data that I could possibly ask for on this interesting little topic, considering all the elements working in my favor. In light of that fact, and at the prompting of both my manager and astro-mentor, I am working towards putting this all together in the form of an article which I will seek to publish in a peer-reviewed journal. That’s a little bit daunting to me, as I’ve not done a lot of this sort of research and writing in some time, but it’s also exciting to think about the possible applications of what I learn along the way.
I must apologize for keeping you in suspense a while longer. I don’t have any mind-blowing things to share just yet, but I assure you that they are coming soon. Being a Mozillian, I strongly believe in working in the open, so I’ll do my best to ensure that wherever the results of my research end up they will be publicly available for the world to make use of. So here’s to the coming solar maximum and its impact on data!
Process separation is one of the cornerstones of the Firefox security model. Instead of running Firefox as a single process, multiple processes with different privileges communicate with each other via Inter-Process Communication (IPC). For example: loading a website, processing its resources, and rendering it is done by an isolated Content Process with a very restrictive sandbox, whereas critical operations such as file system access are only allowed to be executed in the Parent Process.
By running potentially harmful code with lower privileges, the impact of a potential code execution vulnerability is mitigated. In order to gain full control, the attacker now needs to find a second vulnerability that allows bypassing these privilege restrictions – which is colloquially known as a “sandbox escape”.
In order to achieve a sandbox escape, an attacker essentially has two options: The first one is to directly attack the underlying operating system from within the compromised content process. Since every process needs to interact with the operating system for various tasks, an attacker can focus on finding bugs in these interfaces to elevate privileges.
Since we have already deployed changes to Firefox that severely limit the OS interfaces exposed to low-privilege processes, the second attack option becomes more interesting: Exploiting bugs in privileged IPC endpoints. Since low privilege content processes need to interact with the privileged parent process, the parent needs to expose certain interfaces.
If these interfaces do not perform the necessary security checks or contain memory safety errors, the content process might be able to exploit them and perform actions with higher privileges, possibly leading to an entire parent process takeover.
Traditionally , fuzzing has had multiple success stories in the history of Mozilla and allowed us to find all sorts of problems including security vulnerabilities in our code. However, applying fuzzing to our critical IPC interfaces has historically always been difficult. This is primarily because IPC interfaces cannot be tested in isolation, i.e. require the full browser for testing, and because incorrect usage of IPC interfaces can force browser restarts which introduce a prohibitive amount of latency between iterations.
To find a solution to this challenge, we engaged with the research community to apply a new method of rewinding application state during fuzzing. We saw our first results with this approach in 2021 using an experimental prototype that would later become the open source snapshot fuzzing tool called “Nyx”.
As of 2024, we are happy to announce that we are now running various snapshot fuzzing targets for IPC in production. Snapshot fuzzing is a new technology that has become more popular in recent years and we are proud of our role in bringing it from concept to practicality.
Using this technology we have already been able to identify and fix a number of potential problems in our IPC layer and we will continue to improve our testing to provide you with the most secure version of Firefox.
If you’d like to know more, or even consider contributing to Mozilla, check out our post on the security blog explaining the technical architecture behind this new tool.
As a Community Manager in the Mozilla Support (SUMO) team, I feel so fortunate to be working alongside so many inspiring contributors, doing amazing things to support the open web. Each of them have their own story. And through this post, I’d like many more people to hear their story.
In this first edition of contributor spotlight, you’ll hear from Wxie, a localizer who help localize support content on SUMO to Simplified Chinese. Feel free to grab a cup of your favorite drink before you learn more about his contribution journey with SUMO.
My motivation was a blend of gratitude for the software that had aided me, like Thunderbird and Firefox, and a sense of community spirit. This motivation and the idea of all software should be free are still the ultimate drive for me to continue my contribution. I really expect this is a life-long journey because I feel that I am helping make the world a better place.
Q: Please tell us about yourself!
My name is Xie. I live in Shanghai, China, a metropolis.
Like many of you, I have an engineering background. I studied physics and Electrical Engineering, have been working in automotive industry for most of my career. I am interested in things related to technology, both software and hardware. I am good at system integration, like combining solutions together to make a product. Now I am doing technical consulting for a living.
In my spare time, I enjoy sports. I used to play soccer with friends regularly, but now I mainly run on my own. Sports keep me motivated and loving the beautiful life.
I am often in IRC (libera.chat) using wxie as my nick. We can be friends there, too.
Q: What is your SUMO contribution story?
I started contributing to SUMO from May 2016, and I never stop my contribution since then.
I have mainly working on the Simplified Chinese Localization part. I translate the Knowledge-Base articles, like release note, How-to, New-feature-introduction, Trouble-shooting, from English into Chinese. I want to make it easier for Chinese-speaking users to have access to the wonderful world of free internet. Mozilla is a leading organization in this sense.
Apart from Knowledge-Base articles, I also work on UI text at Pontoon. This part of localization requires more discipline and careful thoughts because the text will be directly presented as user interface in the products.
Sometimes I ask and answer questions in our community forums. There I have met many interesting people, and got a lot of help.
You can also contact me at Mozilla Matrix. That is a good place to get quicker response for your questions. In summary, my contribution to SUMO focuses on localization and helping end users.
Q: You indicate in your SUMO profile that you’ve been contributing since 2016 (that’s an amazing milestone!). Can you tell us more about what motivated you to contribute in the first place, and what keeps you going until now?
All this started from the introduction of GNU back in the early year of 21st century. At that time, many people had heard of something called Linux, and I was one of them who dared to order a 6-CD set to install the Debian GNU/Linux system on my new computer.
From that time on, through my GNU system, I enter the world of free software via the GNU website. Not only does the idea of free software attract me, but also there are excellent free programs I am able to use and study. For example, I taught myself C programming though GCC. After years of benefiting from the community’s free programs, I felt a profound sense of gratitude and a desire to give back.
I became a Savannah hack in 2014, a decade ago, to contribute to the GNU project. In 2016, I transitioned from using web-mail to an email client and chose Thunderbird.
Email can be a powerful tool. In May 2016, I received an email from the system asking for support in translating the release notes for Thunderbird 45.0. Considering I was using it for gratis, and I thought I knew some English, I decided to lend a hand. I followed the link and registered as a localization contributor in SUMO (SUpport.Mozilla.Org).
My motivation was a blend of gratitude for the software that had aided me, like Thunderbird and Firefox, and a sense of community spirit. This motivation and the idea of all software should be free are still the ultimate drive for me to continue my contribution. I really expect this is a life-long journey because I feel that I am helping make the world a better place. Would you be part of it?
Q: I know you’re also a big supporter of the free software movement and even part of the Free Software Foundation. Can you tell us more about your activity in other open source communities you’re part of and how it influences your contribution to Mozilla?
As you already know, I support GNU earlier than SUMO, and in 2017 I registered as a member of Free Software Foundation to show my sincere support to free software movement.
I don’t use the term “open source” to associate my contribution to free software. Even though Free Software and Open source software are basically the same category of software, the idea behind it is very different: Free Software advocates computer user freedom, while open source focuses on software development practice.
Actually, my activity in GNU is tightly related to my contribution to Mozilla. First, I am the coordinator of the Chinese translation team for the GNU website. This is a very similar role to the locale leader role in SUMO. I can share my experience between these two roles. Second, both teams are volunteers with enthusiasm. I could talk to them about the relationship of free software and Mozilla so that we can work for both if they wish. Last, I have encountered many excellent individuals from both communities and learned new hacking skills along the way. These friendships and skills give me confidence and push me moving forward. I am grateful to all of them.
Q: What are the biggest challenges you’re facing as a SUMO contributor at the moment? What would you like to see from us in the future?
The Chinese team of SUMO is not in a challenging status at the moment. We have several active members supporting each other, and we are attracting newcomers constantly. However, there is a thing I am worried: many people leave too soon in SUMO before they know why, what and how to contribute. So I think the on-boarding process should be improved. I would suggest that after newcomers’ first contribution there is not only a recognition but also some kind of training session to let them know we welcome them and care about them.
It is always good to have a strong community to support the newcomers, and it is better to keep the newcomers to build a stronger community.
Q: Can you tell us a story about the most rewarding moment and impactful contribution you’ve made in SUMO?
Yes. There were many moments that I felt I achieved something. In 2016, I finished almost all the knowledge-base articles for Simplified Chinese, and I received an email from SUMO to join the All-Hands meeting. It was a surprise. I didn’t know at all that there is such a get-together event. It was an exciting moment when I met all the SUMO contributors and other Mozilla friends. It was rewarding.
Q: What’s your contribution focus at the moment? Any exciting projects you’re working on right now?
At the moment, the team and I are working mainly on Pontoon because Knowledge-base is stable. I am also considering some kind of succession plan to keep the team stable.
In GNU, there are more interesting projects. Besides the www.gnu.org web translation, I am also looking into Emacs, gnunet, Guile and GUIX to see what I can do more there.
Q: I know zh-CN has a pretty active local community. Can you tell us more about the regional community there and how you work with them?
Yes. zh-CN community is very active. We have a local chat group. In the group, people raise questions and get answer and discussion promptly. We often reach agreement regarding specific translations as well as general process through group discussion.
Thanks to SUMO community managers, including Kiki, I could sometimes arrange some small gifts to some members to show our recognition for their outstanding contribution in the localization work.
Q: What advice would you give to someone new who wants to contribute to article localization in SUMO?
Hi, newcomer, welcome to the wonderful world of SUMO. You are awesome!
Localization is an interesting task. If you are good at English and your local language, great, you can start the task right from your language’s dashboard. If you are good at your local language, great too, you can start reviewing other’s translation from the dashboard.
Don’t worry. All the tools and processes are ready for you to use right in your Firefox web browser. You can also find other volunteers from team session and in the contributor forums. We are all here to help you.
Choose an article that is not too long to start, and gradually moves to longer articles. You will win your first SUMO badge soon. Keep going. You will win more.
Stay with Mozilla, good things happen.
I hope you enjoy your read. If you’re interested in joining the Mozilla Support community just like Wxie, please go to SUMO contribute page to learn more. You can also reach out to us through the following channels:
This is the first of what I think will be several follow-up posts to “Claiming, auto and otherwise”. This post is focused on clarifying and tweaking the design I laid out previously in response to some of the feedback I’ve gotten. In future posts I want to lay out some of the alternative designs I’ve heard.
TL;DR: People like it
If there’s any one thing I can take away from what I’ve heard, is that people really like the idea of making working with reference counted or cheaply cloneable data more ergonomic than it is today. A lot of people have expressed a lot of excitement.
If you read only one additional thing from the post—well, don’t do that, but if you must—read the Conclusion. It attempts to restate what I was proposing to help make it clear.
Clarifying the relationship of the traits
I got a few questions about the relationship of the Copy/Clone/Claim traits to one another. I think the best way to show it is with a venn diagram:
The Clone trait is the most general, representing any way of duplicating the value. There are two important subtraits:
Copy represents values that can be cloned via memcpy and which lack destructors (“plain old data”).
Claim represents values whose clones are cheap, infallible, and transparent; on the basis of these properties, claims are inserted automatically by the compiler.
Copy and Claim overlap but do not have a strict hierarchical relationship. Some Claim types (like Rc and Arc) are not “plain old data”. And while all Copy operations are infallible, some of them fail to meet claims other conditions:
Copying a large type like [u8; 1024] is not cheap.
Copying a type with interior mutability like Cell<u8> is not transparent.
On heuristics
One challenge with the Claim trait is that the choice to implement it involves some heuristics:
What exactly is cheap? I tried to be specific by saying “O(1) and doesn’t copy more than a few cache lines”, but clearly it will be hard to draw a strict line.
What exactly is infallible? It was pointed out to me that Arc will abort if the ref count overflows (which is one reason why the Rust-for-Linux project rolled their own alternative). And besides, any Rust code can abort on stack overflow. So clearly we need to have some reasonable compromise.
What exactly is transparent? Again, I tried to specify it, but iterator types are an example of types that are technically transparent to copy but where it is nontheless very confusing to claim them.
An aversion to heuristics is the reason we have the current copy/clone split. We couldn’t figure out where to draw the line (“how much data is too much?”) so we decided to simply make it “memcpy or custom code”. This was a reasonable starting point, but we’ve seen that it is imperfect, leading to uncomfortable compromises.
The thing about “cheap, infallible, and transparent” is that I think it represents exactly the criteria that we really want to represent when something can be automatically claimed. And it seems inherent that those criteria are a bit squishy.
One implication of this is that Claim should rarely if ever appear as a bound on a function. Writing fn foo<T: Claim>(t: T) doesn’t really feel like it adds a lot of value to me, since, given the heuristical nature of claim, it’s going to rule out some uses that may make sense. eternaleye proposed an interesting twist on the original proposal, suggesting we introducing stricter versions of Claim for, say, O(1) Clone, although I don’t yet see what code would want to use that as a bound either.
“Infallible” ought to be “does not unwind” (and we ought to abort if it does)
I originally laid out the conditions for claim as “cheap, infallible, and transparent”, where “infallible” means “cannot panic or abort”. But it was pointed out to me that Arc and Rc in the standard library will indeed abort if the ref-count exceeds std::usize::MAX! This obviously can’t work, since reference counted values are the prime candidate to implement Claim.
Therefore, I think infallible ought to say that “Claim operations should never panic”. This almost doesn’t need to be said, since panics are already meant to represent impossible or extraordinarily unlikely conditions, but it seems worth reiterating since it is particularly important in this case.
In fact, I think we should go further and have the compiler insert an abort if an automatic claim operation does unwind.1 My reasoning here is the same as I gave in my post on unwinding2:
Reasoning about unwinding is already very hard, it becomes nigh impossible if the sources of unwinding are hidden.
It would make for more efficient codegen if the compiler doesn’t have to account for unwinding, which would make code using claim() (automatically or explicitly) mildly more efficient than code using clone().
I was originally thinking of the Rust For Linux project when I wrote the wording on infallible, but their requirements around aborting are really orthogonal and much broader than Claim itself. They already don’t use the Rust standard library, or most dependencies, because they want to limit themselves to code that treats abort as an absolute last resort. Rather than abort on overflow, their version of reference counting opts simply to leak, for example, and their memory allocators return a Result to account for OOM conditions. I think the Claim trait will work just fine for them whatever we say on this point, as they’ll already have to screen for code that meets their more stringent criteria.
Clarifying claim codegen
In my post, I noted almost in passing that I would expect the compiler to still use memcpy at monomorphization time when it knew that the type being claimed implements Copy. One interesting bit of feedback I got was anecdotal evidence that this will indeed be cricital for performance.
To model the semantics I want for claim we would need specialization3. I’m going to use a variant of specialized that lcnr first proposed to me; the idea is to have an if impl expression that, at monomorphization time, either takes the true path (if the type implements Foo via always applicable impls) or the false path (otherwise). This is a cleaner formulation for specialization when the main thing you want to do is provide more optimized or alternative implementations.
Using that, we could write a function use_claim_value that defines the code the compiler should insert:
fnuse_claim_value<T: Claim>(t: &T)-> T{std::panic::catch_unwind(||{ifimplT: Copy{// Copy T if we can
*t}else{// Otherwise clone
t.clone()}}).unwrap_or_else(||{// Do not allow unwinding
abort();})}
This has three important properties:
No unwinding, for easier reasoning and better codegen.
Copies if it can.
Always calls clone otherwise.
Conclusion
What I really proposed
Effectively I proposed to change what it means to “use something by value” in Rust. This has always been a kind of awkward concept in Rust without a proper name, but I’m talking about what happens to the value x in any of these scenarios:
letx: SomeType;// Scenario A: passing as an argument
fnconsume(x: SomeType){}consume(x);// Scenario B: assigning to a new place
lety=x;// Scenario C: captured by a "move" closure
letc=move||x.operation();// Scenario D: used in a non-move closure
// in a way that requires ownership
letd=||consume(x);
No matter which way you do it, the rules today are the same:
If SomeType: Copy, then x is copied, and you can go on using it later.
Else, x is moved, and you cannot.
I am proposing that, modulo the staging required for backwards compatibility, we change those rules to the following:
If SomeType: Claim, then x is claimed, and you can go on using it later.
Else, x is moved, and you cannot.
To a first approximation, “claiming” something means calling x.claim() (which is the same as x.clone()). But in reality we can be more efficient, and the definition I would use is as follows:
If the compiler sees x is “live” (may be used again later), it transforms the use of x to use_claimed_value(&x) (as defined earlier).
If x is dead, then it is just moved.
Why I proposed it
There’s a reason I proposed this change in the way that I did. I really value the way Rust handles “by value consumption” in a consistent way across all those contexts. It fits with Rust’s ethos of orthogonal, consistent rules that fit together to make a harmonious, usable whole.
My goal is to retain Rust’s consistency while also improving the gaps in the current rule, which neither highlights the things I want to pay attention to (large copies), hides the things I (almost always) don’t (reference count increments), nor covers all the patterns I sometimes want (e.g., being able to get and set a Cell<Range<u32>>, which doesn’t work today because making Range<u32>: Copy would introduce footguns). My hope is that we can do this in a way that it benefits most every Rust program, whether it be low-level or high-level in nature.
In fact, I wonder if we could extend RFC #3288 to apply this retroactively to all operations invoked automatically by the compiler, like Deref, DerefMut, and Drop. Obviously this is technically backwards incompatible, but the benefits here could well be worth it in my view, and the code impacted seems very small (who intentionally panics in Deref?). ↩︎
Another blog post for which I ought to post a follow-up! ↩︎
Specialization has definitely acquired that “vaporware” reputation and for good reason—but I still think we can add it! That said, my thinking on the topic has evolved quite a bit. It’d be worth another post sometime. /me adds it to the queue. ↩︎
It has been more than a year since the initial blog post announcing the Types team, and our initial set of goals. For details on what the team is, why it was formed, or our previously-stated overarching goals, go check out that blog post. In short the Types team's purview extends to the parts of the Rust language and compiler that involve the type system, e.g. type checking, trait solving, and borrow checking. Our short and long term goals effectively work to make the type system sound, consistent, extensible, and fast.
Before getting into details, it's worth sharing a quick point: the team over the last year has been very successful. Oftentimes, it's hard to measure impact, particularly when long-term roadmap goals are hard to quantify progress on and various short-term goals either are hit or aren't. But, there is one clear statistic that is somewhat indicative of the team's progress: over the last year or so, more than 50 user-facing changes have landed, each separately approved by Types Team consensus through FCP.
The changes lie at the boundary between language design and implementation, and the Types Team (which is a subteam of both the Language and Compiler Teams) existing means that not only does the Rust Project have the bandwidth to make these decisions but we also have enough people with the knowledge and experience of the type system to make informed decisions that overall make the language better.
The priorities of the types team
To evaluate our progress over the last year and our roadmap going forward,
lets start with our main priorities in order of importance. We will refer
to them during the remainder of this post. To reach our goals, we need a
a healthy group of maintainers which have the expertise and capacity to
react to issues and to implement complex changes.
The type system should be Sound
One of the main promises of Rust is that there cannot be undefined behavior when using
only safe code. It might surprise you that there are currently known type system
bugs which break these guarantees. Most of these issues were found by people familiar with
the inner workings of the compiler by explicitly looking for them and we generally do not expect
users to encounter these bugs by accident. Regardless, we deeply care about fixing them
and are working towards a fully sound and ideally verified type system.
The type system should be Consistent
The type system should be easy to reason about. We should avoid rough edges and
special-cases if possible. We want to keep both the implementation and user-facing behavior
as simple as possible. Where possible we want to consider the overall design instead of
providing local targeted fixes. This is necessary to build trust in the soundness of the
type system and allows for a simpler mental model of Rust.
The type system should be Extensible
Rust is still evolving and we will be required to extend the type system to enable new
language features going forward. This requires the type system to be extensible and
approachable. The design of the language should not be adapted to work around
short-comings of its current type system implementation. We should collaborate with
other teams and users to make sure we're aware of their problems and consider possible
future extensions in our implementation and design.
The type system should be Fast
We care about the compile times of Rust and want to consider the impact on compile times
of our designs. We should look for effective approaches to speed up the existing implementation,
by improving caching or adding fast paths where applicable. We should also be aware of the
compile time impact of future additions to the type system and suggest more performant
solutions where possible.
Updates
We have been very active over the last year and made some significant progress. There
are also a few non-technical updates we would like to share.
Organizational updates
First, a huge welcome to the two new members to team since the announcement post: @BoxyUwU and @aliemjay. @BoxyUwU has been doing a lot of work on const generics and made significant contributions to the design of the next generation trait solver. @aliemjay has been working on some very subtle improvements to opaque types - impl Trait - and to borrow checking. They are both invaluable additions to the team.
We also organized another in-person Types Team meetup last October, immediately prior to EuroRust. We discussed the state of the team, looked at current implementation challenges and in-progress work, and reviewed and updated the roadmap from the previous meetup. Most of this will be covered in this blog post.
Finally, as discussed in the RFC, we would like to have leads rotate out regularly, largely to help share the burden and experience of leads' work. So with that being said, @nikomatsakis is rotating out and @lcnr is joining to co-lead alongside @jackh726.
Roadmap progress and major milestones
The next-generation trait solver
There has been a lot of work on the next-generation trait solver.
The initiative posted a separate update at the end of last year. While
we would have liked to stabilize its use in coherence a few months ago,
this surfaced additional small behavior regressions and hangs, causing delays. We are working on fixing these issues and intend to merge the stabilization PR soon. We are getting close to compiling the standard library
and the compiler with the new solver enabled everywhere, after which will be able to run
crater to figure out the remaining issues. We expect there to be a long tail of minor issues
and behavioral differences from the existing implementation, so there's still a lot to do
here. There are also open design questions which we will have to resolve before stabilizing
the new implementation.
Async and impl Trait
We stabilized async-fn in traits (AFIT) and return-position impl Trait in
traits (RPITIT) in version 1.75 thanks to a significant effort by @compiler-errors and
@spastorino. @cjgillot greatly improved the way generators, and therefore async functions,
are represented in the type system1. This allowed us to support recursive
async-functions without too much additional work2.
Designing the next-generation trait solver surfaced issues and future-compatibility challenges
of our type-alias impl Trait (TAIT) implementation using the old trait solver. We are
currently reworking the design and implementation. @oli-obk is spear-heading this effort.
This also impacts RPIT edge-cases, forcing us to be careful to avoid accidental breakage.
There are some open language design questions for TAIT, so we plan to
stabilize associated type position impl Trait (ATPIT) as it avoids these language design
questions while still closing the expressiveness gap.
a-mir-formality
We made limited progress on a-mir-formality over the last year, mostly
because we were able to allocate less time than expected towards this work.
We have used it as the foundation towards an intuitive approach to
coinductive traits which are necessary for many of the remaining unsound
issues.
Fixing soundness issues
We fixed multiple long-standing unsound issues, see the full list of closed issues. The most most notable of which was #80176. This subtle issue caused us to accept methods in trait implementations whose function signature had outlives requirements not present in the trait definition. These requirements were then never proven when calling the trait method. As there were some crates which relied on this pattern by accident, even if it their usages didn't exploit this unsoundness, we first merged a future-compatibility lint which we then moved to a hard error after a few versions.
We've also spent time on categorizing the remaining open issues and integrating
them into our longterm planning. Most of the remaining ones are blocked on the
next-generation trait solver as fixing them relies on coinductive trait semantics
and improvements to implied bounds. There are some remaining issues which can be at
least partially fixed right now, and we intend to work through them as we go.
Finally, there are some issues for which we still haven't figured out the best
approach and which require some further considerations.
Going forward
We made significant progress during the last year but we are not done! This section covers our goals for the rest of 2024. For each item we also link to the project goals that we have proposed as part of the Rust Project's experimental new roadmap process.
Our biggest goal is to use the next-generation trait solver
everywhere by default and to fully replace the existing implementation. We are currently
finalizing the stabilization of its use in coherence checking. This should
already fix multiple unsound issues and fix a lot of smaller issues and inconsistencies of
the current implementation. See the stabilization report for more details.
We are also working on extracting its implementation into a separate library
outside of the compiler itself. We would like to share the trait solver with
rust-analyzer by the end of this year. They currently use chalk which is no longer
actively maintained. Using the next-generation trait solver in rust-analyzer
should result in a lot of additional testing for the solver while also improving
the IDE experience by positively impacting performance and correctness.
We intend to slowly roll out the solver in other areas of the compiler until we're able
to fully remove the existing implementation by the end of 2025. This switch will fix
multiple unsound issues by itself and will unblock a significant amount of future work.
It will generally cleanup many rough edges of the type system, such as associated types
in higher-ranked types. There are many unsound issues which can only be fixed once we exclusively
use the new implementation.
We intend to more actively develop a-mir-formality this year to use it in our design process.
Using it to model parts of the type system has already been incredibly impactful and we want
to build on that. We are working on more effective testing of a-mir-formality by enabling its
use for actual Rust code snippets and by adding fuzzing support. This will allow us to gain
additional confidence in our model of the type system and will guide its future development.
We plan to fully formalize some components of the type system this year. Coherence is fairly
self-contained, very subtle, and soundness-critical. This has prevented us from making significant
improvements to it in the past. We also intend to formalize coinductive trait semantics, which are
difficult to reason about and necessary to fix many longstanding soundness issues.
We intend to get the internal implementation of opaque types ready for the stabilization
of TAIT and ATPIT this year. We are also hoping to land significant improvements to our
handling of associated types in coherence checking this year.
Our other goal is to get Polonius, the next generation borrow checker, available on nightly, which would put us in a position to stabilize in 2025 once we have time to do more optimization and testing.
We also intend to support the development of other language features, such as async-closures, which are part of the async project goal,
and dyn-trait upcasting, which will hopefully get stabilized in the near future.
Roadmap
EOY 2024
next-generation trait solver
stable in coherence
used by rust-analyzer
ATPIT stabilized
a-mir-formality
support for fuzzing and testing Rust snippets
complete model of coherence and coinductive trait semantics
full polonius implementation available on nightly
EOY 2025
next-generation trait solver used everywhere by default
TAIT stabilized
polonius stabilized
EOY 2027
next-generation trait solver
support for coinduction and (implicit) where-bounds on for<'a>
enable perfect derive
a-mir-formality fully model soundness critical parts of Rust
Mozilla’srecently announced Builders program supports projects that advance the cause of open source AI. Our inaugural theme is “Local AI”: AI-powered applications that can run entirely locally on consumer devices like desktops, laptops, and smartphones. We are keenly interested in this area because it fosters greater privacy and control by putting AI technology directly into the hands of users. It also democratizes AI development by reducing costs, making powerful tools accessible to individual developers and small communities.
As a part of Mozilla Builders, we’ve launchedan accelerator that developers can apply to join, but in parallel we have also been proactively recruiting specific open source projects that we feel have the potential to move AI forward and would benefit from Mozilla’s investment, expertise, and support. Our first such Builders project isllamafile, led by open source developerJustine Tunney. llamafile makes open LLMs run fast on everyday consumer hardware while also making open source AI dramatically more accessible and usable.
Today we’re proud to announce the next Mozilla Builders project:sqlite-vec.Led by independent developerAlex Garcia, this project brings vector search functionality to the beloved SQLite embedded database.
Alex has been working on this problem for a while, and we think his latest approach will have a great impact by providing application developers with a powerful new tool for building Local AI applications.
“I’m very excited for sqlite-vec to be a Mozilla Builders project”, said Alex Garcia. “I care a lot about building software that is easy to get started with and works everywhere, a trait obviously shared by other Builders projects like llamafile. AI tools are no exception — a vector database that runs everywhere means more equitable access for everyone.”
Vector databases are emerging as a key component of the AI application stack, supporting uses like retrieval augmented generation (RAG) and semantic search. But few of today’s available databases are designed for on-device use, making it harder to offer functionality like RAG in Local AI apps. SQLite is a mature and widely-deployed embedded database – in fact, it’s even built-into Mozilla’s own Firefox web browser.
The prospect of a vector-enabled SQLite opens up many new possibilities for locally-running AI applications. For example, imagine a chatbot that can answer questions about your personal data without letting a single byte of that data leave the privacy and safety of your laptop.
We’re excited to be working with Alex and supporting his efforts on sqlite-vec. We encourage you tofollow the project’s progress, and Alex welcomes your contributions. AndMozilla’s Discord server is a great place to connect with Alex, the Mozilla Builders team, and everyone else in our growing community of open source practitioners. Please stop by and introduce yourself.
Process separation remains one of the most important parts of the Firefox security model and securing our IPC (Inter-Process Communication) interfaces is crucial to keep privileges in the different processes separated. Today, we will take a more detailed look at our newest tool for finding vulnerabilities in these interfaces – snapshot fuzzing.
Snapshot Fuzzing
One of the challenges when fuzzing the IPC Layer is that isolating the interfaces that are to be tested isn’t easily doable. Instead, one needs to run an entire Firefox instance to effectively fuzz these interfaces. However, having to run a Firefox instance for fuzzing comes with another set of downsides: First, we cannot easily reset the system back into a known-good state other than restarting the entire browser. This causes issues with reproducibility and breaks determinism required by coverage-guided fuzzing. And second, many errors in the parent process are still handled by crashing, again forcing a full and time consuming restart of the browser. Both cases are essentially a performance problem – restarting the browser is simply too slow to allow for efficient and productive fuzzing. This is where snapshot fuzzing comes into play – it allows us to take a snapshot at the point where we are “ready” to perform fuzzing and reset to that snapshot point after each fuzzing iteration at practically no cost. This snapshot technique even works when we find a bug in the parent process which would normally force us to restart the browser.
Technical Implementation
As Firefox consists of multiple processes that need to be kept in sync, we decided to use Nyx, a full-vm snapshot fuzzing tool. In this setup, Firefox runs in a guest operating system (usually Linux) and the snapshot taken is a snapshot of the whole guest including all of its processes. Nyx is also compatible with AFL++ as a frontend, a tool we already employ for other fuzzing targets.
To facilitate communication between Firefox and Nyx, we use a custom agent, essentially glue-code that is preloaded into Firefox. This code handles the low-level communication with Nyx and is also responsible for providing the trace buffer (for coverage measurements) to the AFL++ runtime linked to Firefox as well as passing through fuzzing data from AFL++. Both of these tasks are more complex in this configuration as AFL++ is not directly launching and communicating with the target binary. The agent further exposes a clean interface to Firefox that can be used to implement the actual fuzzer in Firefox itself without having to worry about the low-level details.
Technology stack for snapshot fuzzing at a glance.
Modifying a single IPC message in transit is one of the rudimentary approaches for IPC fuzzing in general. It is especially useful if the message type being targeted is in itself complex (lots of data contained in a single message rather than a complex interface being composed of a large number of simpler messages).
For this purpose, we intercept messages in the parent process on the target thread before they are dispatched to the generated IPC code that ultimately calls the IPC method. Most of the logic is then contained in IPCFuzzController::replaceIPCMessage which primarily does either of these two things:
If the message type does not match our configured target message, we can optionally dump it to a file (this is useful to create seeds for different types of single message fuzzing), but otherwise we pass the message through.
If the message matches our target specification, take the snapshot, replace the payload of the original message with our fuzzing data and return the new (fuzzed) message to be dispatched.
Once the fuzzed message is dispatched (most commonly to a different thread), we face an important challenge of multi-threaded snapshot fuzzing: synchronization. Coverage-guided fuzzing generally operates under the assumption that we know when our fuzzing data has been processed. Depending on the fuzzing target, it can be fairly difficult to tell when we are “done” but in our case, because we are already on the target thread that is running the actual IPC method. So unless that method again performs an asynchronous dispatch, we can just wait for the dispatch to return and we do so at the end of DispatchMessage() where we call back into IPCFuzzController to release (revert back to the snapshot).
By combining this target with a CI test¹, we are now able to find implementation flaws like for example a vulnerability in the accessibility code that involved the ShowEvent message. This message contains an array of serialized AccessibleData, making this message type a good target for single message fuzzing.
Measuring Code Coverage in Snapshot Fuzzing
Code coverage is probably the most important metric for long-term fuzzing campaigns as it highlights potential shortcomings of the fuzzing. While for most fuzzing, it is rather straightforward to generate code coverage, doing so in snapshot fuzzing is less trivial. Traditional source code coverage provided by tools like gcov which find usage with other fuzzing, aren’t easily deployable because the data would have to be pulled out of the VM on every iteration so it can be saved before the snapshot revert resets the data. Doing so would make the process of obtaining code coverage unfeasibly slow.
Instead, we decided to build our own code coverage measurement on top of the existing instrumentation. For this purpose, we added a new AFL++ instrumentation type that instruments all basic blocks and then creates a second, permanent trace buffer in AFL++ that accumulates the coverage of the regular trace buffer. Finally, we create a third buffer called the pcmap which maps every entry in the trace buffer to an address in the binary that can later be resolved to a source code location using debug information. As this information is contained in the AFL++ runtime, we need to obtain it within our custom Nyx agent and write it out to the host. The same holds for module information that denotes at which addresses Firefox modules were loaded. By combining these three sources of information, we can map the progress of Nyx fuzzing onto actual source code. We also built additional tooling to turn this basic block coverage into line-based coverage using information from a gcov build². As a result, we can generate metrics like percentage of code covered to evaluate the overall effectiveness of snapshot-based fuzzing.
Conclusion
While snapshot fuzzing is a rather complex technology with many moving parts, it allows us to effectively stress code regions of the browser that would otherwise remain beyond the capabilities of traditional fuzzing techniques, but are critical for providing adequate security guarantees. We are happy to report that this new fuzzing technology is becoming the norm and is now an essential part of our security testing strategy. We would like to thank the authors of Nyx and AFL++ for making this technology available and hope that our combined efforts will help others to adapt snapshot fuzzing for their projects.
¹ Firefox runs many Continuous Integration tests to ensure every functionality of the browser is automatically tested.
² Unfortunately, gcov and debug information deviate in some cases, so the result is not a 100% accurate mapping yet and can’t be seamlessly merged with other gcov data. This could likely be improved using LLVM annotations for additional basic block information.
In the coming months, we will experiment with providing easy access to optional AI services in Nightly to improve productivity as you browse. This work is part of our improvements to multitasking and cross-referencing in the sidebar, and we are committed to following the principles of user choice, agency, and privacy as we bring AI-powered enhancements to Firefox. To start, this experiment will only be available to Nightly users, and the AI functionality will be entirely optional. It’s there in case it’s helpful, but it is not built into any core functionality.
In the first experiment that you can try out this week, you will be able to:
Add a chatbot of your choice to the sidebar, so you can quickly access it as you browse.
Select and send text from webpages to:
Summarize the excerpt and make it easier to scan and understand at a glance.
Simplify language. We find this feature handy for answering the typical kids’ “why” questions.
Ask the chatbot to test your knowledge and memory of the excerpt.
Select the text you want to summarize
To activate the experience:
Go to Settings > Firefox Labs and turn the AI Chatbot Integration experiment on.
Choose your preferred chatbot from this list of providers:
ChatGPT
Google Gemini
HuggingChat
Le Chat Mistral
Then, as you browse, select any text, right-click it, and choose the Ask chatbot option to send the text, page title, and prompt to your provider. If you want to keep permanent access to the sidebar, click Customize toolbar in the toolbar right-click menu, and drag the sidebar icon to your toolbar.
We believe providing choice in AI services is important for many reasons. First, you should be able to choose the service that works best for you, and not be locked into a single provider. Second, all of these models are still being developed and improved. None are perfect, and they’re each good at some things and not at others. This gives you an opportunity to experiment with many services to find the one that’s most helpful for whatever you’re trying to accomplish. AI is an ingredient that can make your experience better. It doesn’t need to replace the tools you already know and love.
We will continue to improve our AI services experiment before making it available in our beta and release channels, and we welcome your feedback on how to make it more useful. If you have suggestions for improving the feature and feedback on what custom prompts work best for you, please share your thoughts in this Connect post.
Nightly can be configured by advanced testers to use custom prompts and any compatible chatbot, such as llamafile (discord), which runs on-device open models, including open-source ones. We are excited for the community to share interesting prompts, chatbots, and models as we make this a better user experience. We are also looking at how we can provide an easy-to-set-up option for a private, fully local chatbot as an alternative to using third-party providers.
and that they’re crawling from three different IP addresses with three different user agent strings, which look like normal browsers.
The test I did: I have some pages on this site that are not linked to from anywhere, so tested to see if this company would crawl one. (Mostly just random stuff that I have shared with friends but not blogged.)
My perplexity.ai query:
Can you explain how to play the board game [game name] which is covered by the ruleset at [URL]?
and that URL (which gets a couple of hits on game nights, that’s it) was immediately visted by not one, not two, but three different IP addresses.
44.221.181.252 “Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36”
45.56.133.241 “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36”
134.73.83.233 “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36”
Why three? The first reason I can think of is to try to evade a block, but really? Any better explanations?
This blog post proposes adding a third trait, Claim, that would live alongside Copy and Clone. The goal of this trait is to improve Rust’s existing split, where types are categorized as either Copy (for “plain old data”1 that is safe to memcpy) and Clone (for types that require executing custom code or which have destructors). This split has served Rust fairly well but also has some shortcomings that we’ve seen over time, including maintenance hazards, performance footguns, and (at times quite significant) ergonomic pain and user confusion.
TL;DR
The proposal in this blog post has three phases:
Adding a new Claim trait that refines Clone to identify “cheap, infallible, and transparent” clones (see below for the definition, but it explicitly excludes allocation). Explicit calls to x.claim() are therefore known to be cheap and easily distinguished from calls to x.clone(), which may not be. This makes code easier to understand and addresses existing maintenance hazards (obviously we can bikeshed the name).
Modifying the borrow checker to insert calls to claim() when using a value from a place that will be used later. So given e.g. a variable y: Rc<Vec<u32>>, an assignment like x = y would be transformed to x = y.claim() if y is used again later. This addresses the ergonomic pain and user confusion of reference-counted values in rust today, especially in connection with closures and async blocks.
Finally, disconnect Copy from “moves” altogether, first with warnings (in the current edition) and then errors (in Rust 2027). In short, x = y would move y unless y: Claim. Most Copy types would also be Claim, so this is largely backwards compatible, but it would let us rule out cases like y: [u8; 1024] and also extend Copy to types like Cell<u32> or iterators without the risk of introducing subtle bugs.
For some code, automatically calling Claim may be undesirable. For example, some data structure definitions track reference count increments closely. I propose to address this case by creating a “allow-by-default” automatic-claim lint that crates or modules can opt-into so that all “claims” can be made explicit. This is more-or-less the profile pattern, although I think it’s notable here that the set of crates which would want “auto-claim” do not necessarily fall into neat categories, as I will discuss.
Step 1: Introducing an explicit Claim trait
Quick, reading this code, can you tell me anything about it’s performance characteristics?
tokio::spawn({// Clone `map` and store it into another variable
// named `map`. This new variable shadows the original.
// We can now write code that uses `map` and then go on
// using the original afterwards.
letmap=map.clone();asyncmove{/* code using map */}});/* more code using map */
Short answer: no, you can’t, not without knowing the type of map. The call to map.clone() may just be cloning a large map or incrementing a reference count, you can’t tell.
One-clone-fits-all creates a maintenance hazard
When you’re in the midst of writing code, you tend to have a good idea whether a given value is “cheap to clone” or “expensive”. But this property can change over the lifetime of the code. Maybe map starts out as an Rc<HashMap<K, V>> but is later refactored to HashMap<K, V>. A call to map.clone() will still compile but with very different performance characteristics.
In fact, clone can have an effect on the program’s semantics as well. Imagine you have a variable c: Rc<Cell<u32>> and a call c.clone(). Currently this creates another handle to the same underlying cell. But if you refactor c to Cell<u32>, that call to c.clone() is now creating an independent cell. Argh. (We’ll see this theme, of the importance of distinguishing interior mutability, come up again later.)
Proposal: an explicit Claim trait distinguishing “cheap, infallible, transparent” clones
Now imagine we introduced a new trait Claim. This would be a subtrait of Clonethat indicates that cloning is:
Cheap: Claiming should complete in O(1) time and avoid copying more than a few cache lines (64-256 bytes on current arhictectures).
Infallible: Claim should not encounter failures, even panics or aborts, under any circumstances. Memory allocation is not allowed, as it can abort if memory is exhausted.
Transparent: The old and new value should behave the same with respect to their public API.
Now when I see code calling map.claim(), even without knowing what the type of map is, I can be reasonably confident that this is a “cheap clone”. Moreover, if my code is refactored so that map is no longer ref-counted, I will start to get compilation errors, letting me decide whether I want to clone here (potentially expensive) or find some other solution.
Step 2: Claiming values in assignments
In Rust today, values are moved when accessed unless their type implement the Copy trait. This means (among other things) that given a ref-counted map: Rc<HashMap<K, V>>, using the value map will mean that I can’t use map anymore. So e.g. if I do some_operation(map), then gives my handle to some_operation, preventing me from using it again.
Not all memcopies should be ‘quiet’
The intention of this rule is that something as simple as x = y should correspond to a simple operation at runtime (a memcpy, specifically) rather than something extensible. That, I think, is laudable. And yet the current rule in practice has some issues:
First, x = y can still result in surprising things happening at runtime. If y: [u8; 1024], for example, then a few simple calls like process1(y); process2(y); can easily copy large amounts of data (you probably meant to pass that by reference).
Second, seeing x = y.clone() (or even x = y.claim()) is visual clutter, distracting the reader from what’s really going on. In most applications, incrementing ref counts is simply not that interesting that it needs to be called out so explicitly.
Some things that should implement Copy do not
There’s a more subtle problem: the current rule means adding Copy impls can create correctness hazards. For example, many iterator types like std::ops::Range<u32> and std::vec::Iter<u32> could well be Copy, in the sense that they are safe to memcpy. And that would be cool, because you could put them in a Cell and then use get/set to manipulate them. But we don’t implement Copy for those types because it would introduce a subtle footgun:
letmutiter0=vec.iter();letmutiter1=iter0;iter1.next();// does not effect `iter0`
Whether this is surprising or not depends on how well you know Rust – but definitely it would be clearer if you had to call clone explicitly:
The clone/copy rules interact very poorly with closures
The biggest source of confusion when it comes to clone/copy, however, is not about assignments like x = y but rather closures and async blocks. Combining ref-counted values with closures is a big stumbling block for new users. This has been true as long as I can remember. Here for example is a 2014 talk at Strangeloop in which the speaker devotes considerable time to the “accidental complexity” (their words, but I agree) they encountered navigating cloning and closures (and, I will note, how the term clone is misleading because it doesn’t mean a deep clone). I’m sorry to say that the situation they describe hasn’t really improved much since then. And, bear in mind, this speaker is a skilled programmer. Now imagine a novice trying to navigate this. Oh boy.
But it’s not just beginners who struggle! In fact, there isn’t really a convenient way to manage the problem of having to clone a copy of a ref-counted item for a closure’s use. At the RustNL unconf, Jonathan Kelley, who heads up the Dioxus Labs, described how at CloudFlare codebase they spent significant time trying to find the most ergonomic way to thread context (and these are not Rust novices).
In that setting, they had a master context object cx that had a number of subsystems, each of which was ref-counted. Before launching a new task, they would handle out handles to the subsystems that task required (they didn’t want every task to hold on to the entire context). They ultimately landed on a setup like this, which is still pretty painful:
What I propose is to modify the borrow checker to automatically invoke claim as needed. So e.g. an expression like x = y would be automatically converted to x = y.claim() if y will be used again later. And closures that capture variables in their environment would respect auto-claim as well, so move || process(y) would become { let y = y.claim(); move || process(y) } if y were used again later.
Autoclaim would not apply to the last use of a variable. So x = y only introduces a call to claim if it is needed to prevent an error. This avoids unnecessary reference counting.
Naturally, if the type of y doesn’t implement Claim, we would give a suitable error explaining that this is a move and the user should insert a call to clone if they want to make a cloned value.
Support opt-out with an allow-by-default lint
There is definitely some code that benefits from having the distinction between moving an existing handle and claiming a new one made explicit. For these cases, what I think we should do is add an “allow-by-default” automatic-claim lint that triggers whenever the compiler inserts a call to claim on a type that is not Copy. This is a signal that user-supplied code is running.
To aid in discovery, I would consider a automatic-operations lint group for these kind of “almost always useful, but sometimes not” conveniences; effectively adopting the profile pattern I floated at one point, but just by making it a lint group. Crates could then add automatic-operations = 'deny" (bikeshed needed) in the [lints] section of their Cargo.toml.
Step 3. Stop using Copy to control moves
Adding “autoclaim” addresses the ergonomic issues around having to call clone, but it still means that anything which is Copy can be, well, copied. As noted before that implies performance footguns ([u8;1024] is probably not something to be copied lightly) and correctness hazards (neither is an iterator).
The real goal should be to disconnect “can be memcopied” and “can be automatically copied”4. Once we have “autoclaim”, we can do that, thanks to the magic of lints and editions:
In Rust 2024 and before, we warn when x = y copies a value that is Copy but not Claim.
In the next Rust edition (Rust 2027, presumably), we make it a hard error so that the rule is just tied to Claim trait.
At codegen time, I would still expect us to guarantee that x = y will memcpy and will not invoke y.claim(), since technically the Clone impl may not be the same behavior; it’d be nice if we could extend this guarantee to any call to clone, but I don’t know how to do that, and it’s a separate problem. Furthermore, the automatic_claims lint would only apply to types that don’t implement Copy.5
Frequently asked questions
All right, I’ve laid out the proposal, let me dive into some of the questions that usually come up.
Are you ??!@$!$! nuts???
I mean, maybe? The Copy/Clone split has been a part of Rust for a long time6. But from what I can see in real codebases and daily life, the impact of this change would be a net-positive all around:
For most code, they get less clutter and less confusing error messages but the same great Rust taste (i.e., no impact on reliability or performance).
Where desired, projects can enable the lint (declaring that they care about performance as a side benefit). Furthermore, they can distinguish calls to claim (cheap, infallible, transparent) from calls to clone (anything goes).
What’s not to like?
What kind of code would #[deny(automatic_claims)]?
That’s actually an interesting question! At first I thought this would correspond to the “high-level, business-logic-oriented code” vs “low-level systems software” distinction, but I am no longer convinced.
For example, I spoke with someone from Rust For Linux who felt that autoclaim would be useful, and it doesn’t get more low-level than that! Their basic constraint is that they want to track carefully where memory allocation and other fallible operations occur, and incrementing a reference count is fine.
I think the real answer is “I’m not entirely sure”, we have to wait and see! I suspect it will be a fairly small, specialized set of projects. This is part of why I this this is a good idea.
Well my code definitely wants to track when ref-counts are incremented!
I totally get that! And in fact I think this proposal actually helps your code:
By setting #![deny(automatic_claims)], you declare up front the fact that reference counts are something you track carefully. OK, I admit not everything will consider this a pro. Regardless, it’s a 1-time setup cost.
By distinguishing claim from clone, your project avoids surprising performance footguns (this seems inarguably good).
In the next edition, when we no longer make Copy implicitly copy, you further avoid the footguns associated with that (also inarguably good).
Ooh, deep cut! RFC 936 was a proposal to split Pod (memcopyable values) from Copy (implicitly memcopyable values). At the time, we decided not to do this.7 I am even the one who summarized the reasons. The short version is that we felt it better to have a single trait and lints.
I am definitely offering another alternative aiming at the same problem identified by the RFC. I don’t think this means we made the wrong decision at the time. The problem was real, but the proposed solutions were not worth it. This proposal solves the same problems and more, and it has the benefit of ~10 years of experience.8 (Also, it’s worth pointing out that this RFC came two months before 1.0, and I definitely feel to avoid derailing 1.0 with last minute changes – stability without stagnation!)
Doesn’t having these “profile lints” split Rust?
A good question. Certainly on a technical level, there is nothing new here. We’ve had lints since forever, and we’ve seen that many projects use them in different ways (e.g., customized clippy levels or even – like the linux kernel – a dedicated custom linter). An important invariant is that lints define “subsets” of Rust, they don’t change it. Any given piece of code that compiles always means the same thing.
That said, the profile patterndoes lower the cost to adding syntactic sugar, and I see a “slippery slope” here. I don’t want Rust to fundamentally change its character. We should still be aiming at our core constituency of programs that prioritize performance, reliability, and long-term maintenance.
How will we judge when an ergonomic change is “worth it”?
I think we should write up some design axioms. But it turns out we already have a first draft! Some years back Aaron Turon wrote an astute analysis in the “ergonomics initiative” blog post. He identified three axes to consider:
Applicability. Where are you allowed to elide implied information? Is there any heads-up that this might be happening?
Power. What influence does the elided information have? Can it radically change program behavior or its types?
Context-dependence. How much of do you have to know about the rest of the code to know what is being implied, i.e. how elided details will be filled in? Is there always a clear place to look?
Aaron concluded that "implicit features should balance these three dimensions. If a feature is large in one of the dimensions, it’s best to strongly limit it in the other two." In the case of autoclaim, the applicability is high (could happen a lot with no heads up) and the context dependence is medium-to-large (you have to know the types of things and traits they implement). We should therefore limit power, and this is why we put clear guidelines on who should implement Claim. And of course for the cases where that doesn’t suffice, the lint can limit the applicability to zero.
I like this analysis. I also want us to consider “who will want to opt-out and why” and see if there are simple steps (e.g., ruling out allocation) we can take which will minimize that while retaining the feature’s overall usefulness.
What about explicit closure autoclaim syntax?
In a recent lang team meeting Josh raised the idea of annotating closures (and presumably async blocks) with some form of syntax that means “they will auto-capture things they capture”. I find the concept appealing because I like having an explicit version of automatic syntax; also, projects that deny automatic_claim should have a lightweight alternative for cases where they want to be more explicit. However, I’ve not seen any actual specific proposal and I can’t think of one myself that seems to carry its weight. So I guess I’d say “sure, I like it, but I would want it in addition to what is in this blog post, not instead of”.
What about explicit closure capture clauses?
Ah, good question! It’s almost like you read my mind! I was going to add to the previous question that I do like the idea of having some syntax for “explicit capture clauses” on closures.
Today, we just have || $body (which implicitly captures paths in $body in some mode) and move || $body (which implicitly captures paths in $body by value).
Some years ago I wrote a draft RFC in a hackmd that I still mostly like (I’d want to revisit the details). The idea was to expand move to let it be more explicit about what is captured. So move(a, b) || $body would capture onlya and b by value (and error if $body references other variables). But move(&a, b) || $body would capture a = &a. And move(a.claim(), b) || $body would capture a = a.claim().
This is really attacking a different problem, the fact that closure captures have no explicit form, but it also gives a canonical, lighterweight pattern for “claiming” values from the surrounding context.
How did you come up with the name Claim?
I thoughtJonathan Kelley suggested it to me, but reviewing my notes I see he suggested Capture. Well, that’s a good name too. Maybe even a better one! I’ve already written this whole damn blog post using the name Claim, so I’m not going to go change it now. But I’d expect a proper bikeshed before taking any real action.
I love Wikipedia (of course), but using the name passive data structure (which I have never heard before) instead of plain old data feels very… well, very Wikipedia. ↩︎
In point of fact, I would prefer if we could define the claim method as “final”, meaning that it cannot be overridden by implementations, so that we would have a guarantee that x.claim() and x.clone() are identical. You can do this somewhat awkwardly by defining claim in an extension trait, like so, but it’d be a bit embarassing to have that in the standard library. ↩︎
Interestingly, when I read that snippet, I had a moment where I thought “maybe it should be async move { do_something(cx.io.claim(), ...) }?”. But of course that won’t work, that would be doing the claim in the future, whereas we want to do it before. But it really looks like it should work, and it’s good evidence for how non-obvious this can be. ↩︎
In effect I am proposing to revisit the decision we made in RFC 936, way back when. Actually, I have more thoughts on this, I’ll leave them to a FAQ! ↩︎
Oooh, that gives me an idea. It would be nice if in addition to writing x.claim() one could write x.copy() (similar to iter.copied()) to explicitly indicate that you are doing a memcpy. Then the compiler rule is basicaly that it will insert either x.claim() or x.copy() as appropriate for types that implement Claim. ↩︎
I’ve noticed I’m often more willing to revisit long-standing design decisions than others I talk to. I think it comes from having been present when the decisions were made. I know most of them were close calls and often began with “let’s try this for a while and see how it feels…”. Well, I think it comes from that and a certain predilection for recklessness. 🤘 ↩︎
This RFC is so old it predates rfcbot! Look how informal that comment was. Astounding. ↩︎
This seems to reflect the best and worst of Rust decision making. The best because autoclaim represents (to my mind) a nice “third way” in between two extreme alternatives. The worst because the rough design for autoclaim has been clear for years but it sometimes takes a long time for us to actually act on things. Perhaps that’s just the nature of the beast, though. ↩︎
Igalia has been contributing to the web platform implementations of different web engines for a long time.
One of our goals is ensuring that these implementations are interoperable, by relying on various web standards and web platform tests.
In July 2023, I happily joined a project that focuses on this goal, and I worked more specifically on the Gecko web engine.
One year later, three new features I contributed to are being shipped in Firefox.
In this series of blog posts, I’ll give an overview of those features (namely registered custom properties, content visibility, and fetch priority) and my journey to make them “ride the train” as Mozilla people say.
Let’s start with registered custom properties, an enhancement of traditional CSS variables.
Registered custom properties
You may already be familiar with CSS variables, these “dash dash” names that facilitate the maintenance of a large web site by allowing author-defined CSS properties.
In the example below, the :root selector defines a variable --main-theme-color with value “blue”, which is used for the style applied to other elements via the var() CSS function.
As you can see, this makes the usage of the main theme color in different places more readable and makes customizing that color much easier.
In browsers supporting CSS variables, you should see a frame containing the text “Loading” and a progress bar, all of these components being blue:
Loading...
Having such CSS variables available is already nice, but they are lacking some features available to native CSS properties…
For example, there is (almost) no syntax checking on specified values, they are always inherited, and their initial value is always the guaranteed invalid value.
In order to improve on that situation, the CSS Properties and Values specification provides some APIs to register custom properties with further characteristics:
An accepted syntax for the property; for example, igalia | <url> | <integer>+ means either the custom identifier “igalia”, or a URL, or a space-separated list of integers.
Whether the property is inherited or non-inherited.
An initial value.
Custom properties can be registered via CSS or via a JS API, and these ways are equivalent.
For example, to register --main-theme-color as a non-inherited color with initial value blue:
By having custom properties registered with a specific syntax, we open up the possibility of interpolating between two values of the properties when performing an animation.
Consider the following example, where the width of the animated div depends on the custom property --my-length.
Defining this property as a length allows browsers to interpolate it continuously between 10px and 200px when it is animated:
With non-registered custom properties, we can instead only animate discretely; --my-length would suddenly jump from 10px to 200px halfway through the duration of the animation, which is generally not what is desired for lengths.
Custom properties in the cascade
If you check the Interop 2023 Dashboard for custom properties, you may notice that interoperability was really bad at the beginning of the year, and this was mainly due to Firefox’s low score.
Consequently, when I joined the project, I was asked to help with improving that situation.
While the two registration methods previously mentioned had already been implemented, the main issue was that the CSS cascade was always treating custom properties as inherited and initialized with the guaranteed invalid value.
This is indeed correct for unregistered custom properties, but it’s generally incorrect for registered custom properties!
In bug 1840478, bug 1855887, and others, I made registered custom properties work properly in the cascade, including non-inherited properties and registered initial values.
But in the past, with the previous assumptions around inheritance and initial values, it was possible to store the computed values of custom properties on an element as a “cheap” map, considering only the properties actually specified on the element or an ancestor and (in most cases) only taking shallow copies of the parent’s map.
As a result, when generalizing the cascade for registered custom properties, I had to be careful to avoid introducing performance regressions for existing content.
Custom properties in animations
Another area where the situation was pretty bad was animations.
Not only was Firefox unable to interpolate registered custom properties between two values — one of the main motivations for the new spec — but it was actually unable to animate custom properties at all!
The main problem was that the existing animation code referred to CSS properties using an enum nsCSSPropertyID, with all custom properties represented by the single value nsCSSPropertyID::eCSSPropertyExtra_variable.
To make this work for custom properties, I had to essentially replace that value with a structure containing the nsCSSPropertyID and the name of the custom properties.
I uploaded patches to bug 1846516 to perform that change throughout the whole codebase, and with a few more tweaks, I was able to make registered custom properties animate discretely, but my patches still needed some polish before they could be reviewed.
I had to move onto other tasks, but fortunately, some Mozilla folks were kind enough to take over this task, and more generally, complete the work on registered custom properties!
Conclusion
This was an interesting task to work on, and because a lot of the work happened in Stylo, the CSS engine shared by Servo and Gecko, I also had the opportunity to train more on the Rust programming language.
Thanks to help from folks at Mozilla, we were able to get excellent progress on registered custom properties in Firefox in 2023, and this feature is expected to ship in Firefox 128!
As I said, I’ve since moved onto other tasks, which I’ll describe in subsequent blog posts in this series.
Stay tuned for content-visibility, enabling interesting layout optimizations for web pages.
Imagine for a moment if we treated our laundry the same way we treat our email. It might look something like this: At least ten times an hour, we’d look in the dryer, sigh at the mix of wet and dry clothes, wonder where the shirt we needed was, and then close the dryer door again without emptying a thing. Laura Mae Martin, author of Uptime: A Practical Guide to Personal Productivity and Wellbeing, has a better approach. Treat your email like you would ideally treat your laundry.
How do we put this metaphor to work in our inboxes? Martin has some steps for getting the most out of this analogy, and the first is to set aside a specific time in your day to tackle your inbox. This is the email equivalent of emptying your dryer, not just looking in it, and sorting the clothes into baskets. You’re already setting future you up for a better day with this first step!
The Process
At this set time, you’ll have a first pass at everything in your inbox, or as much as you can, sorting your messages into one of four ‘baskets’ – Respond, To Read, Revisit, and Relax (aka, the archive where the email lives once you’ve acted on it from a basket, and the trash for deleted emails). Acting on those messages comes after the sorting is done. So instead of ‘touching’ your email a dozen times with your attention, you only touch it twice: sorting it, and acting on it.
Let’s discuss those first three baskets in a little more detail.
First, the ‘Respond’ basket is for emails that require a response from you, which need you and your time to complete. Next, the ‘To Read’ basket is for emails that you’d like to read for informative purposes, but don’t require a response. Finally, the ‘Revisit’ basket is for emails where you need to respond but can’t right now because you’re waiting for the appropriate time, a response from someone, etc.
Here’s more info on how treating your email like laundry looks in your inbox. You don’t have separate dryers for work clothes and personal clothes, so ideally you want your multiple inboxes in one place, like Thunderbird’s Unified Folders view. The baskets (Respond, To Read, Revisit) are labels, tags, or folders. Unread messages should not be in the same place with sorted email; that’s like putting in wet clothes with your nice, dry laundry!
Baskets and Batch Tasking
You might be wondering “why not just use this time to sort AND respond to messages?” The answer is that this kind of multitasking saps your focus, thanks to something called attention residue. Hopping between sorting and replying – and increasing the chance of falling down attention rabbit holes doing the latter – makes attention residue thicker, stickier, and ultimately harder to shake. Batch tasking, or putting related tasks together for longer stretches of time, keeps potentially distracting tasks like email in check. So, sorting is one batch, responding is another, etc. No matter how much you’re tempted, don’t mix the tasks!
Putting It Into Practice
You know why you should treat your email like laundry, and you know the process. Here’s some steps for day one and beyond to make this efficient approach a habit.
One-time Setup:
Put active emails in your inbox in one of the first three baskets (Respond, To Read, Revisit)
If email doesn’t need one of these baskets, archive or delete them
Daily Tasks
Remember the 4 Baskets are tasks to be done separately
Pick a time to sort your email each day – at least once, and hopefully no more than two or three more times. Remember, this is time ONLY to sort emails into your baskets.
Give future you the gift of a sorted inbox
Find and schedule time during the day to deal with the baskets – but only one basket at a time! Have slots just for responding, reading, or checking on the progress of your Revisit emails. Think of your energy flow during the day, and assign your most mentally strenuous boxes for your peak energy times.
One Last Fold
Thanks for joining us in our continuing journey to turn our inboxes, calendars, and tasks lists into inspiring productivity tools instead of burdens. We know opening our inboxes can sometimes feel overwhelming, which makes it easier for them to steal our focus and our time. But if you treat your email like laundry, this chore can help make your inbox manageable and put you in control of it, instead of the other way around.
We’re excited to try this method, and we hope you are too. We’re also eager to try this advice with our actual laundry. Watch out, inboxes and floor wardrobes. We’re coming for you!
we should be at parity with the previous version, so if you could enable devtools.debugger.features.codemirror-next and report any issue you see, that would be great!
By the way, we want to enable devtools.debugger.features.windowless-service-workers by default, so you can debug Service Workers directly in the debugger (without going to about:debugging). We’re still looking for feedback, so if you’re working with Service Workers, please foxfood this pref and report any issue you encountered 🙂
As part of the cross-browser compatibility improvements for Manifest Version 3 extensions landed in Firefox 128:
Content scripts can now be executed in the webpage global using the execution world MAIN (which is now supported by the scripting API and content scripts declared in the manifest.json file) and not be blocked by a strict webpage CSP (Bug 1736575)
NOTE: content scripts executed in the MAIN world do not have access to any WebExtensions API.
Added support for domainType (“firstParty”, “thirdParty”) DNR rule conditions (Bug 1797408)
Performance related improvement on evaluating DNR rules using requestDomains and initiatorDomains conditions (Bug 1853569)
Event pages will not be suspended if API calls that require user actions (e.g. permissions.request API calls) are still pending (Bug 1844044 / Bug 1874406)
Event pages persisted listeners removed through the removeListener method will stay persisted and can respawn the event page after it has been suspended (Bug 1869125)
NOTE: API events persisted listeners will instead be completely removed (not persisted anymore and not respawning the event page anymore) if the extension event page scripts do not add the listeners again (by not calling addListener) when the event page is started again.
Developer Tools
DevTools
Sebastian Zartner [:sebo] added warning when properties only applying to replaced elements are used on non-replaced elements (#1583903), and when column-span is used on elements outside of multi-column containers (#1848705)
Thanks to Valentin Gosu [:valentin] for fixing an issue that failing service worker requests when Responsive Design Mode was enabled (#1885308)
Thanks James Teh [:Jamie] for fixing an accessibility issue in the DevTools accessibility tree (#1898661)
Alex fixed an issue that could prevent DevTools to open (#1898490)
Julian fixed an issue that was preventing DevTools to consume sourcemaps files when they required credentials (#1899389)
Nicolas tweaked the filters button colors in Console and Netmonitor so their states should be more explicit (#1590432)
Filter to your hearts content!
Filter to your hearts content! In dark mode!
Nicolas added @property rules (MDN) information in the var() tooltip (#1899489)
And we now indicate when custom property declaration are invalid when their value does not match registered custom property definition (#1866712)
Nicolas added support for @starting-style rules (MDN) in the Rules view (#1892192)
Nicolas added support for @scope rules (MDN) in the Rules view (#1893593)
WebDriver BiDi
External:
Thanks to James Hendry who removed the deprecated desiredCapabilities and requiredCapabilities from geckodriver (#1823907)
Related to that, Henrik updated the default value of the remote.active-protocols preference to “1”, which means that CDP is now disabled by default (#1882089)
Henrik implemented support for the http and bidi flags on the WebDriver Session, which allows to know if a specific session is using classic, bidi or both. (#1884090 and #1898719)
Julian added support for several arguments of the network.continueRequest command. Clients can now update headers, cookies, method and post body of an intercepted request. This also fixes a bug where intercepted requests in the beforeRequestSent phase could still be sent to the server (#1850680)
Sasha fixed the order in which we emit network events in case of redirects. Our behavior now correctly matches the specifications (#1879580)
Sasha implemented the userContext argument for the permissions.setPermission command which allows to update a permission only for a specific user context (#1894217)
Henrik improved the way we handle error pages in the navigation helpers used by WebDriver BiDi (#1878690)
Sasha updated the exception thrown when the input.setFiles command is used with a file which doesn’t exist. (#1887644)
Sasha updated our vendored version of puppeteer to v22.9.0. As usual we try to keep up to date with Puppeteer releases to benefit from their latest test changes and improvements in BiDi support. (#1897183)
Lint, Docs and Workflow
Some more files (in toolkit/) have been transitioned to use the .worker.(m)js file name system to automatically pick up the worker environment for ESLint.
We’re almost at the point where we have end-to-end backup and recovery in a testable spot! As a reminder, this is not yet production ready, and might change dramatically before it’s ready to be used.
Initial work on the toolkit profile service and profile database is in review. Engineering work is pausing for two weeks to free up engineers for some Review Checker work.
Search and Navigation
HTTPS trimming in the address bar
Marco fixed a bug related to displaying the scheme for RTL (right-to-left) domains (1862404)
Google account signed-in status
Stephanie landed patches enabling telemetry indicating whether the client was signed in to a Google account at the time of a SERP load (1877494, 1892332)
Search Config v2
Mark & Mandy have been hard at work on the new search config over the past several months, and it is now permanently enabled (1900638)
Standard8 resolved an incident where one of our Glean pings wasn’t being sent due to the new search config (1901057, 1901208)
Bug fixes, clean up and intermittents
We completed a significant number of one-off bug fixes, intermittent test failure fixes and code clean up. Special shout out to patches from Yazan, our team’s new co-op student and to Moritz, our team’s new student worker.
It appears that some of the issues observed by me and others with Chromium on Fedora ppc64le may in fact be due to an incomplete patch set, which is now available on Solid Silicon's Gitlab. If your distro doesn't support this, now you have an upstream to point them at or build your own. They include the Ungoogled changes as well, even though I retain my philosophical objections to Chromium, and still use Firefox personally (I've got to get back on the horse and resume maintaining my personal builds now that I've got Plasma 6 back running on Xorg again).
Oh, yeah, it really is that Solid Silicon. You can make your own speculations from the commit log, though regardless of whether Solid Silicon is truly a separate concern or a Raptor subsidiary, it wouldn't be surprising that Raptor resources are assisting since they've kind of bet the store on the S1.
Timothy Pearson's comments in the Electron Github suggest that Google has been pretty resistant to incorporating support for architectures outside of their core platforms. This is not a wholly unreasonable position on Google's part but it's not a particularly charitable one, and unlike Mozilla, the Chrome team doesn't really have the concept of a tier-3 build nor any motivation to. That kind of behaviour is all the more reason not to encourage browser monocultures because it's not just the layout engine that causes vendor lock-in. Fortunately V8, the JavaScript engine, is maintained separately, and reportedly has been more accommodating presumably because of things like Node.js on IBM hardware (even IBM i via PASE!).
Mozilla is much more accepting of this as long as regressions aren't introduced. This is why TenFourFox patches were largely not upstreamed since they would potentially cause problems with Cocoa widgets in later versions of macOS, though what patches were generally applicable I would do so. The main reason I'm still maintaining the Firefox ppc64le JIT patches outside is because I still can't solve these recent startup crashes deep within Wasm code, which largely limits me to Baseline Compiler and thus is not suitable for loading into the tree yet (we'd have to also upstream pref changes that would adversely affect tier-1 until this is fixed). I still intend to pull these patches up to the next ESR, especially since Github is glacially slow now without a JIT and it's affecting my personal ability to do other tasks. Maybe I should be working on something like rr for ppc64le at the same time because stepping through deeply layered code in gdb is a great way to go stark raving mad.
Developer Tools help developers write and debug websites on Firefox. This newsletter gives an overview of the work we’ve done as part of the Firefox 127 Nightly release cycle.
Performance project
If you’ve been reading us for a bit, you are now well aware that we’re focusing on performance for a few months to make our tools as fast as they can be.
We made displaying rules in the Inspector 5% faster for the common case, and even 600 times faster on pages with very large stylesheets (going from ~3 seconds to ~5 milliseconds in a page using Tailwind)! This was made possible by moving away from our DevTools-specific, JS-written, CSS lexer to a Rust-based implementation. In various places of the codebase, we need to know the different “parts” of a CSS selector, or a property declaration. To have a reliable way of analyzing a given CSS snippet, we use a CSS lexer which computes a sequence of tokens describing the different parts of the snippet. Since this tokenization is actually also done at the CSS engine level when a stylesheet is parsed, as described in the CSS Syntax Module Level 3 specification. We were trying to do the same thing as the engine, and given that we do have access to the engine machinery, it felt silly not sharing the same code. This performance project was a nice opportunity to integrate with the Rust-based implementation the engine is using and ditch our JS-implementation.
Oh my bugs
As temperatures rise in the Northern hemisphere, we’re entering bugs season, and unfortunately, our project isn’t immune to that. First, we identified and addressed a pretty severe race condition that could result in the toolbox not opening at all (#1898490). We also got reports of Debugger crashing (#1891699), as well as issues in the Console when displaying wasm stracktraces (#1888645). Hopefully everything is now working correctly.
If those could be thought of “killer bees” bugs, we also tackle some annoying “midge” bugs:
The Network panel could be missing requests made from iframes at the very end of their lifecycle, for example in the unload event (#1887852)
When using the node picker, you can hold the Shift key to be able to retrieve elements that are not receiving mouse events (e.g. having pointer-events: none declaration). When using this feature, our heuristic should now better pick the “deepest” element under the mouse (#1889500)
Did you know that you could nest @keyframes rule in other at-rules? In such case, we’re now properly detecting the rules, and displaying it in the Rules view, like non-nested keyframes rules (#1894603)
Firefox 125 added support for the Popover API, but it wasn’t possible to inspect their ::backdrop pseudo-element, it’s now fixed.
Finally, last year, on OSX, we changed the location for screeshots taken in DevTools, from Downloads to Pictures. This was confusing for some people as Firefox Screenshots still put them in the Downloads folder, so we reverted our change.
And that’s it for this months folks, Thank you for reading this and using our tools, see you in a few weeks for a new round of updates
What reminded me of that joke is all the surveillance advertising companies going on about how surveillance advertising is so good for small businesses. But if they have so much trouble telling small businesses and fraud apart, how can they know? Maybe surveillance ads are just better for fraud. The interesting comparison to make is not between a legit business at times they have surveillance advertising on or off, because the scammers competing to reach the same customers are leaving the surveillance ads on. IMHO you have to look from the customer side. If surveillance advertising helps legit companies reach people who can benefit from their products, then people who use ad blockers or privacy tools should be less happy with the stuff they buy.
Instead, people who installed ad blockers for a study turned out to be less likely to regret their recent purchases, and that’s surprising enough to be worth digging into. Maybe it’s not fraud, just drop-shippers. Lots of drop-shippers/social media advertisers are finding existing cheap products, marking them up, and selling using surveillance ads. It’s not illegal, but the people who click the ads end up paying more money for the same stuff. Maybe the reason that the ad blocker users are happier as shoppers is that they search out and buy, say, a $20 product for $20 instead of paying a drop-shipper $99? Or maybe ad blocker users are just making fewer but better thought out purchases?
Just some reading material, more later. I did mess with the CSS on this blog a little, so pages with code on them should look a little better on small screens even if you have to scroll horizontally to see the code.
Which top sites block AI crawlers?All in all, most sites I looked at don’t care to have their content used to train AI. (IMHO this will be a big issue with the Fediverse—currently the only way to pass a noai signal is to defederate. I made a FEP (fep-5e53) so will see what happens.)
Why First Party Data May Not Save Digital Advertising (This is why it’s going to be better to get real consent, later, from fewer people than bogus consent based on zero information about the brand or publisher.)
Economic Termites Are Everywhere[E]conomic termites…are instances of monopolization big enough to make investors a huge amount of money, but not noticeable enough for most of us. An individual termite isn’t big enough to matter, but the existence of a termite is extremely bad news, because it means there are others. Add enough of them up, and you get our modern economic experience.
Tesla may be in trouble, but other EVs are selling just fine (How much of this is the brand personality and how much is the problem that Teslas are expensive to insure? I think every car I have ever owned ended up costing a lot more in car insurance than its price.)
We need to rewild the internetFor California residents, GPC automates the request to “accept” or “reject” sales of your data, such as cookie-based tracking, on its websites. However, it isn’t yet supported by major default browsers like Chrome and Safari. Broad adoption will take time, but it’s a small step in changing real-world outcomes by driving antimonopoly practices deep into the standards stack — and it’s already being adopted elsewhere.
Last week marked two years of working on Firefox. For me, this was a return to the browser I fervently used in my early internet days (circa 2004–2011). I don’t recall exactly when I left, and whether it was abrupt or gradual, but at some point Firefox was out and Chrome was the browser on my screen. Looking back, I’m pretty sure it was notifications telling me Gmail would work better on Chrome that led me there. Oof.
I certainly wasn’t alone. The storied history of browsers (including not one, but two browser wars) is marked by intense competition and shifting landscapes. Starting around 2010–2011, as Chrome’s market share went up, Firefox’s went down.
A doorway to the internet
When I started working on Firefox, a colleague likened a browser to a doorway — you walk through several a day, but don’t think much about them. It’s a window to the internet, but it’s not the internet. It helps you search the web, but it’s not a search engine. It’s a universal product, but many struggle to describe it.
So what is it, then, and why am I so happy I get to spend my days thinking about it?
A browser is an enabler, facilitating online exploration, learning, work, communication, entertainment, shopping, and more. More technically, it renders web pages, uses code to display content, and provides navigation and organization tools that allow people to explore, interact with, and retrieve information on the web.
With use cases galore, there are challenges. It’s a product that needs to be good at many things.
To help our design, product and engineering stakeholders meet these challenges, the Firefox User Research team tackles topics including managing information in the browser (what’s your relationship to tabs?), privacy in the browser, when and how people choose browsers (if they choose at all), and why they stay or leave. Fascinating research topics feel endless in the browser world.
My introduction to browser users
For my first project at Mozilla, I conducted 17, hour-long, in-depth interviews with browser users. A formative introduction to how people think about and use browsers. When I look back on that study, I recall how much I learned about a product that I previously hadn’t given much thought to. Here I summarize some of those initial learnings.
Browser adoption on desktop vs mobile: Firefox is a browser that people opt-in to. Unlike other mainstream browsers, it doesn’t come pre-installed on devices. This means that users must actively choose Firefox, bypassing the default. While many people do this — close to 200 million monthly on Firefox — using the default is common, and even more so on mobile. When talking to users of various browsers, the sentiment that “I just use what came on the device” is particularly prevalent for mobile.
Why is this so? For one, people have different needs on their desktop and mobile browsers (e.g. conducting complex work vs quick searches), leading to different behaviors. The presence of stand-alone apps on mobile that help people accomplish some of the tasks they might have otherwise done in their browser (e.g. email, shopping) also differentiate the experience.
That’s not the whole story, though. Gatekeeping practices by large tech companies, such as self-preferencing and interoperability, play a role. These practices, which Europe’s Digital Markets Act and related remedies like browser choice screens aim to address, limit consumer choice and are especially potent on mobile. In my in-depth interviews, for example, I spoke with a devoted Firefox desktop user. When explaining to me why she used the default browser on her mobile phone, she held up her phone, pointing to the dock at the bottom of her home screen. She wanted quick access to her browser through this dock, and didn’t realize she could replace the default browser that came there with one of her choosing.
Online privacy dilemmas: Having worked on privacy and the protection of personal information in the past, I was keen to learn about users’ attitudes and behaviors towards online privacy. What were their stances? How did they protect themselves? My in-depth interviews revealed that attitudes and feelings range vastly: protective, indifferent, disempowered, resigned. And often, attitudes and values towards privacy don’t align with behaviors. In today’s online world, acting on your values can be hard.
The intention-action gap speaks to the many cases when our attitudes, values or goals are at odds with our behavior. While the draw of convenience and other tradeoffs are certainly at play in the online privacy gap, so too are deceptive digital designs that make it all too difficult to use the internet on your own terms. These include buried privacy settings, complex opt-out processes, and deceptive cookie banners.
Navigating online privacy risks can feel daunting and confusing — and for good reason. One participant in the interviews described it as something that she didn’t have the time or esoteric knowledge for, even though she cared about it:
“It’s so big and complicated for a user like me, you really have to put in the time to figure it out, to understand it. And I don’t have the time for that, I honestly don’t. But that doesn’t stop me from doing things online, because, how, if being online is such an important part of my day?”
On the browser side, the technical aspects of online privacy present a perennial challenge for communicating our protective measures to users. How do we communicate the safeguards we offer users in ways that are accessible and effective?
Browser recommendations: For a product that isn’t top of mind for most people, many are steered to their browsers by word of mouth and other types of recommendations. In fact, we consistently find that around one-third of our users report having recommended Firefox in the past month. That’s more people talking about browsers than I would have imagined.
The people I interviewed spoke about recommendations from family members (“Mom, you need to step up your browser game!” one participant recalled her son saying as he guided her to a new browser), tech-oriented friends, IT departments at work, computer repair shops, and online forums and other communities.
One factor behind personal recommendations is likely that most people are satisfied with their browser. Our quantitative user research team finds high levels of browser satisfaction among not only Firefox users, but the users of other popular browsers examined in their work.
Wrapping up
Coming back to Firefox involved a process of piecing together what had happened to the browser with the little fox. In doing so, I’ve learned a lot about what brings people to browsers, and away from them, and the constrained digital landscape in which these dynamics occur. The web has changed a great deal since Firefox 1.0 was released in 2004, but Mozilla’s goal of fostering an open and accessible internet remains constant.
Thank you for reviewing a draft of this post, Laura Lopez and Rosanne Scholl.
You might be scrolling through your morning news, checking email, or any other routine online moment when suddenly you notice a small winged beast slowly glide across your screen. It’s a challenge. A chance to earn more crystals. A fight to the finish, should you choose to accept the duel. Since you’re not super busy and battles only take a few seconds — and you sure could use more crystals to upgrade gear — you click the angry creature and next thing you know your Network Guardian (avatar) and opponent appear on floating battle stations exchanging blows. It’s a close contest, but soon your nemesis succumbs to his injuries. The thrill of victory is fleeting, though. Gotta get back to those emails.
Customize the skills, gear (and fashion!) of your own Network Guardian.
Dedalium is a novel game concept. There are a lot of browser games out there, but nothing quite like Dedalium, which turns the entire internet into a role-playing game, or RPG. You start by customizing the look and skills of your Network Guardian and then you’re ready to wait for battle invites to emerge; or you can go on the offensive and seek out challengers. Beyond battles, you’ll occasionally find crystals or loot boxes on the edges of your screen.
There’s also a solo Adventure mode featuring 100+ levels that lead to a final battle against the big boss Spamicus Wildpost, who has never been defeated since Dedalium’s beta launch last year.
“We’ve created something new and innovative,” says Dedalium co-creator Joel Corominas. “We call this concept ‘augmented web’ akin to augmented reality but within the web environment. While it may take time for players and browser users to fully appreciate, we strongly believe it will become a significant trend in the future. We are proud to have pioneered this concept and believe it adds a fun, interactive layer to web browsing.”
Dedalium is the debut title from Loycom Games, which Corominas co-founded in 2021 with his game development partner Adrián Quevedo. Loycom’s mission is to “gamify internet browsing.”
Still in beta, Dedalium is growing quickly. About 4,000 players currently engage with the game daily across various browsers. If you’re looking for an entirely unique browser gaming experience, Dedalium is definitely that. At first I was worried random game prompts would get annoying as I went about my business on the web, but to my delight I usually found myself eager to engage in a quick Dedalium detour. The game does a great job of never feeling intrusive. But even so, you can pause the game anytime and set specific websites as no-play zones.
If turning the entire web into an RPG sounds like a good time, give Dedalium a shot and good luck gathering those crystals!
Do you have an intriguing extension development story? Do tell! Maybe your story should appear on this blog. Contact us at amo-featured [at] mozilla [dot] org and let us know a bit about your extension development journey.
Welcome add-on developers! Below is the next installation in our series of community updates designed to provide clarity and transparency as we continue to deliver Manifest V3 related improvements with each new Firefox release.
The engineering team continues to build upon previous MV3 Chrome compatibility related work available in Firefox 126 with several additional items that landed in Firefox 127, which was released on June 11. Beginning in the 127 release, the following improvements have launched:
Customized keyboard shortcuts associated with the _execute_browser_action command for MV2 extensions will be automatically associated with the _execute_action command when migrating the same extension to MV3. This allows the custom keyboard shortcuts to keep functioning as expected from an end user perspective.
declarativeNetRequest getDynamicRules and getSessonRules API methods now accept the additional ruleIds filter as a parameter and the rule limits have been increased to match the limits enforced by other browsers.
The team will land more Chrome compatibility enhancements in Firefox 128 in addition to delivering other Manifest V3 improvements, at which time MV3 will be supported on Firefox for Android.
And to reiterate a couple important points we’ve communicated in our previous updates published in March and May:
The webRequest API is not on a deprecation path in Firefox
Mozilla has no plans to deprecate MV2
For more information on adopting MV3, please refer to our migration guide. If you have questions or feedback on our MV3 plans we would love to hear from you in the comments section below or if you prefer, drop us an email. Thanks for reading and happy coding!
The Rust team is happy to announce a new version of Rust, 1.79.0. Rust is a programming language empowering everyone to build reliable and efficient software.
If you have a previous version of Rust installed via rustup, you can get 1.79.0 with:
If you'd like to help us out by testing future releases, you might consider updating locally to use the beta channel (rustup default beta) or the nightly channel (rustup default nightly). Please report any bugs you might come across!
What's in 1.79.0 stable
Inline const expressions
const { ... } blocks are now stable in expression position, permitting
explicitly entering a const context without requiring extra declarations (e.g.,
defining const items or associated constants on a trait).
Unlike const items (const ITEM: ... = ...), inline consts are able to make
use of in-scope generics, and have their type inferred rather than written explicitly, making them particularly useful for inline code snippets. For example, a pattern like:
const EMPTY: Option<Vec<u8>> = None;
let foo = [EMPTY; 100];
can now be written like this:
let foo = [const { None }; 100];
Notably, this is also true of generic contexts, where previously a verbose trait declaration with an associated constant would be required:
Rust 1.79 stabilizes the associated item bounds syntax, which allows us to put
bounds in associated type position within other bounds, i.e.
T: Trait<Assoc: Bounds...>. This avoids the need to provide an extra,
explicit generic type just to constrain the associated type.
This feature allows specifying bounds in a few places that previously either
were not possible or imposed extra, unnecessary constraints on usage:
where clauses - in this position, this is equivalent to breaking up the bound into two (or more) where clauses. For example, where T: Trait<Assoc: Bound> is equivalent to where T: Trait, <T as Trait>::Assoc: Bound.
Supertraits - a bound specified via the new syntax is implied when the trait is used, unlike where clauses. Sample syntax: trait CopyIterator: Iterator<Item: Copy> {}.
Associated type item bounds - This allows constraining the nested rigid projections that are associated with a trait's associated types. e.g. trait Trait { type Assoc: Trait2<Assoc2: Copy>; }.
opaque type bounds (RPIT, TAIT) - This allows constraining associated types that are associated with the opaque type without having to name the opaque type. For example, impl Iterator<Item: Copy> defines an iterator whose item is Copy without having to actually name that item bound.
Temporaries which are immediately referenced in construction are now
automatically lifetime extended in match and if constructs. This has the
same behavior as lifetime extension for temporaries in block constructs.
For example:
let a = if true {
..;
&temp() // used to error, but now gets lifetime extended
} else {
..;
&temp() // used to error, but now gets lifetime extended
};
and
let a = match () {
_ => {
..;
&temp() // used to error, but now gets lifetime extended
}
};
are now consistent with prior behavior:
let a = {
..;
&temp() // lifetime is extended
};
This behavior is backwards compatible since these programs used to fail compilation.
Frame pointers enabled in standard library builds
The standard library distributed by the Rust project is now compiled with
-Cforce-frame-pointers=yes, enabling downstream users to more easily profile
their programs. Note that the standard library also continues to come up with
line-level debug info (e.g., DWARF), though that is stripped by default in Cargo's release profiles.
AI-specific laws are still in progress, and copyright cases are still making their way through the court system. I still don’t know if all the stuff I did to block AI training on a web site is going to be enforceable—it depends on how well web site Terms of Service hold up in court as contracts. But in the meantime we do have a tool that is already in place and tested. An Opt-Out Preference Signal like Global Privacy Control is a way to signal, in a legally enforceable way, that you opt out of the sale or sharing of your personal information.
GPC already protects residents of California, Colorado, Connecticut, and other states in the USA, and enforcement is coming on line in other jurisdications as well. Sounds like a useful tool, right? But there’s one missing piece. The GPC standard covers a signal sent from the client to the server. When you visit a site as a user, this is just fine. But when you need protection for a blog, a portfolio, or a profile page, your personal info is on a server, but the company looking to exploit it is running a client—a crawler or scraper. That’s where we need to borrow some basics from the methods for blocking AI training on a web site and add a meta tag and HTTP header that work like GPC, from server to client.
The header is pretty easy. I just did it. Have a look at this site’s HTTP headers in developer tools or do a
Colorado has a process for registering OOPSs, so I will need to write this up and submit it so it’s valid there. In other jurisdictions the OOPS is valid as long as it expresses the deliberate opt-out of the user, which mine does.
Just to make it extra clear, I need to put something in my Web Site User Agreement, the way a lot of sites do for noai
Remember that laws are downstream of norms here. People generally believe in moral rights and some kind of copyrights for people who do creative work, and people generally believe in some kind of privacy right to control use of your personal information. And you shouldn’t be at a disadvantage when you choose to share personally relevant content on your own site compared to people who share on a big service. The details will get worked out. Big AI will probably be able to make bogus legal arguments, delay, and lobby for a while, but in the long run the law will reflect norms more than it reflects billable hours spent trying to push a disliked business model uphill. Comments and suggestions welcome.
WebDriver is a remote control interface that enables introspection and control of user agents.As such itcanhelp developers to verify that their websites are working and performing well with all major browsers. The protocol is standardized by the W3C and consists of two separate specifications: WebDriver classic (HTTP) and the new WebDriver BiDi (Bi-Directional).
This newsletter gives an overview of the work we’ve done as part of the Firefox 127 release cycle.
Contributions
Firefox – including our WebDriver implementation – is developed as an open source project, and everyone is welcome to contribute. We are always grateful to receive external contributions, here are the ones which made it in 127:
Victoria simplified our implementation of the “Is Element Enabled” command for WebDriver classic in order to use regular DOM APIs instead of an external helper imported from Selenium. This cleanup will also make this command easier to maintain in the future.
Gravyant added a new isInstance assertion helper which can be used in the WebDriver codebase to check that a given object is an instance of a specific class.
Fixed a bug with the "wheel" action, which can be used both in WebDriver BiDi and WebDriver classic. We now correctly handle modifier keys such as Shift, Control, etc. With this, you can simulate a user action scrolling the wheel while holding a modifier.
WebDriver BiDi
New: Support for the “permissions.setPermission” command
The permissions module is an extension to the WebDriver BiDi specification, defined in the Permissions specification. It is the first extension for WebDriver BiDi to be implemented in Firefox, with the permissions.setPermission command. This command allows you to grant, deny or prompt for a given permission, such as “geolocation”. The permission will be set for a provided origin, and optionally for a specific user context.
The descriptor argument should be a Permission Descriptor, which is basically an object with a name string property set to the name of the permission to update. The state argument should be one of "granted", "denied" or "prompt". The origin argument should be the origin for which the permission setting will be set. And finally the optional argument userContext should be the user context id where the permission should be applied ("default" if omitted).
Below is an example of setting the "geolocation" permission to "prompt" for the "https://www.google.com" origin:
Afterwards, trying to use a geolocation feature on a website with the “https://www.google.com” origin such as Google Maps will trigger the permission prompt as shown below:
<figcaption class="wp-element-caption">Google Maps shows the "geolocation" permission prompt</figcaption>
New: Support for accessibility locator in the “browsingContext.locateNodes” command
The accessibility locator allows you to find elements matching a specific computed role or accessible name. This locator has the type "accessibility", and for the value it expects an object with a "name" property (for accessible name) and/or a "role" property (for computed role). You may provide one or both properties at the same time. Note that the start nodes (startNodes argument) can contain elements, documents and document fragments.
For instance, considering the following markup, which attributes the checkbox role to a span, labelled by another span element:
Do you like your computers to be big, fire-prone and inflexible? Then you'll love macOS Sequoia, another missed naming opportunity from the company that should have brought you macOS Mettler, macOS Bolinas (now with no support for mail), or macOS Weed. Plus, now you'll have to deal with pervasive ChatGPT integration, meaning you won't have to watch the next Mission: Impossible to find out what the Entity AI will do to you.
Now that I've had my cup of snark, though, Intel Mac users beware: this one almost uniformly requires a T2 chip, the Apple A10 derivative used as a security controller in the last generation of Intel Macs, and even at least one Mac that does have one isn't supported (the 2018 MacBook Air, presumably because of its lower-powered CPU-GPU, which is likely why the more powerful 2019 iMac without one is supported, albeit incompletely). It would not be a stretch to conclude that this is the final macOS for Intel Macs, though Rosetta 2's integration to support x86_64 in VMs means Intel Mac software will likely stay supported on Apple silicon for awhile. But that shouldn't be particularly surprising. What I did find a little more ominous is that only the 2020 MacBook Air and up is supported in their price segment, and since those Macs are about four years old now, it's possible some M1 Macs might not make the jump to macOS 16 either — whatever Apple ends up calling it.
Our Community Office Hours session for May 2024 has concluded, and it was quite informative (especially for non-developers like me)! Wayne and Daniel shed light on Thunderbird’s build and release process, ran through a detailed presentation, answered questions, and treated us to live demos showing how a new Thunderbird build gets pushed and promoted to release.
Below you’ll find a lightly edited recording of the session, and the presentation slides in PDF format.
We’ll be announcing the topic of our June Office Hours session soon, so keep an eye on the Thunderbird blog.
Have you ever wondered what the release process of Thunderbird is like? Wanted to know if a particular bug would be fixed in the next release? Or how long release support lasts? Or just how many point releases are there?
In the May Office Hours, we’ll demystify the current Thunderbird release process as we get closer to the next Extended Security Release on July 10, 2024.
May Office Hours: The Thunderbird Release Process
One of our guests you may know already: Wayne Mery, our release and community manager. Daniel Darnell, a key release engineer, will also join us. They’ll answer questions about what roles they play, how we stage releases, and when they know if releases are ready. Additionally, they’ll tell us about the future of Thunderbird releases, including working with add-on developers and exploring a monthly release cadence.
Join us as our guests answer these questions and more in the next edition of our Community Office Hours! You can also submit your own questions about this topic beforehand and we’ll be sure to answer them: officehours@thunderbird.net
Catch Up On Last Month’s Thunderbird Community Office Hours
While you’re thinking of questions to ask, watch last month’s office hours where we chatted with three key developers bringing Rust and native Microsoft Exchange support into Thunderbird. You can find the video on our TILvids page.
Join The Video Chat
We’ll be back in our Big Blue Button room, provided by KDE and the Linux Application Summit. We’re grateful for their support and to have an open source web conferencing solution for our community office hours.
(Update 14 Jun 2024: Add darkvisitors.com API and GPC.)
I’m going to start with a warning. You can’t completely block “AI” training from a web site. Underground AI will always get through, and it might turn out that the future of AI-based infringement is bot accounts so that the sites that profit from it can just be shocked at what one of their users was doing—kind of like how big companies monetize copyright infringement.
But there are some ways to tell the halfway crooks of the AI business to go away. Will update if I find others.
This site uses the API to catch up on the latest. So if I fall behind on reading the technology news, the Makefile has me covered.
# update AI crawlers blocking list from darkvisitors.com tmp/robots.txt : curl -X POST "https://api.darkvisitors.com/robots-txts" \ -H "Authorization: Bearer $(shell pass darkvisitors-token)" \ -H "Content-Type: application/json" \ -d '{"agent_types": ["AI Data Scraper", "AI Assistant", "Undocumented AI Agent", "AI Search Crawler"], "disallow": "/"}' \ > $@ # The real robots.txt is built from the local lines # in the conf directory, with the # darkvisitors.com lines added public/robots.txt : conf/robots.txt tmp/robots.txt cat conf/robots.txt tmp/robots.txt > $@
One of my cleanup scripts gets rid of the tmp/robots.txt fetched from Dark Visitors if it gets stale, and I use Pass to store the token.
That support FAQ includes a good point that applies to all of these—the opt out is stronger if it’s backed up with the site Terms of Service or User Agreement. Big companies have invested hella lawyer hours in making these things more enforceable, and if they wanted to override ToS they would be acting against their other interests in keeping their sites in company town mode.
new: privacy opt out for servers
This is the first site to include the new SPC meta tag and X-Robots-Tag header for a privacy opt-out that works like Global Privacy Control but for servers. Basically you have legally enforceable rights in your personal information, blogs have personal information, but regular GPC only works from your browser (client) to company on the server. This goes the other way, and sends a legally enforceable* *yes, I know, this has not yet been tested in court, but give it a minute, we’re just getting started here privacy signal from a personal blog on the server to an AI scraper on the client side.
So the new header on here is
X-Robots-Tag: noai, noimageai, SPC
So we’re up to four, somebody send me number five?
Related
Google Chrome ad features checklist covers the client side of this— how to protect your personal info, and other people’s, from being fed to AI (among other abuses)
How to Stop Your Data From Being Used to Train AI | WIRED covers much other software including Adobe, Slack, and others. The list below only includes companies currently with an opt-out process. For example, Microsoft’s Copilot does not offer users with personal accounts the option to have their prompts not used to improve the software.
For tech CEOs, the dystopia is the pointThe CEOs obviously don’t much care what some flyby cultural critics think of their branding aspirations, but beyond even that, we have to bear in mind that these dystopias are actively useful to them.
Amazon is filled with garbage ebooks. Here’s how they get made.The biographer in question was just one in a vast, hidden ecosystem centered on the production and distribution of very cheap, low-quality ebooks about increasingly esoteric subjects. Many of them gleefully share misinformation or repackage basic facts from WikiHow behind a title that’s been search-engine-optimized to hell and back again. Some of them even steal the names of well-established existing authors and masquerade as new releases from those writers. (I’m going to the real bookstore.)
“Pink slime” local news outlets erupt all over US as election nearsKathleen Carley, a computer science professor at Carnegie Mellon University, said her research suggests that following the 2022 midterms “a lot more money” is being poured into pink slime sites, including advertising on Meta.
Since there’s a search quality crisis on, a lot of the companies you might find on social media are scams, and a lot of the stuff sold on big retail sites is fake, here are some real businesses I can recommend in several categories. Will fill in some more.
I personally know about all of these and would be happy to answer questions.
art, crafts, gifts
Modern Mouse (A place for local artists and artisans to sell their work.)
audio gear
Sweetwater is a good source of pro/semi-pro/office/podcasting equipment. Good support for checking compatibility and other questions.
books
Books Inc (Several Bay Area locations including SFO. If they don’t have it they can order it.)
burritos
Island Taqueria 1313 Park St., Alameda. (Bay Area’s best burritos. El Gran Taco in San Francisco would have been a contender but they’re gone now.)
car repair
Fred’s Wrenchouse has kept a 22-year-old car going for me. (They also provide good recommendations for shops that do the work they don’t.)
JVC Gumy HAFX7 These really sound good and come with a set of silicone ear pieces in different sizes, so in real-world listening situations they sound better than more expensive options that don’t fit as well. (In my experience most drama and waste from electronic devices are caused by apps, firmware, Terms of Service, radios, and batteries. These have none of those.)
electrician
sotelectric dot com memo to self: check and fix link
Microsoft is reworking Recall after researchers point out its security problems (Maybe this is downstream of extreme economic inequality? When so many decisions are made by an out-of-touch management class that shares few of the problems of regular people, new product news turns into an endless stream of weird shit that makes regular people’s problems worse.)
New York to ban ‘addictive’ suggested posts on social media feeds for kidsIn practice, the bill would stop platforms from showing suggested posts to people under the age of 18, content the legislation describes as addictive. Instead, children would get posts only from accounts they follow. A minor could still get the suggested posts if he or she has what the bill defines as verifiable parental consent.
We’re unprepared for the threat GenAI on Instagram, Facebook, and Whatsapp poses to kidsWaves of Child Sexual Abuse Material (CSAM) are inundating social media platforms as bad actors target these sites for their accessibility and reach. (The other issue is labor organizing among social site moderators. The people who run social platforms seem to really think they can AI their way out of dealing with the moderators’ union.)
I turned in my manuscript! (Looks like Evan’s ActivityPub book is coming soon. I put in a purchase request at the library already.)
Thunderbird wouldn’t be here today without its incredible and dedicated contributors. The people developing Thunderbird and all of its add-ons, testing new releases, and supporting fellow users, for example, are the wind beneath our wings. It’s time to give them the spotlight in our new Contributor Highlight series.
We kick things off with Arthur, who contributes to Thunderbird by triaging and filing bug reports at Bugzilla, as well as assisting others.
Arthur, Chicago USA
Why do you like using Thunderbird?
Thunderbird helps me organize my life and I could not function in this world without its Calendar feature. It syncs well with things I do on my Android device and I can even run a portable version of it on my USB drive when I don’t have physical access to my home or office PC. Try doing that with that “other” email client.
What do you do in the Thunderbird community and why do you enjoy it? What motivates you to contribute?
Being a user myself, I can help other users because I know where they’re coming from. Also, having a forum like Bugzilla allows regular users to bring bugs to the attention of the Devs and for me to interface with those users to see if I can reproduce bugs or help them resolve issues. Having a direct line to Mozilla is an amazing resource. If you don’t have skin in the game, you can’t complain about the direction in which a product goes.
How do you relate your professional background and volunteerism to your involvement in Thunderbird?
As an IT veteran of 33+ years, I am very comfortable in user facing support and working with app vendors to resolve app problems but volunteering takes on many forms and is good for personal growth. Some choose to volunteer at their local Food Panty or Homeless shelter. I’ve found my comfort zone in leveraging my decades of IT experience to make something I know millions of users use and help make it better.
Share Your Contributor Highlight (or Get Involved!)
A big thanks to Arthur and all our Thunderbird contributors who have kept us alive and are helping us thrive! We’ll be back soon with more contributor highlights to spotlight more of our community.
If you’re a contributor who would like to share your story, get in touch with us at community@thunderbird.net. If you’re reading this and want to know more about getting involved with Thunderbird, check out our new and improved guide to learn about all the ways to contribute your skills to Thunderbird.
Most of the web already supports HTTPS: In fact, 93% of requests made by Firefox are already HTTPS. As a reminder, HTTP over TLS (HTTPS) fixes the security shortcoming of HTTP by creating a secure and encrypted connection. Oftentimes, when web applications enable encryption with HTTPS on their servers, legacy content may still contain references using HTTP, even though that content would also be available over a secure and encrypted connection. When such a document gets loaded over HTTPS but subresources like images, audio and video are loaded using HTTP, it is referred to as “mixed content”.
Starting with version 127, Firefox is going to automatically upgrade audio, video, and image subresources from HTTP to HTTPS.
Background
When introducing the notion of “mixed content” a long while ago, browsers used to make a fairly sharp distinction between active and passive mixed content: Loading scripts or iframes over HTTP can be really detrimental to the whole document’s security and has long since been blocked as “active mixed content”. Images and other resources were otherwise called “passive” or “display” mixed content. If a network attacker could modify them, they would not gain full control over the document. So, in hope of supporting most existing content, passive content had been allowed to load insecurely, albeit with a warning in the address bar.
Previous behavior, without upgrading: Degraded lock icon, with a warning sign in the lower right corner.
With the web platform supporting many new and exciting forms of content (e.g., responsive images), that notion became a bit blurry: Responsive images are not active in a sense that a malicious responsive image can take over the whole web page. However, with an impetus toward a more secure web, since 2018, we require that new features are only available when using HTTPS.
Upgradable and blockable mixed content
Given these blurry lines between active and passive mixed content, the latest revision of the Mixed content standard distinguishes between blockable and upgradable content, where scripts, iframes, responsive images and really all other features are considered blockable. The formerly-called passive content types (<img>, <audio> and <video> elements) are now being upgraded by the browser to use HTTPS and are not loaded if they are unavailable via HTTPS.
This also introduces a behavior change in our security indicators: Firefox will no longer make use of the tiny warning sign in the lower right corner of the lock icon:
After our change. A fully secure lock icon. The image load was successfully upgraded or failed (e.g., Connection Reset).
With Firefox 127, all mixed content will either be blocked or upgraded. Making sure that documents transferred with HTTPS remain fully secure and encrypted.
Enterprise Users
Enterprise users that do not want Firefox to perform an upgrade have the following options by changing the existing preferences:
Set security.mixed_content.upgrade_display_content to false, such that Firefox will continue displaying mixed content insecurely (including the degraded lock icon from the first picture).
Set security.mixed_content.block_display_content to true, such that Firefox will block all mixed content (including upgradable).
Reasons for changing these preferences might include legacy infrastructure that does not support a secure HTTPS experience. We want to note that neither of these options are recommended because with those, Firefox would deviate from an interoperable web platform. Furthermore, these preferences do not receive the amount of support, scrutiny and quality assurance as those available in our built-in settings page.
Outlook
We will continue our mission where privacy and security is not optional, to bring yet more HTTPS to the web: Next up, we are going to default all addresses from the URL bar to prefer HTTPS, with a fallback to HTTP if the site does not load securely. This feature is already available in Firefox Nightly.
We are also working on another iteration that upgrades more page loads with a fallback called “HTTPS-First” that should be in Firefox Nightly soon. Lastly, security-conscious users with a higher desire to not expose any of their traffic to the network over HTTP can already make use of our strict HTTPS-Only Mode, which is available through Firefox settings. It requires all resource loads to happen over HTTPS or else be blocked.
Collected here are the most recent blog posts from all over the Mozilla community.
The content here is unfiltered and uncensored, and represents the views of individual community members.
Individual posts are owned by their authors -- see original source for licensing information.








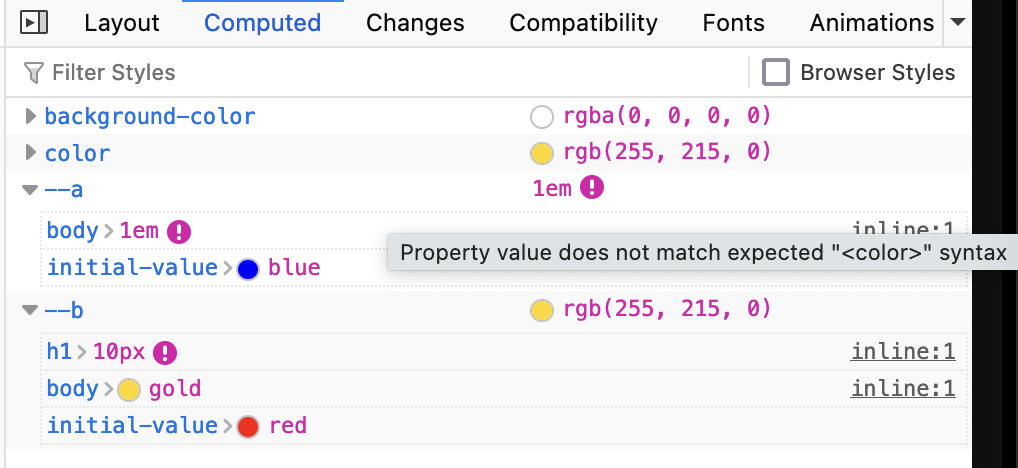










 <figcaption class="wp-element-caption">Udbhav Tiwari, Mozilla’s Director of Global Product Policy, testifies at a Senate committee hearing on the importance of federal privacy legislation in the development of AI.</figcaption>
<figcaption class="wp-element-caption">Udbhav Tiwari, Mozilla’s Director of Global Product Policy, testifies at a Senate committee hearing on the importance of federal privacy legislation in the development of AI.</figcaption>

 <figcaption class="wp-element-caption">When you see an interesting page or video, click the Save to Pocket button to save it instantly.</figcaption>
<figcaption class="wp-element-caption">When you see an interesting page or video, click the Save to Pocket button to save it instantly.</figcaption> <figcaption class="wp-element-caption">Fakespot Review Grades indicate how reliable the reviews are, not the product.</figcaption>
<figcaption class="wp-element-caption">Fakespot Review Grades indicate how reliable the reviews are, not the product.</figcaption>
 <figcaption class="wp-element-caption">Participants of the Dataset Convening in Amsterdam.</figcaption>
<figcaption class="wp-element-caption">Participants of the Dataset Convening in Amsterdam.</figcaption> <figcaption class="wp-element-caption">Participants engaged in a discussion at “The Dataset Convening,” hosted by Mozilla and EleutherAI on June 11, 2024 to explore creating open-access and openly licensed LLM training datasets.</figcaption>
<figcaption class="wp-element-caption">Participants engaged in a discussion at “The Dataset Convening,” hosted by Mozilla and EleutherAI on June 11, 2024 to explore creating open-access and openly licensed LLM training datasets.</figcaption> <figcaption class="wp-element-caption">Participants at the Mozilla and EleutherAI event collaborating on best practices for creating open-access and openly licensed LLM training datasets.
</figcaption>
<figcaption class="wp-element-caption">Participants at the Mozilla and EleutherAI event collaborating on best practices for creating open-access and openly licensed LLM training datasets.
</figcaption>
 <figcaption class="wp-element-caption">Kay Lopez at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>
<figcaption class="wp-element-caption">Kay Lopez at Mozilla’s Rise25 award ceremony in October 2023.</figcaption>



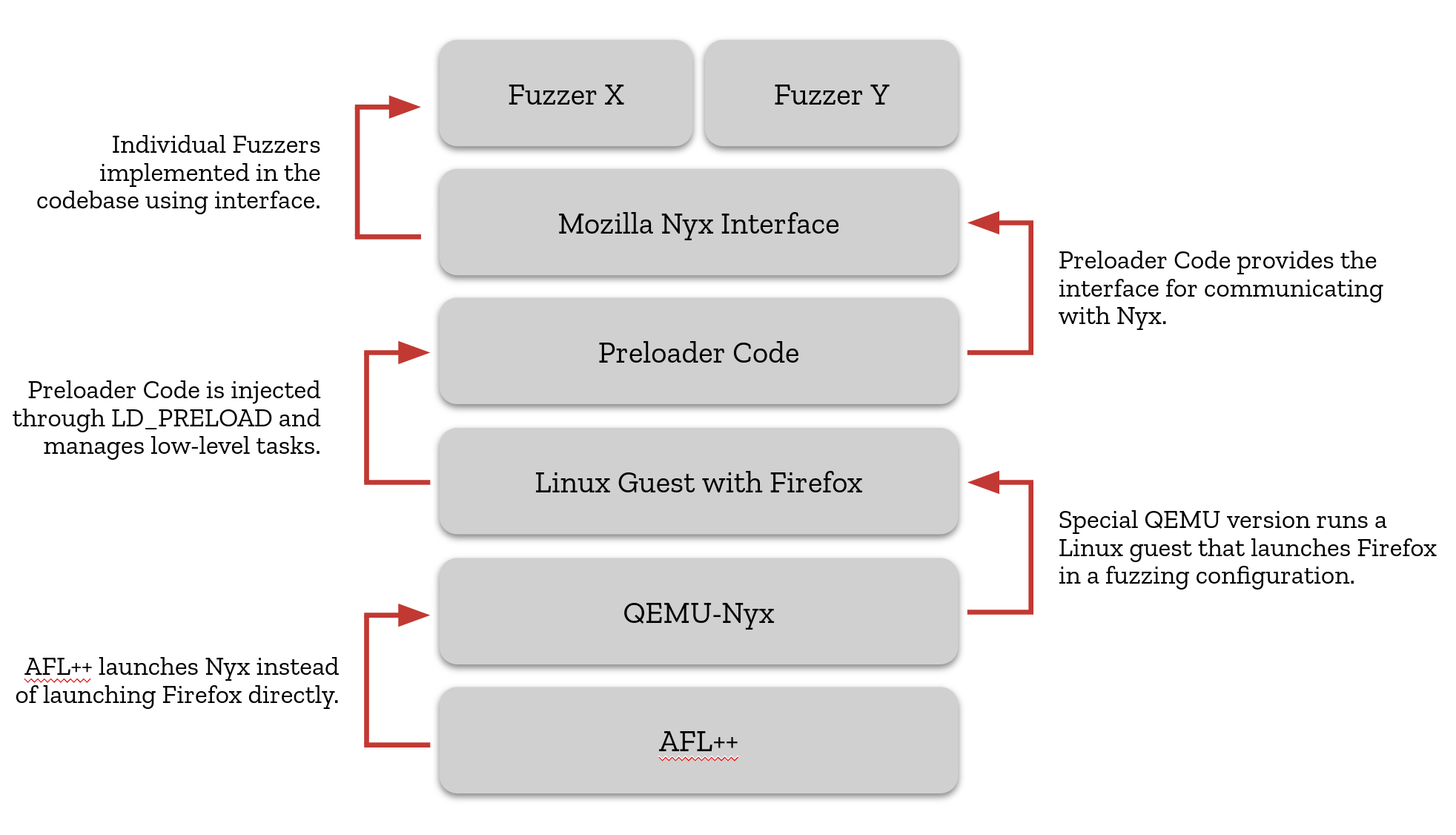





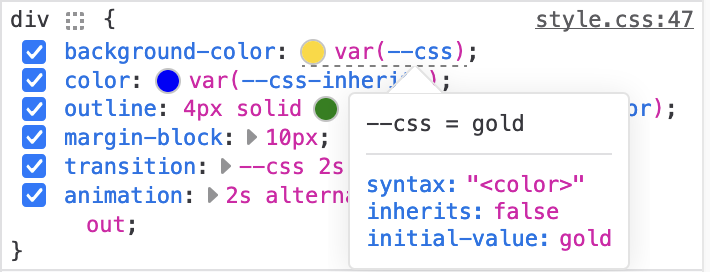





 <figcaption class="wp-element-caption">Google Maps shows the
<figcaption class="wp-element-caption">Google Maps shows the